
基于Kubernetes的分布式ELK日志分析系统
2017-04-27 16:15陈建娟刘行行
电子技术与软件工程 2016年15期
关键词:分布式
陈建娟++刘行行
摘 要 在大规模云服务及系统中,对日志的收集和集中处理具有重要作用,通过分析日志可以快速定位错误,提前预警风险。本文结合开源日志解决方案ELK和分布式消息队列Kafka构建了实时消息系统,阐述了各组件的主要功能及其工作原理,并利用主流的云技术Kubernetes来实现快速部署和管理,通过ETCD和SKYDNS作为服务发现,为分布式系统提供技术支撑。基于Kubernetes的分布式ELK日志分析系统具有灵活性,方便性等特点,可用于企业快速搭建日志处理平台。
【关键词】Kubernetes ELK 日志分析 分布式
大数据时代,企业的IT构架不断扩展,资源的种类和数量也越来越多,这标志着企业IT系统建设的日趋完善,同时也意味着运维管理将面临更大的挑战。优秀的系统运维平台既能实现数据平台各组件的集中式管理、方便系统运维人员日常监测、提升运维效率,又能反馈系统运行状态给系统开发人员。大规模云服务及系统中,日志系统是保障系统稳定运行不可或缺的一部分,通过把带时间戳的基于时间序列的机器数据包括IT系统信息、物联网各种传感器信息进行集中管理,并运用实时数据处理技术对这些数据建立索引以及统计,帮助快速定位问题的根源,发现数据价值,提高工作效率。其重要性和监控系统、自动测试系统等相当。
1 ELK
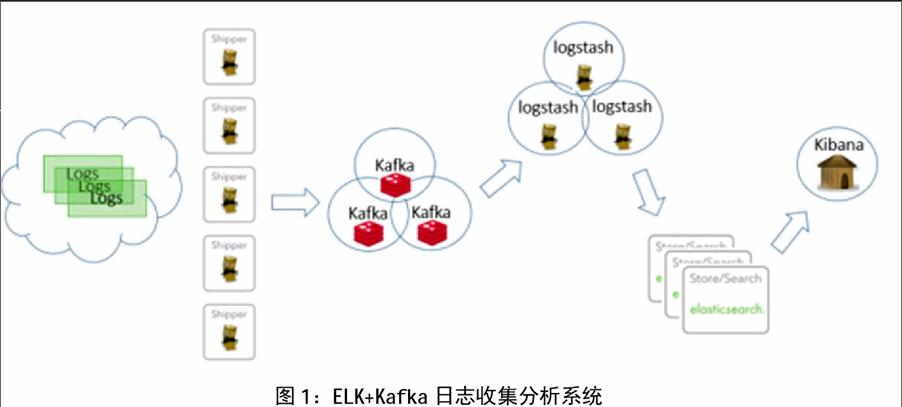
目前开源的日志收集系统有很多,比如Scribe、Flume、Logstash、Fluentd等,日志存储工具有Redis、HDFS、MangoDB、Elasticsearch等,分析软件如Kibana、Graylog2等,构建一个强健的集中化日志管理解决方案,需要多种工具的组合。本文采用ELK+Kafka实现日志收集分析,架构如图1所示。ELK能在大量日志中快速准确定位故障,适合应用级别的实时监控和重要核心服务的报警。
ELK是一套流行的一体化日志处理平台解决方案,提供日志收集、处理、存储、搜索、展示等全方位功能。由分布式搜素引擎ElasticSearch、日志采集解析工具Logstash、分析可视化平台Kibana组成。
Logstash是Ruby编写的一款分布式日志收集系统,利用JVM的线程功能进行并行的数据处理,支持多输入源Input,Filter中可以使用Grok、Mutat等插件来过滤文本和匹配的字段,Output指定日志去向,可以是消息队列、Email、全文搜索引擎等几十种目标端。
Elasticsearch是一个强大的具有搜索功能的无模式数据库,是一个近实时搜索平台,基于Lucene的分布式RESTfull搜素引擎。设计用于云计算中,能够达到实时搜索、稳定、可靠、快速、安装使用方便。支持通过HTTP使用JSON进行数据索引。
Kibana提供日志分析的web可视化界面,利用ElasticSearch搜索功能,以秒为单位可视化数据,支持Lucene的查询字符串的语法和Elasticsearch的过滤功能。
2 Kubernetes
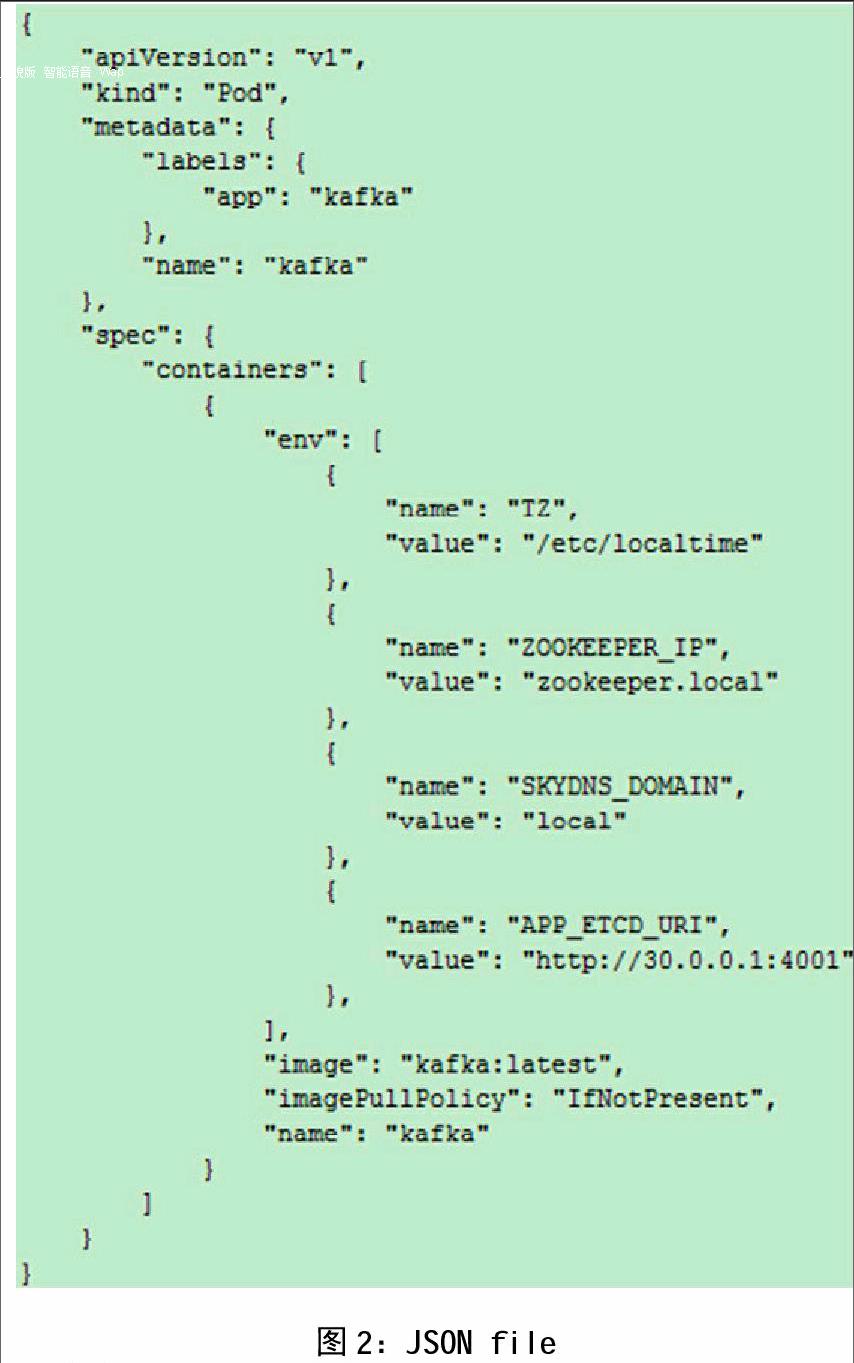
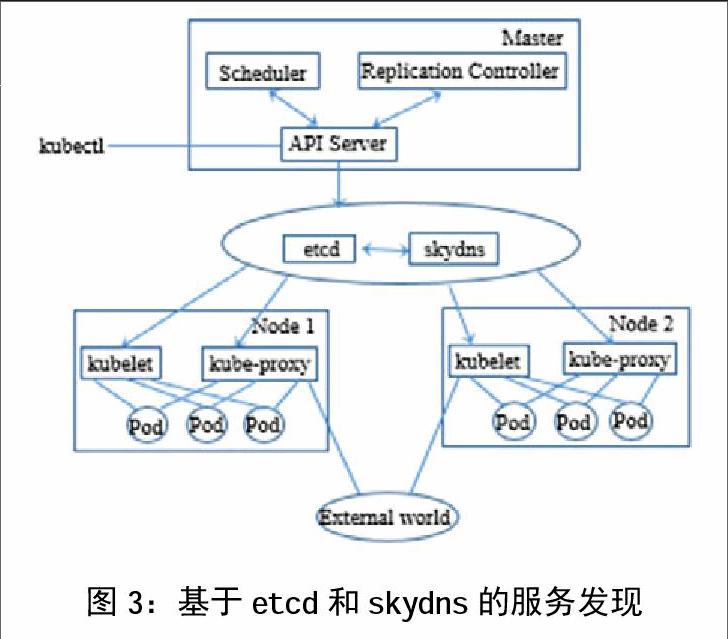
随着云计算的推进,Docker作为主流云技术地位渐渐凸显出来。Docker 是一个开源的应用容器引擎, 让开发者可以打包他们的应用以及依赖包到一个可移植容器中, 然后发布到任何流行的 Linux 机器上,Docker可以快速构建一个高性能、超大规模的宿主机部署,但同时也给容器内日志收集与分析带来了挑战。Kubernetes作为Docker生态圈中重要一员,是自动化容器操作的平台,是Google开源的容器集群管理系统,提供资源调度、均衡容灾、服务注册、动态扩缩容等功能套件。利用Kubernetes能方便地管理跨机器运行容器化的应用。一个典型的Kubernetes架构包括Pod、Container、Label、ReplicationController、Service、Node、KubernetesMaster。基于Kubernetes的ELK只需一个部署文件,使用一条命令就可以部署多层容器的完整集群,可随时扩展或收缩容器规模,简化分布式系统构建的过程。图2显示了部署一个pod所使用的json文件,通过kubectl命令即可部署并运行一个pod,修改类型为‘ReplicationController即可实现多replicas部署。在分布式集群系统中,服务发现功能至关重要,针对企业级系统最重要的是有效地发现部署在各个物理环境中分布式的服务,以及服务发现的引擎本身要能够集群部署。本文采用etcd+skydns的技术组合来实现服务发现,如图3所示。
skydns会通过读取KubernetesAPI获取服务的ip和port信息,同時以watch的方式发现service的变动并收集变动信息,并将对应的ip信息注册到etcd,而skydns通过etcd内的dns记录信息,开启对外端口提供服务。注册和发现组件在容器中独立运行,负责监听端口或者连接到其他主机的端口 ,不需要编写容器植入性代码。可以实现服务注册集群,以及分布式的终端部署集成。
3 日志系统框架
使用Docker部署云平台系统非常方便,但因为容器的隔离性,收集容器内的日志很不方便。容器中应用的日志有两个去向,日志写到控制台或磁盘文件,这两部分日志数据的生命期和容器相同,容器删除后,日志也被删除。收集容器应用的日志可借助Docker的volume功能。在Host机器上开辟一个固定目录/path/a,产生日志的容器将日志文件所在目录mount到/path/a目录下的子目录中,收集日志的容器Logstash再把目录/path/amount到自己容器内。这样日志收集容器就能访问到所有日志文件了, 如图4所示。另外,为了收集容器的stdout、stderr日志,还需要将host的/var/lib/docker/目录mount到日志收集容器中,可以收集到json日志。
基于Kubernetes部署ELK非常方便,有各种现成的image可用。本文将Kubernetes、ELK、Kafka深度整合,构建生产环境,组成分布式日志收集分析系统,如图5所示。多个独立的Logstash agent(Shipper)部署在各个不同的Host上,负责收集不同来源的数据,一个中心Logstash agent(Indexer)负责汇总和分析数据,在中心agent前配置了KafkaBroker作为缓冲区,中心agent后的Elasticsearch用于存储和搜索数据,前端的Kibana提供丰富的图表展示。
Shipper表示日志收集,使用Logstash收集各种来源的日志数据,可以是系统日志、文件、redis、mq等等。Broker作为远程agent与中心agent之间的缓冲区,使用Kafka实现。Logstashagent(Shipper)作为Kafka消息的生产者时,Output 插件需要配置好KafkaBroker的列表,相当于Kafka 集群主机的列表;相应的,用作Kafka消费者角色的 Logstashagent(Indexer),从broker中提取数据,其Input插件就要配置好需要订阅的Kafka中相应消息的主题名称和Zookeeper主机列表,执行相关的分析和处理(Filter)。Kafka通过将数据持久化到硬盘的WriteAheadLog(WAL)保证数据可靠性与顺序性。Kafka是依赖于Zookeeper的,它将每组消费者消费的相应Topic的偏移量保存在Zookeeper中, 除了可靠性和先进的Push&Pull架构外,相较于传统的消息队列,Kafka有更大的吞吐量。简化的Shipper和Indexer配置如图6和图7所示。
Elasticsearch用于存储最终的数据,并提供搜索功能。Kibana提供一个简单丰富的web界面,数据来自于Elasticsearch,支持各种查询、统计和展示,图8为UI动态监控数据库实例产生的各种日志。系统中设计了Syslog主要用于备份Elasticsearch的数据,并可以输出到远程的logserver进行存储。
4 总结
随着虚拟技术的不断发展,大规模云服务及系统的日志处理平台是保障系统稳定运行的重要部分。本文结合目前主流的kubernetes和ELK简单介绍了各自在日志处理系统架构中的功能。日志处理平台不僅需要收集和分析日志,还需要对相应的分析结果进行处理,比如自动报警、提前预警风险等。现实中日志应用场景多种多样,日志处理系统需要不断的完善和优化。
参考文献
[1]李祥池.基于ELK和Spark Streaming的 日志分析系统设计与实现[J].电子科学技术,2015.2(06):674-678.
[2]王亚玲,李春阳,崔蔚,张晶.基于 Docker的PaaS 平台建设[J].计算机系统应用,2016(03).
[3]理解kubernetes核心概念[J].电脑编程技巧与维护,2016(03).
作者单位
诺基亚通信系统技术(北京)有限公司 浙江省杭州市 310000
猜你喜欢
湖南电力(2022年3期)2022-07-07
制导与引信(2017年3期)2017-11-02
通信电源技术(2016年6期)2016-04-20
通信电源技术(2016年5期)2016-03-22
雷达与对抗(2015年3期)2015-12-09
自动化博览(2014年12期)2014-02-28
汽车电器(2014年5期)2014-02-28
智能系统学报(2011年4期)2011-02-17
