
一种基于Boosting的集成学习算法在银行个人信用评级中的应用
2017-06-06 07:37陈力黄艳莹游德创
价值工程 2017年18期
陈力+黄艳莹+游德创
摘要: 本文针对银行个人信用数据的分类预测问题,从数据集的特征选择和集成学习两个角度出发,提出了PCA-Adaboost-Logistic集成学习算法。在采用Accuracy和AUC作为分类模型评价指标的前提下,本文选取了源于澳大利亚某银行的个人信贷数据集进行测试。测试结果表明本算法在有效提取关键特征后提高了Adaboost的稳定性,并且在分类准确度上相比单纯使用Logistic分类器有不同程度的提高。
Abstract: This paper focused on classification prediction problem of the bank personal credit data, proposed a PCA-Adaboost-Logistic ensemble learning algorithm based on feature selection and ensemble learning. Accuracy and AUC were used as the classification model evaluation metric under the premise, this paper used the credit data sets from Australian banks to test the proposed algorithm. The results show that the proposed algorithm improves the stability of the Adaboost after extract the key features, and the classification accuracy is higher than the Logistic classifier.
关键词: 信用评级;主成分分析;Adaboost;逻辑回归
Key words: credit score;PCA;Adaboost;Logistic Regression
中图分类号:F830.5 文献标识码:A 文章编号:1006-4311(2017)18-0170-03
0 引言
1936年,费舍尔[1]提出了统计判别分析的概念,这是信用评级领域的基础。后来,大卫·杜兰德[2]在1941年运用了几种算法来区分好的贷款和坏的贷款。1980年,银行业专家鼓励对信用卡使用信用评级,这也是首次将信用评级应用到其他产品。托马斯[3]定义信用评级为认识银行客户的过程,为了根据一系列预定的标准给他们发放贷款。现在,许多关于信用评级的研究集中到人工智能技术上,比如人工神经网络、遗传算法和支持向量机,这些算法比统计优化方法更能区分客户的好坏。此外,基于集成学习算法的信用评分模型已经被广大的研究人员所使用,他们的研究成果已经证实这种模型比单纯的分类算法模型拥有更好的性能。
基于以上的研究背景,本文采取了融合特征选择和集成算法的PCA-Adaboost-Logistic集成学习算法来评估银行客户信用等级。本算法首先利用PCA对数据集进行特征选择,然后采用Adaboost集成学习框架,提出基于Logistic分类器的Adaboost算法,该算法有效提升了分类模型的学习能力,在预测银行客户信用等级方面具有良好的性能。
1 PCA-Adaboost-Logistic集成学习算法
1.1 PCA
PCA,即Principal Components Analysis,也就是主成分分析。PCA是一种常用的数据分析方法,它通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降维。
1.2 Adaboost-Logistic分类算法
1.2.1 Adaboost算法
Boosting,也称为增强学习或提升法,是一种重要的集成学习技术,能够将预测精度仅比随机猜测度略高的弱分类器增强为预测精度高的强分类器。Adaboost正是其中最成功的代表,其被评为数据挖掘十大算法之一[4]。该算法是一种迭代算法,是由Schapire和Freund在1995年共同提出的[5][6][7]。
Adaboost算法的基本思想是:开始时,每个样本对应的权重是相同的,即其中m为样本个数,那么每个训练样本的初始权重都是1/m,在此样本分布下训练出一弱分类器。基本规则是对训练失败的样本赋予较大的权重,这样下次迭代时分类器将重点学习那些失败的样本,而对于分类正确的样本,降低其权重,从而得到一个新的样本分布。在新的样本分布下,再次对样本进行训练,得到弱分类器。依次类推,经过T次循环,得到T个弱分类器,把这T个弱分类器按一定的权重叠加起来,得到最终想要的强分类器。
1.2.2 Logistic 回归
Logistic回归,即Logistic Rregression。Logistic回归是概率型非线性回归模型,是研究二分类观察结果y与一些影响因素(x1,x2,…,xn)之间关系的一种多变量分析方法。通常的问题是,研究某些因素条件下某个结果是否发生,比如本文中根据银行客户的数据信息来评价该客户是“Good(好客户)”或者“Bad(坏客户)”。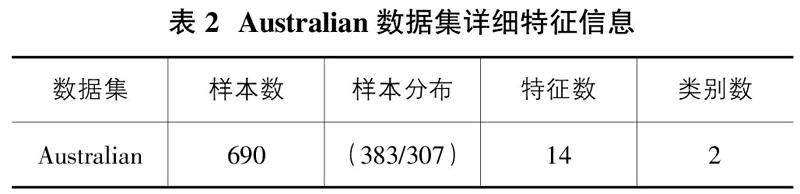
1.3 PCA-Adaboost-Logistic集成學习算法
PCA-Adaboost-Logistic集成学习算法首先采取PCA进行特征选择,之后用经特征选择的数据来训练模型,然后通过模型对测试数据集进行分类,得到分类结果,并且计算出模型预测的精度和AUC值。PCA-Adaboost-Logistic集成学习算法的具体流程如表1所示。
2 數据准备和模型评估指标
2.1 数据集的描述
一些来源于现实世界的公共数据集已经非常有名,而且在学者的文章中都有广泛采用,这些数据集很容易地可以从UCI数据库中获得。本文所使用的个人信贷数据集Australian采集于UCI数据库、源于澳大利亚某银行。这个数据集的详细特征信息如表2所述。
2.2 数据预处理
数据集Australian共有690条记录,每一条记录有15个字段组成。这其中前面14个字段是有关银行客户信贷信息的描述,最后一个字段是银行对客户信用级别的定义,该字段分为两类,分别是:“Good(好客户)”、“Bad(坏客户)”。
以上部分对Australian数据集进行了简单的总结分析,明显发现每个数据集的特征属性都比较多。然而,这些特征属性对目标属性的影响程度大不相同,因此使用PCA对数据集进行特征选择从而达到降低数据维度的步骤不可或缺。另外,数据集中的属性的类型各不相同,有数值型、字符型等,因此我们将字符型属性对应转换成数值型属性,这样有利于后文实验的开展。
2.3 模型评价指标
在传统的分类方法中,常用准确度(Accuracy)作为评价指标。然而,很多情况下,仅仅依靠准确度不足以区分分类模型的优劣。所以,为了让所提出的模型的预测结论可靠,本文在模型准确度的基础上,新增AUC(area under the curve)作为评估分类模型性能的指标。AUC就是ROC(receiver operating characteristic)曲线下方的面积,取值在0.5到1之间。ROC曲线是一种使用率很高的分类器评价指标,它是基于混淆矩阵得来的,表3就是一个分类问题的混淆矩阵。
根据上面的混淆矩阵,有以下概念:
3 实验设计及结果分析
3.1 实验设计
为了同时验证本文提出的PCA-Adaboost-Logistic算法中Adaboost的性能和特征选择的有效性,实验分别测试了不经过特征提取也不使用Adaboost的单纯Logistic算法、不经过特征提取使用Adaboost-Logistic算法、采用特征提取的PCA-Logistic算法、采用特征提取的PCA-Adaboost-Logistic算法四种算法所得出的Accuracy和AUC。在实验中,我们采用十字交叉验证(10-fold cross-validation)的测试方法。这种方法的基本思想是把原始数据分成十份,轮流将其中9份作为训练集,1份作为测试集。首先用训练集对分类器进行训练,然后利用测试集来测试训练得到的模型,最后评价模型的分类性能。在使用十字交叉验证方法时,会得到10次模型评价结果,将这10次结果的平均值作为模型最终的评价指标。另外,试验中集成学习算法Adaboost的迭代次数取值100。表4为以上四种算法的Accuracy和AUC对比情况。
3.2 结果分析
从表4可以看出,单纯使用Logistic回归的分类模型在Accuracy和AUC值上都比其他三种模型低,这说明单纯的Logistic算法的预测精度和稳定性都有很大的改善空间。在使用Logistic回归的前提下,加入集成学习算法Adaboost使得模型的分类精度和稳定性有了显著的提升,同理,对数据集进行特征选择后Logistic回归算法预测的精度也有了极大的提升,同时也更加稳定,这说明数据集的质量对分类模型的影响十分大,从某种程度上决定了分类模型的性能。而且,可以很容易地看出,PCA-Adaboost-Logistic算法较前三种算法的性能更加优秀,这种模型的预测精度和稳定性都表现地很出色。因此基于数据处理的集成学习算法较单纯的分类算法具有更好的性能。
4 结论
本文提出了PCA-Adaboost-Logistic集成学习算法,该算法首先利用PCA对数据进行特征选择,选取最优特征子集后采用Adaboost-Logistic分类算法进行分类。在使用相同组数据集的前提下,实验使用Logistic、Adaboost-Logistic、PCA-Logistic和PCA-Adaboost-Logistic四种分类算法分别对银行客户进行信用评级,实验结果证实PCA-Adaboost-Logistic集成学习算法较其他三种算法的性能更优越。因此,集成学习算法较单纯的分类器具有更优良的分类性能。
参考文献:
[1]Fisher, R. A. (1936). The use of multiple measurements in taxonomic problems. Annals of Human Genetics, 7(2), 179-188.
[2]Durand, D. (1941). Risk elements in consumer instalment financing. NY: National Bureau of Economic Research.
[3]Crook, J. N., Edelman, D. B., & Thomas, L. C. (2007). Recent developments in consumer credit risk assessment. European Journal of Operational Research, 183, 1447-1465.
[4]Zhou Z H, Yang Y, Wu X D, Kumar V. The Top Ten Algorithms in Data Mining. New York, USA: CRC Press, 2009,127-149.
[5]Freund Y, Schapire R E. A decision-theoretic generalization of on-line learning and an application to Boosting. Journal of Computer and System Sciences, 1997, 55(1): 119-139.
[6]Freund Y, Schapire R E. Experiments with a new Boosting algorithm. In: Proceedings of the 13th Conference on Machine Learning. San Francisco, USA: Morgan Kaufmann,1996. 148-156.
[7]Schapire R E, Singer Y. Improved Boosting algorithms using confidence-rated predictions. Machine Learning, 1999,37(3): 297-336.
猜你喜欢
中国房地产·学术版(2016年10期)2016-11-18
大学教育(2016年11期)2016-11-16
中小企业管理与科技·上旬刊(2016年10期)2016-11-15
考试周刊(2016年84期)2016-11-11
