
动态社区演化研究进展
2017-05-03 07:37潘剑飞徐丽丽董一鸿
电信科学 2017年1期
潘剑飞,徐丽丽,董一鸿
(宁波大学信息科学与工程学院,浙江 宁波 315211)
动态社区演化研究进展
潘剑飞,徐丽丽,董一鸿
(宁波大学信息科学与工程学院,浙江 宁波 315211)
社区结构是社会网络普遍存在的拓扑特性之一。挖掘社会网络中的社区结构、探测并预测社区结构的变化是社会网络研究中重要的研究课题。主要从时间片处理和动态增量的策略对动态社区演化进行阐述,时间片处理策略介绍了时间片的对比演化、聚类演化、融合演化的研究方法;动态增量策略描述了核心社区、聚类、指标的动态演化的研究方法;最后对社区演化预测的框架进行了归纳总结。
动态社区挖掘;动态社区演化;动态社区演化预测
1 引言
社会网络是边与点的连接组成的图,通过对社会网络的研究,发现社会网络呈现一种内部顶点连接紧密、外部顶点连接松散[1]的结构,即社区结构。社区结构对深入理解和研究社会网络的性质具有很重要的意义,因此社区研究将成为真实社会网络分析的一个重要的研究方向。
自2002年Girvan和Newman提出GN算法思想[2]以来,国内外掀起了社区研究的热潮,各学科领域 (如生物、物理、计算机等)的研究者都带来了很多算法思想,并广泛应用于实际的生活中以解决各个方面的具体问题。随着互联网的快速发展,更多的人加入互联网中,新浪、微博和微信等交互平台很受广大用户的欢迎,用户交互形成的社交网络存在着显著的社区结构,研究社区结构能够进一步确定用户的社交动态。同时以社区结构的形式发现数据内在的联系,对提高网络管理质量提供辅助决策意见,发现社区内的隐含子群结构特征,发现未来的用户流动、用户需求和商品推荐的研究都有很好的指引作用。
当前对社区结构的研究主要集中针对于静态网络中的挖掘算法设计,随着研究的深入,研究者开始关注复杂动态网络中演化社区结构的识别分析。社区结构识别也正经历从静态研究向动态演化分析的转变,动态网络演化社区结构识别的研究逐步成为研究的热点。
动态社区演化的研究过程可分为时间片处理社区演化和动态增量社区演化。时间片处理社区演化是以时间片为单位,对时间片进行分离、聚类或融合处理,并对其进行时间片社区发现和相似度比较或差距比较两个过程,该做法增加了冗余计算量,同时有些比较策略没有合理的依据。动态增量社区演化解决了时间片可能存在的硬划分问题,通过点边的变化判定前一次社区的变化,能细化到每个社区的演化过程,更具合理性和判定社区动态社区变化的准确性。本文最后引出了社区演化的衍生品社区演化预测的框架,概括地论述了整个动态社区演化研究的主体内容。
2 基本概念
定义1 (时间片)动态网络Gt:t+n按时间段分,可表示为{Gt,Gt+1,…,Gt+n},Gt=(Vt,Et)为 t时间段的网络。
定义2 (时间片社区)对每个时间段的网络Gt=(Vt, Et),t=1,2,3,…进行社区发现得 Gt={Ct1,Ct2,…,Ctn},Ctn表示在t时间段的网络中发现的第n个社区。
定义3 (动态网络[3])在t时刻到t+n时刻的动态网络 Gt:t+n可表示为{Ct,ΔCt+1,…,ΔCt+n},Gt=(Vt,Et)表示 t时刻顶点集合为Vt、边的集合为Et的网络。ΔGt+1表示在t+1时刻的更新子图,即Gt+ΔGt+1=Gt+1。
定义4 (动态社区[3])在t时刻到t+n时刻的动态社区 Ct:t+n可表示为{Ct,ΔCt+1,…,ΔCt+n},Ct表示从 t时刻网络 Gt中挖掘的社区。ΔCt+1表示在t+1时刻的更新子社区,即Ct+ ΔCt+1=Ct+1。
定义 5 (社区演化事件[4])对复杂动态网络而言,当网络动态变化时,网络中的社区可能随时间推进而发生持续、缩减、增长、分离、融合、消失、生成等事件,这些事件将导致社区的结构形态发生动态变化,以下对各个事件进行介绍:
· 持续事件表示随时间推进过程中对应的社区变化很小,社区变化范围一般小于5%,如图1(a)所示;
· 缩减事件表示随时间推进过程中对应的社区规模变小,社区变化范围一般为5%~20%,如图1(b)所示:
· 增长事件表示随时间推进过程中对应的社区规模变大,社区变化范围一般为5%~20%,如图1(c)所示;
·分离事件表示随时间推进过程中,社区分成多个部分,包括等量分离和不等量分离两种方式,如图1(d)和图1(e)所示;
·消失事件表示随时间推进过程中,对应的社区结构消失,如图1(f)所示;
·融合事件表示随时间推进过程中,多个社区发生融合成一个社区,包括等量融合和不等量融合两种方式,如图1(g)和图1(h)所示;
·生成事件表示随时间推进过程中,新的社区结构出现,如图1(i)所示。

图1 社区演化事件
3 时间片处理社区演化
时间片处理社区演化是指社区数据按时间段获取形成动态时间片数据,然后以整个时间片为研究单位,对时间片进行分离、聚类或融合等处理后,用静态社区发现算法或静态聚类思想分离出对应的社区,并探索相邻时间片内社区之间的变化,如图2所示。
目前时间片分解社区演化的基本策略有3种:基于时间片的比对演化、基于时间片的聚类演化、基于时间片的融合演化。

图2 时间片分解社区
3.1 基于时间片的比对演化
基于时间片的比对演化的思想相对比较简单,是基于静态社区发现算法进行的改进,即动态社区发现算法上并没有本质的提高,研究目标从算法研究转为比较策略上的改进。其思想是:首先对整个网络进行时间片处理,然后针对每个时间片,用已存在的静态社区发现算法(LPA算法[5]、FCM算法[6]、LMF算法[7]等)进行社区发现,然后用相似性比较策略对相邻时间片社区进行社区比较,发现社区变化的过程并判定内在的演变事件。
3.1.1 顶点比较策略
[8]提出在t时间片社区Ct与t+1时间片社区Ct+1间,顶点变化衡量相似性的比较标准为:

基于此比较标准,结合元社区和二分匹配的方法得到社区演化序列和演化事件。
· 如果在t+1时间片存在社区Ctk+1与t时间片的社区Cti匹配,则社区Cti在t+1时间片存活,社区Ctk+1将被添加到Cti对应的元社区中。
·当t+1时间片的社区不断进入,分别对每个社区用最大相似度二分匹配与t时间片的社区进行匹配,如果t+1时间片的社区与所有 t时间片社区都没有匹配,则认为该社区是在t+1时间片新形成的社区,对它建立一个新的元社区。
在二分匹配过程的同时,t时间片社区Ct与t+1时间片社区Ct+1的匹配情况确定演化事件,同时匹配过程中建立的元社区,每个元社区表示为演化的社区序列。
上述比较分析方法的不足在于判定相似度条件上,其将每个顶点等同看待,这在实际的网络条件下是不合理的,每个社区而言顶点应当有重要程度之分。
3.1.2 核心顶点比较策略
参考文献[9]提出了如何获取核心顶点的算法,核心顶点表示顶点的权值相比其他顶点更高,其中顶点的权值可以由顶点度、PageRank值等指标来衡量。该算法和投票策略相似,对于每个顶点都有权去评估连接它的核心顶点,W(Ni)表示顶点Ni的度,如果W(Ni)的值越大,那么Ni点越重要。当W(Ni)≥W(Nj),Ni的核心值Cen(Ni)应该增大|W(Ni)-W(Nj)|的值,否则Ni的核心值Cen(Ni)应该减少|W(Ni)-W(Nj)|的值,通过一轮投票后,当Cen(Ni)的值为非负值时,Ni为核心顶点,否则为普通顶点。根据以上策略获取到每个时间片的核心点,比较相邻时间片内核心点来确定演化社区序列。
上述比较分析方法的不足在于只考虑社区中的核心点的变化,这种核心点的比较策略没有充分的依据说明方法的有效性,同时没有从整体的角度去考虑社区的演化。
3.1.3 顶点数量与重要程度比较策略
参考文献[4]给出了一种更合理的方法即GED算法,该算法根据演化过程中社区顶点数量和顶点重要程度共同的变化衡量相似性。社区顶点的重要程度可以根据PageRank的思路进行初始化:

在t时间片中的社区Ct中与t+1时间片社区Ct+1的相似度可由I(Ct,Ct+1)和I(Ct+1,Ct)共同来衡量,I(Ct,Ct+1)表示为:

社区演化的事件可以由I(Ct,Ct+1)、I(Ct+1,Ct)和社区的规模变化共同来决定:
· 当I(Ct+1,Ct)≥α,I(Ct+1,Ct)≥β,|Ct|=|Ct+1|时,社区 Ct
以社区Ct+1的形式在t+1时间片持续;
· 当I(Ct+1,Ct)≥α,I(Ct+1,Ct)≥β,|Ct|>|Gt+1|或者 I(Ct+1, Ct)≥α,I(Ct+1,Ct)≥β,|Ct|≥|Ct+1|,并且社区Ct在t+1时间片只有社区Ct+1一个社区与之匹配时,社区Ct在t+1时间片缩减为社区Ct+1;
· 当I(Ct,Ct+1)≥α,I(Ct+1,Ct)≥β,|Ct|<|Ct+1|或者,I(Ct,Ct+1)≥α,I(Ct+1,Ct)<β,|Ct|<|Ct+1|,并且社区Ct在t+1时间片只有社区Ct+1一个社区与之匹配时,社区Ct在t+1时间片增长为社区Ct+1;
· 当I(Ct,Ct+1)≥α,I(Ct+1,Ct)≥β,|Ct|≥|Ct+1|并且社区Ct在t+1时间片不止社区Ct+1一个社区与之匹配时,社区Ct在t+1时间片分离;
· 当I(Ct,Ct+1)≥α,I(Ct+1,Ct)<β,|Ct|≤|Ct+1|并且社区Ct+1在t+1时间片不止社区Ct一个社区与之匹配时,社区Ct在t+1时间片融合;
· 当在t+1时间片的每一个社区Ct+1,I(Ct,Ct+1)<10%,I(Ct+1,Ct)<10%时,社区Ct在t+1时间片消失;
· 当在t时间片的每一个社区Ct,I(Ct,Ct+1)<10%,I(Ct+1,Ct)<10%时,社区Ct+1在t+1时间片生成。
GED算法从顶点数量和顶点重要程度共同来比较两个时间片社区相似度,在实际运用中的合理性和实用性。
3.2 基于时间片的聚类演化
基于时间片聚类的演化是在静态聚类分析算法的基础上,提出了一个动态演化聚类思想。参考文献[10]中提出社区在相邻时间片间的变化应该不大,对此在考察t时间片内的社区Ct时,既要满足当前t时间片内在的结构,同时用t-1时间片来规整t时间片的社区,并且提出一种衡量t时间片社区Ct质量的标准,可以表示为:

其中,CS用于衡量t时间片内社区发现是否符合当前社区内部的交互,CT用于衡量t时间片的社区和t-1时间片的社区结构的差异,并用KL散度来刻画两者的损失。此方法的思想虽然是时间片处理的策略,但是在发现社区的结构时提出了用历史社区结构来做参考的思想,更具合理性,更符合时间序列的思想。但是,社区结构的差异和发现过程是不断地对矩阵进行迭代计算过程,整个过程时间复杂度很高,并不符合现实生活中真实的大规模网络数据。在参考文献[11]中也提出了此思想,但是文献属于非重叠社区发现并且局限在规模不可变化的动态社区变化的过程中。
3.3 基于时间片的融合演化
基于时间片融合的演化是将相邻时间片的网络数据进行融合,并对融合后的数据进行静态社区发现后,与前一时间片的社区结构进行相似性比较和判定归属分离出当前时刻的社区结构。
参考文献[12,13]中使用到派系过滤算法,该算法用于重叠最大团社区发现的经典算法(CPM算法),通过判断k完全图的相互重叠可达性来对最大团进行发现,在参考文献[14]中提出考虑社区应该考虑其内部的结构分布,因此,从内部结构方面来考虑用此方法进行社区发现,更符合现实的网络数据的结构分布,并且社区的凝聚程度相对其他策略更高,但是随着 k的增大,发现社区的时间复杂度将急剧增加。时间片融合的重叠最大团社区发现的思想是:首先将相邻时间的网络Gt和Gt+1合并成为中间网络Gt,t+1,然后对Gt,t+1网络用CPM算法进行社区发现,结合已存在网络的社区结构,用顶点的Jaccard相似度进行相似度比较,根据比较结果分离出Gt+1的社区结构。其顶点的相似度比较如下:

其方法在社区发现CPM有一定优势的同时,融合后分离的策略考虑了历史社区的结构分布,并不是时间片单独处理策略,解决了时间片孤立处理的硬分割问题。但是假设两个时间片间的社区变化不是很大的情况下,每次都要进行社区发现,无形中增加了社区演化发现过程中的时间复杂度。
3.4 时间片策略综合比较
时间片的比对演化、聚类演化、融合演化都属于时间片处理的社区演化策略,时间片的比对演化思想,在时间片处理方面过于粗糙,直接将其时间片分离,相邻时间片社区划分之间可能呈现显著的结构变化,属于硬分割问题。时间片的聚类演化思想,当前时间片社区的划分依据当前时刻社区情况和历史时间片社区的划分来决定,根据社区在相邻时间片变化不是很大的原理,该考虑和历史时间片社区的情况的差异最小化的思想具有合理性。时间片的融合演化进行相邻时间片融合然后对重叠社区进行发现虽然解决了硬分割的问题,但是这3个策略不属于真正的动态社区演化,对每个时间片处理复杂度高,甚至还得用些相似度比较获取社区演化序列,然而比较策略标准不一,没有合理的依据。时间片处理社区演化策略综合比较见表1,其中n表示网络顶点的数目,e表示网络边的数目,m表示社区的数目,d表示网络的度(顶点度的均值)。
4 动态增量社区演化
动态增量社区演化是指根据初始时刻网络的社区,随时间的变化更新社区结构,从而发现动态社区演化序列和事件。相比于时间片处理的社区演化,动态增量的社区演化充分利用了前次识别的结果,在前次的结果上进行动态判定,真正实现了动态识别和演化。

表1 时间片处理策略综合比较
4.1 基于核心社区的动态演化
基于核心社区的动态演化的思想在于首先判定核心点组成的核心社区的动态变化,然后扩展为整个网络的社区变化。
参考文献 [15]中提出追踪社区演化的统一框架——FICET(fast increment community evolution tracking,快速增量社区演化跟踪)框架,整个社区演化过程既考虑当前社区结构的合理性,又考虑了当前社区结构和历史社区结构的衔接性;同时,追踪社区演化针对核心社区的增点、增边、减点和减边的4种变化的研究,既能保证高效率演化也能快速跟踪社区演化的过程。整个框架如图3所示。

图3 FICET框架
整个框架的思想主要分为两个步骤:社区的发现和核心社区动态增量演化扩展。社区发现是动态增量演化的基础,随后的演化都是在此基础上的。社区发现分为3个步骤。
步骤 1 通过改变后的PageRank(modified weighted pagerank,MP)算法,发现网络的核心点、连接边组成核心的子图。利用改进后的MP算法求PageRank值:

步骤 2 对核心的子图,运用高层聚类(high-level clustering,HC)算法发现核心的社区集。其中HC算法中引入适应度函数来作为核心社区形成标准:

步骤3 对核心的社区集,运用扩展(core community expanding,EC)算法扩展为整个网络的社区。其中EC算法引入顶点和各个核心社区间亲密度的概念,以顶点和各个核心社区间的大小来硬分割社区。顶点和核心社区的亲密度为:

社区发现后,将经历核心社区动态增量演化扩展的过程,增量演化运用增量 (incremental community evolution, IC)算法对前一时刻的核心社区进行增量变化来发现当前核心社区。同时引入社区结构稳定参数(community structure stability,CSM)来防止数据漂移的情况。扩展过程和社区发现的扩展过程一致。其中,IC算法考虑核心顶点集和对应的边集的变化:

其中,Vdel表示在t+1时刻消失的顶点,Vnew表示在t+1时刻新增加的顶点,Edel表示在t+1时刻消失的边,Enew表示在t+1时刻新增加的边。针对每一种增点、增边、减点和减边的变化来动态判定社区可能发生的变化。增点、增边可能导致社区的增长和社区的融合事件,减点、减边可能导致缩减和消失事件。
快速增量社区演化跟踪框架体现了动态增量社区演化的本质思想由t时刻核心点的社区来指导t+1时刻核心社区的发现和核心社区演化,然后对演化后核心社区通过扩展算法来获取整个网络内的社区结构。追踪社区演化针对核心点社区的动态变化,既能保证演化的准确性,也能快速跟踪社区演化的过程。但是,核心社区扩展的过程采用的是顶点强硬社区分配,不能对重叠社区进行发现,同时社区结构稳定参数不够合理。
4.2 基于聚类的动态演化
基于聚类的动态演化思想在于将静态聚类的思想和概念运用在动态更新社区和演化事件跟踪的过程。
参考文献 [16]中基于静态密度聚类思想提出了DENGRAPH的算法。动态演化的过程,考虑积极的改变和消极的改变两个方面。积极的改变为考虑新的核心顶点、新的边界顶点、新的邻接顶点添加时导致原本社区的变化。
·新的核心顶点,考察是否与已存在的社区存在连接,如果存在,将其添加到连接社区中,否则形成新的社区。
·新的边界顶点,考察边界顶点是否与社区中的核心顶点密度可达,如果可达,将其添加在社区中,否则作为孤立点处理。
·新的邻接顶点,将其添加到邻接的社区,并且更新社区内的强度。
积极的改变可产生社区的生成、增长和融合事件,如图4所示。

图4 积极改变
消极的改变为考虑核心顶点、邻边顶点、边界顶点和核心顶点的边,核心顶点间边消失时导致原本社区的变化。
· 核心顶点的消失,考虑核心顶点周围的顶点,判断其与其他核心顶点的可达性来决定原本顶点的归属社区。
· 邻接顶点的消失,当邻边顶点为边界顶点时,更新社区的强度。
· 边界顶点和核心顶点的边消失,原本的边界顶点可能将不可达,边界顶点将成为孤立点。
· 连接核心顶点边的消失,两个核心顶点将不可达,可能产生社区间的分离事件发生消极的改变可产生社区的消失、缩减和分离的事件,如图5所示。
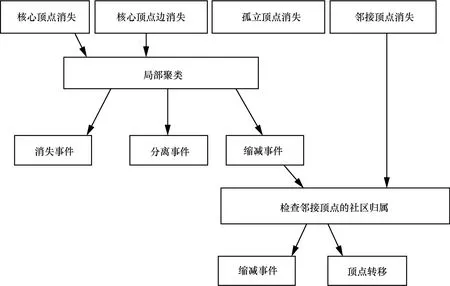
图5 消极的改变
采用聚类的思想进行动态社区演化发现,方法简易,能根据静态聚类对应的参数和顶点变化来判定社区的变化和对应的社区事件更具合理性,而且能细化到每个细节的变化可能导致的社区演变事件。
4.3 基于指标的动态演化
基于指标的动态演化的思想主要在于通过点、边社区内和社区间的变化,设定顶点的指标判定顶点归属社区,从而衡量社区的动态演化过程。
参考文献[17]中根据增点、增边、减点、减边和对于顶点是否归属同一个社区,建立候选的顶点集后判定社区演化的强度,如果强度大于阈值时,该时刻社区重新进行社区发现,否则根据候选集中顶点在相邻社区内顶点和邻接顶点的永久度大小,动态更新顶点的归属社区,从而动态更新社区。其社区的演化强度可表示为:

社区演化强度本质而言就是不断累加社区点边变化的强度,如果变化强度超过一定范围就认为社区演化可能产生数据漂移现象,应当重新进行社区发现的过程来防止社区演化异常,这是演化事件累积指标,并不能明确指出当前是否已经发现偏移情况。其顶点的永久度可表示为:

顶点的永久度考虑两个方面:一个方面是社区顶点的社区内连接和社区外连接比,另一个方面是社区内部结构的结构有效度。
参考文献[17]用顶点的归属社区变化来合理地确定整个动态过程,但是,并没有发现整个社区演化的事件,并且顶点的永久度和社区发现过程也是引用参考文献[18]的思想。
参考文献[19]根据增加、减少离群顶点,增加、减少边,顶点从一个社区转移到另一个社区的5种变化,判断顶点的社区成员度的变化,从而判定顶点的归属社区,进而实现动态社区发现。
4.4 动态增量策略综合比较
动态增量社区演化分为核心社区的动态演化、聚类的动态演化、指标的动态演化3个部分,其区别在于核心社区的动态演化主要通过核心社区和扩展判定社区的演化,在时间复杂度上要优于其他策略,但是从探索社区变化的细节和探索演化事件的准确性方面,聚类和指标的动态变化要高一些,但是依据参考文献[14]中的思想,3种策略欠考虑社区内部的结构方面,本质以边作为研究对象,把所有的边同等看待,在实际的网络中表现的社区结构并不明显。动态增量社区演化策略综合比较见表2,其中α为两个时刻间的变化事件转为顶点的变化比率。
5 社区演化预测
社区演化预测是历史动态社区演化事件判定之后衍生出的新的研究热潮,在已知历史社区本身的特征和历史社区演化事件的基础上,如何探究接下来社区会发生怎么样的演化事件,即社区演化预测。社区演化预测的思路具有代表性的是Stanislaw提出的参考文献[20],其他文献在社区演化的思路方面和 Stanislaw大体一致,主要还是在时间片处理社区演化的基础上衍生的课题,如参考文献[21]预测演化事件的出发点在于不同的网络,对不同时间片运用不同的静态社区发现算法将导致最终不同的社区演化事件的预测准确性。参考文献[22]预测演化的周期,本质而言就是判定下一时间片社区是否消失,从而确定社区演化周期。Stanislaw提出的社区演化预测思路如图 6所示。
社区演化预测思想主要包括以下3个方面:
· 根据以上动态社区演化判定演化序列中两社区间的演化事件;
·发现社区内部的特征、社区间的特征和演化序列中两个时间段的特征变化;
· 运用合理的机器学习方法进行分类预测。
5.1 特征选取
参考文献[20]中的特征选择主要是从社区整体特征、点特征、点特征量统计计算3个角度,社区整体特征包括社区的大小、社区内点与点之间的连接密度、社区内部的凝聚度、社区核心顶点、社区边的相互作用;点特征包括点的入度、出度,连接顶点的最短路径,点对应的特征向量,顶点与其他社区内顶点距离和;点特征量统计计算包括对点的所有特征进行求和、最小值、最大值、均值等运算。社区内点与点之间的连接密度为:

表2 动态增量策略综合比较

图6 社区演化预测思路

当顶点与顶点之间存在连接时,a(i,j)为1。社区内部的凝聚力为:

其中,w(i,j)表示顶点i与顶点j组成边的权值,n表示在社区内的顶点数,N表示整个网络内的顶点数。社区边的相互作用为:

其中,m表示整个网络中的边的数目,当顶点i与顶点j之间存在连接时,a(i,j)为1。
参考文献[21]中的特征选择包括社区内部的特征、社区间的特征和演化序列中两个时间段的特征变化,社区内部特征包括核心点的比例、核心点的度、核心点的凝聚度、核心点的特征向量;社区间的特征包括社区的大小、社区的凝聚度、社区聚类有效性、社区内连接度、社区的度的均值、社区特征向量的均值;演化过程中两个时间段的特征变化为以社区角度来考察对应社区特征的变化。其社区聚类有效性为:

其中,#△表示在社区内组成的三角形的数目,#Triples表示整个网络中三角形的数目。社区内连接度为:

其中,sh(u,v)表示社区内两点间组成的最短路径。
5.2 分类预测
参考文献[20]中获取社区的特征后首先进行特征归一化及筛选,然后运用了机器学习的分类算法 J48、RandomForest、AdaBoost、Bagging、Logistic进行训练,对数据集进行十折交叉验证,得到预测模型,然后用模型对对应时间片的社区进行预测。参考文献[22]中提出了对每种事件分开进行训练,分别对每种事件进行判定预测准确性,同时调用了weka的api对特征进行优化选取和降维,分析社区特征对最终预测的重要程度。
由于社区网络的复杂性、基于时间片硬分割分离的社区发现和相似度定义社区历史演化事件的不合理性,发现社区事件会出现严重的偏移情况,社区消失的事件比其他社区事件要多很多,参考文献[21]中提出了针对每个事件的进行weka中的SMOTE采样,使训练样本每个事件的训练样本数目达到均值,然后对每个机器学习分类算法进行训练,这种策略没有合理的依据,同时对于以上预测方法,都是将每个时间片的社区特征归结在一起进行训练,没有对每个时间片社区演化序列作为训练的对象,无形中缺少了社区演化序列间的时间特征。
6 结束语
介绍了动态社区演化的研究现状和社区演化预测的相关工作。动态社区演化主要对当今现存的主流的时间片处理策略和动态增量演化策略进行阐述,但是现今研究动态社区演化还处在单机处理阶段。随着大数据时代的来临,更多的研究人员将对社区的动态演化过程进行分布式处理,提高整个演化计算的效率。同时,动态社区演化衍生出的社区演化预测还处于刚起步阶段,没有成熟的理论架构基础,如何建立有效预测模型和统一演化预测过程将成为未来的研究趋势。
参考文献:
[1]WANG L,CHENG X Q.Dynamic community online social network discovery and evolution [J].Chinese Journalof Computers,2015,38(2):219-237.
[2]GIRVAN M,NEWMAN M E J.Community structure in social and biological networks[J].Proceedings of the National Academy of sciences of United States of America,2002,99(12):7821-7826.
[3]PEI L,LAKSHMANAN L V S,MILIOS E E.Incremental cluster evolution tracking from highly dynamic network data[C]//IEEE International Conference on Data Engineering,March 31-April 4, 2014,Chicago,USA.New Jersey:IEEE Press,2014:3-14.
[4]BRÓDKA P,SAGANOWSKIS,KAZIENKOP.GED:the method for group evolution discovery in social networks[J]. Social Network Analysis and Mining,2013,3(1):1-14.
[5]WU T,CHEN L,GUAN Y,et al.LPA based hierarchical community detection [C]//IEEE International Conference on Computational Science and Engineering,August 22-24,2014, Vancouver,Canada.New Jersey:IEEE Press,2014:185-191.
[6]ZHANG S,WANG R,ZHANG X.Identification of overlapping community structure in complex networks using fuzzy C-means clustering [J].Physics A:StatisticalMechanics and its Applications,2007,374(1):483-490.
[7]LANCICHINETTI A,FORTUNATO S,KERTÉSZ J.Detecting the overlapping and hierarchical community structure of complex networks[J].New Journal of Physics,2009,11(3):19-44.
[8]TAKAFFOLI M,SANGI F,FAGNAN J.Community evolution mining in dynamic social networks[J].Procedia-Social and Behavioral Sciences,2011,22(22):49-58.
[9]WANG Y,WU B,DU N.Community evolution of social network: feature,algorithm and model[J].Physics,2008(3):31-46.
[10]LIN Y R,CHIY,ZHU S.Facetnet:aframework for analyzing communities and their evolutions in dynamic networks [C]//17th International Conference on World Wide Web,April 21-25,2008,Beijing,China.New York:ACM Press,2008:685-694.
[11]CHAKRABARTI D,KUMAR R,TOMKINS A.Evolutionary clustering[C]//12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,August 5-8,2011, Philadelphia,PA,USA.New Jersey:IEEE Press,2011:332-337.
[12]PALLA G,VICSEK T.Quantifying social group evolution[J]. Nature,2007,446(7136):664-7.
[13]PALLA G,BARABÁSI A,VICSEK T.Community dynamics in socialnetworks [C]//SPIE 4th InternationalSymposium on Fluctuations and Noise,International Society for Optics and Photonics,July 2-August 10,2007,San Diego,USA.New Jersey:IEEE Press,2007:273-287.
[14]PRAT P,REZ A,DOMINGUEZ-SAL D,et al.Put three and three together:triangle-driven community detection [J].ACM Transactions on Knowledge Discovery from Data,2016,10(3): 1-42.
[15]LIU Y,GAO H,KANG X.Fast community discovery and its evolution tracking in time-evolving social networks[C]//IEEE International Conference on Data Mining Workshop,November 14-17,2015,Atlantic,NJ,USA.New Jersey:IEEE Press, 2015:13-20.
[16]FALKOWSKI T,BARTH A.Studying community dynamics with an incremental graph mining algorithm[C]//Learning from the Past& Charting the Future ofthe Discipline Americas Conference on Information Systems,August 14-17,2008,Toronto, Canada.New Jersey:IEEE Press,2008.
[17]LI X,WU B,GUO Q,et al.Dynamic community detection algorithm based on incremental identification [C]//IEEE International Conference on Data Mining Workshop,March 3-11, 2015,Toronto,Canoda,New Jersey:IEEE Press,2015:900-907.
[18]CHAKRABORTY T,SRINIVASAN S,GANGULY N.On the permanence ofverticesin network communities[C]//ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,August 24-27,2014,New York,NY,USA.New York:ACM Press,2014:1396-1405.
[19]LI J,HUANG L,BAI T.CDBIA:A dynamic community detection method based on incremental analysis [C]//International Conference on Systems and Informatics,May 19-21,2012,Yantai, China.New Jersey:IEEE Press,2012:2224-2228.
[20]SAGANOWSKI,STANISLAW.Predicting community evolution in social networks[J].Entropy,2015,17(5):3053-3096.
[21]SHAHRIM,GUNASHEKARS,DOMARVSMV,etal. Predictive analysis of temporal and overlapping community structures in social media [C]//International Conference Companion on World Wide Web,April 11-15,2016,Montreal, Canada.New Jersey:IEEE Press,2016.
[22]TAKAFFOLI M,RABBANY R,ZAIANE O R.Community evolution prediction in dynamic social networks[C]//IEEE/ACM InternationalConference on Advancesin SocialNetworks Analysis and Mining,August 17-20,2014,Beijing,China.New Jersey:IEEE Press,2014:9-16.
Research progress of dynamic community evolution
PAN Jianfei,XU Lili,DONG Yihong
Faculty of Electrical Engineering and Computer Science,Ningbo University,Ningbo 315211,China
Community structure is one of the topological characteristics of social network.It is an important research topic in social network research to explore the structure of community,detect and predict the change of community structure.The evolution of dynamic community was discussed from time slicing processing and dynamic increment strategies.The time slice processing strategy introduced the comparative evolution of the time slice,the clustering evolution of the time slice,and the fusion evolution of the time slice.The dynamic increment strategy described the dynamic evolution of the core community,the dynamic evolution of the cluster and the dynamic evolution of the index.Finally,the framework of community evolution prediction was summarized.
dynamic community mining,dynamic community evolution,dynamic community evolution prediction
TP391
A
10.11959/j.issn.1000-0801.2017026

潘剑飞(1991-),男,宁波大学信息科学与工程学院硕士生,主要研究方向为大数据、数据挖掘。

徐丽丽(1993-),女,宁波大学信息科学与工程学院硕士生,主要研究方向为大数据、数据挖掘。

董一鸿(1969-),男,博士,宁波大学信息科学与工程学院教授,主要研究方向为大数据、数据挖掘和人工智能。
2016-12-15;
2017-01-06
董一鸿,dongyihong@nbu.edu.cn
浙江省自然科学基金资助项目(No.LY16F020003)
Foundation Item:Zhejiang Provincial Natural Science Foundation of China(No.LY16F020003)
猜你喜欢
中等数学(2021年9期)2021-11-22
国际比较文学(中英文)(2019年1期)2019-11-12
山东科学(2018年6期)2018-12-20
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
东方教育(2016年4期)2016-12-14
电子设计工程(2015年6期)2015-02-27
中国校外教育(下旬)(2014年10期)2014-11-20
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
中学生数理化·高一版(2009年6期)2009-08-31
