
面向评价数据中用户偏好发现的证据理论方法*
2017-02-20 10:48郭心宇张彬彬
计算机与生活 2017年2期
郭心宇,岳 昆+,李 劲,武 浩,张彬彬
1.云南大学 信息学院,昆明 650504
2.云南大学 软件学院,昆明 650504
面向评价数据中用户偏好发现的证据理论方法*
郭心宇1,岳 昆1+,李 劲2,武 浩1,张彬彬1
1.云南大学 信息学院,昆明 650504
2.云南大学 软件学院,昆明 650504
海量评价数据;用户偏好;D-S证据理论;证据融合;MapReduce
1 引言
随着Web2.0技术的普及与发展,越来越多的用户通过各种Web平台(例如电子商务网站、评论网站和微博等)浏览、发布和转发消息。淘宝和亚马逊等电子商务应用中用户对商品的评价,信息服务应用中用户对旅游和金融等服务的评价,都是典型的例子。2011年美国Cone公司的调查指出,64%的用户会通过阅读商品的相关评论来了解商品信息,87%的用户阅读了肯定的评论后做出购买的决定,而80%的用户阅读了否定的评论后放弃购买的意向[1]。这些评价数据通常包括用户ID、文本形式的评论内容(review),以及数值(例如分数)或非数值(例如星级)形式的评分(score)等,富含了用户的兴趣、观点和偏好等行为信息。对用户产生的海量评价数据进行分析和挖掘,可发现用户的偏好和兴趣,以及社会个体或群体的行为和心理倾向,识别行为的目标和意图,进而更好地分析用户行为的产生机制,并对用户行为进行预测,为电子商务、社交网络、网络舆情监控和信息服务等各类典型的Web应用提供理论基础和支撑技术[2-3]。从评价数据对用户偏好的影响看,其中文本形式的评论内容,以及数值或非数值形式的评分都体现了用户的偏好;同时,作为对于商品选择倾向性的刻画,用户偏好也决定了用户对商品给出的评论及评分。因此,本文同时考虑用户评价中评论数据和评分数据中所蕴含的用户偏好,旨在得到综合全面的用户偏好信息。
多年来,国内外研究人员基于不同的理论框架或从不同的角度,提出了许多用户偏好的提取或建模方法。这些方法为用户偏好发现的研究提供了许多可供借鉴的思路,但仍存在一些不足之处。例如,Hong等人[3]提出一种基于Agent和决策规则的上下文感知的偏好计算,并提供相应的个性化服务或商品的方法,但规则的确定具有一定的主观性;Skillen等人[4]提出基于本体的偏好建模方法,但本体的设计很大程度上依赖于人的经验;Yao等人[5]提出基于关联规则的方法,但需要根据用户反馈信息来更新用户偏好,且计算复杂度较高;Zhang等人[6]讨论了社交媒体对用户购买行为的影响,基于朴素贝叶斯和支持向量机等算法,从社交媒体学习分类器来预测用户可能购买的商品,但不能细致地描述用户行为影响因素之间的依赖关系,且通用性较差;Tang等人[7]提出基于神经网络的用户偏好发现方法,但存在局部极小点,且对学习、结构和类型的选择过分依赖于经验;Harvey等人[8]针对协同过滤中的评分预测问题,用隐变量刻画用户兴趣和商品主题,基于图模型和概率推理技术来预测用户对商品的评分。
一方面,将考虑用户评价数据中评论和评分对用户偏好的综合影响,而如何有效地综合考虑多个影响因素,是近年来影响用户偏好因素多元化背景下保证用户偏好准确性的前提。目前的方法首先给定各因素的权重,进而以各因素及其权重的加权平均作为度量标准[9]。然而人们预先给定的权重带有一定的主观性,未必能客观地反映实际情况,也忽略了各因素之间的相互联系,当权重未知的情况下难以度量最终的用户偏好。
另一方面,用户的评论数据中不同词汇对其偏好的影响,用户评论和评分数据对其偏好的综合影响,面向单个商品的偏好对面向商品类别的偏好的影响,都具有不确定性,并且词汇、评论和评分等不同影响因素可能来自不同的观测空间,其不确定性也从某种意义上反映了它对用户偏好影响的权重[10]。针对实际中不同的需求,可能需要得到不同层面的用户偏好,例如,有时可能只需要得到用户对某类商品的偏好就可满足应用的需求。因此,本文考虑各层面因素的不确定性和它们之间的相互联系,也考虑这些因素对用户偏好影响的不确定性,研究支持以上3个层面用户偏好发现的方法。
从用户评价数据本身的特点看,以电子商务应用为例,根据Alexa统计及数据计算,淘宝网的日均访问量达到了3.53亿,除了用户的日志记录,也包含了用户对商品的海量评价数据,即用户的评价数据具有海量和非结构化的特征[2,11]。因此,本文利用现有的数据密集型计算技术对海量的评价数据进行分析计算。
具体而言,本文的主要研究工作概括如下:
(1)由Dempster提出,Shafer进一步发展起来的D-S证据理论[12-14],利用证据组合来计算不确定性,通过不确定性推理从不精确和不完整信息中得到可能性最大的结论,被广泛用于信息融合、专家系统、情报与法律案件分析和多属性决策分析等领域[15-16]。根据前述用户偏好的影响因素的特点,用户给出正面评论时未必就不会给出负面评论,因此本文基于D-S证据理论的基本思想,无需假设各影响因素不确定性的完备性,以评论中的各词汇作为用户评论对商品偏好的“证据”,以评论和评分作为用户对商品偏好的“证据”,以用户对一个类别中各商品的偏好作为对商品类别偏好的“证据”,讨论用户在以上3个层面的用户偏好发现的关键技术。本文以第一个层面的偏好发现问题为代表,定义了相应的概率赋值函数和证据组合规则,得到不同证据对最终用户偏好的联合影响。
(2)Hadoop平台下的MapReduce是支持数据密集型计算的并行编程模型[17],被广泛用于云计算、数据挖掘等众多领域[2,18]。因此,为了高效地从海量评价数据中发现用户偏好,本文基于MapReduce编程模型对用户评价数据进行分析处理,提出了实现从用户评价信息发现用户偏好的两趟MapReduce算法。第一趟算法得到一条评论数据中各词汇的统计结果,第二趟算法得到用户对各商品的偏好。
(3)采用MovieLens[19]的用户评价信息作为测试数据集,对本文所提出方法的正确性、加速比和并行效率进行了测试,实验结果验证了本文方法的有效性。
本文组织结构如下:第2章给出用户偏好的表示;第3章给出基于D-S证据理论从海量评价数据中发现用户偏好的方法;第4章给出实验结果;第5章总结全文并展望将来的工作。
2 用户偏好表示
2.1 用户偏好定义
假设用户对一个商品只有1条评价,表1中的示例给出了两个用户对4个类别中8个商品的评价信息。其中,“评论”是从用户评论文本中所抽取的词汇的集合。不难看出:
(1)由用户1的评论“舒适,掉色”可知,用户评论中的各词汇可能反映的是相反的偏好,需要综合考虑各词汇对偏好的影响。
(2)综合考虑用户1的评论和评分可知,在服装类商品中,用户1更倾向于“长裙”;但用户1比用户2更倾向于服装类商品,还是用户2比用户1更倾向于服装类商品,需要综合考虑这两个用户对服装类中各商品的偏好。
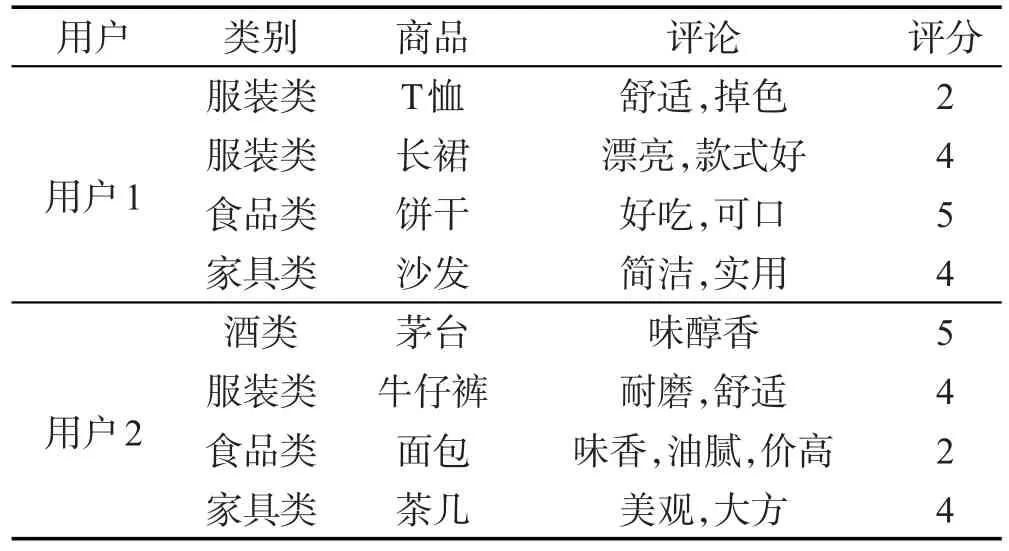
Table 1 Ratings of users on products表1 用户对商品的评价信息
根据以上观察,下面给出用户偏好的定义。
定义1(用户偏好)若u表示一个用户,给定商品集合P={p1,p2,…,pn}和商品类别集合C=(c1,c2,…,cm)(其中,n和m分别为商品数和商品类别数,m〈n),任意商品pi(1≤i≤n)只属于类别cj(1≤j≤m)而不属于C中其他类别。用户u对商品的偏好定义为一个n维向量D=(d1,d2,…,dn),其中di(0≤di≤1)表示用户u对商品pi的喜好程度;用户u对商品类别的偏好定义为一个m维向量,其中(0≤≤1,1≤j≤m)表示用户u对商品类别cj的喜好程度。
2.2 基于边际效用的用户偏好表示
利用信息检索领域已有的关键词抽取方法[20],可以从用户的评论文本中抽取表征用户喜好或态度的标识性词汇,作为衡量评论数据对用户偏好影响的依据,例如表1中的“舒适”和“漂亮”等正面词汇,以及“不好”和“难看”等负面词汇。关键词的抽取不是本文研究的重点,在此不做赘述。
直观地,在用户对一个商品的评论中,正面词汇出现频度越高,负面词汇出现频度越低,说明用户对该商品的喜好程度越高。根据社会学及经济学领域的结论[21],可以基于效用(utility)来描述用户通过消费行为使其欲望得到满足的程度;而边际效用(marginal utility)是指在一定时间内用户增加商品或服务所带来的新增效用,与消费的商品数量成反比,而与消费的欲望成正比。对于一个用户而言,把用户评论中的正面词汇与消费的欲望进行类比,正面词汇越多,对该商品的购买欲望越强(即喜好程度越高);用边际效用刻画评论数据对用户偏好的贡献。根据上述思想,下面定义用户评论中正面词汇/负面词汇对用户偏好的影响。
定义2(边际效用函数)设r表示用户的一条评价,r中评论数据所包含的词汇集合为W,用T和F分别表示W中正面词汇和负面词汇的集合,W=T∪F。正面词汇和负面词汇对于r的边际效用函数分别定义为fT(T)和fF(F),0≤fT(T),fF(F)≤1。
根据前述边际效用的基本思想以及消费欲望与正面词汇的类比关系,针对一条评价信息,定义2中边际效用函数应该满足如下性质:
(1)fT(T)的值随着评论中正面词汇数量的增加而增加,但增加的趋势逐渐变缓;
(2)fF(F)的值随着评论中负面词汇数量的增加而减小,但减小的趋势逐渐变缓;
(3)若评论中既有正面词汇,又有负面词汇,最终的效用函数值应为fT(T)和fF(F)的折衷,且小于fT(T)和fF(F)中的较大者。
结合边际效用的“递减”性和以上性质(1)~(3),下面基于指数函数来刻画边际效用函数值随着评论中词汇数量增加的变化趋势:
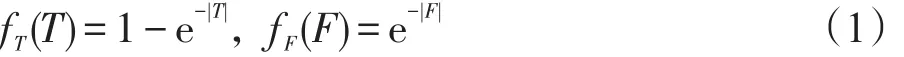
其中,|T|和|F|分别表示正面词汇和负面词汇数量,0≤fT(T),fF(F)≤1。
基于此,可以得到fT(T)和fF(F),即用户的一条评论中正面词汇和负面词汇对用户偏好的贡献。那么,如何进一步得到这条评论对用户偏好的联合贡献(问题1)?如何将一条用户评价中的评论与评分对其偏好的贡献综合起来考虑,得到这条评价信息对用户偏好的综合贡献(问题2)?如何将用户的多条评价对偏好的综合贡献综合起来考虑,得到该用户对各商品的偏好(问题3)?
(1)针对问题1,给出联合算子⊕d,并在第3章给出基于D-S证据理论的计算方法。针对一条用户评价r,以fT(T)和fF(F)作为r中评论数据对用户偏好贡献的“证据”,使用如下公式计算评论数据对用户偏好的联合贡献(记为f(W)):

(2)针对问题2,用户对商品的评分实际上已经给出了一个量化的偏好值,因此首先将评价r中的评分信息进行归一化处理。若所有用户评价中评分的最大值为S,则评分sr对用户偏好的贡献为sr/S(0≤sr/S≤1)。进而,可利用联合算子⊕d计算f(W)⊕dsr/S,从而得到评价r中所蕴含的用户偏好,记为pre(r) (0≤pre(r)≤1)。
(3)针对问题3,仍使用联合算子⊕d,将用户各条评价中所蕴含的偏好综合考虑,得到定义1中描述的偏好向量D。进一步,以用户评价中所涉及商品的偏好为“证据”,使用联合算子⊕d将一类商品的各个偏好进行综合考虑,得到用户对商品类别的偏好。
因此,如何从给定的用户评价数据计算联合算子⊕d,是解决以上3个问题,得到3个层面的用户偏好的基本任务,也是从评价数据发现用户偏好的关键和本文研究的重点。
3 数据密集型的用户偏好发现
如前所述,基于D-S证据理论,通过证据融合规则计算用户偏好。下面以第2章中陈述的问题1为代表,分别讨论联合算子的定义及相应的计算方法。
3.1 基于D-S证据理论的联合算子
下面基于D-S证据理论[11]给出辨识框架和基本概率分配函数(简称mass函数)的定义。
定义3(辨识框架)将一条用户评价r的评论数据中正面词汇(T)和负面词汇(F)构成的集合定义为辨识框架,记为Θ={T,F},Θ的幂集2θ={{∅},{T},{F}, {T,F}}对应于Θ的所有可能评论对用户偏好的影响。
定义4(mass函数)函数m:2Θ→[0,1]称为Θ上的mass函数,函数m1和m2分别为T和F对用户偏好影响的mass函数,且满足:
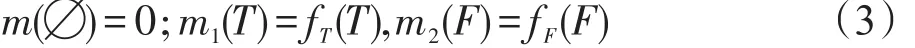
根据D-S证据理论,m称为m1和m2的正交和,也称为证据融合,记为m=m1(T)⊕m2(F),其中⊕为融合算子。进而,基于m讨论式(2)中的联合算子⊕d。事实上,用户对商品给出正面评论的同时也会给出负面评论,给出正面评论,未必就不会给出负面评论。因此,针对正面评论T,用m1(Θ)表示该评论中除了T之外的可能评论的mass函数,且

同理,仅针对负面评论F,用m2(Θ)表示该评论中除了F之外的可能评论的mass函数,且

D-S证据理论中,Dempster证据组合规则[12-14]组合两个mass函数,以产生一个新的mass函数,表示初始可能冲突的证据间的一致意见,通过仅仅对交集的mass函数值求和汇集一致意见,集合的交集表达了公共证据元素。根据Dempster证据组合规则的基本思想,基于式(3)~(5),得到:
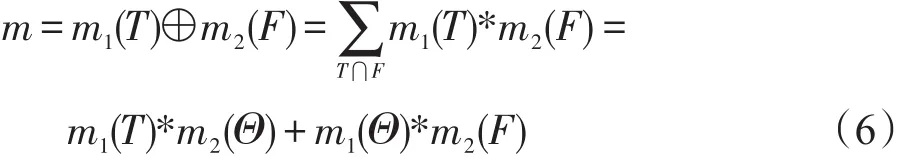

进而,基于证据融合后的mass函数,⊕d可定义为包含T或F的mass函数值之和,即:
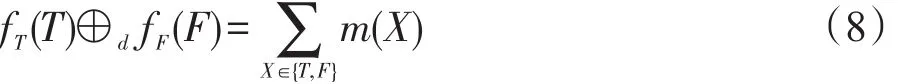
下面通过一个简单的例子说明基于D-S证据理论的联合算子的基本思想。对于表1中用户2对“面包”的评论,T={味香},F={油腻,价高},根据式(1)、(3)、(4)和(5),可以得到m1(T)=0.6,m1(Θ)=1-m1(T)= 0.4,m2(F)=0.1,m2(Θ)=1-m2(F)=0.9。
基于式(6),以T和F作为该评论对用户偏好影响的证据,组合结果如表2所示。
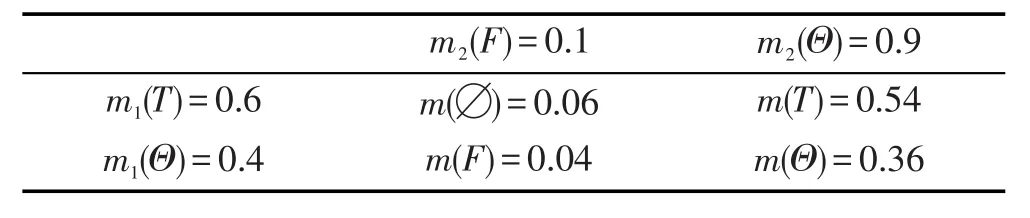
Table 2 Evidence combination ofTandF表2 T和F证据组合
基于式(7),可以得到:
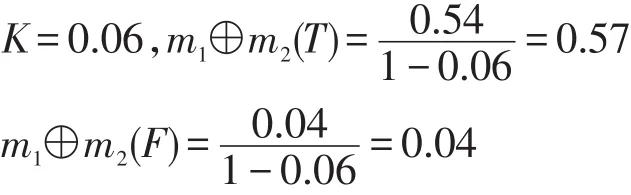
基于式(8),式(2)的具体计算如下:

也就是说,用户2的偏好向量中,商品“面包”维度的偏好值为0.61。
3.2 基于MapReduce的用户偏好发现算法
针对海量的用户评价信息,基于3.1节中给出的方法计算用户评论数据对其偏好的联合影响,本文设计了两趟执行的MapReduce算法。第一趟算法(算法1)针对每一条评论数据,通过Map函数得到这条评论中正面词汇及负面词汇出现的次数,通过Reduce函数对这条评论中正面词汇及负面词汇的出现次数进行求和;第二趟算法(算法2)针对用户对各商品的评论数据,通过Map函数得到用户对一个商品(针对一条评论)的偏好,通过Reduce函数得到该用户对所有商品的偏好向量。
算法1 Count_|T|_|F|
对于每条评论,将算法1的执行结果以〈key,value〉的形式存储到中间结果文件W中,即用|T|和|F|来表示用户的一条评论,以之作为用户偏好计算的基础。不难看出,算法1的执行代价主要取决于遍历评论信息,并与已知标示性词语集合匹配,若标示性词语集合中有n个词语,则算法1在最坏情况下时间复杂度为O(n2)。根据算法1,可以得到每一条用户评论中关键词的数量,方便对评论进行量化处理。下面给出从每一条评论发现其中所蕴含用户偏好的算法,体现3.1节中的各个计算步骤。
算法2 Compute_Preference


不难看出,算法2的执行代价主要取决于遍历每一条用户评价信息的统计结果,利用算法1的统计结果,由算法2将用户的评分和评论进行量化处理,从而得到最终的用户偏好。若有n条评价信息,算法2的时间复杂度为O(n)。本文采用MapReduce算法通过并行计算的方式保证了算法较高的执行效率。
4 实验结果
4.1 实验设置
本文使用MovieLens[19]上用户的真实评价数据作为测试数据集,包括229 060位用户对27 303部电影的21 063 128条记录。每个用户至少为20部电影评分,平均每1 GB数据包含37 886 000条用户记录。数据集格式为UserId::MovieId::Rating::Tags,依次为用户Id、电影Id、用户评分和用户对这部电影的评论标签。实验环境如下:运行Linux CentOs7系统和Hadoop-2.5.1平台的6台机器,Inter Core i3 3240处理器、3.4 GHz主频和2 GB内存,每台机器作为一个DataNode。为了测试本文方法的可行性,测试了从评论数据发现用户偏好方法的有效性、执行时间、加速比和并行效率。
4.2 有效性测试
为了测试本文从用户评价数据发现其偏好的方法的有效性,首先假设用户评价中的评分数据反映了其真实的偏好,并以之作为衡量从评论数据发现用户偏好的正确性标准。直观地,若评分的最大值为5,则评分为4和5即为高分,相应地,评论中的正面词汇数量应不少于负面词汇数量。对此,针对评分为4或5的评价,通过多次实验确定偏好阈值为0.63,可保证评分与评论具有上述的对应关系。对于各条评分为4或5的用户评价,若基于本文方法从评论数据计算得到的用户偏好值不低于该阈值,则说明基于本文方法得到的用户偏好是正确的。从测试数据中随机选择10条评价,考虑从评论数据计算得到的用户偏好与评分之间是否一致,如表3所示。不难看出,值为4或5的高评分所对应的用户偏好大于0.63的占70%,即正确率为70%,这与人们的直观理解基本相符,从一定程度上说明了本文方法的正确性。
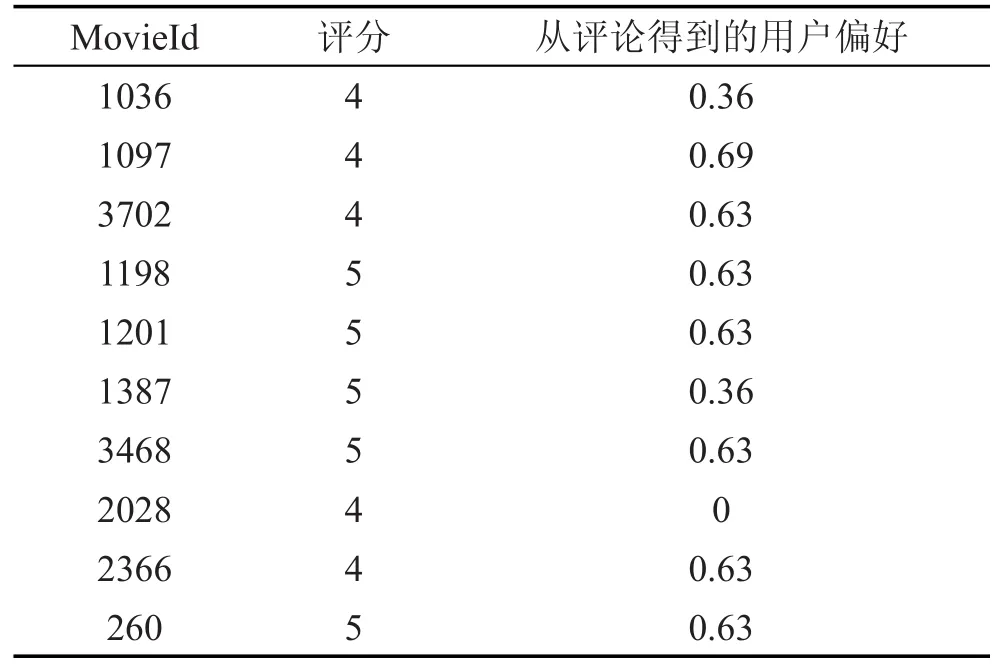
Table 3 Comparisons between scores and user preference derived from reviews表3 评分与从评论得到的用户偏好对比
进一步,对评分进行归一化处理,对评论按照第3章给出的方法,分别得到从评分和评论数据中发现的用户偏好(分别记为ds和dr),基于2.2节的基本思路,将评分和评论看作最终用户偏好的证据,无需评分与评论的权重,得到综合考虑评分和评论的最终结果(记为d)。随机选择10条评价数据,将d与基于ds和dr算术平均(记为da)的结果进行比较,如表4所示。通过前3条评价数据的结果对比可以看出,当ds不变时,d随着dr的增加而增加,当dr不变时,d随着ds的增加而增加,这一趋势符合实际情况。对于第10条缺失评论的评价数据,基于本文方法得到的用户偏好即为ds,基于算术平均方法得到的结果与实际不符。对这10条评价对应的d与da排序,除了第3条和第8条外,d与da趋势一致,说明基于本文方法得到的用户偏好可有效用于商品投放和用户定向等基于用户偏好的实际应用中。因此,基于本文方法,可在各影响因素权重未知的情况下考虑它们之间的内在联系而得出符合实际情况的偏好排序,能以更符合人们直观理解的方式,更合理地反映用户对于商品的喜好程度。
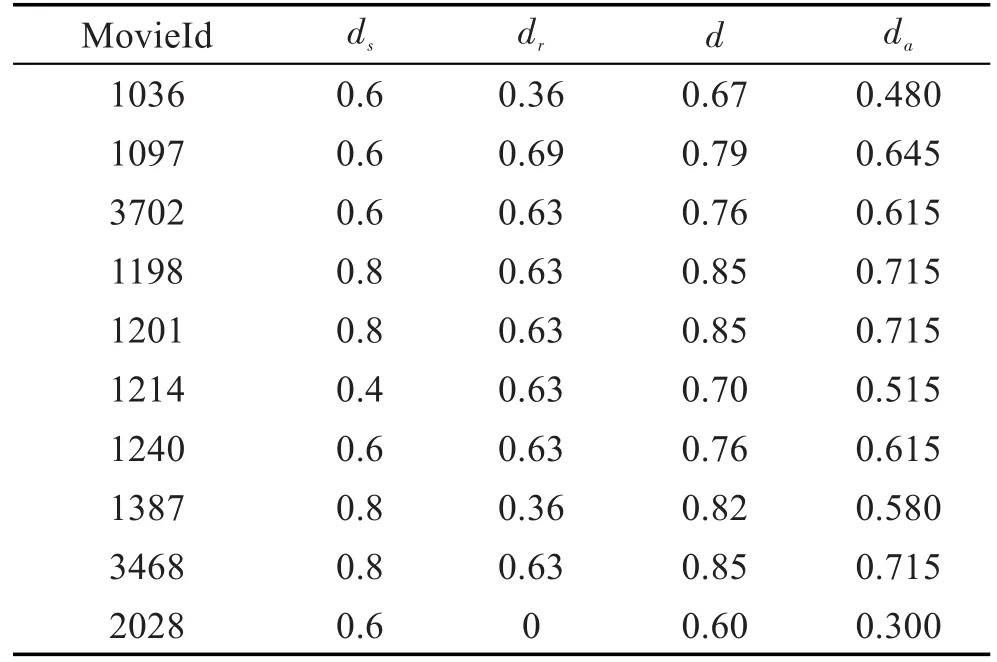
Table 4 Comparisons between user preference by this paper method and that by arithmetic mean表4 基于本文方法与算术平均方法结果对比
接下来,再从另一个角度来说明本文方法的有效性。随机选取3名用户(记为A、B和C),同时随机选取20部他们都评价过的电影作为测试数据,其中10部电影的评价信息作为训练数据,剩下10部电影的评价信息作为对比数据。表5给出了3名用户对10部电影的评分数据。
对比基于协同过滤算法[8]和基于本文方法得到的用户偏好,以测试本文方法的有效性。实验选定用户B为目标用户。首先假设用户A和C只对ID为1~10的电影进行了评价,而用户B对全部电影进行了评价;然后基于余弦相似度找出与用户B相似的用户集;将ID为11~20的电影按照B的喜好推荐给A或C。对比以上两个结果,若用户评分不小于4,则表示用户喜欢此电影;基于余弦相似度可得到用户A和用户B相似度最高。表6给出了他们对后10部电影的评价信息。用户A的评分数据通过协同过滤方法预测得到,通过与基于本文方法从评论中获取的用户偏好进行比较,可以看出,除了ID为13、15和19的电影,通过基于协同过滤方法预测得到的电影评分与使用本文方法从评论中得到用户偏好结果基本一致,进而可得到用户对电影的倾向性选择,这在一定程度上说明了本文方法的正确性。
Table 5 Ratings of users on movies表5 用户对电影的评分信息
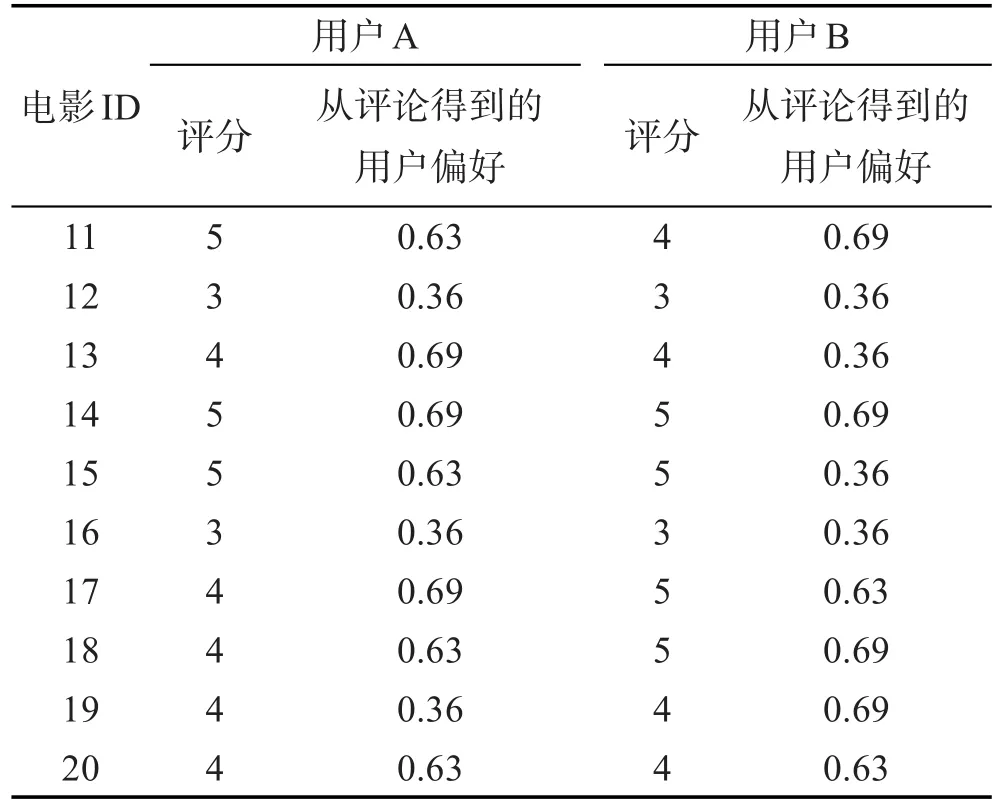
Table 6 Comparions between userAand user B evaluation information表6 用户A和用户B评价信息对比
4.3 效率测试
为了测试本文方法的执行效率,选取了规模为2.5 GB、5 GB、10 GB、15 GB和20 GB的5组MovieLens数据,分别测试了不同DataNode数量情况下的执行时间、加速比和并行效率。其中执行时间包括对测试数据集中所有评价执行算法1的时间以及执行算法2的时间,每个测试结果取3次执行时间的平均值。
图1给出了随着评价数据规模增加,不同Data-Node数量时的执行时间。可以看出,随着评价数据规模增加,DataNode数量越多,执行时间增加越慢;当评价数据规模达到20 GB时,本文方法在当前实验环境下仍能高效地得到用户偏好。图2给出了随着DataNode数量增加,不同评价数据规模时的执行时间。可以看出,随着DataNode增加,执行时间减少,且数据量越大这一趋势越显著,说明本文方法对于海量评价数据分析具有较好的可扩展性。
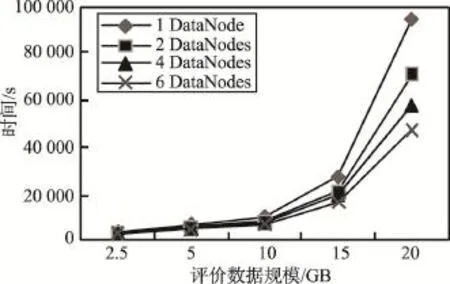
Fig.1 Execution time with the increase of rating data size图1 随着评价数据规模增加的执行时间
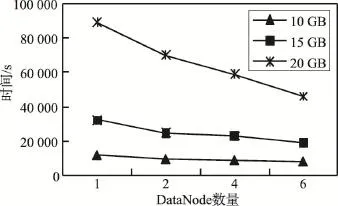
Fig.2 Execution time with the increase of DataNodes图2 随着DataNode增加的执行时间
并行算法的加速比是单节点情形下执行时间与多节点情形下执行时间的比值。图3给出了随着评价数据规模增加,不同DataNode数量时的加速比。图4给出了随着DataNode数量增加,不同评价数据规模时的加速比。可以看出,随着评价数据量增加,Data-Node数量越多,加速比增加越快。
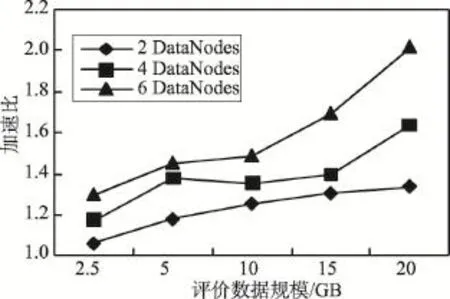
Fig.3 Speedup with the increase of rating data size图3 随着评价数据规模增加的加速比
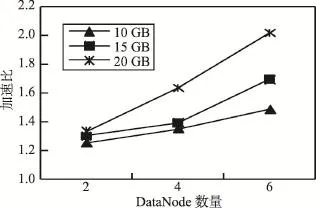
Fig.4 Speedup with the increase of DataNodes图4 随着DataNode增加的加速比
并行算法的并行效率是加速比与节点数的比值。图5给出了随着评价数据规模增加,不同DataNode数量时的并行效率。可以看出,随着评价数据规模增加,不同DataNode数量时并行效率都逐渐增加,但DataNode越多,并行效率越低。图6给出了随着DataNode数量增加,不同评价数据规模时的并行效率。可以看出,随着DataNode数量增加,不同评价数据规模时的并行效率都逐渐下降,同一Data-Node数量时数据量越大,并行效率越高,说明了本文方法对于海量评价数据规模具有较好的可扩展性。
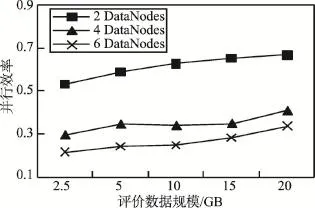
Fig.5 Parallel efficiency with the increase of rating data size图5 随着评价数据规模增加的并行效率
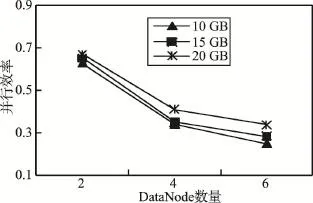
Fig.6 Parallel efficiency with the increase of DataNodes图6 随着DataNode增加的并行效率
5 总结与展望
本文基于D-S证据理论和MapReduce编程模型,提出了从海量的用户评价数据中发现用户偏好的方法。本文提出的方法和思路:利用影响用户偏好的各因素的不确定性和它们之间的相互关系,可得到基于用户评论中正面词汇和负面词汇、基于用户评论和评分、面向商品类别的3个层次的用户偏好。本文方法可准确、快速地发现用户偏好,可支持实际中商品推荐和用户定向等应用。然而,作为一种初步的尝试,本文从评论数据中抽取正面词汇和负面词汇时,未考虑评论中词汇的语义,具有一定的主观性;针对每个商品计算用户的偏好,而实际中商品的数量较多,需要引入降维技术来提高计算的效率,也更符合实际情形,这些是将要开展的工作。
References:
[1]Lin Yuming,Zhu Tao,Wang Xiaoling,et al.Assembling and optimizing multiple classifiers for user opinion analysis[J]. Chinese Journal of Computers,2013,36(8):1650-1658.
[2]Wang Yuanzhuo,Jin Xiaolong,Cheng Xueqi.Network big data:present and future[J].Chinese Journal of Computers, 2013,36(6):1125-1138.
[3]Hong Jongyi,Suh E,Kim J,et al.Context-aware system for proactive personalized service based on context history[J]. Expert Systems withApplications,2009,36(4):7448-7457.
[4]Skillen K L,Chen Liming,Nugent C,et al.Ontological user profile modeling for context-aware application personalization[C]//LNCS 7656:Proceedings of the 6th International Conference on Ubiquitous Computing and Ambient Intelligence,Vitoria-Gasteiz,Spain,Dec 3-5,2012.Berlin,Heidelberg:Springer,2012:261-268.
[5]Yao Xiuli,Shu Huaying.Study on value-added service in mobile telecom based on association rules[C]//Proceedings of the 2009 10th ACIS International Conference on Software Engineering,Artificial Intelligences,Networking and Parallel/Distributed Computing,Daegu,Korea,May 27-29, 2009.Washington:IEEE Computer Society,2009:116-119.
[6]Zhang Yongzheng,Pennacchiotti M.Predicting purchase behaviors from social media[C]//Proceedings of the 22nd International Conference on World Wide Web,Rio,Brazil,May 13-17,2013.New York:ACM,2013:1521-1532.
[7]Tang Duyu,Qin Bing,Liu Ting,et al.User modeling with neural network for review rating prediction[C]//Proceedings of the 24th International Conference on Artificial Intelligence,Buenos Aires,Argentina,Jul 25-31,2015.Palo Alto, USA:AAAI Press,2015:1340-1346.
[8]Harvey M,Carman M J,Ruthven I,et al.Bayesian latent variable models for collaborative item rating prediction[C]// Proceedings of the 20th ACM Conference on Information and Knowledge Management,Glasgow,UK,Oct 24-28, 2011.New York:ACM,2011:699-708.
[9]Ma You,Wang Shangguang,Sun Qibo,et al.Web services QoS measure based on subjective and objective weight[C]// Proceedings of the 2013 IEEE International Conference on Services Computing,Santa Clara,USA,Jun 28-Jul 3,2013. Piscataway,USA:IEEE,2013:543-550.
[10]Yue Kun,Liu Weiyi,Wang Xiaoling,et al.An approach for measuring quality of Web services based on the superposition of uncertain factors[J].Journal of Computer Research and Development,2009,46(5):841-849.
[11]Shmueli-Scheuer M,Roitman H,Carmel D,et al.Extracting user profiles from large scale data[C]//Proceedings of the 2010 Workshop on Massive DataAnalytics on the Cloud,Raleigh,USA,Apr 26,2010.New York:ACM,2010:4.
[12]Dempster A.Upper and lower probabilities induced by a multivalued mapping[J].Annals of Mathematical Statistics, 1967,38(2):325-339.
[13]Shafer G.Mathematical theory of evidence[M].Princeton, USA:Princeton University Press,1976.
[14]Pearl J.Probabilistic reasoning in intelligent systems:networks of plausible inference[M].San Mateo,USA:Morgan Kaufmann Publishers,Inc,1988.
[15]Yang Jianping,Huang Hongzhong,Miao Qiang,et al.A novel information fusion method based on Dempster-Shafer evidence theory for conflict resolution[J].Intelligent Data Analysis,2011,15(3):399-411.
[16]Qiu Peiyuan,Lu Feng,Zhang Hengcai.Extracting traffic information from Web texts with a D-S evidence theory based approach[C]//Proceedings of the 21st International Conference on Geoinformatics,Kaifeng,China,Jun 20-22,2013. Piscataway,USA:IEEE,2013:1-5.
[17]Dean J,Ghemawat S.MapReduce:a flexible data processing tool[J].Communications of theACM,2010,53(1):72-77.
[18]Yue Kun,Fang Qiyu,Wang Xiaoling,et al.A parallel and incremental approach for data-intensive learning of Bayesian networks[J].IEEE Transactions on Cybernetics,2005,45 (12):2890-2904.
[19]MovieLens[EB/OL].(2015)[2015-09-28].http://grouplens. org/datasets/movielens/.
[20]Yue Kun,Liu Weiyi,Zhou Liping.Automatic keyword extraction from documents based on multi-perspective semantic measures[J].International Journal of Computer Systems Science and Engineering,2011,26(2):133-145.
[21]Gao Hongye.Mocroeconomics[M].5th ed.Beijing:China Renmin University Press,2010.
附中文参考文献:
[1]林煜明,朱涛,王晓玲,等.面向用户观点分析的多分类器集成和优化技术[J].计算机学报,2013,36(8):1650-1658.
[2]王元卓,靳小龙,程学旗.网络大数据:现状与展望[J].计算机学报,2013,36(6):1125-1138.
[10]岳昆,刘惟一,王晓玲,等.一种基于不确定性因素叠加的Web服务质量度量方法[J].计算机研究与发展,2009,46 (5):841-849.
[21]高鸿业.西方经济学(微观部分)[M].5版.北京:中国人民大学出版社,2010.

GUO Xinyu was born in 1990.He is an M.S.candidate at School of Information Science and Engineering,Yunnan University.His research interests include massive data analysis and services.
郭心宇(1990—),男,河北石家庄人,云南大学信息学院硕士研究生,主要研究领域为海量数据分析与服务。

YUE Kun was born in 1979.He received the M.S degree in computer science from Fudan University in 2004,and received the Ph.D.degree in computer science from Yunnan University in 2009.Now he is a professor and Ph.D.supervisor at Yunnan University,and the member of CCF.His research interests include massive data analysis and services.
岳昆(1979—),男,云南曲靖人,2004年于复旦大学获得计算机硕士学位,2009年于云南大学获得计算机博士学位,现为云南大学教授、博士生导师,CCF会员,主要研究领域为海量数据分析与服务。

LI Jin was born in 1975.He received the Ph.D.degree in computer science from Yunnan University in 2012.Now he is an associate professor at Yunnan University,and the member of CCF.His research interests include massive data analysis and artificial intelligence.
李劲(1975—),男,云南大理人,2012年于云南大学获得计算机博士学位,现为云南大学副教授,CCF会员,主要研究领域为海量数据分析与人工智能。

WU Hao was born in 1979.He received the Ph.D.degree in computer science from Huazhong University of Science and Technology in 2007.Now he is an associate professor at Yunnan University.His research interests include information retrieval,recommendation system and service computing.
武浩(1979—),男,河南平顶山人,2007年于华中科技大学获得计算机博士学位,现为云南大学副教授,主要研究领域为信息检索,推荐系统,服务计算。

ZHANG Binbin was born in 1982.She received the Ph.D.degree in computer science from Peking University in 2011.Now she is a lecturer at Yunnan University.Her research interests include virtualization and cloud computing.张彬彬(1982—),女,云南大理人,2011年于北京大学获得计算机博士学位,现为云南大学讲师,主要研究领域为虚拟化,云计算。
Evidence-TheoryApproach for Discovering User Preferences in Rating Data*
GUO Xinyu1,YUE Kun1+,LI Jin2,WU Hao1,ZHANG Binbin1
1.School of Information Science and Engineering,Yunnan University,Kunming 650504,China
2.School of Software,Yunnan University,Kunming 650504,China
+Corresponding author:E-mail:kyue@ynu.edu.cn
User rating on products or information services includes reviews and scores,and reflects user behavior information,such as interest,opinions and preferences.In order to represent the degrees of user preferences on products inherently and quantitatively,starting from the massive rating data,this paper defines user preference based on the idea of marginal utility.Then,this paper describes the uncertainties of relevant influence factors on user preferences and the mutual relationships among these factors based on the D-S evidence theory.Taking the vocabulary in a review, the vocabulary including positive/negative words and the score as the evidence of user preference respectively,this paper gives the operator for combining the relevant factors jointly,as well as the computation method and mechanism for discovering user preferences based on MapReduce.The experimental results on correctness,execution time,speedup and parallel efficiency verify the effectiveness of the method proposed in this paper.
massive rating data;user preference;D-S evidence theory;evidence fusion;MapReduce
10.3778/j.issn.1673-9418.1511023
A
TP311
*The National Natural Science Foundation of China under Grant Nos.61472345,61402398,61562090,61562091(国家自然科学基金);the Applied Basic Research Project of Yunnan Province under Grant Nos.2014FA023,2016FB110(云南省应用基础研究计划); the Program for the Second Batch of Yunling Scholar of Yunnan Province under Grant No.C6153001(第二批“云岭学者”培养项目);the Program for Excellent Young Talents of Yunnan University under Grant No.XT412003(云南大学青年英才培养计划).
Received 2015-11,Accepted 2016-04.
CNKI网络优先出版:2016-04-01,http://www.cnki.net/kcms/detail/11.5602.TP.20160401.1614.002.html
GUO Xinyu,YUE Kun,LI Jin,et al.Evidence-theory approach for discovering user preferences in rating data. Journal of Frontiers of Computer Science and Technology,2017,11(2):231-241.
摘 要:用户对商品和信息服务的评价包含评论和评分,富含了用户的兴趣、观点和偏好等行为信息。以真实和量化地反映用户对商品的喜好程度为目标,从海量的用户评价数据出发,基于边际效用定义用户偏好,基于D-S证据理论描述影响用户偏好的各影响因素的不确定性以及各因素之间的相互关系;以评论中的各词汇、包含正面/负面词汇的评论和评分作为用户对商品偏好的“证据”,给出了综合考虑各影响因素的联合算子,以及基于MapReduce的计算方法和用户偏好发现机制。针对正确性、执行时间、加速比和并行效率等指标进行实验,结果验证了所提出方法的有效性。
猜你喜欢
昆明医科大学学报(2022年3期)2022-04-19
昆明医科大学学报(2022年2期)2022-03-29
中华胰腺病杂志(2021年1期)2021-02-26
山东医药(2020年34期)2020-12-09
小学生优秀作文(低年级)(2020年5期)2020-07-25
文理导航·趣味课堂(2016年5期)2016-07-21
文理导航·趣味课堂(2016年4期)2016-06-01
幼儿智力世界(2016年6期)2016-05-14
祝你幸福·知心(2016年3期)2016-03-29
