
基于词向量的中文微博实体链接方法
2017-04-24 10:24毛二松唐永旺
计算机应用与软件 2017年4期
毛二松 王 波 唐永旺 梁 丹
(解放军信息工程大学 河南 郑州 450002)
基于词向量的中文微博实体链接方法
毛二松 王 波 唐永旺 梁 丹
(解放军信息工程大学 河南 郑州 450002)
实体链接是指给定实体指称项和它所在的文本,将其链接到给定知识库中的目标实体上。由于微博内容存在特征稀疏、用语不规范的特点,使用传统的方法效果较差,为了准确地对微博中给定的实体进行链接,提出一种基于词向量的中文微博实体链接方法。首先,对知识库进行扩展,并从中文维基百科抽取同义词构建同义词表;然后,利用词向量解决错别字和外来人名音译的问题;最后,通过词向量计算实体指称项和候选实体的语义相似度来进行实体链接。实验结果表明,该方法在NLP&CC2013评测数据上的微平均准确率达到了91.4%。
实体链接 词向量 维基百科 同义词
0 引 言
随着互联网技术的快速发展,基于互联网信息构建的知识库的出现促使自然语言处理中出现了一项新的任务,即实体链接[1]。实体链接是指给定实体指称项和它所在的文本,将其链接到知识库中目标实体上。然而现实中的实体存在歧义性和多样性的问题,如何将存在歧义的实体正确地链接到知识库中对应的实体上在知识库的构建与扩展、知识图谱和信息检索等领域具有重要的理论意义和应用前景[2]。
已有的研究大多专注于英文实体链接,对于中文的实体链接研究较晚,虽然在TAC2011中引入了中文实体链接任务,但它的实质是将中文实体指称链接到英文知识库中,因而属于跨语言实体链接范畴[3]。而一些会议如CLP(Chinese Language Processing)和WePS(Web People Search)只是针对人名进行链接。2013年自然语言处理与中文计算会议NLP&CC(Natural Language Processing & Chinese Computing)设置了中文微博实体链接评测任务,旨在将中文微博中的实体(人名、地名、组织机构名等)链接到知识库中目标实体上。NLP&CC2013会议给出中文微博实体链接的定义为给定一条微博,一个待链接的实体指称项,以及该实体指称项在这条微博中出现的位置。首先判断该实体指称项是否指向了知识库中的某一个实体;若存在这样的对应实体,则将该实体在知识库中的编号输出,若不存在,则输出空置符NIL。
实体链接任务的主要步骤为先获取实体指称项的候选实体,之后计算实体指称项的上下文和候选实体上下文的语义相似度,选择相似度最大的候选实体作为链接的目标实体[4]。实体链接的核心是计算实体指称项和候选实体上下文的语义相似度,传统的相似度计算采用词袋模型BOW(Bow Of Words)[5-6]将实体指称项和候选实体的上下文表示成BOW向量,计算两者的余弦距离得到相似度。针对文献[5-6]仅仅考虑实体指称项与候选实体之间的语义相似度,2011年,Han等[7]提出一种基于图模型的协同实体链接方法,利用协同式策略考虑知识库中实体间的语义关联,建立全局语义约束,能够更准确地对文本中的实体进行链接。其中图中节点为所有的实体指称和知识库中的目标实体,通过使用词袋模型的方法得到实体指称和目标实体的语义相似度,使用基于维基百科的链接关系得到目标实体之间的语义相似度。2013年,Zeng等[8]通过对内容过于简短的微博进行适当的扩充来增加实体的上下文特征,使用渐进式的词袋模型S-BOW(Stepwise Bag-of-Words)来计算实体指称项和候选实体之间的语义相似度。2015年,昝红英等[9]针对微博中的实体具有多样性的问题,提出了一种基于多源知识的中文微博命名实体链接方法,通过将同义词词典、百科资源等知识与词袋模型相结合的方法来计算实体指称项和候选实体之间的语义相似度,之后进行实体链接,实验结果表明该方法能够有效提高实体链接的准确率。
然而,基于BOW模型计算相似度的主要缺陷为假设任意两个词之间是相互独立的,在计算实体指称项的上下文和候选实体上下文的相似度时无法利用词语中存在的同义词、近义词和相关词等语义关系[10]。此外,微博内容具有长度短、语法不规范的特点,给命名实体链接任务增加了难度。由于微博内容长度短,使用基于BOW模型的方法对实体指称项的上下文进行表示时会造成严重的特征稀疏问题;微博内容的不规范性,微博中经常出现错别字和外来人名音译不统一的问题,如微博中出现的外来人名“萨科齐”与知识库中的“萨科奇”,其实二者指代的都是同一个人名。
词向量最早由Rumelhart等[11]提出的一种词语表示方式,Mikolov等提出的Skip-gram模型[12]可以快速地完成大规模数据的训练,得到的词向量在计算词语之间的语义相似度方面更加准确。
综上所述,为了计算实体指称项和候选实体上下文的语义相似度更加准确,提高实体链接的准确率,本文提出一种基于词向量的中文微博实体链接方法,使用词向量对实体指称项和候选实体的上下文进行表示,通过词向量计算两者之间的语义相似度。另外,无论是错别字还是外来人名音译,如“阿里巴巴”和“阿里爸爸”以及外来人名“萨科齐”和“萨科奇”,两者之间都具有相同的语义信息,本文基于此特点使用词向量来解决错别字和外来人名音译的问题。
1 中文微博实体链接的总体框架
中文微博实体链接任务可定义为如下的五元组:
G=(M,C,D,S,θ)
(1)
其中,M是实体指称项集合,C是知识库候选实体集合,D是实体指称项的上下文词语集合,S是候选实体的上下文词语集合,θ:M×D×S→C是实体链接函数,将实体指称项映射到知识库目标实体上。
中文微博实体链接的总体框架如图1所示。其中包括知识库扩展、构建同义词表、错别字和外来人名音译的处理、获取候选实体集和实体链接共五个模块。本文首先对知识库进行扩展,然后从中文维基百科抽取同义词构建同义词表,之后利用词向量解决错别字和外来人名音译的问题,在获取候选实体集后,通过词向量计算实体指称项和候选实体的语义相似度来进行实体链接。
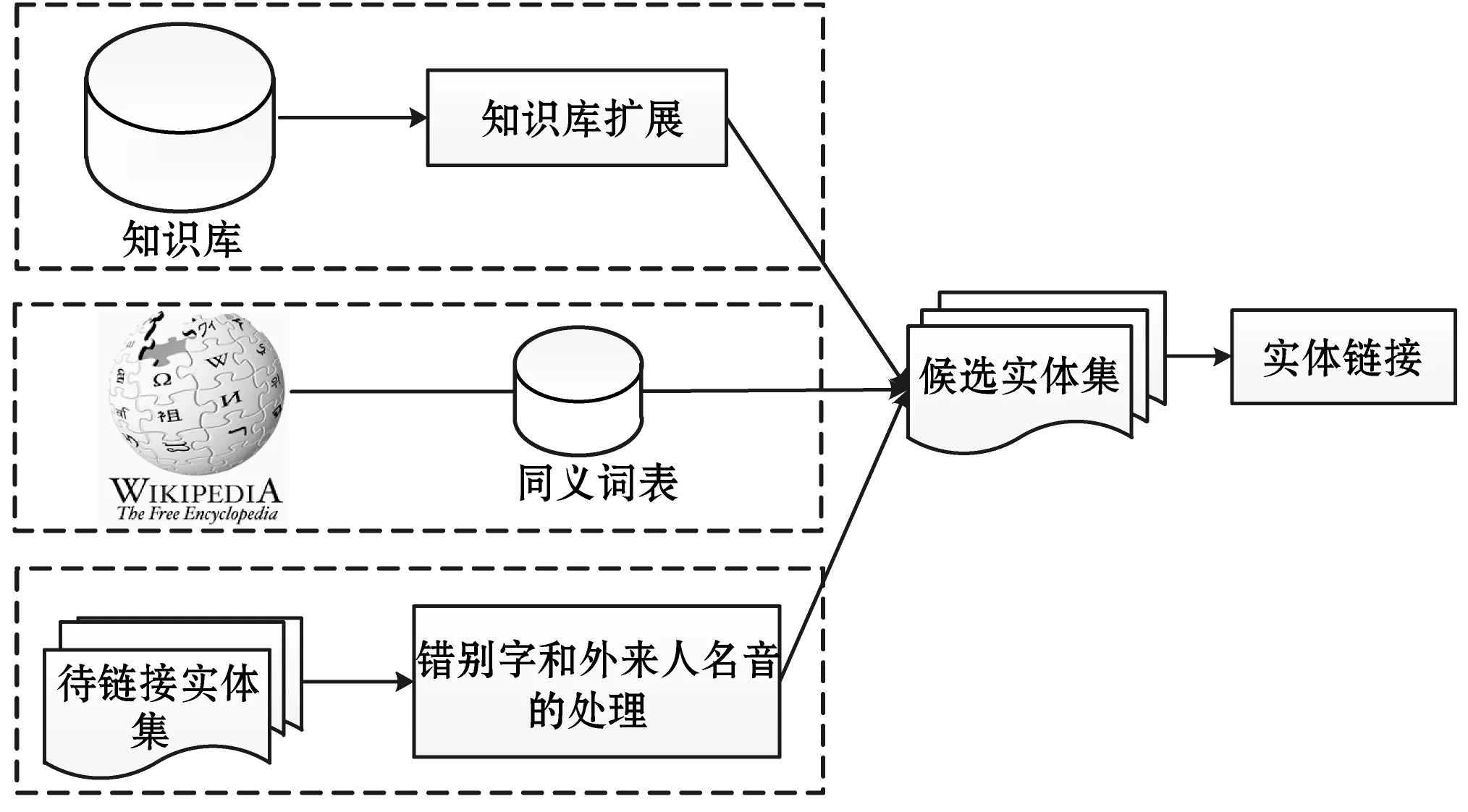
图1 中文微博实体链接的总体框架
2 中文微博实体链接的具体流程
2.1 知识库扩展
NLP&CC2013会议中实体链接评测使用的是百度百科知识库,由于部分实体存在噪声、不准确以及描述不全的情况,因此本文采用以下方法解决上述问题:
(1) 本文从实体的百度百科中获取词条标签,对知识库的类标进行修正。例如,知识库中的词条“倚天屠龙刀”,其在知识库中的分类标签为“地理地貌大陆”,然而该词条标签为“电视剧影视作品”[13],如表1所示。另外,从该词条的字面上也可以看出该词条属于影视作品。

表1 “倚天屠龙刀”词条标签
(2) 百度百科知识库中部分实体具有歧义性,为了更准确地描述知识库中的实体,本文从百度百科的消歧页面获得每个实体的描述词语。例如,“霸王别姬”实体总共有19个义项,其中“霸王别姬(国产电视剧)”的页面表明该实体为电视剧名称;“霸王别姬(历史典故)”的页面表明该实体为历史典故词语;“霸王别姬(1993年陈凯歌执导电影)”的页面表明该实体为电影名称。
2.2 构建同义词表
由于微博中经常出现实体的简称、别称等,为了准确地对实体进行链接,本文从中文维基百科[14]中共抽取735 053个同义词形成同义词表。具体构建方法如下:
(1) 从重定向页面中抽取同义词
当两个不同的词语所指代的含义完全相同或绝大部分人对这两个词语的认知一致时,维基百科不会为这两个词语建立两个页面,而是添加一个重定向链接,将该词语指向另一个词语的页面。
(2) 从维基百科首段加粗内容抽取同义词
维基百科的首段内容会有很多的加粗字体,该加粗字体都是该实体的简称、别称、统称等等。
2.3 错别字和外来人名音译的处理
词向量的基本思想是将每个词映射成一个k维实数向量。Mikolov在文献[12]中指出相比于传统的语言模型,基于神经网络语言模型[15]NNML(Neural Network Language Model)得到的词向量对词的表示更加准确。本文使用Mikolov提出的Skip-gram模型在中文数据上进行训练。其中Skip-gram模型可以通过Hierarchical Softmax[16]和Negative Sampling[12]两种框架构造实现,本文使用的是基于Hierarchical Softmax构造的Skip-gram模型。通过词向量计算词与词之间的余弦距离得到词与词之间的语义相似度,计算公式如下所示:
(2)
其中,v(w1)表示w1的词向量,v(w2)表示w2的词向量,sim(v(w1),v(w2))表示通过词向量计算w1和w2的余弦距离得到w1和w2的语义相似度。
表2列举了一些通过词向量计算词与词之间语义相似度的测试结果。
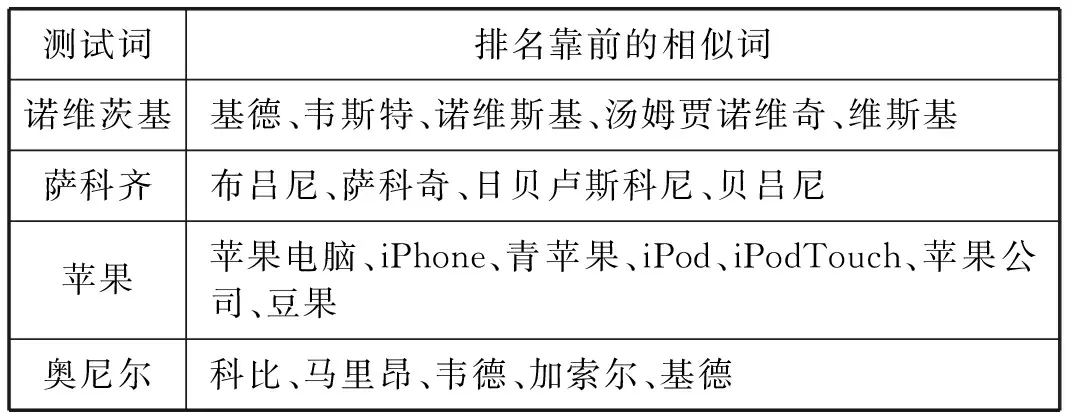
表2 词与词之间的相似度
由表2可以发现和“萨科齐”相似的词中包括“萨科奇”这种同音词,“诺维茨基”的相似词中也包括相似发音的词“诺维斯基”。
本文使用以下原则来解决错别字和外来人名音译的问题:
(1) 待纠错的实体指称项和知识库中的目标实体具有相同的字越多,则待纠错的实体指称项和该目标实体的匹配度越高。例如,待纠错的实体指称项“阿里爸爸”与知识库中的目标实体“阿里巴巴”的匹配度要比“诺维茨基”的匹配度高。
(2) 待纠错的实体指称项和知识库中的目标实体的语义相似度越高,则待纠错的实体指称项和该目标实体的匹配度越高。根据表2发现“诺维茨基”和“诺维斯基”的语义相似度要比“阿里巴巴”的相似度高。
(3) 待纠错的实体指称项和知识库中的目标实体的长度必须相同。这里假设待纠错的实体指称项仍然和自身的长度相同,例如,待纠错的实体指称项“阿里爸爸”的真实实体仍然是四个字,不可能是其他长度的实体。
最后,选择匹配度越高的目标实体作为待纠错实体指称项的真实实体。根据以上原则,计算两者的匹配度公式如下所示:
(3)
其中,mi表示第i个待纠错的实体指称项,ej表示知识库中第j个目标实体,l(mi)表示mi的字数,l(ej)表示ej的字数,sl(mi,ej)表示mi和ej相同的字数,sim(v(mi),v(ej))表示mi和ej的语义相似度;若mi和ej的字数不相等,则match(mi,ej)=0;若sim(v(mi),v(ej))的相似度小于0.5,则match(mi,ej)=0。
2.4 获取候选实体
候选实体的获取是实体链接的关键步骤,只有尽可能多地获取候选实体,下一步才可能正确地链接候选实体。如果候选实体集中不包括目标实体,则无论使用何种方法都无法正确实现链接。获取候选实体的具体方法如表3所示。
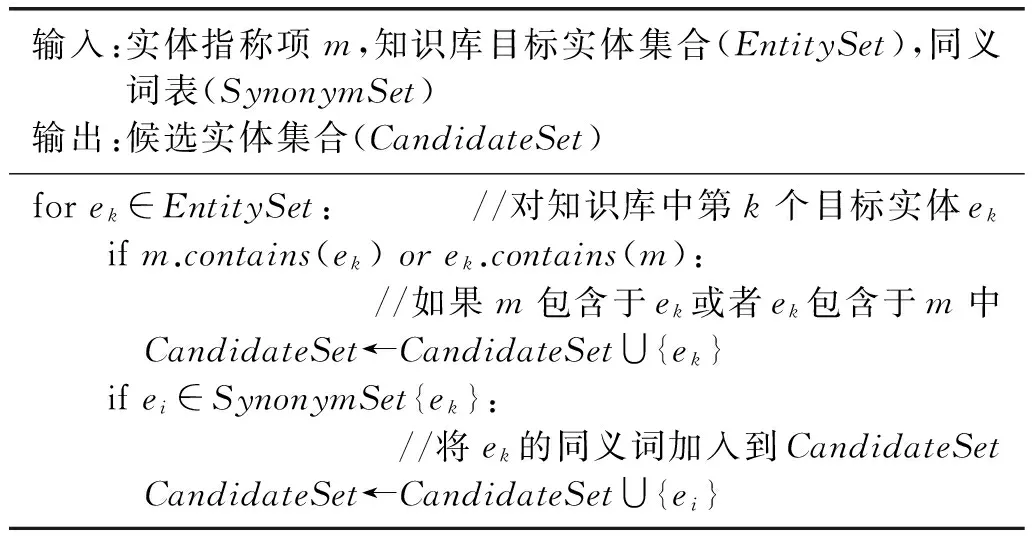
表3 获取候选实体的具体流程
2.5 实体链接
获得每个实体指称项的候选实体之后,通过计算该实体指称项和候选实体的语义相似度,并选择相似度最大的候选实体。然而候选实体中最大的相似度有可能太低,相似度最大的候选实体未必是链接的目标实体,所以实验中设置相似度的阈值,只有最大的相似度大于设定的阈值,则将该候选实体作为链接的目标实体。例如,实体指称项“霸王别姬”总共有四个候选实体,分别为“霸王别姬(1993年陈凯歌执导电影)”、“霸王别姬(菜肴名称)”、“霸王别姬(单机RPG游戏)”、“霸王别姬(屠洪刚演唱歌曲)”。实体指称项“霸王别姬”所在的微博文本为“4月1日,怀念哥哥张国荣!最爱你的《霸王别姬》,美艳动人!”,从微博的上下文内容包含“张国荣”一词可以看出,该实体指称项“霸王别姬”与“霸王别姬(1993年陈凯歌执导电影)”条目的语义相似度最大。
本文将实体指称项的上下文和候选实体的上下文表示成词语的集合。通过对该实体指称项所在的微博进行分词,去掉停用词后,将微博中所有的名词作为该实体指称项的上下文。由于实体指称项所在的微博内容有时太过简短,实体指称项的上下文信息过于稀疏,而同一个话题实体之间语义相近,因此将该实体指称项所在话题的所有实体加入到该实体指称项的上下文中。例如,实体指称项“霸王别姬”所在的话题所有的实体有“谢婷婷”、“梅艳芳”、“《当爱已成往事》”和“林嘉欣”等实体。另外,将候选实体的词条标签和该候选实体的描述词语作为该候选实体的上下文,实体指称项和候选实体的语义相似度计算公式如下所示:
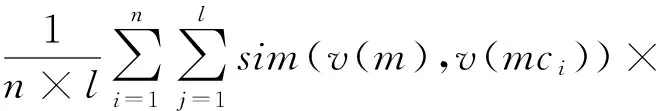
sim(v(mci),v(ecj))
(4)
其中,m表示实体指称项,e表示候选实体,n表示实体指称项上下文词语的个数,l表示候选实体上下文词语的个数,mci表示实体指称项上下文中第i个词语,ecj表示候选实体上下文中第j个词语,sim(v(m),v(mci))表示通过计算m和mci的语义相似度作为mci词语的权重,sim(v(mci),v(ecj))表示mci和ecj的语义相似度。实体链接的具体算法流程如表4所示。

表4 实体链接的算法流程
3 实验与分析
3.1 实验数据
本文采用的实验数据是NLP&CC2013提供的中文微博实体链接标注的数据集,该数据集包含560条中文微博,这些微博分布在53个话题中,共有826个待链接的实体,其中包括421个能够链接到知识库 In-KB(In-KnowledgeBase)的实体,405个不能链接到知识库的实体即空链接(NIL)的实体。
实验中使用的词向量是使用Skip-gram模型在中文数据上训练得到,其中训练数据来源于“搜狗实验室”的“全网新闻数据”[17]、中文维基百科语料[14]以及本文的实验数据。
3.2 评价指标
为了评价本文方法的有效性,采用NLP&CC 2013中文微博实体链接任务的评价标准,即微平均准确率maa(micro-averaged accuracy)作为评价指标。其计算式如下:
(5)
为了更好地对实验结果进行分析,本文对存在链接的实体集以及空链接的实体集这两类实体集分别计算准确率P、召回率R以及F1值。
(6)
(7)
(8)
其中,TP表示被正确链接的实体个数,FP表示被错误链接的实体个数,FN表示被错误链接到另一个实体集的实体个数。
3.3 实验结果
(1) 相似度阈值θ的影响
相似度阈值的设置影响实体的链接结果,通过实验分析,实体指称项和候选实体的语义相似度集中在[0,0.2]之间,为了得到合理的阈值,本文对相似度阈值在[0,0.2]范围内以步长为0.01进行遍历,结果如图2所示。
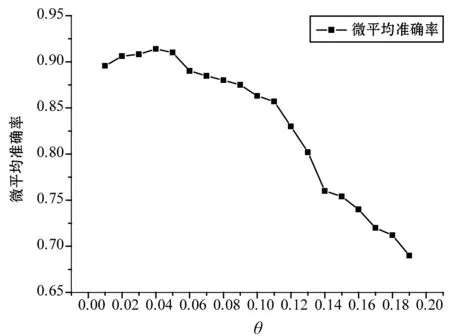
图2 参数θ对微平均准确率的影响
从图2可以看出,微平均准确率随着相似度阈值θ的增加呈现出先上升后下降的趋势,当相似度阈值θ为0.04时,微平均准确率最高,所以相似度阈值θ的大小设为0.04。
(2) 错别字和外来人名音译对结果的影响
为了验证错别字和外来人名音译的问题对实验结果的影响,本文设置两组实验,实验1是没有对错别字和外来人名音译的问题进行处理所得结果,实验2则是对该问题处理后所得结果,实验结果如表5所示。
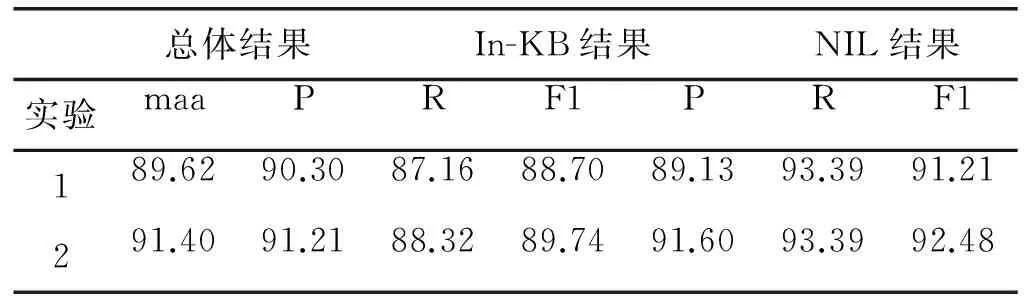
表5 错别字和外来人名音译对结果的影响 %
从表5结果可以看出,实验2的微平均准确率高于实验1的微平均准确率,而且实验2中NIL结果的准确率比实验1中NIL结果的准确率高出了2.47%。主要是因为一些错别字和外来人名音译的实体通过处理得到纠正,例如,实体“阿里爸爸”、“高小松”和“林舒壕”纠正后分别链接到知识库中的实体“阿里巴巴”、“高晓松”和“林书豪”。
(3) 不同方法的实验结果对比
为了验证本文方法的有效性,本文选取NLP&CC2013中最好的评测结果(bestResult)以及Zeng等人[8]使用的S-BOW方法作为baseline进行对比,对实验结果取10次求平均作为其最终结果。

表6 不同方法的实验结果对比 %
从表6中可以看出,本文方法的微平均准确率明显高于S-BOW的微平均准确率,主要是因为S-BOW方法在计算词语相似度时无法利用词语中存在的同义词、近义词和相关词等语义关系,另外有些实体所在微博的内容太过简短,实体指称项的上下文信息过于稀疏,计算实体指称项的上下文和候选实体的上下文的语义相似度太低,导致实体链接错误。本文方法的NIL结果略低于最好的评测结果,原因在于若实体指称项有多个候选实体时,这些实体的最佳相似度阈值往往不同,当设置相似度阈值一样时,会导致部分实体链接到NIL中。从整体来看,本文提出的方法是可行并且有效的。
4 结 语
为了准确地对微博中给定的实体进行链接,提出了一种基于词向量的中文微博实体链接方法。首先,对知识库进行扩展,并从中文维基百科抽取同义词构建同义词表。然后,利用词向量解决错别字和外来人名音译的问题。最后,通过词向量计算实体指称项和候选实体的语义相似度来进行实体链接。实验结果表明,该方法较传统的方法的微平均准确率有了很大的提高。然而,当对人名进行链接时,其候选实体的职业相同或相似时,只计算实体指称项和候选实体的语义相似度来进行实体链接容易出现误判,所以在下一步的研究中,如何解决这种问题将是研究的重点方向。
[1] 郭宇航, 秦兵, 刘挺, 等. 实体链指技术研究进展[J]. 智能计算机与应用, 2014, 4(5): 9-13.
[2] 陆伟, 武川. 实体链接研究综述[J]. 情报学报, 2015(1): 105-112.
[3] 舒佳根, 惠浩添, 钱龙华, 等. 一个中文实体链接语料库的建设[J]. 北京大学学报(自然科学版), 2015, 51(2): 321-327.
[4] 赵军, 刘康, 周光有, 等. 开放式文本信息抽取[J]. 中文信息学报, 2011, 25(6): 98-110.
[5]HonnibalM,DaleR.DAMSEL:TheDSTO/MacquarieSystemforEntity-Linking[C]//ProceedingsofTextAnalysisConference2009, 2009.
[6]BikelD,CastelliV,FlorianR,etal.Entitylinkingandslotfillingthroughstatisticalprocessingandinferencerules[C]//ProceedingsofTextAnalysisConference2009Workshop, 2009.
[7]HanX,SunL,ZhaoJ.Collectiveentitylinkinginwebtext:agraph-basedmethod[C]//Proceedingsofthe34thInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval.ACM, 2011: 765-774.
[8]ZengY,WangD,ZhangT,etal.LinkingentitiesinshorttextsbasedonaChinesesemanticknowledgebase[C]//TheSecondConferenceonNaturalLanguageProcessingandChineseComputing.Springer, 2013: 266-276.
[9] 昝红英, 吴泳钢, 贾玉祥, 等. 基于多源知识的中文微博命名实体链接[J]. 山东大学学报(理学版), 2015, 50(7): 9-16.
[10]XuanJ,LuJ,ZhangG,etal.ExtensionofsimilaritymeasuresinVSM:Fromorthogonalcoordinatesystemtoaffinecoordinatesystem[C]//NeuralNetworks(IJCNN), 2014InternationalJointConferenceon,IEEE, 2014: 4084-4091.
[11]RumelhartDE,HintonGE,WilliamsRJ.Learningrepresentationsbyback-propagatingerrors[J].Nature, 1986, 323(6088): 533-536.
[12]MikolovT,ChenK,CorradoG,etal.Efficientestimationofwordrepresentationsinvectorspace[C]//ProceedingsoftheInternationalConferenceonLearningRepresentations, 2013: 1-12.
[13] 百度百科. 倚天屠龙记[DB/OL].http://baike.baidu.com/subview/11113/6730113.htm.
[14] 中文维基百科.zhwikidumpprogress[DB/OL].https://dumps.wikimedia.org/zhwiki/.
[15]BengioY,DucharmeR,VincentP,etal.Aneuralprobabilisticlanguagemodel[J].TheJournalofMachineLearningResearch, 2003, 3: 1137-1155.
[16]MorinF,BengioY.Hierarchicalprobabilisticneuralnetworklanguagemodel[C]//Proceedingsofthe10thInternationalWorkshoponArtificialIntelligenceandStatistics, 2005: 246-252.
[17] 搜狗实验室. 全网新闻数据[DB/OL].http://www.sogou.com/labs/resource/ca.php.
ENTITY LINKING METHOD OF CHINESE MICRO-BLOG BASED ON WORD VECTOR
Mao Ersong Wang Bo Tang Yongwang Liang Dan
(ThePLAInformationEngineeringUniversity,Zhengzhou450002,Henan,China)
Entity linking refers to a given entity referring to an item and its text, linking it to a target entity in a given knowledge base. Due to the characteristics of micro-blog content sparse, non-standard terms, the use of traditional methods less effective.In order to accurately link to a given entity in microblogging, a method based on word vector for Chinese microblogging entity linking is proposed. First, the knowledge base is extended, and synonyms are extracted from the Chinese Wikipedia to construct the synonym list. Then, using the word vector to solve typos and foreign name transliteration problem. Finally, the entity link is calculated by computing the semantic similarity between the entity and the candidate entity. The experimental results show that the micro-averaged accuracy of the proposed method is 91.4% on the NLP&CC2013 evaluation data.
Entity linking Word vector Wikipedia Synonyms
2016-02-13。国家社会科学基金项目(14BXW028)。毛二松,硕士生,主研领域:社会计算。王波,副教授。唐永旺,讲师。梁丹,硕士生。
TP391
A
10.3969/j.issn.1000-386x.2017.04.003
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京大学学报(自然科学版)(2022年1期)2022-02-21
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
科技视界(2014年27期)2014-08-15
