
Web服务编排场景的XML Schema消息类型精化
2017-02-27 10:58杨红丽
计算机应用与软件 2017年2期
王 瑾 马 凯 杨红丽
(北京工业大学计算机学院 北京 100124)
Web服务编排场景的XML Schema消息类型精化
王 瑾 马 凯 杨红丽
(北京工业大学计算机学院 北京 100124)
Web服务(Web Services)编排描述了Web服务组合的交互行为,在实际开发中,Web服务组合的实现可能存在交互的数据类型、交互序列与编排规范不相符的情况,为了测试Web服务(组合)与编排的相符性,需要从编排规范生成测试用例。由于编排场景描述了编排中各个参与方的交互序列及其交互消息的XML Schema类型,从而可以根据场景中的XML Schema类型生成测试数据。由于XML Schema类型中指示器的作用导致类型的不确定性,需要解决XML Schema类型精化问题,为此提出了基于组合测试的XML Schema类型精化方法。通过定义XML Schema类型树,给出了基于组合测试工具Cascade的类型精化算法,并通过实例表明该方法的有效性。
Web服务编排 XML Schema 指示器 类型精化 组合测试
0 引 言
Web服务是针对因特网上分布计算提出的一种基于开放标准、松散耦合及跨平台的新型软件构件。但是单个Web服务已经越来越难以满足人们日益复杂的业务需求,Web服务组合应运而生。服务编排是从全局的角度描述Web服务组合之间的交互,从而确保服务组合各个参与方能够协调完成一项业务逻辑。
编排结构多样,数据类型复杂。国外的很多研究组都对编排进行了研究,文献[1-4]提出了基于模型检查的方法验证服务编排;大部分工作着眼于编排的建模与模型检查,验证的方法可以确保编排规范和角色需求的正确性,而测试可以保证在源码不可知只能获得实现端的接口时,编排实现的正确性,而基于编排的相符性的测试研究工作还很不成熟。本课题组提出了基于编排场景的Web服务组合的相符性测试框架[1],编排场景可以理解为多个角色之间的确定的交互序列(不含选择、循环)[6]。根据编排中的控制流活动抽取一组编排场景,每个编排场景的交互序列一定,从而在编排场景上进行测试。
编排场景不仅描述了多个参与方的交互序列,还定义了交互的数据类型,这些类型被定义在XML Schema中。而相符性测试的测试数据由场景中的XML Schema产生。由于XML Schema中存在choice、minOccurs和maxOccurs这样的指示器,造成变量类型的多样化,因此在生成测试数据之前要先对XML Schema中的指示器进行划分。多个指示器存在时,需要对划分的子类型进行组合,如果采用全排列的组合方式容易造成组合爆炸,产生昂贵的测试代价[7-9]。本文采用了组合测试的思想对子类型的划分进行组合,并将组合后的数据转换为一组类型确定的类型树,为测试数据的生成奠定基础。首先,将XML Schema解析成类型树,方便与组合测试工具进行模型转换,然后通过遍历类型树边的指示器信息,对不同指示器进行不同的处理,得到相应组合测试工具输入模型,通过组合测试工具的组合,得到的一组输出模型,再将输出值转化为一组对应的精化后的类型树。
1 相关概念
1.1 编排场景
定义1 编排场景S是一个四元组:
S=
其中,R是角色声明的有限集,分为被测服务和测试桩;I是交互类型的有限集,被定义在外部的XML Schema中;V是变量声明的有限集,每一个变量都对应I中的一个变量;A是交互序列的有限集,分为请求型Request{R1.x op R2.y Guard}和响应型Response{R1.x op R2.x Guard}。Request{R1.x op R2.y Guard}是指在满足Guard前置条件的基础上,将R1上的x变量通过操作op传给R2的y变量;Response{R1.x op R2.x Guard}是指在满足Guard前置条件的基础上,将R2的变量y通过op操作传给R1的x变量。
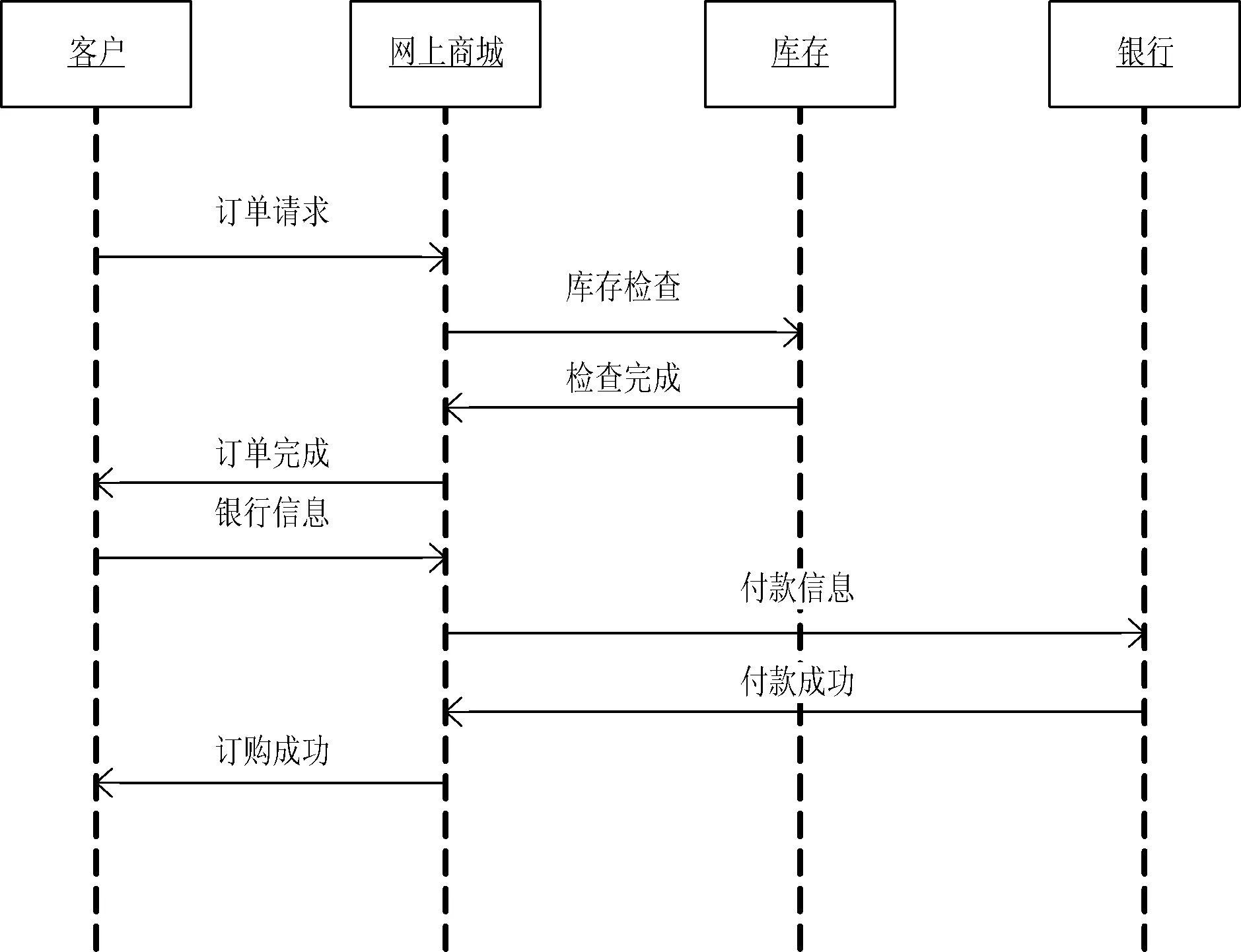
图1 成功购买场景
图1的UML时序图描述了购买成功的场景。场景中包含客户、网上商城、库存和银行四个角色。交互流程为:客户发送订单请求给网上商城;网上商城向库存发送库存检查信息;库存将检查结果发送给商城;商城发送订单完成的信息给客户。客户发送银行信息给商城;商城将付款信息发送给银行;银行向商城发送付款完成信息;商城发送订购成功信息给客户。
1.2 XML Schema类型划分
XML Schema[10]是用于描述和规范XML文档逻辑结构的一种语言,通过指示器来控制元素的使用方式。指示器导致了变量类型的多样性,尤其是choice、minOccurs、maxOccurs三种指示器。表1给出了这三种指示器的划分规则。

表1 指示器类型划分规则
1) 当出现choice指示器时,someElement可以选择c1、c2、c3、…,将其分别划分为someElement子元素为c1、c2、c3、…多个子类型。
2) 当出现minOccurs=″k1″ maxOccurs=″k2″指示器时,someElement最少可以出现k1次,最多可以出现k2次,将其划分为三个子类型,分别为minOccurs=″k1″ maxOccurs =″k1″, minOccurs=″k2″ maxOccurs=″k2″,minOccurs=″k″ maxOccurs= ″k″ (k1 3) 当出现minOccurs=″k1″ maxOccurs=″unbound″指示器时,将其划分为两种子类型:minOccurs=″k1″ maxOccurs =″k1″,minOccurs=″k1+1″ maxOccurs =″k1+1″。 通过相应的划分规则,得到结构确定的子类型,并且使得该子类型一定满足XML Schema类型定义。当一个XML Schema中存在多个指示器时,对每个指示器进行划分并且重新组合,可以得到一组类型确定并满足初始XML Schema类型的子类型。如果采用全排列的方式对划分后的元素进行重组,势必会产生一组数量庞大的子类型,为了解决这个问题,本文引入了组合的测试方法对划分的子类型进行组合。 1.3 组合测试方法 组合测试方法旨在应用较少的测试用例有效地检查软件系统中各个因素以及它们之间的互相作用对系统产生的影响。 针对具体待测软件,在满足给定组合覆盖要求的前提下,生成规模尽可能小的测试用例集,以便在保证错误检测能力的前提下尽可能降低测试成本。 组合测试中的基本概念包括: (1) 变量,表示软件的输入; (2) 水平,表示变量的取值; (3) 强度,表示变量之间相互作用的强度。 Cascade[11]是一款组合测试用例生成工具,工具支持的变量类型有:string、integer、double。变量的水平由用户输入。用户可以输入蕴含表达式对用例的生成进行约束,表达式支持字符串以及数值的比较,支持逻辑和算数运算符。 Cascade蕴含式约束的引入可以人为的减少无效组合的出现,有效提高用例集质量。Cascade的约束表达式有两种形式: (1) expA -> expB 表示A蕴含B,即若表达式A成立,那么B也必须成立。 (2) expA##(param_list), 表示如果表达式expA成立,那么param_list集合中的参数无意义,不参加组合。 下面给出Cascade的输入和输出模型定义: 定义2 Cascade的输入模型 (1) { (Vi,Li) |i=1,2,…,n}。其中n为自然数。每个Vi都是一个变量,Li是该变量的水平。整个集合可以看作包含了多个VL对,每个VL表示一个指示器的划分; (2) Cons,约束表达式的集合。 定义3 Cascade的输出模型 表示为{ 1.4 类型树 为了方便将场景交互类型XML Schema类型与组合测试工具进行转换,需要对XML Schema类型建模。本文用树模型表示XML Schema类型,称为XML Schema类型树,简称类型树,在类型精化的过程中只需关注类型树边上的指示器约束信息。下面给出类型树及精化后类型树的定义。 定义4 XML Schema类型树定义为一个四元组: T= 其中,N是元素节点和控制节点的有穷集合,控制节点分为 sequence和choice两种。 r是树的根节点。 C是节点之间的指示器约束集合,本文涉及minOccurs、maxOccurs和choice三种指示器。其中指示器约束可以取以下约束中的一种或多种: (1) True; (2) (3) (4) E是边的有穷集合。边可以表示为e(m,c,n),其中c∈C,m∈N∪r,n∈N。 图2是图1中第一个交互中订单请求的XML Schema所对应的类型树。purchaseOrder是该类型树的根节点。purchaseOrder_sequence、coupon_choice和goods_sequence是控制节点,其他节点均为元素节点。每一条边上都有一种或多种指示器约束。例如边e1对应的约束c1 图2 订单类型树 2.1 XML Schema类型精化过程 如图3所示,是XML Schema类型精化的过程,包括四部分内容。 图3 XML Schema类型精化过程 (1) 从场景中抽取XML Schema及卫士信息(Guard), 通过分析文件中的XML Schema,提取指示器信息,生成相应的类型树模型。 (2) 对解析生成的XML Schema类型树调用treeToCascade算法遍历类型树边上的约束信息,生成Cascade组合测试工具的输入模型。 (3) 通过Cascade的组合,得到一组输出数据,每一组数据代表类型树约束信息的确定取值,即Cascade的输出模型。 (4) 对输出的每组数据调用toTrees算法生成一个精化的类型树,得到一组精化的类型树集合。精化后的类型树中每个指示器信息都为确定值。 2.2 treeToCascade算法 treeToCascade算法是以类型树模型为输入,通过遍历边上的指示器信息,将其自动转化为Cascade的输入数据VL对和相应的约束Cons。 1) 算法思路 遍历边的过程中: (1) 当遇到 (2) 当遇到 (3) 当choice节点的入度边有 对于choice节点可出现多次的情况,为choice节点增加额外的信息记录其子节点出现的次序。同时引入新的组合变量即VL对,来表示choice节点每一次的子节点选择。设choice节点的minOccurs为k1,maxOccurs为k2,且拥有的子节点为C1、C2、C3、C4。则引入的VL对如表2所示。 表2 choice出现多次的VL对 第一列表示的是choice节点的出现次数,剩下分别表示第i次choice子节点的选择。为了减少无效组合数,同时为蕴含式集和Cons添加新的约束集: {choice=k ##(choicep) | k1<=k, k 若组合中choice节点出现次数取p,那么讨论第p+1次choice节点的子节点显然是没有意义的。其中##(choicep)表示变量choicep不参与组合,是为了在实际组合用例的生成过程中去除无效VL对的影响,减少无效组合数量。 (4) 当一个节点的入度边有 {choice1!=C &&…&& choicek2!=C → C=0|C∈L(choice)} 如果每一次choice子节点的选择都没有出现C,那么C节点置为0。 2) 辅助函数 treeToCascade算法中用到的辅助函数有: (1) addVL(V,k1,k2)的输入为变量V、指示器minOccurs的值k1和maxOccurs的值k2。如果k1==k2,则L={k1};如果k2==unbounded,则L={k1,k1+1};否则L={k1,k2,mid(k1,k2)},将该VL对加入到Cinput的{(V,L)}集合中。 (2) addVLs(m,j,L)的输入为该边的父节点、父节点入度边maxOccurs指示器的值j和水平V。该函数的功能是将(m1,L) 、…、(mj,L)组(V,L)对加入到Cinput的{(V,L)}集合中。如果变量V已经存在,将L的值并到V的水平中。 (3) addCon(con)的输入为一条约束信息con,功能是将con约束加入Cinput中的{Cons}集合中。 (4) getL(V)的功能是返回Cinput中变量V的水平,setL(V,L)是将Cinput中变量V设置为L。 3) 算法伪码 treeToCascade算法 输入:类型树T,场景中的卫式信息(Guard) 输出:Cinput={(Vi,Li)|i=1,2,3,...,n} ∪{Cons} 1 Cinput= ∅ 2 foreach e(m,c,n) ∈ T.E && c≠True do 3 if c== 4 addVL(n, k1, k2) 5 if n is the node with choice then 6 addCon({n=k ##(np)| k1<=k, k 7 if c== 8 if m.fatherEdge.c== 9 addVLs(m,k2,b) 10 else 11 addVL(m,b) 12 if c== 13 addVL(n, k1, k2) 14 if m.fatherEdge.c== 15 addVLs(m,k2’ , b) 16 addCon({m1!=C &&...&& mk2’!=C → C=0 |C∈L(cho)}) 17 else 18 addVL(m,b) 19 if n.guard != null then 20 e’=e 21 foreach m’ != root do 22 if c’== 23 setL(n’,getL(n)>0) 24 if c’== 25 setL(m’, b) 26 if c’== 27 setL(n’,getL(n)>0) 28 setL(m’, b) 29 m’=m’.father 30 return Cinput 算法中,第3-6行处理了类型树边上的约束c为 第7-11行处理了c为 第12-18行处理了c为 第19-29行处理Guard约束标记的节点。卫式信息(Guard)来自编排规范,在场景抽取的过程中,每一个交互都带有一个卫式作为前置约束条件,对本次交互变量数据的全部或部分片段取值进行约束。当n节点含有卫式标记时,生成测试数据时,要保证该节点一定存在。表现为: (1) 当root节点到该节点的路径中,遇到choice指示器时choice=此边的节点; (2) 当root节点到该节点的路径中,遇到occurrence指示器时,此边的孩子节点occurrence>0。 4) 算法时间复杂度 依据算法的设计,算法的时间复杂度主要体现在遍历类型树的边以及当节点含有卫式信息时要回溯到根节点处理相应的指示器上。当类型树边的数量为n, 则遍历类型树边的时间复杂度为O(n),设有m个节点含有卫式信息,含卫式信息的节点到根节点的平均距离为p,这里的距离是指节点到根节点之间的边树,则treeToCascade算法的时间复杂度为O(n)+mO(p)。 2.3 toTrees算法 通过输入Cascade的变量、水平及约束,工具可以输出变量的组合(称为组合覆盖数组),表示为Coutput:{ toTrees(T,a)算法中,a是Coutput中的一种组合,T是原来的类型树模型集合。算法的输出为精化后的类型树集合。反复调用toTrees(T,a)算法处理Coutput中的每一条记录,将得到每一种组合情况对应的子类型。 算法用到的辅助函数有: 1) getVar(T,l)的输入为类型树T和水平中的某个值l,返回一个变量,这个变量的水平包含l且对应的节点在类型树T中。 2) add(V,T)的输入为变量V和类型树T,功能是添加变量V在T中对应的节点及所有的子孙。 3) delete(V, T)的输入为变量V和类型树T,功能是删除变量V在T中对应的节点及其所有的子孙。 4) changeConstraint(y, c, V, T)的功能是改变特定边上的约束为c,这条边的父节点是y,子节点是变量V在类型树T上对应的节点。 toTrees算法 输入:类型树T, a= 输出:精化类型树集合T’s 1 T’s= ∅ 2 T’=T 3 foreach li in a do 4 Vi=getVar(T’,li) 5 if Vi is a choice node && !isNode(li) then 6 for i=1to li 7 Vi.father.add(Vi, T’) 8 name=getName(Vi) 9 changeName(Vi,name+”i”) 10 delete(Vi,T’) 11 else if isNode(li) then 12 foreach n in Vi.childrenlist do 13 if n!=li then delete(n, T’) 14 else if li==0 then delete(Vi, T’) 15 else if li==”#” continue 16 else 17 y=Vi.father 18 c= 19 changeConstraint(y, c, Vi, T’) 20 T’s=T’s∪{T’} 21 return T’s 算法中第5-10行是处理choice节点可出现多次的情况,首先获取choice子节点数量n,根据子节点的数量,对该choice节点进行n次拷贝,这里的拷贝是指递归的对子节点及其孩子信息进行深度的拷贝。 第11-13行处理li对应一个节点的值的情况,说明该li对应的变量为一个choice节点,删除该choice节点除li对应的子节点外的其他孩子节点。 第14-15行是指当li==0时,代表li对应的节点出现次数为0,删除该节点。当li==”#”,代表该li无效,不做任何处理。 第19-21行表示将li所对应节点的入度边的约束改为 3.1 订单类型树的Cascade输入模型 图2所示的订单类型树,调用treeToCascade算法后,可以得到表3所示的变量及水平。 表3中,共有6个参数及水平,2个约束表达式,其中coupon_choice == ″1″ ##(coupon_choice2) 表示当参数coupon_choice取值为1时,参数coupon_choice2则不参与组合,coupon_choice1!= ″cashback″ && coupon_choice2!= ″cashback″ -> cashback == ″0″表示当coupon_choice1和coupon_choice2都不为cashback,则将cashback 的值置为0。强度设置为2,可以手动添加。 表3 订单类型的Cascade的输入 3.2 Cascade的输出模型 通过Cascade的组合,表3中Cascade输入模型会转化为表4中的Cascade的输出。每一行代表一组Cascade输入变量的值的组合。表3中6个变量产生了9组值的组合。 例如第1行表示,coupon取值为0,coupon_choice取值为2,coupon_choice1取值为discount,coupon_choice2取值为discount,cashback取值为0,goods取值为2。 3.3 精化后的类型树 对每一条Cascade的输出调用toTrees算法后,会产生一组相应的精化后的类型树。如图4所示,表示表6中第4条输出调用toTrees算法后得到精化的类型树。coupon节点的入度边上的指示器信息为minOccurs=1&&maxOccurs=1,代表coupon节点只出现一次;coupon_choice为1代表coupon_choice指示器只出现一次,由conpon_choice1表示;coupon_choice1值为discount;goods入度边上的指示器信息为minOccurs=2&&maxOccurs=2,代表goods出现的次数确定为2。 通过实例分析可得,每一颗精化后的类型树的指示器信息都是确定的。在没有借助Cascade组合测试工具时,订单请求的XML Schema类型通过划分和全排列的组合,会产生96组子类型,并且会产生一些无效的组合,例如当coupon_choice选择1时,讨论coupon_choice2变量的组合没有意义。在Cascade组合测试工具的帮助下,得到了9组子类型并覆盖了所有需要被组合的变量的取值。 图4 精化后的类型树 利用组合测试的思想实现XML Schema的类型精化,不仅可以减少精化后的类型树的数量,从而极大地减少测试数据的数量,降低了测试代价;同时提高了测试数据生成的可控性。为测试数据的生成及相符性测试奠定了重要的基础。 国内外关于Web服务组合测试的工作有很多。Zhou等[12]采用动态符号执行的方法产生测试的输入和断言从而进行WS-CDL的测试。Tsai等[13]从服务请求者和UDDI服务中介两个角度考虑Web服务的测试,提出了一种使用多层次场景描述的方法来描述系统行为。张大勇等[14]着眼于Web服务的的交互以及交互之间对Web服务行为的影响对Web服务进行测试。Bravetti等[15]提出了一个有效的方法验证包含了给定合约的服务是否可以在编排中正确地扮演自己的角色,这个过程是通过编排的组合与合约的精化实现的。 基于编排的测试工作主要包括:Besson等[16]开发了一个测试框架来支持测试驱动的编排开发。Nguyen等[17]提出了基于编排的消极的相符性测试框架。本研究组采用积极测试,并从编排中对控制流进行抽取生成编排场景进行相符性测试。 诸多关于测试数据生成的工作涉及到XML Schema以及XML Schema指示器的划分。Li等[18]扩展了适用于XML Schema常规改变的方法并提出了分析改变后XML Schema的语义正确性的技术。Bai等[19]将WSDL解析成结构化的DOM树,通过分析标准XML Schema语法来生成测试数据。Xu等[20]考虑了Web服务交互中的XML Schema信息,提出基于扰动算子对XML Schema进行修改和实例化,进而测试基于XML的通信应用。Bulbul等[21]基于给定的数据定义实现了测试数据自动生成系统。Bertolino等[22]去掉XML Schema中不影响结构的属性,根据XML-Schema的指示器进行等价划分,本文的思路与其类似,但是利用了组合测试用例的生成技术,控制了测试用例的数量,降低了测试代价,并且在指示器的复合问题上考虑得更为详细。Cohen等解释了数学组合理论以及多个因素下,几个因素值域覆盖的理论[23]。王子元等说明了组合测试用例生成技术,并解释了组合测试的覆盖标准[24]。 测试数据的生成为编排与web服务组合的相符性测试提供了基础。XML Schema类型精化是测试数据生成过程中必不可少的部分。本文主要研究编排场景消息交互的XML Schema类型精化: (1) 在测试数据生成过程中,XML Schema指示器的存在为测试数据的生成增加了难度,本文提出了类型精化的概念。即通过指示器的划分和组合,产生一组类型确定的精化后的类型树。 (2) 在指示器的组合过程中,为了避免组合数量爆炸,造成测试代价过高。本文采用的组合的测试思想,在保证覆盖率的情况下,极大的减少组合数量。 (3) 由于组合的过程中需要用到组合测试工具Cascade,本文提出了treeToCascade算法和toTrees算法完成类型树到Cascade工具输入模型和Cascade输出模型到精化后的类型树之间的转换。并在转换过程中,考虑到指示器的各种情况,旨在可以处理任何指示器的复合情况,覆盖更多的子类型,并通过蕴含式减少无用的组合数据。 本文的进一步工作主要围绕通过精化后的类型树产生测试数据集。通过相应的数据集生成规则为精化后的类型树的叶子结点产生测试数据,并在测试数据生成过程中提取场景中的卫式信息对叶子结点进行标记,以满足交互序列执行的条件。在得到一组测试数据集后,基于编排场景对Web服务组合进行相符性测试。 [1] Salauün G, Bultan T, Roohi N. Realizability of choreographies using process algebra encodings[J].IEEE Transactions on Services Computing, 2012, 5(3):290-304. [2] Pi4SOA[OL]. http://www.pi4soa.org. [3] Salauün G, Roohi N. On realizability and dynamic reconfiguration of choreographies[C]//Proceedings of WASELF’09, 2009. [4] Bozkurt M, Harman M, Hassoun Y. Testing web services: a survey: TR-10-01[R]. Technical Report of King’s College London, 2010. [5] 周亮. 基于编排规范的Web服务相符性测试[D]. 北京:北京工业大学, 2011. [6] 邓晨. Web服务编排的场景研究[D]. 北京:北京工业大学, 2012. [7] Yang H, Ma K, Deng C, et al. Towards conformance testing of choreography based on scenario[C]//Proceedings of the 2013 International Symposium on Theoretical Aspects of Software Engineering. IEEE Computer Society, 2013:59-62. [8] Ma K, Wang J, Yang H, et al. Choreography scenario-based test data generation[C]//2014 Theoretical Aspects of Software Engineering Conference (TASE). IEEE Computer Society, 2014:70-73. [9] 马凯. 基于编排场景的Web服务相符性测试[D]. 北京:北京工业大学, 2014. [10] XML Schema教程[OL]. http://www.w3school.com.cn/schema/index.asp. [11] Cascade: CAS Covering Array DEsigner[OL]. http://lcs.ios.ac.cn/zhangzq/cTtoolkit.html. [12] Zhou L, Ping J, Xiao H, et al. Automatically testing web services choreography with assertions[C]//Proceedings of the 12th International Conference on Formal Engineering Methods and Software Engineering. Springer, 2010:138-154. [13] Tsai W T, Paul R, Yu L, et al. Scenario-based web services testing with distributed agents[J]. IEICE Transactions on Information and Systems, 2003, 86(10):2130-2144. [14] 张大勇, 黄宁, 余莹, 等. Web服务交互测试中SOAP消息的控制和分析[J]. 计算机与数字工程, 2005, 33(9):10-14. [15] Bravetti M, Zavattaro G. Towards a unifying theory for choreography conformance and contract compliance[C]//Proceedings of the 6th International Conference on Software Composition. Springer, 2007:34-50. [16] Besson F M, Leal P M B, Kon F, et al. Towards automated testing of web service choreographies[C]//Proceedings of the 6th International Workshop on Automation of Software Test, 2011:109-110. [17] Nguyen H N, Poizat P, Zaïdi F. Passive conformance testing of service choreographies[C]//Proceedings of the 27th Annual ACM Symposium on Applied Computing, 2012:1528-1535. [18] Li J B, Miller J. Testing the semantics of W3C XML schema[C]//29th Annual International Conference on Computer Software and Applications. IEEE, 2005:443-448. [19] Bai X, Dong W, Tsai W T, et al. WSDL-based automatic test case generation for web services testing[C]//2005 IEEE International Workshop on Service-Oriented System Engineering. IEEE, 2005:207-212. [20] Xu W, Offutt J, Luo J. Testing web services by XML perturbation[C]//Proceedings of the 16th IEEE International Symposium on Software Reliability Engineering. Washington, DC, USA: IEEE Computer Society, 2005:257-266. [21] Bulbul H I, Bakir T. XML-based automatic test data generation[J]. Computing & Informatics, 2008, 27:681-698. [22] Bertolino A, Gao J, Marchetti E, et al. Automatic test data generation for XML schema-based partition testing[C]//Second International Workshop on Automation and Software Test. IEEE Computer Society, 2007:4. [23] Cohen D M, Dalal S R, Fredman M L, et al. The AETG system: an approach to testing based on combinatorial design[J]. IEEE Transactions on Software Engineering, 1997, 23(7):437-444. [24] 王子元, 徐宝文, 聂长海. 组合测试用例生成技术[J]. 计算机科学与探索, 2008, 2(6):571-588. THE REFINEMENT OF XML SCHEMA TYPE OF WEB SERVICES ARRANGEMENT SCENE Wang Jin Ma Kai Yang Hongli (CollegeofComputerScience,BeijingUniversityofTechnology,Beijing100124,China) Web Services arrangement specifies the interaction among multiple Web services. In the actual development, interactive data type and interactive sequence may not be consistent with arrangement standard. It needs to generate the test data to check the conformance of the implementation with reference to the arrangement standard. Since arrangement scene describes the interactions sequence of each participant and the XML Schema type of its interaction information, the test data can be generated by the XML Schema. The indicators in XML Schema type lead to the uncertainty of the data type, so the method of the XML Schema type refinement is proposed to solve the problem based on combined test. By defining the XML Schema type tree and presenting the type tree refinement algorithm based on the combinatorial tool Cascade, the effectiveness is proved by examples. Web Services arrangement XML Schema Indicator Type refinement Combined test 2015-12-24。王瑾,硕士,主研领域:Web服务编排。马凯,硕士。杨红丽,副教授。 TP3 A 10.3969/j.issn.1000-386x.2017.02.005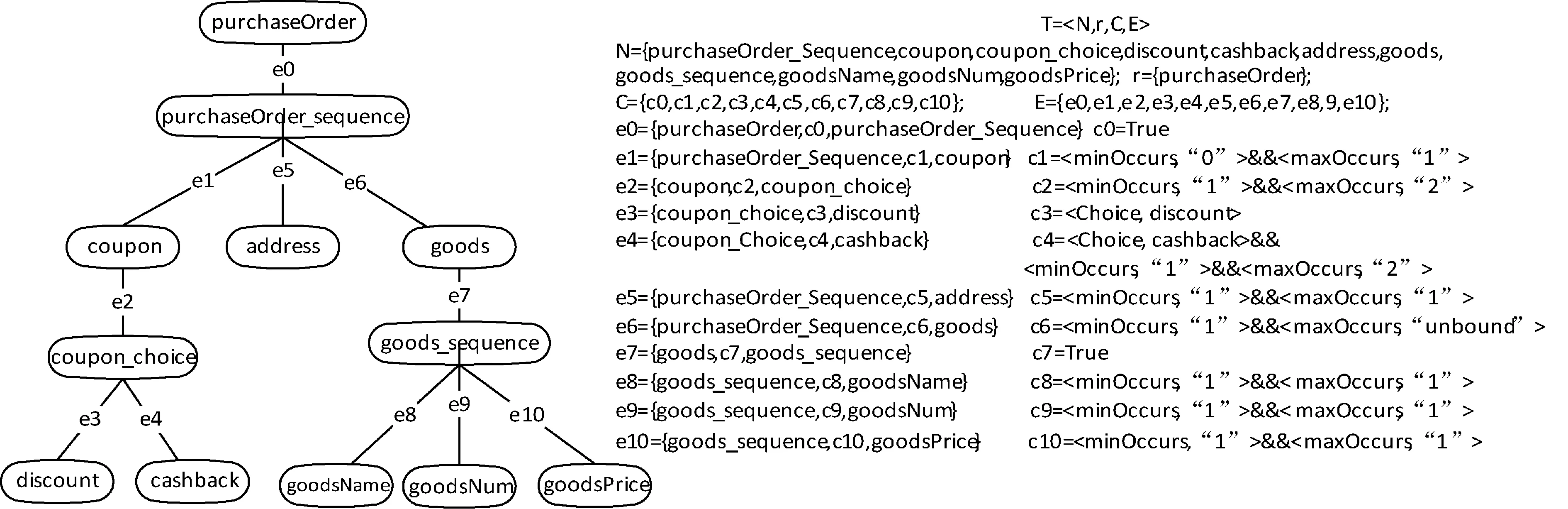
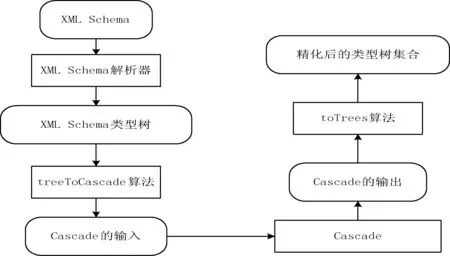
2 XML Schema类型精化算法

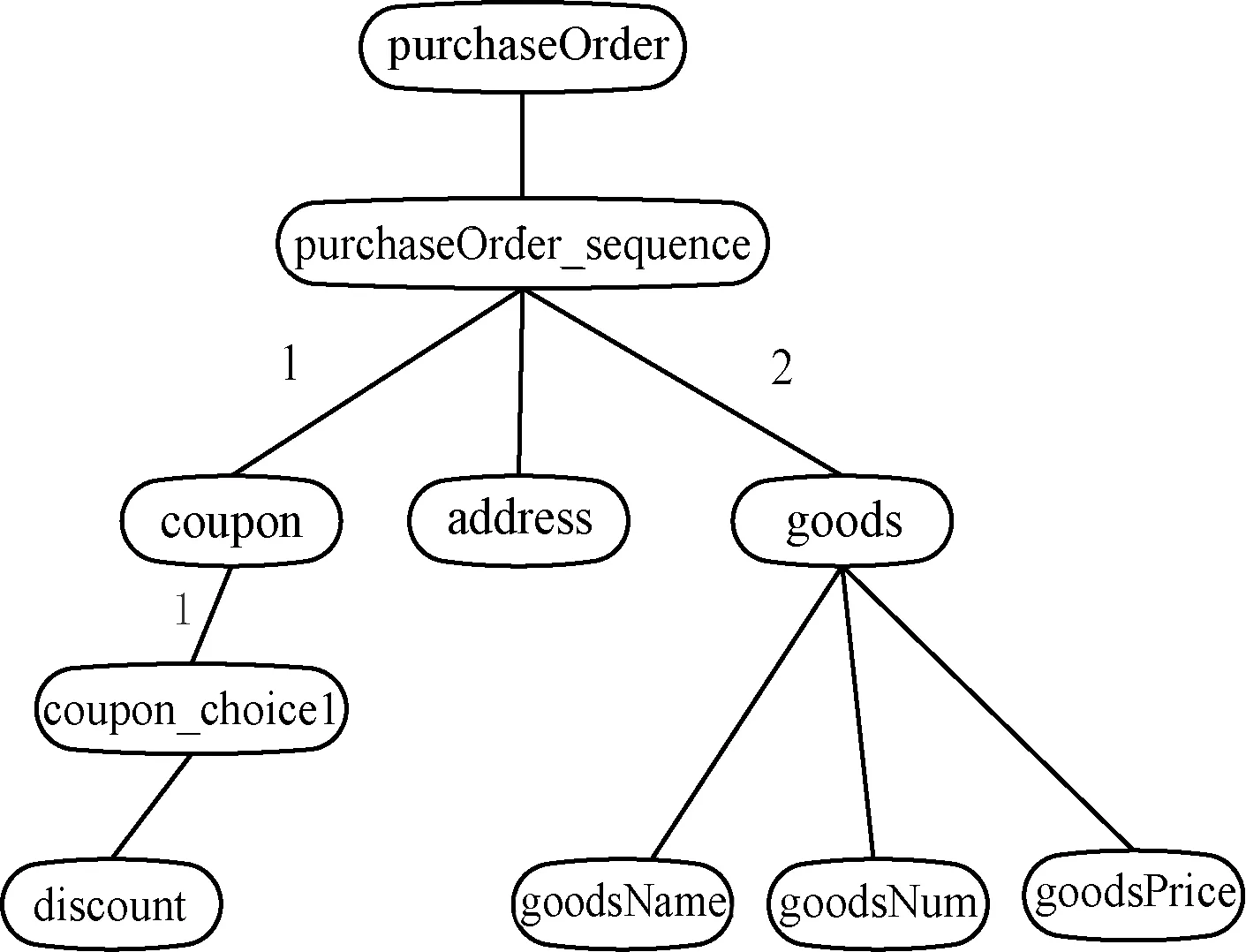
3 XML Schema类型精化实例

4 相关工作
5 结 语
猜你喜欢
包装工程(2022年9期)2022-05-14环球时报(2021-07-13)2021-07-13科学与财富(2018年30期)2018-12-28小学阅读指南·低年级版(2017年1期)2017-03-13企业技术开发·下旬刊(2016年11期)2016-12-27计算机应用(2016年9期)2016-11-01体育科技(2016年2期)2016-02-28中国新技术新产品(2015年9期)2015-07-18人生十六七(2015年6期)2015-02-28计算机辅助工程(2012年5期)2012-11-21
