
金融信用风险评价中的数据挖掘技术综述
2017-11-08 23:53陈安陈宁范超��
智能计算机与应用 2017年5期
陈安+陈宁+范超��
摘要:信用风险是金融风险管理中的一个热点问题,和国家的宏观经济形式以及国际发展态势有着密切的关联。互联网信贷等新兴商业模式的出现和发展给金融科技带来了巨大的影响,如何充分发挥金融数据的价值成为数据挖掘技术急需解决的问题。以数据技术为核心的金融信用风险评价可以构建更准确、覆盖面更广的金融信用风险模型,将成为传统信用评估体系的有力补充和发展趋势。本文分析了金融信用风险评价所面临的挑战,阐述了数据挖掘在数据选择、预处理、信用风险建模过程中的关键技术和应用,并对金融信用风险评价未来的研究方向提出了一些思路。
关键词: 金融风险管理; 信用风险评价; 数据挖掘; 大数据; 分类
中图分类号: R730.58
文献标志码: A
文章编号:2095-2163(2017)05-0055-05
Abstract:Credit risk is a hot issue in financial credit risk management, closely related to the state's macroeconomy and international development. The emergence and development of new business models have brought everincreasing impact on financial domain. Financial credit risk assessment based on data technique is able to build more accurate and universal credit risk models, and will become the powerful supplement and development tendency of traditional credit evaluation system in future. This paper analyzes the challenge to nowadays financial credit risk evaluation and illustrates the key data mining techniques in data preparation, preprocessing, and modeling when implementing a financial credit risk evaluation platform. Finally, the future research directions are discussed for financial credit risk assessment.
Keywords:financial risk management; credit risk assessment; data mining; big data; classification
0引言
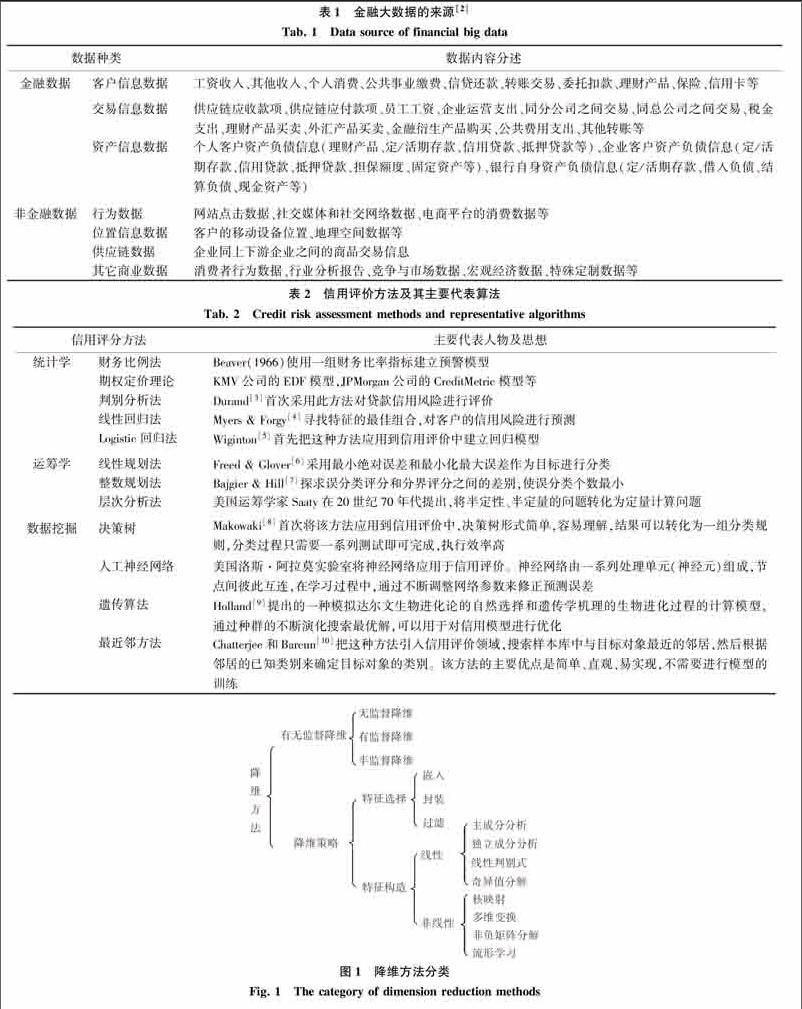
信用风险是金融风险管理中的一个热点问题,是指借款者(或债务人)未能满足合同要求而给贷款者(或债权人)带来经济损失的风险。众所周知,数据是对风险进行有效、准确量度的关键因素,特别是信息技术和互联网的发展,金融风险管理对海量数据的依赖越来越大。大数据[1]是指“无法用现有的软件工具提取、存储、搜索、共享、分析和处理的海量的、复杂的数据集合”。对于金融企业来说,大数据可以解决由信息不对称带来的营销、定价、欺诈、信用等问题。与传统的信用风险分析相比,大数据背景下的金融信用风险分析最根本的创新在于使用了大量的非金融数据进行建模。在大数据背景下,金融数据挖掘的数据来源主要有2类,如表1所示。
1金融信用风险评价中的数据挖掘技术
一般来说,金融信用风险分析可以表示为一个典型的分类问题:给出一组金融数据以及描述这些数据的特征,构建分类模型,然后用这个模型预测未来的信用情况。其中,破产预测是金融风险预测中的一个热点,同时又是很重要的问题。问题中即将企业未来运营状况划分为2类:正常或者破产。例如,中国商业银行贷款分为正常、逾期、呆滞、呆账四类,后3类合称不良贷款,这样银行贷款风险问题就可以转简化为一个二分类问题。国外对信用评价的研究始于上世纪40年代,早期主要代表人物及模型如表2所示。
1.1金融信用风险评价中的数据降维方法
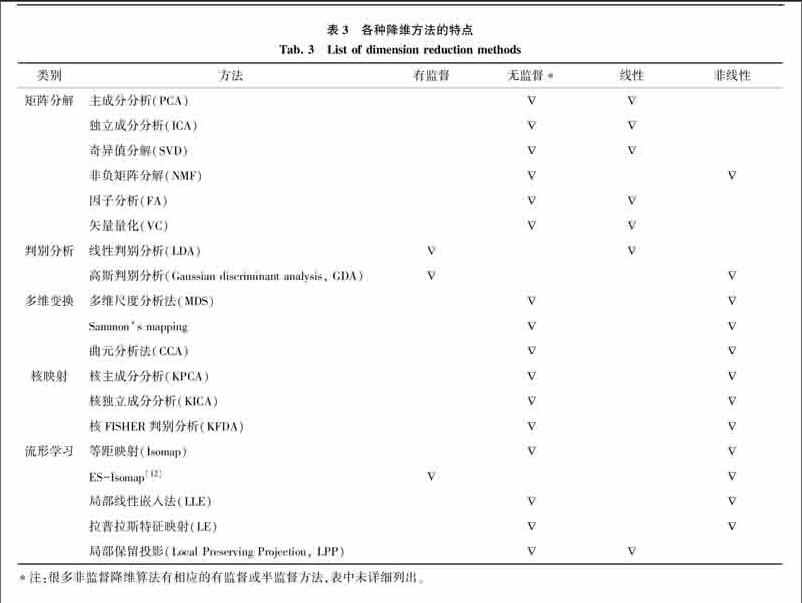
由于金融数据中包含大量冗余并隐藏重要关系的相关性,在分类之前需要进行降维,消除冗余,降低被处理数据的数量。对金融数据先进行降维处理,再构造分类模型,可以有效地提高分类的准确度。数据降维是将样本点从输入空间通过线性或非线性变换映射到一个低维空间,从而获得一个关于原数据集的紧致的低维表示,以达到特定的数据处理目的。图1从不同的角度对降维算法进行分类。首先,根据样本是否包含类别标识,降维方法可分为无监督降维、有监督降维、半监督降维。其次,从维的产生策略上可分为特征选择和特征构造两种方式。特征选择从原始维度中选择一些子集,主要有嵌入、封装、过滤三种方法。特征构造从原始维度中提取新的维度,又可分为线性学习和非线性学习两种。非线性子空间学习克服了线性方法的局限性,可以有效地降低分类的泛化误差,揭示嵌入在金融数据的隐含结构,主要代表方法有多维变换、核映射、非负矩阵分解算法、流形学习等[11]。表3列举了一些经典的降维算法及其特点。
1.2基于启发式优化算法的金融信用风险评价
为了提高分类器的准确度,经常采用启发式算法对分类器进行优化(包括特征优化、模型拓扑结构优化、参数优化等),这样构造出来的分类器称为混合分类器。最常用的启发式优化方法包括遗传算法、模拟退火、群体智能等技术。
遗传算法具有自组织、自适应、自学习性、隐含的并行性、极强的容错能力等优点,适用范围非常广,是解决各种组合优化问题的强有力的手段。Gordini利用遗传算法对意大利制造行业3 100個中小型企业的经营状况进行预测,取得了比Logistic回归分析和SVM模型更好的预测结果[13]。endprint
模擬退火根据热力学的退火原理对局部搜索算法进行扩展,在搜索过程中以一定的概率接受不好的解,使搜索有机会跳出局部极值区域,从而有可能找到全局极值。Jiang将模拟退火算法与决策树C4.5算法结合,构造最优决策规则,用于金融信用风险的评价[14]。
[JP2]群体智能算法模拟昆虫、兽群、鸟群等自然界的群集行为,通过种群的群体智慧进行协同搜索,从而在解空间内找到最优解。群体智能算法具有稳健性、自组织、分布性、简单性、可扩充性等特点,特别适合解决大数据环境下的复杂的优化问题。目前,已经提出并获得较广泛应用的群体智能算法有蚁群算法、粒子群优化算法、菌群优化算法、蛙跳算法、人工蜂群算法等。近年来又出现了一些新兴的仿生学优化算法,包括萤火虫算法、布谷鸟算法、蝙蝠算法、磷虾群算法等。这些群体智能优化算法都可以与分类算法结合,改进分类器的预测结果[15-17]。
1.3金融信用风险评价的集成分类建模
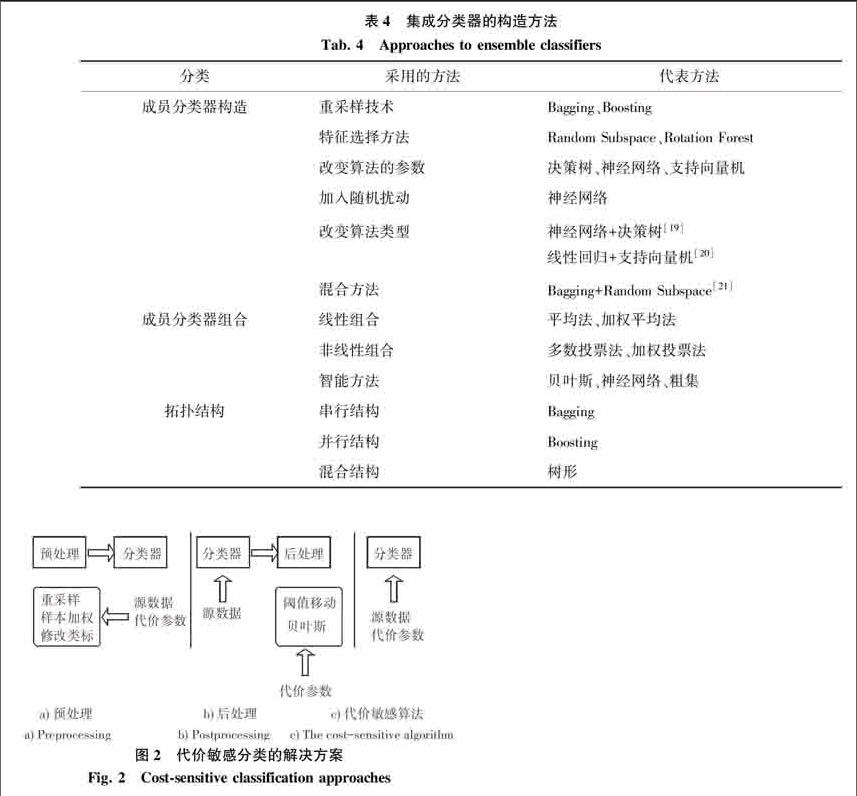
集成分类可以显著地提高分类的准确度,受到越来越多研究者的关注。在金融大数据背景下,数据的海量、分布、动态的特点对集成分类提出了更高的要求。集成学习是指把若干单个分类器集成起来,通过综合各分类器的结果决定最终的分类,以取得比单个分类器更好的预测性能。表4从成员分类器的构造、组合、拓扑结构等几个方面概括了金融信用风险评价中集成分类建模的主要方法[18]。
1.4代价不均衡和类不平衡下的金融信用风险分类
传统分类的目标是使总错误率最小,本质上是假设不同类上的误判造成的代价相同。但在实际应用中,误判的类型不同,其代价通常差别很大,即误判代价不均衡。对金融信用风险评估来说,将破产的企业预测为运行良好造成的代价远远大于将运行良好的企业预测为破产造成的代价。因此,一个好的金融信用风险评价系统必须在预测模型的构建与优化中考虑成本偏好。代价敏感学习就是在分类学习中考虑到误判代价,使总误判代价最小。代价不均衡的分类可以在数据层次上解决,也可以在算法层次上解决。前者可以用于大多数分类器,不需要修改算法本身,包括重采样、样本加权、修改类标记(例如,MetaCost 算法[22],ACO算法[23])、后处理等方法。后者针对特定的算法而设计,通过修改算法的学习策略来完成。图2归纳了代价敏感分类的3种常用的解决方案
另一方面,当数据中类别间的比例十分悬殊,即类分布不平衡时,就会使以总体均方误差为衡量准则的分类器倾向于输出比例大的类别,造成对于样本占少数的类别的错误率很高。而在实际应用中,样本数很少的类往往更受到关注。例如,在企业破产预测中,破产企业往往在实际数据中的比例非常小,但又是这类研究特别关注的目标。不平衡数据分类学习与代价敏感学习可以互相转化,因此可在统一的框架下进行。不平衡数据分类一般通过数据抽样(对少数类过抽样和对多数类欠抽样)、阈值移动(改变阈值使分类器的输出偏向少数类)、样本加权(提高少数类样本的权值)、代价敏感算法(对稀有类元组设置更高的误判代价)来解决[24-25]。
2大数据下金融信用风险评价的挑战
随着互联网的普及和数据挖掘技术的深入,大数据分析在金融信用风险中将会起着越来越重要的作用。大数据征信依赖巨量的、相互性很高的非结构化数据,而互联网金融数据恰好可以作为大数据征信的数据来源,从而为互联网金融产品提供风险控制评估。
首先,传统的数据挖掘技术适用于相对少量、结构化数据的处理,而大数据提供的海量数据多数是非结构化或半结构化数据,对这类数据的集成和预处理是金融信用风险分析所面临的首要问题。
其次,传统的降维方法大多建立在欧几里德距离度量的基础,没有充分利用领域知识(例如数据类型、类标识等),所以有必要研究更有效的非线性子空间学习方法,才能更好地反映金融信用风险数据的复杂结构。
第三,在金融信用风险分析中,研究比较多的是二分问题,例如企业破产预测、信用卡欺诈预测等。但也存在大量的多类别分类问题,例如企业的信用等级评价。研究多类别分类和普适性代价敏感学习算法是未来大数据金融信用风险分析的重点方向之一。
第四,大数据背景下的金融数据集具有数据规模大、数据分布、异构、动态等特点,决定了集成分类是解决这类问题的可行方案,如何对集成分类器进行优化是提高分类器性能的关键。在大数据背景下,研究用于金融信用风险评价的迁移算法将成为这个领域的一个热点。
第五,传统的信用风险评价多针对静态数据,偏重于对企业的风险预测,很少涉及动态的时间序列分析和可视化。研究信用风险的可视化方法可以从企业的时间序列中提取有价值的轨迹模式,勾勒出企业的风险信用轨迹,力求从使用者的角度提供更方便、更直观、可理解的知识表示方法,协助专家观察企业的发展,动态评估企业的信用风险,向那些可能面临破产危机的企业发出预警。
参考文献:
郭平,王可,罗阿理,等. 大数据分析中的计算智能研究现状与展望[J]. 软件学报,2015,26(11): 3010-3025.
[2] 鲍忠铁. 大数据在金融之二:数据来源和应用[EB/OL]. [2014-12-26]. http://www.36dsj.com/archives/19463.
[3] DURAND D. Risk elements in consumer installment financing[M] . New York: National Bureau of Economic Research,1941.
[4] MYERSJ H, FORGY E W. The development of numerical credit evaluation systems[J]. Journal of the American Statistical Association, 1963 , 58 (303) :799-806.endprint
[5] WIGINTON J C. A note on the comparison of logic and discriminate models of consumer credit Behavior[J]. Journal of Financial & Quantitative Analysis, 1980, 15(3): 757-770.
[6] FREED N, GLOVER F. A Linear programming approach to the discriminal problems[J]. Decision Sciences, 1981, 12: 68-74.
[7] BAJGIER S M, HILL A V. An experimental comparison of statistical and linear programming approaches to the discriminate problem[J]. Decision Science, 1982, 13(4): 604-618.
[8] MAKOWSK P. Credit scoring branches out[J]. Credit world, 1985, 75: 30-37.
[9] HOLLANDJ H. Adaptation in natural and artificial systems[M]. MA, USA: MIT Press, 1992.
[10]CHATTERJEES,BARCUN S. A nonparametric approach to credit screening[J]. Journal of the American Statistical Associations, 1970,65(329): 150-154.
[11]MAR-MOLINERO C, SERRANOCINCA C. Bank failure: A multidimensional scaling approach[J]. European Journal of Finance, 2001, 7(2):165-183.
[12]RIBEIRO B, VIEIRA A, DUARTE J, et al. Learning manifolds for bankruptcy analysis[C]// Lecture Notes in Computer Science. Berlin/Heidelberg: Springer, 2008 ,5506: 723-730.
[13]GORDINI N. A genetic algorithm approach for SMEs bankruptcy prediction: Empirical evidence from Italy[J]. Expert Systems with Applications, 2014, 41(14):6433-6445.
[14]JIANG Yi. Credit scoring model based on the decision tree and the simulated annealing algorithm[C]// CSIE 2009, 2009 WRI World Congress on Computer Science and Information Engineering. Los Angeles, California, USA:IEEE,2009:18-22.
[15][JP3]CHEN Ning, RIBEIRO B, VIEIRA A, et al. Extension of learning vector quantization to cost-sensitive learning[J]. International Journal of Computer Theory and Engineering, 2011, 3(3): 352-359.[JP]
[16][JP3]YANG Zhongjin. Bankruptcy prediction using neural networks with structure optimization by particle swarm optimization and genetic algorithm[J]. Mathematics in Practice & Theory, 2015,45(23):192-201.[JP]
[17]李凌霞, 郝春梅, 王紅丽. PSO算法优化BP神经网络的金融风险预警研究[J]. 信息技术, 2014, 8:86-89.
[18]LOURENCO A, BUL S R, REBAGLIATI N, et al. Probabilistic consensus clustering using evidence accumulation[J]. Machine Learning, 2015, 98(1/2): 331-357.
[19]SOLTAN A,MOHAMMADI M. A hybrid model using decision tree and neural network for credit scoring problem[J]. Management Science Letters, 2012, 2(5): 1683-1688.
[20]ZHANG Liang, ZHANG Lingling,TENG Weili, et al. Based on information fusion technique with data mining in the application of finance earlywarning[J]. Procedia Computer Science, 2013, 17: 695-703.endprint
[21]WANG Gang, MA Jian. A hybrid ensemble approach for enterprise credit risk assessment based on support vector machine[J]. Expert Systems with Applications, 2012, 39(5): 5325-5331.
[22]DOMINGOS P. Metacost: A general method for making classifiers costsensitive[C]//Proceedings of 5th ACM SIGKDD international conference on knowledge discovery and data mining. San Diego, CA, USA: ACM, 1999: 155-164.
[23]陳晓林,宋恩民,马光志.一种基于ACO的代价敏感集成分类器[J],华中科技大学学报(自然科学版),2010, 38(10):5-8.
[24]KIM M J, KANG D K, HONG B K. Geometric mean based boosting algorithm with oversampling to resolve data imbalance problem for bankruptcy prediction[J]. Expert Systems with Applications, 2015, 42(3):1074-1082.
[25]ALEJO R, GARCA V, PACHECOSNCHEZ J J. An efficient oversampling approach based on mean square error backpropagation for dealing with the multiclass imbalance problem[J]. Neural Processing Letters, 2015, 42(3):603-617.
wanhang_530_3524GX Dec2 11:10:15 IP ARP: 192.168.0.1 moved from 00:22:aa:d6:9b:34 to 00:e0:0f:37:9e:df
wanhang_530_3524GX Dec2 11:10:15 IP ARP: 192.168.0.1 moved from 00:e0:0f:37:9e:df to fc:fa:f7:b8:c7:60
根据对实际设备的调查,确认该信息是用户接入点设备的配置错误产生的IP地址冲突,错误信息造成该区域10台交换机同时触发告警。由于用户接入点交换机一般会在工作时间开机、休息时间关机,因而造成图6和图13的有规律的网络振荡。可见,该异常事件同时触发了多个设备产生异常日志,对网络运行具有一定的危害性。
4结束语
网络运维工作是一项系统、长期的工作。长远来看,主动式的网络运维工作必将成为发展趋势,也一定能够推动运维部门有效提高工作效率。在提高网络可用性的同时,改善用户体验。在从被动运维转向主动运维的过程中,运维部门需要从多方面改变或改进已有的工作方式和工作方法,并在设计开发中探索寻求找出更多更加良好的适用于企业自身特点的网络运维工作方法,使主动运维给企业带来收益。
参考文献:
廖敬新. 网络运维管理系统优化与建议[J]. 信息与电脑(理论版),2016(8):152-153.
[2] 王政. 基于ITIL理论视角S公司IT服务管理研究[D]. 昆明:云南师范大学,2014.
[3] 任凯,邓武,俞琰, 基于大数据技术的网络日志分析系统研究[J]. 现代电子技术,2016,39(2):39-41,44.
[4] 毕建华,王颖. 大数据时代运维管理面临的调整[J]. 金融科技时代,2014(1):85.
[5] 何映军,何昱锋,王林,等. 主动式IT运维服务模式运用[J]. 民营科技,2017(1):35-36.
[6] 龚银锋. 网络日志管理系统的技术研究与实现[J]. 网络安全技术与应用,2016(3):26-28.
[7] 黄文,谢东青. 基于Syslog的网络日志管理分析模型[J]. 湖南科技学院学报,2006,27(5):164-167.
[8] GILL P, JAIN N, NAGAPPAN N. Understanding network failures in data centers: Measurement, analysis, and implications[C]//SIGCOMM'11. Toronto, Ontario, Canada:ACM, 2011:350-361.
[9] QIU Tongqing, GE Zihui, WANG Jia, et al. What happened in my network: Mining network events from router Syslogs[C]// ACM IMC.Melbourne, Australia: ACM, 2010:472-484.
[10]廖湘科,李姗姗,董威,等. 大规模软件系统日志研究综述[J]. 软件学报,2016,27(8):1934-1947.
[11]唐琳,李伟. 基于用户体验的“主动式”信息运维管理实践[J]. 电力信息化,2013,11(3):89-93.endprint
猜你喜欢
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
速读·下旬(2016年8期)2017-05-09
电子技术与软件工程(2016年24期)2017-02-23
大经贸(2016年11期)2017-01-06
现代商贸工业(2016年11期)2016-12-26
哈尔滨理工大学学报(2016年2期)2016-09-12
现代经济信息(2016年7期)2016-05-19
少儿科学周刊·少年版(2015年3期)2015-07-07
