
基于深度学习手写字符的特征抽取方法研究
2017-02-27 03:11刘兴旺
软件 2017年1期
邹 煜,刘兴旺
(中南民族大学 计算机科学学院,武汉 430074)
基于深度学习手写字符的特征抽取方法研究
邹 煜,刘兴旺
(中南民族大学 计算机科学学院,武汉 430074)
当前对深度学习单层训练算法的研究工作较少,本文采用数据量、隐层节点和感受野大小,分析自动编码器和K-means算法在训练深度网络抽取特征上的表现。发现自动编码器对数据量,隐层节点敏感,且学习率与数据量和感受野呈负相关;数据量一定后,K-means对数据量不敏感,且感受野大小的选取对该算法发挥性能至关重要。在实际应用中给自动编码器加入稀疏性控制是必要的。实验结果表明,本文的研究工作,对用自动编码器或K-means训练深度网络有一定的参考借鉴意义。
深度学习;K-means;自动编码器;感受野;数据量;隐层节点
本文著录格式:邹 煜,刘兴旺. 基于深度学习手写字符的特征抽取方法研究[J]. 软件,2017,38(1):23-28
0 引言
当下,人工智能已经是科技领域内研究的热点,深度学习(Deep Learing,DL)更是人工智能技术中最具代表性的技术之一。引起了学术界与产业、工业界的广泛关注。深度学习是由传统的神经网络发展而来的,但是又不仅仅是传统网络的简单继承。深度学习的概念最早由多伦多大学的GE.Hinton等人于2006年提出,指基于样本数据通过一定的训练方法得到包含多个层级的深度网络结构的机器学习过程。传统的神经网络随机初始化网络中的权值,导致网络很容易收敛到局部最小值,为解决这一问题,Hinton提出使用无监督预训练方法优化网络权值的初值,再进行权值微调的方法,拉开了深度学习的序幕[1]。
在图像识别领域深度学习也有广泛的应用,利用深度学习模型得到图像标注信息,主要是利用了图像间的视觉相似性,选用高层视觉特征作为深度神经网络的输入信息。可以对一些模糊的特征做分类,这是一个非常有前瞻意义的研究[2]。我国对深度学习的研究起步较晚,学习者批判性地学习新思想和新知识,将它们与原有的认知结构相融合,将众多思想相互关联,将已有的知识迁移到新的情境中去,做出决策并解决问题的学习。此后国内开展了一系列针对深度学习的相关学术研究[3]。深度学习的主要目的是训练模型,使学习模型在满足一定精度要求的前提下具有最简单的网络结构。并且在这一网络结构的基础上去测试样本[4]。图像领域的研究是深度学习最早进行尝试的应用领域,面对一幅图像,其像素级的特征几乎没什么实用价值,人体视觉系统对图像信息的处理就是从低级的颜色、边缘等特征到实体形状或者再到更高层的人类理解层级,即将底层特征组合理解获得图像高级特征。而深度学习在图像领域的应用过程就是模拟这个人类视觉系统对图像内容进行理解建模的过程[5]。基于深度学习理论的神经网络模型能够很好的应用于中文命名实体识别任务。以该模型为核心建立的中文命名实体识别系统具有良好的健壮性和可维护性,能够满足大数据背景下中文命名实体识别的新需求[6]。深度学习模型己广泛应用于计算机视觉、语音识别机器翻译和语义挖掘等领域,而流数据变得越来越多,因此深度学习模型不得不对及时更新的流数据进行学习。如果把流数据放入原始的训练数据集,重新对原始数据集进行学习,随着流数据的加入越来越多,模型对数据学习所花费的时间将变得越来越长,就可能导致训练模型所投入的成本大于模型对数据学习的收益的恶性循环。一种有效的解决方案是增量学习或在线学习[7]。由于深度学习在训练过程后,它的结果是以一种模型文件显示的,对于特定的分类需求中的特征提取能够提升准确率[8[9]。
虽然深度学习方法在众多方面取得了不少研究成果,但有关深度学习的单层训练算法的研究工作较少,进展缓慢。本文在几种规模的数据集上开展实验,探讨深度神经网络的单层训练中特征抽取方法。通过调整图像块的大小和隐层节点的数量,针对自动编码器方法和K-means算法在不同训练参数情况下,分析它们提取图像样本数据特征的表达性能。
1 自动编码器算法
自动编码器多用于堆叠构件深度网络,一般是逐层预训练,最后通过反向微调机制来微调整个网络。
将高维的数据用低维信息予以表示,是自动编码器的特点。它是一个三层的网络结构,包含输入层、隐藏层各输出层。图1所示为其网络结构。其中输入与输出均有n个节点,图中1为偏置项。

图1 自动编码器网络结构示意图Fig.1 AutoEncoder network structure
其中,网络的输入表示为x=(x1,x2,…,xn),输出表示为y=(y1,y2,…,yn)。自动编码器的全局代价函数如公式(1)所示,单次代价函数如公式(2)所示。其中,K为输入样本数,n为输入维度,xi j,表示样本i的第j个分量,yi j,表示样本i对应输出的第j个分量。

采用梯度下降算法训练网络,输出层权值更新如公式(7)所示,隐藏层权值更新如公式(10)所示,算法迭代推导过程见公式(3)~(7)。

同理利用链式求导法则可得隐层权值更新算法,见公式(8)~(10)。


O表示输出层,H表示隐层,hi表示隐藏层第i个节点的输出,Io k表示输出层第k个节点的累计输出,IH i表示隐含层第i个节点的累计输出,f为sigmod函数,δo k表示输出层第k节点的残差,δH i表示隐含层第i个节点的残差。WO表示输出层节点的权值,WH表示隐层节点的权值,η表示学习率。
经过迭代训练得到隐层权值WH后,用样本x与它做内积运算,便得到了样本x的特征表示。这种特征映射的方法比K-means算法的特征映射要简单,但训练映射字典的复杂度和时间开销超过K-means算法。
2 改进的K-means算法
K-mean聚类算法自诞生起就在人工智能领域受到青睐,它的算法思想通俗易懂,且算法计算速度也非常快,是一种无监督学习算法。该方法假定将某个数据集划分成k个聚簇,簇中心用该簇中所有数据的均值计算得到,定义它的误差函数如式(11)所示。当J的值最小或不再变化时,认为聚类过程完成,簇中心的迭代计算见公式(12)所示。算法的学习目标是使得J最小化。u=(u1,u2,…,uk,…),其中,当xn属于uk簇时,tnk取值为1;否则,取值为0,uk为簇k的均值,即簇中心,M为第k个簇中样本的数量,N为样本数。
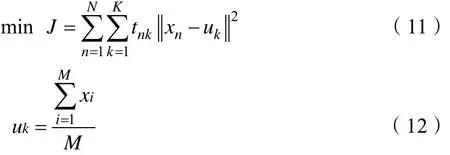
然后,由于K-means算法的初始化是随机值,有可能造成空聚类的等问题。本文提出一种改进的K-means聚类方法,算法描述见算法1所示。其中,xi表示样本i,T表示对向量或矩阵做转置,X=(x1,x2,…,xn)表示所有样本,s表示X在u下的一个映射,si k表示样本i在u下映射的第k个分量。
算法1一种改进的K-means聚类算法


经过训练得到字典u之后,进行特征映射。对字典u的一次映射,要求仅有少量类簇被激活。映射方式见公式(13)所示,其中Feature(x)k表示样本x特征的第k个分量,md表示样本x到各个类中心的平均距离,uk是K-means算法训练得到的簇k的均值。这种映射保证了K-means算法抽取的特征的稀疏性,且综合考虑了样本以某概率属于某个聚簇。K-means通过这种方式计算得到的特征的稀疏性,要比普通的自动编码器得到的特征的稀疏性高。见下文的实验分析。

3 实验及结果分析
3.1 数据准备及预处理
本文实验的数据集采用minist手写数字数据库,从60000个训练样本中,在随机位置选取不同像素尺寸大小的图块,共生成6批数据,分别是:(1)4*4像素图像,40000张;(2)4*4像素图像,80000张;(3)8*8像素图像,40000张;(4)8*8像素图像,80000张;(5)16*16像素图像,40000张(6)16*16像素图像,80000张。
在开展实验之前,分别将这些样本数据进行归一化处理,使得样本的均值为0,方差为1。归一化处理见公式(14)所示,std()表示求标准差,x为样本,xmean为样本均值。

3.2 样本数量大小的影响分析
样本数量的大小关系到特征抽取字典是否丰富,是获得较好实验结果的重要前提之一。在讨论样本数量大小对特征抽取字典的影响时,实验选取2批数据,它们的图像块大小固定为8*8像素,样本数量分为40000个和80000个。从实验对比结果分析,发现当样本数量增长一倍时,对K-means算法的影响较弱,而对自动编码器方法影响较大,见图2和图3所示,标号8-40000-48表示8*8像素图块,样本数量40000个,且隐层节点为48个,以下其他图中标号含义类似。在图3中,误差值随着样本数量的增加而逐步减小,结果表明经过训练得到的特征字典更加丰富。

图2 自动编码器的特征字典变化分析Fig.2 The Features dictionary changing analysis of AutoEncoder

图3 K-means的特征字典变化分析Fig.3 The Features dictionary changing analysis of K-means
3.3 感受野大小的影响分析
感受野是人眼观察一副图像时,每次抓取多大的局部像素,不同大小的图像的感受野不一样。考察感受野对特征抽取字典的影响时,实验选取3批数据,固定它们的样本数量为80000个,感受野的大小依次从4*4像素到8*8像素,再到16*16像素。从模型训练的复杂度角度来说,图块大小增加时,自动编码器训练的复杂度会大大增大,如图4所示。但是图块太小,模型学习不能获得特征。当图块大小为16*16像素时,实验结果不理想,如图5所示,一个重要原因是特征的稀疏性不高。对于K-means来说,图块训练结果分析如下:当图块太小时,没有学习到边缘,见图6所示;当图块太大时,已经学习到了具体数字,见图7所示,这都不是理想的实验结果。针对本文的实验数据,图块大小保持在8*8像素,相差不到2个单位量是合适的,见图8,学习获得不同的边缘,从而可以用学习得到的这些边缘进行特征抽取。

图4 自动编码器感受野大小分析Fig.4 Patch size analysis of AutoEncoder

图5 自动编码器16*16图块学习结果Fig.5 AutoEncoder's learning result about 16*16 patch

图6 K-means4*4图块学习结果Fig.6 K-means's learning result about 4*4

图7 K-means16*16图块学习结果Fig.7 K-means's learning result about 16*16 patch

图8 K-means 8*8图块学习结果Fig.8 K-means's learning result about 8*8 patch
3.4 隐层节点数量影响分析
隐层节点的数量多少决定了抽取特征的维度,隐层的节点数量是自动编码器的隐层节点数和K-means的k的选择。实验固定样本数据为图块8*8像素大小,样本数量80000个。隐层节点数考虑40、48和56三种情况。实验结果分析,见图9和图10所示,从这两个结果图中,可以看到两种算法的相同之处,增大隐层节点数量可降低误差,当考虑到数据抽象和降维要求时,应该在低维度表示和低误差之间选取合理的平衡点。

图9 自动编码器的隐层节点数量分析Fig.9 AutoEncoder hidden layer node analysis

图10 K-means算法的k值分析Fig.10 Analysis of the value of K about K-means
3.5 实验结果
样本特征抽取的表达效果直接与误差或平均最小距离相关。实验通过参数调节,讨论分析特征抽取的成效,实验结果见表1、表2所示,其中,第1列X-Y表示感受野为X*X大小、数据量为Y条。在表1中,第2与第4行表明数据量与学习率呈负相关,与误差呈正相关。在表1,第3、第4和第5行,表明隐层节点与误差呈负相关,且相关性较强。在表1中,第1与第4行表明当感受野快速变大,误差快速变大,训练难度增加,两者相关性强。
在表2中,根据第2与第4行结果,可知当数据量到达一定数量时,再增加数据量对该算法影响波动较小;第3、4和5行结果数据可知K值与平均最小距离呈负相关,平均最小距离随K值波动不大,表明该算法稳定性较好;第1与第4列数据表明感受野与平均最小距离呈正相关,且相关性强。
对比分析表1的第2和第4行与表2的第2和第4行的数据结果,可以发现自动编码器方法对数据量的敏感度要高于K-means值算法;通过表1与表2的第3、4和5行对比分析可知,自动编码器对隐层节点的数量的敏感度也要高于K-means;通过表1和表2的结果对比分析,可知二者对感受野都极为敏感。

表1 自动编码器结果Table 1 The result of AutoEncoder

表2 K-means结果Table 2 The result of K-means
4 结语
本文通过分析样本数量、感受野大小和隐层节点数等3种因素对自动编码器方法和K-means算法在特征学习方面的性能影响,发现K-means算法比自动编码器更容易训练。同时,通过本实验数据评估了两种算法各自的适用性。实验结果表明,对于自动编码器,样数量和感受野大小均与学习率成负相关,且较好好的特征抽取与较低的错误率相关,在实际应用中,给自动编码器加入稀疏性控制,往往能取得更好的结果。
[1] 尹宝才, 王文通, 王立春. 深度学习研究综述[J]. 北京工业大学学报, 2015, 01∶ 48-59.
[2] 杨阳, 张文生. 基于深度学习的图像自动标注算法[J]. 数据采集与处理, 2015, 01∶ 88-98.
[3] 樊雅琴,王炳皓,王伟,唐烨伟. 深度学习国内研究综述[J].中国远程教育, 2015, 06∶ 27-33+79.
[4] 陈珍, 夏靖波, 柏骏, 徐敏. 基于进化深度学习的特征提取算法[J]. 计算机科学, 2015, 11∶ 288-292.
[5] 杨宇. 基于深度学习特征的图像推荐系统[D]. 电子科技大学, 2015.
[6] 王国昱. 基于深度学习的中文命名实体识别研究[D]. 北京工业大学, 2015.
[7] 岳永鹏. 深度无监督学习算法研究[D]. 西南石油大学, 2015.
[8] 万维. 基于深度学习的目标检测算法研究及应用[D]. 电子科技大学, 2015.
[9] 王茜, 张海仙. 深度学习框架Caffe在图像分类中的应用[J].现代计算机(专业版), 2016, 05∶ 72-75+80.
[10] 赵鹏, 王斐, 刘慧婷, 姚晟. 基于深度学习的手绘草图识别[J]. 四川大学学报(工程科学版), 2016, 03∶ 94-99.
[11] 金连文, 钟卓耀, 杨钊, 杨维信, 谢泽澄, 孙俊. 深度学习在手写汉字识别中的应用综述[J]. 自动化学报, 2016, 08∶1125-1141.
[12] Mahmood Yousefi-Azar, Len Hamey, Text summarization using unsupervised deep learning, Expert Systems with Applications, Volume 68, February 2017, Pages 93-105, ISSN 0957-4174, Keywords∶ Deep Learning; Query-oriented Summarization; Extractive Summarization; Ensemble Noisy Auto-Encoder.
[13] Zhong Yin, Jianhua Zhang, Cross-session classification of mental workload levels using EEG and an adaptive deep learning model, Biomedical Signal Processing and Control, Volume 33, March 2017, Pages 30-47, ISSN 1746-8094.
Research of Feature Extraction Method for Offline Handwritten Character Based on Deep Learning
ZOU Yu, LIU Xing-wang
(College of Computer Science, South-Central University for Nationalities, Wuhan 430074)
In currently, there are few studies of monolayer training algorithms about deep learning. In this paper, We analyze the performance of the AutoEncoder and K-means in training deep network and feature extraction on three points∶data volume, hidden layer nodes and receptive field. We find that automatic encoder is sensitive to data volume and hidden layer nodes,and learning rate has a negative correlation with data volume and receptive field. After a certain amount of data, K-means is not sensitive to data volume, so select receptive field size plays a crucial performance for the algorithm. In practice, added sparsity control into AutoEncoder is necessary. Experimental results shows that studies of this paper has reference value for training deep network with AutoEncoder or K-means.
Deep learning; K-means; AutoEncoder; Receptive field; Data volume; Hidden layer nodes
TP391.43
A
10.3969/j.issn.1003-6970.2017.01.006
国家自然科学基金资助项目(60975021,女书规范化及识别技术研究)
邹煜(1985-),男(通信作者),硕士研究生,研究方向为人工智能与模式识别;刘兴旺(1991-),男,硕士研究生,研究方向为文字图像处理。
猜你喜欢
艺术家(2023年8期)2023-11-02
小哥白尼(军事科学)(2022年2期)2022-05-25
人民珠江(2019年4期)2019-04-20
成都信息工程大学学报(2018年3期)2018-08-29
电子设计工程(2017年20期)2017-02-10
电子器件(2015年5期)2015-12-29
计算机工程(2014年9期)2014-06-06
机械工程与自动化(2014年3期)2014-05-07
电测与仪表(2014年13期)2014-04-04
上海电机学院学报(2013年3期)2013-03-11
