
复杂网络搜索算法比较研究
2017-04-10 07:17阿布力米提·艾西丁
电脑知识与技术 2017年4期
关键词:复杂网络
阿布力米提·艾西丁

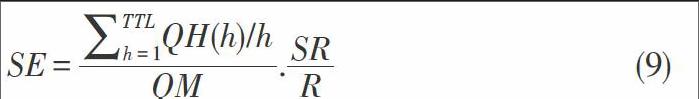

摘要:许多复杂网络中,单个节点无法充分掌握整个网络的全局信息与目标节点的具体位置。因为复杂网络具有不断变化的动态性,准确地确定网络的全局行为是非常困难的。一般在搜索算法中,我们从一个给定的源节点开始查询所需要的目标节点上的文件,按照某一种规则向源节点的某一个或是多个邻居节点发送查询消息,寻找符合目标状态节点的过程。搜索算法的有效性将直接影响到复杂网络的卓越性能。目前复杂搜索策略中有广度优先搜索算法(BFS)、最大度搜索算法(MD)与随机游走搜索算法(RW)等比较经典及常用的算法。除了这三种算法外,其他算法大都是由这三种算法改进而来。本文上述前三种搜索算法的性能进行逻辑分析与比较。
关键词:复杂网络;网络模型;网络特性
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2017)04-0169-02
许多复杂网络中,单个节点无法充分掌握整个网络的全局信息与目标节点的具体位置。因为复杂网络具有不断变化的动态性,准确地确定网络的全局行为是非常困难的。一般在搜索算法中,我们从一个给定的源节点开始查询所需要的目标节点上的文件,按照某一种规则向源节点的某一个或是多个邻居节点发送查询消息,寻找符合目标状态节点的过程。搜索算法的有效性将直接影响到复杂网络的卓越性能。鉴于搜索问题的重要地位和实际价值,人们会从不同的角度对搜索问题进行分析研究。我们在这里提出了一种新的基于幂律度分布的搜索算法DBM,它引用BFS与MD的各种优点进行搜索。DBM算法小范围引用BFS搜索算法,大范围引用MD搜索算法,更进一步基于知识进行搜索,提高搜索的效率。为了更可靠地分析并解释,我们选择无标度(BA)网络模型来验证DBM搜索算法的有效性与可行性。
1 逻辑分析
以下我们将对复杂网络中基本搜索方式广度优先搜索算法(BFS)与最大度搜索算法(MD)进行比较与分析。首先,BFS是一種经典的复杂网络基本搜索算法,它在Internet中获得了比较广泛的应用。事实上,复杂网络中的单个节点往往难以全面反映整个网络的信息,甚至无法明确复杂网络中目标节点的所在位置。在这种情况下我们可以应用的最简单地搜索策略就是广度优先搜索算法(BFS)。BFS搜索算法的工作原理如下:当源节点开始在复杂网络中寻找目标文件时,S先查询所有邻居节点,并向邻居阶段询问是否拥有目标文件,假设S的某个邻居节点上发现目标文件,目标节点即将目标文件反馈给源节点;假设S的邻居节点都不拥有目标文件,S的邻居节点则将查询信息向各自的邻居节点传递查询信息,直到发现目标节点和产讯到目标文件。广度优先搜索算法BFS示例如图1所示:
在图中没有搜索过的路径用虚线表示,已经搜索过的路径用实线表示。在这里我们根据最大度算法的搜索思路分析,在最大度搜索(MD)方式中,搜索过程如下:最大搜索策略的应用前提为每个节点都了解其邻居节点度。详细搜索流程为:源节点先查询其度最大的邻居节点,假设此邻居节点为目标节点,则将目标文件反馈回源节点,假设非目标节点,则继续挑选度最大的邻居节点查询,截止到发现目标节点[9]。在这种最大度搜索MD搜索方式中,虽然搜索效率一般,但其产生的搜索消息流量非常小。最大度搜索MD搜索算法过程示例如图2所示:
通过比较以上两种搜索方式,我们得到以下结论:选用广度优先搜索算法,可以得到比较小的搜索步数,即可以最快捷地搜索到目标节点,但是查询消息流量特别多。最大度搜索算法获得的查询消息流量比较小的,其搜索步数介于随机游走搜索(MD)和广度优先搜索(BFS)之间。随机游走搜索算法的查找速度最慢,而产生的查询信息流量在其他两种搜索策略之间。具体关系如表1所示:
表1 搜索算法比较
[搜索算法方式\&搜索步数\&查询消息流量\&广度最先搜索(BFS)\&最小\&最高\&最大度搜索(MD)\&中\&最小\&]
2 性能分析
2.1 无标度网络
我们把Newman的工作可总结为随机图。用[G0(x)]表示节点度[k]的分布母函数,[G0(x)]可以表达为:
在这里[pk]表示一个图里面随机选定度恰好为[k]的节点的概率,[m]是度的最大值。根据母函数,这里随机选择的节点的平均度可表达为:
为了解决准确测量与采样中的困难,我们在这里采用无标度网络模型。本文中,我们应用幂律图来评估搜索性能,如果幂律分布的随机图的度指数是[τ],[pk]跟[k-τ]是成正比,那么:
依照(4),可以得出以下近似幂律分布:
2.2 成功率[SR]
成功率[SR]是查询成功完成的概率,在这里至少有一个查询工作成功地完成。假设查询源用复制比[R]统一分配到整个网络,[SR]在这里[R]是复制比,[C]是覆盖率,这公式说明[SR]是依靠搜索算法的覆盖率。我们使用(8)获得的一个非常重要的性能指标是搜索时间[ST]。
2.3 搜索有效性[SE]
搜索有效性[SE]是搜索算法中提出的一个统一的性能指标,[SE]可以定义为:在这里[QH(h)]是在第[h]跳的查询命中率,[QM]是查询过程中产生的查询消息总数量,[SR]是成功查询的概率,比如在这里至少有一个查询命中,[R]是查询对象的复制比。当然如果考虑成功率[SR]时,假设查询对象统一地分布在整个网络。这时第[h]跳的查询命中率等于第[h]跳的覆盖率与复制比[R]的乘积。那么公式(9)可以改写为如下:
在这里是[Ch]是第[h]跳的覆盖率,[ek]是第[h]跳时所产生的查询消息。[R]是复制比。
在这里我们考虑[SE5],[SE1]两种类型,不考虑远程过来的搜索结果。比如:
3 结语
我们从一个给定的源节点开始查询所需要的目标节点上的文件,按照某一种规则向源节点的某一个或是多个邻居节点发送查询消息,寻找符合目标状态节点的过程。搜索算法的有效性将直接影响到复杂网络的卓越性能,本文中主要阐述了本文研究目的;主要解说了本文研究的相关工作;对复杂网络中典型的几种搜索算法进行了逻辑分析并比较。
参考文献:
[1] D. Stutzbach, R. Rejaie, N. Duffield, S. Sen, and W. Willinger, Sampling Techniques for Large, Dynamic Graphs[D]. NinthIEEE Global Internet Symp, 2006.
[2] A.H. Rasti, D. Stutzbach, R. Rejaie. On the Long-TermEvolution of the Two-Tier Gnutella Overlay[D]. Ninth IEEEGlobal Internet Symp, 2006.
[3] 吴兆福, 董文永. P2P网络搜索技术研究[J]. 武汉理工大学学报(信息与管理工程版), 2007(6).
猜你喜欢
计算机应用(2016年12期)2017-01-13
中小企业管理与科技·上旬刊(2016年10期)2016-11-15
计算技术与自动化(2015年4期)2016-03-25
软科学(2015年10期)2015-10-28
