
3D_EW在MIC并行编程中的移植与实现研究
2017-06-10 08:38李薛剑许兴中
实验室研究与探索 2017年4期
李薛剑, 罗 京, 鲁 昶, 许兴中
(安徽大学 计算机科学与技术学院, 合肥 230601)

3D_EW在MIC并行编程中的移植与实现研究
李薛剑, 罗 京, 鲁 昶, 许兴中
(安徽大学 计算机科学与技术学院, 合肥 230601)
3D_EW是一款用于石油勘探领域的应用程序,其运行需要极高的计算能力支持,在CPU上进行大规模计算时效率极低,而MIC卡为英特尔公司推出的基于集成中和架构的至强融核产品,可以提供数百个同时运行的硬件线程,带来极高的并行性。将3D_EW程序并行化并移植于MIC卡,实验表明:3D_EW进行大规模运算时在MIC并行运行速度远大于仅利用CPU时的串行运行速度。
三维弹性波建模(3D_EW); MIC; 移植; 并行; 优化策略
0 引 言
随着现代技术的高速发展,串行程序往往不能满足人们的对各方面的要求,如运行时间、运行空间,人们急需一种可以提高程序效率的方法,并行程序应运而生。而且随着大数据的高速发展,现在在社会的各个方面,人们对计算的要求也越来越高,要求程序计算能提高效率或精度,MIC卡则应运而生,MIC卡可以很好地运行并行[1]的大规模计算,其还可以与CPU合作,CPU运行简单的串行部分和不能并行的程序部分,而MIC则运行复杂的并行计算[2],目前针对MIC平台的研究已经取得了一定的进展[3-6]。
本文中的3D_EW程序就是用以CPU为主MIC为协处理器的offload模式[7]。实验表明,3D_EW在此方式下处理大规模运算数据时效率远高于CPU。
1 三维纵横波分离的弹性波方程模拟算法
1.1 介绍
3D_EW(3D Elastic Wave Modeling)[8]是用于石油勘探领域的应用程序。它是一种用波场延拓的方法来模拟弹性波在各向同性的弹性介质中传播的方法。在该程序中,纵波(P波)和横波(S波)被分别模拟,这样可以更好地得知纵波和横波在弹性介质中的传递。该方法可以通过高阶有限差分方法来模拟弹性波的传递。其求解的方程为弹性波波动方程:
(1)
1.2 原程序结构
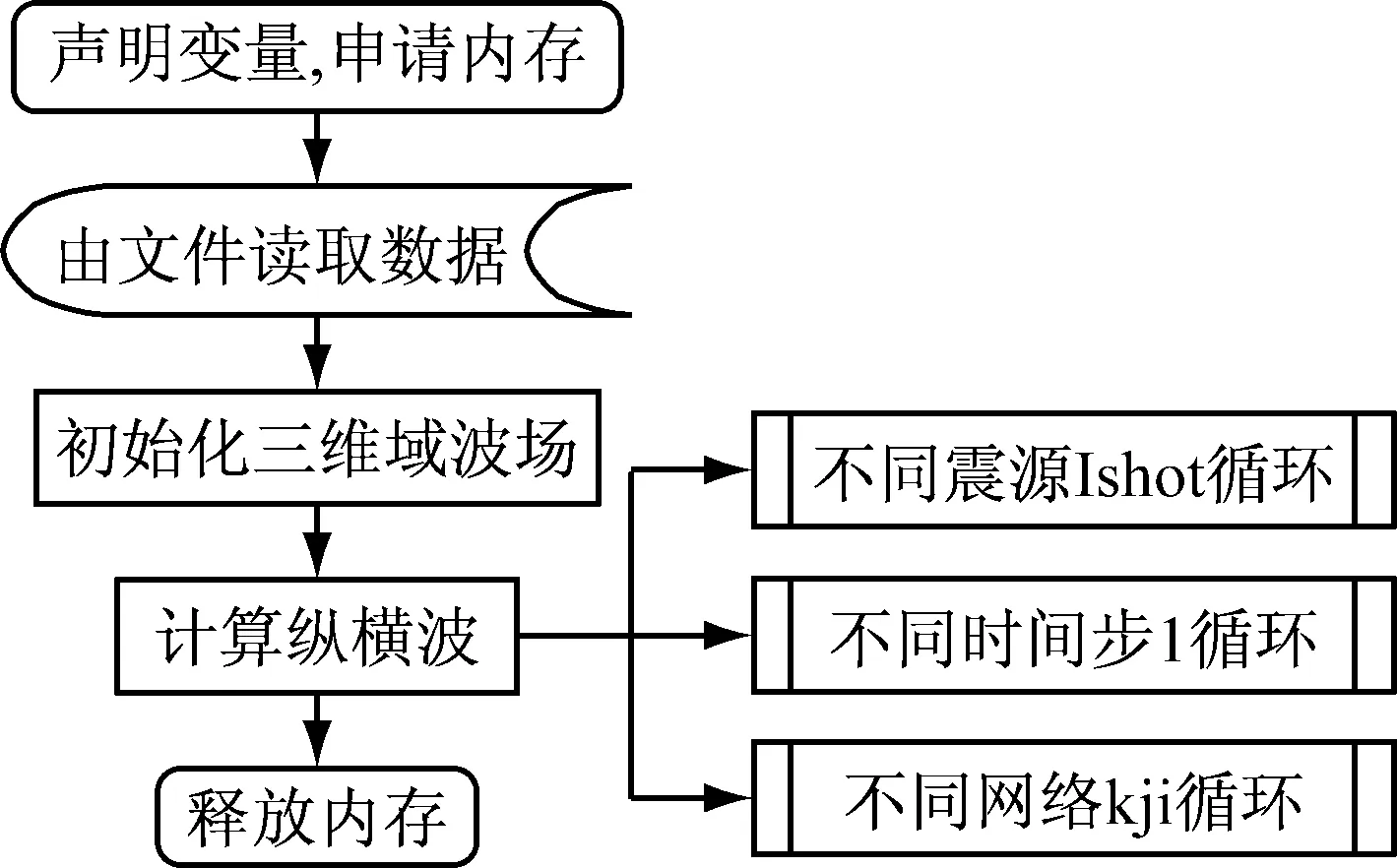
原程序结构如图1所示。
2 MIC移植的优化设计
2.1 MIC介绍
至强融核TM(Xeon Phi)协处理器,是首款英特尔集成众核(Many Integrated Core,MIC)[9]架构产品。用作高性能计算(HPC)[10]的超级计算机或服务器的加速卡。最多61个处理器核心,每个核心拥有4个超线程,最多244个线程,超线程无法关闭。与之竞争的是GPGPU(通用图形处理器)在HPC领域应用的普及。英特尔至强融核协处理器提供了类似于英特尔至强处理器编程环境的通用编程环境。多个英特尔至强融核协处理器可安装在单个主机系统中,这些协处理器可通过 PCIe 对等互连相互通信,不受主机的任何干扰。
2.2 MIC程序移植流程
具体改写与移植流程[11]:
(1) 将串行程序改为OpenMP程序[12];
(2) 将OpenMP版本程序做一定优化;
(3) 将OpenMP版本程序移植到单MIC卡上;
(4) 根据MIC版程序运行情况,做针对性优化;
(5) 单节点内CPU+MIC协同计算。
2.3 MIC移植优化策略
2.3.1 移植前OpenMP并行优化
程序进行移植前,需要使用OpenMP对原串行程序进行改写。OpenMP是一种API,用于编写可移植的多线程应用程序,能够为编写多线程应用程序提供一种简单的方法,而无需程序员进行复杂的线程创建、同步、负载均衡和销毁工作。OpenMP是基于共享内存和线程的支持单指令流多数据流的并行编程模型。OpenMP基于fork/join模型,即在并行任务开始时穿件并发线程,执行并行任务,并在任务结束时收束线程,等待线程全部结束才认为任务结束。OpenMP是显式并行的,需要程序员显示控制需要并行的代码。本次移植优化使用了内部各线程负载均衡优化、向量化优化、并行力度优化的策略。
3D_EW程序根据不同的输入数据量,计算规模也不同,在小规模时各线程间存在任务分配不均而导致的性能使用效率低下,使用各线程负载均衡优化可以解决此问题。
Intel编译器支持向量化,即使用批处理单元进行批量计算的方法,可以把循环计算部分用MMX、SSE等扩展指令进行向量化,从而提高计算速度。MIC向量化优化方式主要有两种,自动向量化和SIMD指令优化,由于SIMD同时支持CPU与MIC,故十分适合用于本程序优化。
3D_EW程序根据不同的输入数据量,计算规模也不同,在小规模时单个线程所分配到的任务量可能会很小,一层循环可能无法达到MIC的并行度要求,而经过并行力度优化后可以满足。
2.3.2 移植后深度优化
程序移植于MIC后,由于种种原因,运行效率可能并不尽如人意,此时仍需要对MIC版本程序进行针对性优化,使用的优化策略为C Intrinsic优化、数据对齐优化与数据传输优化。
C Intrinsic、数据对齐操作可为3D_EW的数据进行优化处理,提高程序在MIC上的运行效率,而数据传输优化则提高了CPU与MIC之间的数据交换,从而提高了总体效率。
3 实验与结果分析
3.1 硬件环境
硬件主要有:① 服务器,型号为Inspur NF5280M4, CPU:Intel XeonE5-2680v3 × 2,2.5 GB,12核心;内存:16 GB × 8,DDR4,2 133 MB; 硬盘: 1T SATA × 1。 ② 加速卡(MIC),型号为XEON PHI-31S1P, Intel XEON PHI-31S1P (57核心,1.1 GB,1003GFlops,8GB GDDR5)。
3.2 热点分析与判断
3D_EW程序结构相对简单,并没有复杂的函数调用,主要的计算都是在循环内,而l之间数据依赖,l循环内部则是如下所示的kji3层循环,在最内层的i循环中,仅有简单的加法和乘法运算,使用Intel分析工具VTune[9]可以很简单的分析出程序内花费较多的部分,看出整个程序花费时间最多的为350行左右,查看原代码后可以发现正好属于kji循环,所以程序的热点就是kji循环内的计算。
3.3 移植可行性分析
Ishot循环为计算不同震源的数据,在Ishot循环内,对于不同的Ishot,计算任务完全独立。Ishot循环之后进入l循环,这里是时间推进方法,不同的l表示不同的时步,前一次迭代的结果将会用于后一步的计算,因而不同l之间存在极强的数据依赖。在l以内,则是不同格的计算,对于显示格式的有限差分来说,不同网格的计算是完全独立的,因而这里也具备很强的并行性。l循环部分十分适合利用MIC进行加速。
3.4 MIC平台判断(程序移植模式分析)
在MIC应用程序模式[11,13]中,存在以CPU为主、以MIC为主和CPU与MIC对等模式3种可能性,而前两种模式也会有仅用CPU(CPU原生模式)或MIC(MIC原生模式)的分支。
在3D_EW程序中,大部分代码为串行执行,串行执行部分在CPU与MIC上执行效率相差无几,而小部分的可并行代码部分计算量又十分巨大,此时在CPU与MIC计算效率则会有显著不同,因此3D_EW程序适合于以CPU为主MIC为协处理器的offload模式。
3.5 使用OpenMP对串行程序进行改写[14-15]
如图2所示,使用制导语句#pragma omp parallel指出并行区域即kji循环,由于kji循环中存在一些变量px、sx、vvp2、vvs2、drd1、drd2等与并行区域外并没有存储关联,所以可以用private进行标识,若如此做则每个线程都会有自己的一份拷贝。

原程序目的是为了在超级计算机上实现,故输入数据量较大,在测试环境中(普通计算机未安装MIC卡,双核四线程,2.6 GHz)实现是相当不现实的,为了检验修改后程序运行效率是否提高,对输入量(即循环次数)进行了一定比例的缩小。
在此数据下,未修改串行程序运行完毕需要188 s,使用OpenMP修改后运行完毕需190 s。从结果可以得出,经OpenMP改写后,程序的运行效率不仅没有提高,反而还降低了(此现象是正常的)。在使用修改后的输入数据后,循环规模相比于原规模已大大减小,使用并行化带来的效果无法抵消并行化的额外负担,而当数据量较大时(使用原输入),每个线程负担的工作将会足够多,并行化的效率便会提高。
3.6 优化OpenmMP版本程序
3.6.1 内部各线程负载均衡优化
并行区域内线程[16]分配方式可选有dynamic、static、guided和runtime,经过对每一种方式测试,最终得到较好方案为dynamic,如图3所示,将循环任务进行动态分配,采取先到先得方式,为每个线程分配任务。

3.6.2 向量化优化
在3D_EW程序中,处理的大部分数据是3维数组,而C程序是基于存储的,源程序kji循环内数组的索引也是基于最内层i循环,因而对i循环进行了向量化处理,如图4所示。这样可以使得同一条SIMD指令处理的数据跨度更小,增加数据读写的空间局部性,更加高效的利用读写带宽。

3.6.3 并行力度优化
在当前程序中,当程序规模较小时(输入的循环变量较小)一层循环可能无法达到MIC的并行度要求,针对这种情况,可以采取多层循环合并或者嵌套并行的方法。当前程序由于循环内变量初值不为0,合并循环进行的计算可能较为繁琐,因此,使用的方法为嵌套并行。
3.7 将程序移植于MIC卡[11]
当前使用的应用模式以CPU为主,MIC为辅的offload模式,offload模式以CPU端为控制端完成控制任务和数据传输任务(可能会有小部分计算任务),MIC端作为计算端,完成CPU交于的并行计算任务。基本流程是在当前的串行程序中,每当执行到需要并行的部分(OpenMP语句已标出),则将这段代码与相关的数据发送到设备端并行执行,待其返回后,主线程再继续执行。
在修改后的代码基础上,使用offload关键字将需要在MIC卡上运行的程序部分进行标出。在kji循环开始之前,添加offload引语。使用编译指令icpc生成MIC程序。
3.8 MIC程序进一步优化
3.8.1 C Intrinsic优化
使用底层编程指令集C Intrinsic来控制向量化的数据读取操作,从而有效减少聚合/分散操作,使得MIC平台上程序性能提升。
3.8.2 数据对齐优化
如图5所示,在MIC上开辟内存时使用_mm_malloc语句可以保证数据对齐,将一个高速缓存行的数据一次性读入向量寄存器。

3.8.3 数据传输优化
当程序运行至MIC程序块部分/MIC程序部分运行完毕时,CPU与MIC卡之间需要进行数据传输,例如开始时CPU需要向MIC传送MIC代码段需要的变量值,而在MIC部分程序计算完成后向CPU返回计算结果,如图6所示。

采用以上方法后,使得CPU与MIC卡之间高效传输,并减少不必要的数据交换,提高了程序运行效率。
3.9 运算性能结果与分析
在高性能计算领域中常使用加速比[1,10]来衡量并行系统或程序并行化的性能和效果,加速比定义为:

(2)

从图7中的运算结果可以看出,程序运算量较小时,使用CPU与MIC协同计算的效果并不是很好,较仅使用CPU甚至更差,主要是因为MIC与CPU之间数据传输所花费的时间比例较大,而主要的计算部分花费的时间却并不多。当程序运算量达到中等时,MIC的计算优势开始渐渐显现,与在MIC上计算所需的时间相比,数据传输的时间占比已渐渐减小,当达到大规模数据计算时,数据传输在整个时间花费上已可以忽略不计。

图7 不同规模下的加速比
4 结 语
程序的并行化和大规模计算都是近几年发展的热点。本文将两者利用MIC卡结合起来,在大规模计算的前提下,很好地提高了程序的效率,而通过实验也证明了MIC卡并行计算的优越性。
[1] 陈国良编著.并行算法的设计与分析[M].2版.北京:高等教育出版社,2002.
[2] (美)格兰马,等.并行计算导论[M].2版.张武等译.北京:机械工业出版社,2005.
[3] 易 娟.基于MIC的主从式并行遗传算法的研究和实现[D].济南:山东大学.2015.
[4] 陈 呈.面向MIC平台的OpenACC实现与优化关键技术研究[D].长沙:国防科学技术大学.2013.
[5] 周长飞.基于MIC的图像显著性检测技术研究[D].长沙:国防科学技术大学.2013.
[6] 刘国波.MIC平台上的并行散列函数库的研究与应用[D].广州:华南理工大学.2015.
[7] 沈 铂,张广勇,吴韶华,等.基于MIC平台的offload并行方法研究[J].计算机科学.2014,41(6):477-480.
[8] 亚洲超算竞赛协会.超算竞赛导论.
[9] 英特尔Xeon Phi协处理器的软件开发指南ver.1.04.
[10] 张军华,臧胜涛,单联瑜,等.高性能计算的发展现状及趋势[J].石油地球物理勘探.2010,45(6):918-925.
[11] 王恩东,张 清,沈 铂,等.MIC高性能计算编程指南[M].北京:中国水利水电出版社.2012.
[12] 殷顺昌.OpenMP并行程序性能分析[D].长沙:国防科学技术大学.2006.
[13] (美)马特森,等.并行编程模式[M].张云良等译.北京:机械工业出版社, 2015.
[14] 罗秋明.OpenMP编译原理及实现技术[M].北京:清华大学出版社,2012.
[15] 查普曼.使用OpenMP:便携式共享存储并行编程(科学与工程计算).
[16] (孟加拉)阿克特,(美)罗伯茨.多核程序设计技术:通过软件多线程提升性能[M].李宝峰,富弘毅,李稻译.北京:电子工业出版社,2007.
Research on the Porting and Implementation of 3D_EW in MIC Parallel Programming
LIXuejian,LUOJing,LUChang,XUXingzhong
(School of Computer Science and Technology, Anhui University, Hefei 230601, China)
3D_EW is a real application in the field of petroleum exploration which requires high computing power support when it operates. The efficiency is very low when the calculation runs on one CPU. MIC card is a Xeon core melt product launched by Intel Corporation. It provides hundreds of hardware threads running simultaneously, bringing a high parallelism. In this paper, a method is proposed to parallel 3D_EW program and transplant it to the MIC card. The experiments show that the parallel running speed of MIC is much larger than that of serial operation speed when 3D_EW is used in large scale operation.
3D elastic wave modeling; MIC; transplant; parallel; optimization policy
2016-08-15
国家自然科学基金项目(61300169)
李薛剑(1981-),男,安徽合肥人,硕士,讲师,研究方向为程序分析与验证、高性能计算。
Tel.:13856005370; E-mail:wind1999@mail.ustc.edu.cn
TP 391
A
1006-7167(2017)04-0123-04
猜你喜欢
煤气与热力(2021年12期)2022-01-19
少先队活动(2021年2期)2021-03-29
汽车维修与保养(2021年8期)2021-02-16
学生天地(2020年17期)2020-08-25
数学大王·低年级(2020年3期)2020-03-12
网络安全技术与应用(2020年1期)2020-01-07
中国特种设备安全(2019年2期)2019-04-22
环球市场(2017年36期)2017-03-09
中国交通信息化(2014年5期)2014-06-05
河南科技(2014年12期)2014-02-27
