
实验室环境下Hadoop和HAMR的性能比较
2017-04-10 19:24赵迪生
中国新通信 2017年4期
赵迪生
【摘要】 随着互联网技术的发展,数据爆炸即将发生。为了处理海量数据,包括存储,组织和分析,单个机器的能力是远远不够的。因此,构建一个分布式计算平台不仅对学术目的,而且对工业使用是有重要意义的。现如今,Hadoop是大数据最受欢以及开发最为完善的解决方案之一。 它为基于HDFS和MapReduce的大规模数据处理提供可靠,可扩展,容错和高效的服务。HAMR是另一种新出现的大数据处理技术,据说运行速度比Hadoop更快,内存和CPU消耗更少。 本文通过测量运行时间,最大和平均内存和CPU使用率,基于运行PageRank来进行Hadoop和HAMR之间的性能比较。 结果有助于构建分布式计算机平台。
【关键词】 分布式计算平台 Hadoop HAMR PageRank
一、引言
如今,数据已经成为最宝贵的社会财富之一,并且与其他社会和自然资源不同的是,它可以从几乎任何地方产生:从智能手机,从社会媒体,从电子商务和信用卡,从交通系统,从无线传感器监控系统,从工业生产领域以及从科学和工程计算领域。在每一分钟:Facebook用户点赞4,166,667个; Instagram的用户赞了1,736,111张照片; Twitter用户发送了347222条tweets; Skype用户拨打110,040个电话;苹果用户下载了51,000个应用程序。所有这些大数字都将人们引向了今天的热门话题 - 大数据。
为了以可扩展,可靠和容错的方式处理如此大规模的数据,Google推出了著名的数据处理框架MapReduce,基于它, Apache Hadoop得以发布。以四个最初的组件(GFS,MapReduce,Bigtable和Chubby)为基础,Hadoop现在已发展成一个完整的生态系统,包括HDFS,Hive和Hbase等。虽然Hadoop易于实现,但由于任务调度算法的限制,使得其并不适合处理具有高并发和大量交互操作的作业。此外,在执行迭代时,Hadoop需要更多的I / O操作。
HAMR作为以款新式分布式计算框架,用于处理和分析大规模的数据,它可以提供比Hadoop快30倍的处理速度。它是由ET International公司开发和首次发布。与Hadoop不同,HAMR是一个流式引擎,通过Flowlet技术驱动数据的流式传输和实时分析。这不仅减少了每个任务的内存使用,而且降低了CPU利用率。
在本文中,我们进行实验来评估和比较Hadoop和HAMR在实验室条件下的系统性能。我们选择一个典型的基准PageRank来运行数据集。实验结果表明,HAMR运行速度远远超过Hadoop,并且内存使用量更少。
本文组织如下。第二部分提供了相关工作的系统概述。第三部分描述我们的实验设置。第四节介绍了我们的实验结果。我们在第五节中给出我们的结论和未来的工作。
二、相关研究介绍
2.1 hadoop
Apache Hadoop作为一个开源软件项目,是以提供一个综合大数据解决方案为目的而设计的。它包含两种主要技术:HDFS,用于数据存储; MapReduce,它用于數据处理。Hadoop分布式文件系统(HDFS)是一种用于大型分布式文件系统的可扩展文件系统。与其他分布式文件系统不同,HDFS被设计为可运行在低成本的商业硬件之上的一套系统,这要求它拥有较完善的容错机制和较高高的容错率。HDFS集群由称为NameNode的主服务器和称为DataNode的几个子服务器组成。
MapReduce1.0最初是由Google开发的。 它是一种大规模可扩展的并行处理编程模型和软件框架,用于处理大型数据集。顾名思义它包含两个部分:Map和Reduce。其主要想法是将输入数据映射到键值,并将相同键的值分组在一起,然后reduce函数将这些值与相同的键合并。
2.2 HAMR
HAMR作为另外一种用于处理大规模数据的分布式软件系统,与其他系统最大的区别在于它以流式数据引擎作为核心。最终目标是最小化数据的内存占用。这使得在运行过程中,中间运算结果会占用更少的内存空间,使得更多的系统资源得以释放从而分配给更多的计算任务。为了实现这一点,HAMR尽可能早地减少数据,并尽快将数据推出系统。HAMR的工作流程包括许多称为Flowlet的逻辑数据处理单元。如图2.1所示。
这些Flowlet形成有向无环图。图中的边是连接Flowlet并传递它们之间的键/值对的数据链接。Flowlet表示单个并行处理但与,对键/值对进行操作。
像Hadoop一样,HAMR的集群也包含主节点和从节点。每个计算节点包含几个处理器核心。在HAMR中,每个计算节点被看作是计算资源的集合,在节点内部,计算资源可以被分为多个Partition,如图2.2所示。这些分区是Flowlet的物理基础。图中显示了Flowlet和分区之间的关系。一个Flowlet包含多Partition,每个Partition表示一个或多个串行处理器,其执行相应的Flowlet行为,包括键值对的计算以及传递。
2.3 PageRank
1996年,PageRank算法由来自斯坦福大学的Larry Page和Sergey Brin首先提出,到目前为止已经成为最成功的算法之一,几乎被用于所有的搜索引擎。其基本思想是,能链接到许多其他具有高质量的网页的网页往往也具有很高的质量。我们使用PageRank(PR)值来描述这种质量并进行计算。这是一种迭代过程。
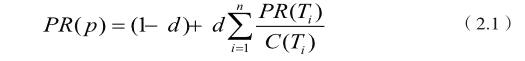
其中Ti (i=1,2,...,n)表示链接到当前网页的其他网页; d是用户可以随机到达网页的概率; C(Ti)是指向另一个网页的链接数。
三、实验场景搭建
3.1 集群设置
本次实验集群由四台计算机组成。 其中一个计算机充当主节点。其他三个被设计为从节点。每台计算机的IP地址和主机名显示在表3.1中。
每台计算机有4GB RAM和64GB硬盘驱动器,并使用Ubuntu 12.04.2操作系统(GNU / Linux3.5.0-24-generiv x86 64)和Java 1.7.0。 我们安装了目前为止最为稳定的Hadoop 2.7.1。
与Hadoop不同,HAMR在安装前需要软件依赖关系。我们使用ZooKeeper 3.4.6和RabbitMQ 3.5.4,然后我们安装了Hadoop 0.4.1。 所有这三个都是是最新的版本。
3.2 数据描述
我们使用HiBench Benchmark Suite 4.06版本为实验生成数据。运行在HAMR上的PageRank算法代码包括在HAMR 0.4.1版本中中。表3.2显示了用于Hadoop和HAMR的PageRank的路径。
3.3 Hadoop上的PageRank
在Hadoop上運行PageRank的基本思想是使用一个MapReduce过程作为PageRank的一个迭代。在每次迭代中,Map的输入键为单个网页,输入值为当前PageRank值。我们将每次迭代划分为两个阶段。在第一阶段,每个网页将其当前PR值与连接数的比值分配给每个指向其他网页的链接。这个分配过程由映射函数实现。然后每个网页统计souy瓯指向自己链接的所携带的PR值。该聚合过程由reduce函数实现。Hadoop上PageRank的一个迭代如表3.3所示。
3.4 HAMR上的PageRank
在算法的初始化阶段,从HDFS读取输入文件。 创建图表KeyValueStore,并初始化Ranks KeyValueStore。接下来执行算法的迭代部分。每次迭代中,每个页面的PR值由所有指向其链接的PR值之和求得。一旦所有页面被遍历,迭代更新保存PR值的KeyValueStore。为了保持与HAMR的稳定,迭代次数被限制为固定次数。
四、实验结果分析
实验输入数据集的范围从200万个网页到3000万个网页,输入数据大小从1GB到19.9GB不等。每个数据集运行5次迭代。我们通史记录运行时间,最大和平均内存使用率,最大和平均CPU使用率以及吞吐量。
4.1 运行时间
显然,在运行PageRank算法时HAMR比Hadoop更高效。它比Hadoop快10倍,当输入大小更大时,这种优势将达到20倍。 参见图4.1。
4.2 内存使用率
当输入数据较小(如200万和400万)时,HAMR的内存使用率保持稳定,但当数据大于800万时,HAMR的内存使用速度增长速度几乎与Hadoop一样快。 然而总体来说,HAMR的内存利用率比Hadoop高。见图4.2。
4.3 CPU使用率
与Hadoop相比,HAMR的CPU资源使用率,而与此同时Hadoop的CPU使用率几乎不受输入数据大小的影响,保持在60%左右。 但是当输入大于800万时,HAMR需要比Hadoop多2倍的CPU资源。见图4.3。
4.4 包通过量
HAMR在每个节点中具有比Hadoop高得多的吞吐量。当输入集变大时,HAMR展示出比Hadoop更好的自适应特性。见图4.4。
五、总结与展望
在本次实验中,我们建立了一个在实验室环境下运行大数据应用的平台,我们选择PageRank算法来测试Hadoop和HAMR的性能。通过比较运行时间,内存使用率,CPU使用率和包通过量,我们发现HAMR的与性速度远超Hadoop,并消耗更少的内存资源。这意味着HAMR有能力处理一些具有高实时性要求的任务。然而,由于HAMR的Flowlet技术,它需要更多的CPU资源来协调并行进程,因此HAMR对CPU性能的要求比MapReduce高。但随着处理器技术的巨大发展,这种要求可以更容易和更容易地实现。
随着我们的未来工作,我们计划通过在我们的平台上实施Spark来扩展我们的实验。Spark也是一个用于解决大数据问题的开源集群计算框架,它也已成为最广泛使用的程序之一。它被设计为支持应用程序,其在多个并行操作中重用一组工作数据,同时还提供与MapReduce相同的可伸缩性和容错属性。而不是在I / O操作上浪费太多的计算资源,这使得Spark运行速度也快于MapReduce。然而,Spark是否也具有HAMR的优势是我们下一步验证。
此外,我们计划建立一个更大的集群,以测试每个框架的性能,并使用更多的算法,如WordCount,Naiver Bayes和K-Cliques8来更全面的衡量系统性能性能。此外,我们计划设计一个智能系统,可以帮助我们根据应用程序和输入数据大小选择平台和配置参数,以获得优化的性能。
参 考 文 献
[1] Josh James. Data never sleeps 3.0. [Online]. Available: https://www.domo.com/blog/2015/08/datanever-sleeps-3-0/, August 2015.
[2] J. Dean and S. Ghemawat, “MapReduce: Simplified data processing on large clusters,” in OSDI, 2004
[3] Apache Hadoop. [Online]. Available: http://hadoop.apache.org
[4] Hamr – beyond mapreduce. [Online]. Availabe: http://www.etinternational.com/index.php/news-andevents/press-releases/hamr-beyond-mapreduce/, August 2014.
[5] HAMR. [Online]. Available http://hamrtech.com/benchmarks.html
[6] Hibench. [Online]. Available: https://github.com/intel-hadoop/HiBench.
[7] J. Lin and C. Dyer, “Dara-Intensive Text Processing with MapReduce,” Morgan & Claypool, 2010
[8] D. Jiang, B. C. Ooi, I. Shi, and S. Wu, “The performance of MapReduce: An in-depth study,”Proceedings of the VLDB Endowment, vol. 3, no. 1-2, pp. 472-483, 2010.
