
基于分散分配的非对称距离倒排索引机制研究
2017-04-27 15:57宝航
电子技术与软件工程 2016年15期
宝航
摘 要 随着计算机多媒体技术的快速发展,基于图像内容的检索逐渐成为了热点的研究问题。图像的特征描述和特征索引机制的建立是实现基于内容图像检索的关键。根据图像局部特征向量与聚类中心的相对距离,建立非对称距离计算倒排索引机制。为了进一步提高查询效率,本文将可能落入多条哈希链表中的数据库向量进行多次编码,实现了基于分散分配的非对称距离计算倒排索引机制。通过实验可以发现,这种索引机制可以有效的提升查询效率。
【关键词】倒排索引 非对称距离计算 分散分配
1 引言
如今,针对规模巨大的影像数据集,一般的检索系统分为三个基础步骤:特征提取、高维索引机制和检索系统设计,而高维索引机制是快速、精确检索的核心,高维索引结构的构建也是影像数据进行建库和检索引擎模块建立的重点。从数据库里提取出来的数据特征表现为分散的、无序的向量,通过建立多维索引结构将这些特征向量进行有规律的存储,其中索引结构的设计是重点。一般,高维索引结构主要分三类:基于树的索引(tree-based index),基于哈希的索引( hashing-based index)和基于视觉词的倒排索引( visual words based inverted index)方法。
2 基于视觉词的倒排索引结构
基于视觉词的倒排索引源于基于内容的图像检索,对于给定的图像,首先提取出局部特征,如SIFT,然后量化为视觉词,这些视觉词字典是预先在训练数据集上训练得到的。然后,用BOF描述符的高维向量生成表示图像。BOF描述符通过倒排索引文件方式进行索引,该倒排索引文件中每个条目为每个视觉词和发生该视觉词的所有图像的列表组成。描述符的构建可以基于视觉词所发生的频率计数或tf-idf方法。基于视觉词的倒排索引主要集中在视觉描述符的构造、描述符压缩编码和倒排索引结构的研究。
在标准的基于视觉词的倒排索引结构中,每个视觉词与一个倒排的列表关联,列表中存储图像的识别和图像中发生的视觉词的频率。给定一个查询图像,转换为BOF描述符后,与查询图像中视觉词关联的倒排列表将作为检索后续结果集。如果在查询图像中有1000个视觉词发生,则需要1000个倒排列表进行检索。因此,一些粗量化(包含少量的聚类)的方法被提出来以减少检索的倒排列表数量,提供时间性能。
非对称距离计算倒排索引机制聚合了全局量化、积量化、非对称距离计算以及倒排索引等关键技术。其中,全局量化是指在全局基础上对整个数据空间进行统一量化。量化是将原始向量经某种方法获取离散值,即用一组少量的、规定的向量来表示整个原始空间中的所有向量。k-means 方法中的聚类中心就是这样一组规定的向量,是经过训练集合均值聚类获取的中心点,目的在于使用少量有代表性的数据来表示整个数据空间。非对称距离计算是指非量化的查询向量与量化后的数据库向量之间的距离计算。使用非对称距离计算更能体现对象之间的相似度,减小量化带来的距离误差。
非对称距离计算倒排索引机制首先使用 k-means 方法对所有的特征向量进行聚类,将数据库中的特征向量分配给聚类,即进行全局量化,然后将计算特征向量与所属聚类中心之差获得剩余向量,对所有的剩余向量进行积量化,从而获得积量化后的编码连同数据的索引标识组成哈希对,添加到对应的聚类所属的倒排索引链表中。使用 IVFADC 组织图像的聚合向量,每幅图像可用少至 20 字节的编码表示,使得海量数据库在内存中的检索成为可能。
3 基于分散分配的非对称距离计算倒排索引机制
在多维索引机制中,“维度灾难”会随着特征维度的增多而出现。在特征向量维度较高的情况下,传统的树型索引结构表现并不理想。维度过高时,大多数索引方法的查询性能甚至低于对原始数据进行顺序扫描的性能。高维数据检索(high-dimentional retrieval)是一个有挑战的任务。由于时间和空间的限制,将检索数据与数据库中的数据进行一对一的相似度比较是无法实现的。决定检索复杂程度的因素有两个,一是高维向量的相似度比较,二是海量的数据检索。第一个问题,可以用哈希算法对高维数据进行降维。第二个问题,可以在检索初期就排除掉一些数据来减小比较的次数。而位置敏感哈希类算法(LSH)恰好满足了这一需求。位置敏感哈希类以及建立在 BOF 基础上的倒排索引类是一种效果比较好的解决“维度灾难”的索引方法。本文介绍一种基于LSH的索引方法——基于分散分配的非对称距离计算倒排索引机制(DA-IVFADC)。
该索引机制建立的主要过程如下:
(1)参考支点选择,利用HF算法选择支点,用于基于距离的降维。
HF支点选择算法,首先在数据库中选择随机的数据点A1,到距离A1最远的数据点B1,B1记为第一个支点,接下来离B1最远的支点B2,B2记为第二个支点,计算B1和B2之间的距离,并记为S。对数据库的每一个数据点对象Ai,具有最小F值的对象即为下一个支点,重复最后一步,直到所有支点被选择。一般选取的支点个数比高维特征向量的维度小很多。
(2)预先计算所有数据点到支点距离并进行全局量化。
根据之前所選取的支点,计算出数据集中所有数据点到支点的距离,将高维特征向量Oi映射为{d(Oi,p1 ),d(Oi,p2),...,d(Oi, pj)},pj 为支点,j 为支点个数,这样得到低维向量,在低维情况下聚类算法将会有很好的效果,使用 k-means 方法对映射的向量进行聚类,在聚类过程中同时获取两个与向量y最近的聚类中心,最近Ci与次近Cj;
(3)计算向量y与最近的两个聚类中心的距离d(y,Ci)与d(y,Cj);
(4)如果d(y,Cj) - d(y,Ci) ≥σ,则计算剩余向量r(y)= y - Ci,接步骤 5;
如果d(y,Cj) - d(y,Ci) < σ,则计算r1(y)= y - Ci、r2(y)= y - Cj,接步骤 6;
σ值可以将那些与多个聚类中心的距离相近的对象,同时分配到这些聚类中,以得到更佳的查询结果。
(5)积量化r(y)得到p( r(y) ),将得到的编码以及PID 添加到所属的聚类对应的倒排索引链表i中;
(6)积量化r1(y)得到p( r1(y) ),积量化r2(y)得到p( r2(y) ),将得到的编码以及PID 分别添加到所属的聚类对应的倒排索引链表i、链表j中。
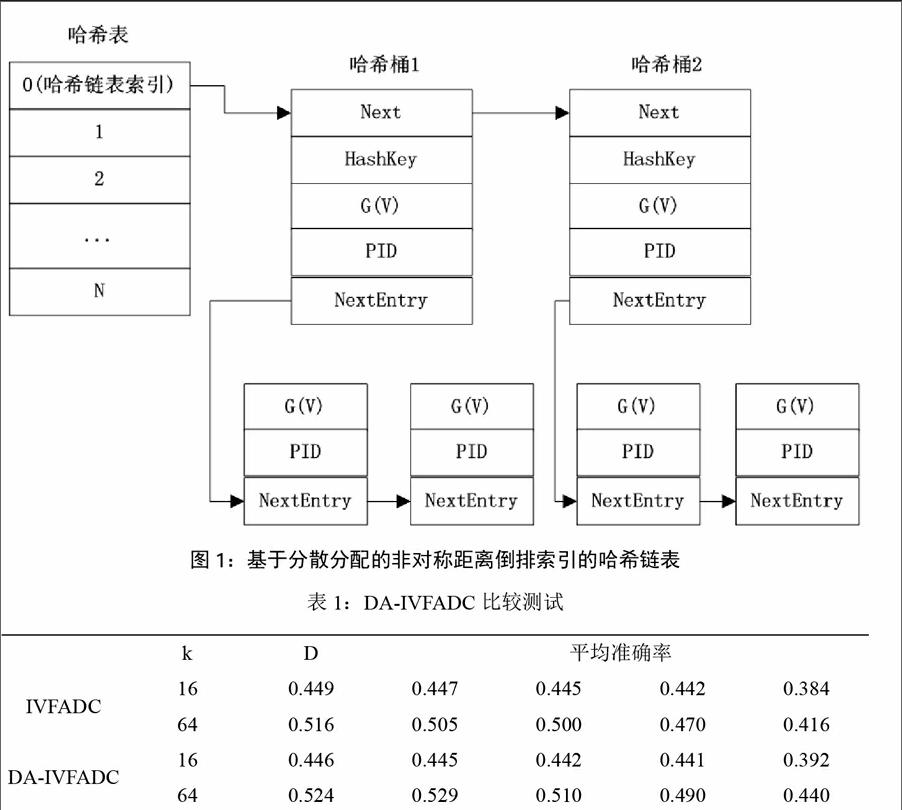
(7)对倒排索引链表进行哈希,生成哈希表进行索引:
经过积量化得到的编码G(v)={ h1(v), h2(v), .. .hm(v)},m为积量化参数(即向量等分子部分的数量),直接存入哈希表,即占用内存又不便于查找,因此定义另外两个哈希函数h1的值作为哈希表索引,h2的值作为链表中的关键值。ri 和ri'是随机整数,C是一个大素数的取值为232-5,tableSize为哈希表的大小,则每个哈希表的结构如图1所示。
测试数据集是由机器随机生成104个维度为64的浮点数向量,训练集合大小为25×103个向量,数据库集合大小为104个向量,查询集合100个向量。目的在于测试算法对于无规律、各个维度都完全独立的非结构化数据的查询性能,如表1所示。
测试结果表明,本文的DA-IVFADC索引机制相对于传统的IVFADC索引机制的查询性能得到了一定的提升。
4 结束语
本文对基于分散分配的非對称距离计算的倒排索引机制进行了研究,研究表明该索引机制相对于传统的索引机制的查询性能得到了提升。但由于该索引机制的建立基础是训练集合的编码本,频繁的插入删除操作会使中心点产生偏移现象,进而影响检索的准确性,而重新训练编码本是不现实的。如何使该索引机制适应频繁的增删操作,是下一步要研究的主要问题。
参考文献
[1]何云峰,周玲,于俊清,徐涛,管涛. 基于局部特征聚合的图像检索方法[J].计算机学报,2011(11):2224-2233.
[2]艾列富,于俊清,管涛,何云峰.大规模图像特征检索中查询结果的自适应过滤[J].计算机学报,2015(01):122-132.
[3]汪昀,朱明,冯伟国.一种支持海量人脸图片快速检索的索引结构[J].计算机工程,2015(03):186-190.
[4]林俊鸿,姜琨,杨岳湘.倒排索引查询处理技术[J]. 计算机工程与设计,2015(03):572-575+580.
[5]王晶,王昊.融合局部特征和全局特征的视频拷贝检测[J].清华大学学报(自然科学版),2016(03):269-272.
[6]张志远,徐恒盼.一种基于倒排索引的多维网络存储模型[J].计算机技术与发展,2016(04):1-6.
作者单位
辽宁民族师范高等专科学校 辽宁省阜新市 123000
