
基于相似度质量的混合协同过滤算法∗
2017-12-18 06:22陈洪雁
计算机与数字工程 2017年11期
郭 雷 张 琨 陈洪雁 严 霞
(南京理工大学计算机科学与工程学院 南京 210094)
基于相似度质量的混合协同过滤算法∗
郭 雷 张 琨 陈洪雁 严 霞
(南京理工大学计算机科学与工程学院 南京 210094)
在传统协同过滤算法中一直面临着冷启动和数据稀疏等问题,导致推荐信息不够准确。通过分析基于用户的协同过滤算法和基于物品的协同过滤算法的各自特点提出一种新的混合协同过滤算法。改进相似度的计算方式来提高相似度的精准度,从近邻相似度的均值和标准差出发对两种协同过滤算法进行加权结合,同时引入控制因子提高预测的精度。以Movie Lens数据集进行实验验证,以平均绝对误差作为实验的测试标准。实验结果表明,在评分矩阵极度稀疏的条件下该算法提高了推荐的准确度。
推荐算法;协同过滤;相似度
1 引言
随着当今社会互联网的普及和信息技术的飞速发展,信息过载问题也随之而来,如何从海量的信息中准确快速地获取自己想要的信息显得尤为重要。过往的搜索引擎在一定程度上可以满足用户对信息检索的需求,但对于检索的结果往往千篇一律,无法根据用户的兴趣和偏好主动提供个性化信息。在这种背景下推荐系统应运而生,与搜索引擎不同,个性化推荐系统可以基于个人的行为数据为用户提供定制的信息[1]。
目前主流的推荐系统主要有基于内容的推荐系统和协同过滤推荐系统[2]。基于内容的推荐算法是建立在物品的内容信息上做出推荐的,不需要依赖用户对物品的评价意见,更多的需要用机器学习的方法从关于内容的特征描述和事例中得到用户的兴趣资料,因此该算法要求信息内容要容易抽取成有意义的特征,并且特征内容要具有良好的结构性。协同过滤推荐算法通过对用户的行为进行分析来挖掘用户的兴趣,从用户群中找出与目标用户兴趣相近的用户并通过这些近邻用户对物品的评价值来预测目标用户对该物品的喜好程度[3~4]。因为无需对物品内容进行分析,协同过滤在推荐图片、音乐、电影等方面具有更好的优势,在推荐系统中被广泛使用。
根据协同过滤的相关特性,将协同过滤分为两类:基于用户(User-Based)协同过滤算法和基于物品(Item-Based)协同过滤算法。基于用户的协同过滤,通过用户对不同物品的评分来计算物品之间的相似性,再通过物品之间的相似性预测评分做出推荐,但随着用户的增加会不断地影响预测的结果导致预测偏差增大[5]。基于物品的协同过滤,通过不同用户对物品的评分来计算物品之间的相似性,再通过用户之间的相似性预测评分做出推荐,可能造成推荐的单一化导致预测结果不准确。目前,两种协同过滤算法均存在数据稀疏、冷启动和可扩展性差等问题[6~7]。通过对这些缺点的分析,提出一种基于用户和物品的加权混合型协同过滤算法来提高预测的准确性。
2 传统协同过滤算法
首先我们对基于用户协同过滤算法和基于物品协同过滤算法进行详细介绍。两种基本的协同过滤算法均可分为四个步骤:创建用户-物品评分矩阵,相似性计算,近邻选择,评分预测。
2.1 基于用户协同过滤算法
基于用户协同过滤推荐的主要思想可以简述为:首先,给定一个用户-物品的评分数据集,找出与当前用户过去有相似偏好的其他用户,这些用户被称为近邻用户;然后,对当前用户没有见过的物品,利用其近邻对该物品的评分来计算预测值。这种算法的潜在假设有两点:如果用户过去有相似的偏好,那么他们未来也会有相似的偏好;用户偏好不会随时间而变化。
1)创建用户-物品评分矩阵
推荐系统中包含m个用户记为{u1,u2,…,um}和 n个物品记为{i1,i2,…,in},则创建一个 m×n的用户-物品评分矩阵 Rm×n。矩阵中的元素 Ri,j(1≤i≤m,1≤j≤n)表示用户i对物品 j的评分,评分一般为1~5的整数,评分越高表示用户对物品的兴趣程度越高,如果Ri,j=0则表示用户i未对 j进行评分。
2)相似性计算
目前计算相似度的方法主要有:皮尔森相关系数、余弦相似度、欧几里得距离相似度、曼哈顿距离相似度。在基于用户协同过滤中采用最常用的皮尔森相关系数进行计算,该方法可以反应出两个变量之间的线性相关程度,取值范围从-1(强负相关)到+1(强正相关),若取值为0则表明不存在线性相关关系。
将用户u和用户v共同评论过的物品集合记为 I(u)∩I(v),用户 u和用户 v的相似度记为sim(u,v),则皮尔森相关系数公式可以表示为
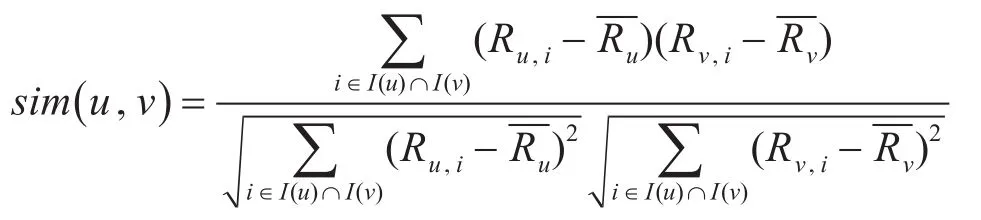
3)近邻选择
在得到用户之间的相似度之后,对目标用户与其他用户之间的相似度进行筛选,挑选相似度最大的K个用户组成近邻集合记为N(u)。K值的大小会对预测的结果产生影响:当近邻个数K太高时,会给预测带来额外的“噪声”;当K太小时,预测的结果可能出现负面影响。因此近邻个数的选择应控制在合理的范围内。
4)评分预测
目标用户u对物品i的预测评分记为pred(u,i)可以通过如下公式计算得出:
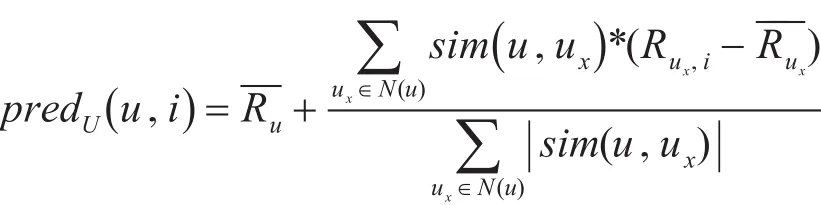
其中,ux为近邻集合中的某一用户;Rux,i为用户u对物品i的评分;为用户u对物品评分xx的均值;sim(u ,ux)为用户u与用户ux的相似度。
2.2 基于物品协同过滤算法
基于物品协同过滤的主要思想是利用物品之间的相似度来预测用户对物品的兴趣程度。
1)创建用户-物品评分矩阵
和基于用户协同过滤算法一样,需要对数据进行相同的处理生成用户-物品评分矩阵。
2)相似性计算
在基于物品协同过滤中,余弦相似度是比较常见的相似性计算方法。由于基本的余弦相似度算法没有考虑用户评分均值之间的差异,因此使用修正余弦相似度方法计算物品之间的相似度。将同时评论过物品i和物品 j的所有用户集合记为U(i)∩U(j),物品i和物品 j的相似度记为sim(i,j),则有:
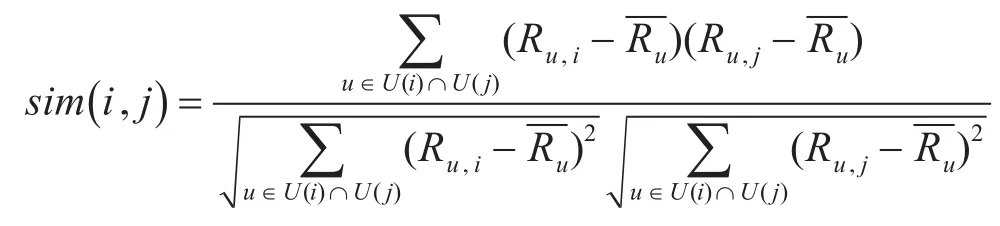
其中,u表示同时评分过物品i和物品 j的用户;-Ru表示用户u对物品评分的均值。
3)近邻选择
与基于用户协同过滤的近邻选择类似,筛选出与目标物品相似度最大的K个物品组成近邻集合记为N(i)。同样近邻的个数应控制在合理的范围内。
4)评分预测
预测目标用户u对物品i的评分公式如下:
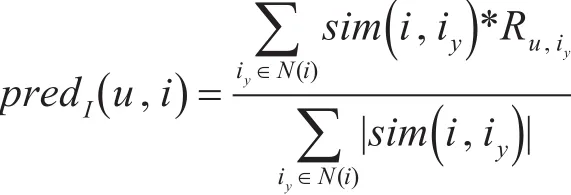
其中,iy为近邻集合中的某一物品;Ru,iy为用户u对物品iy的评分;sim(i , iy)为物品i与物品iy的相似度。
3 改进的协同过滤算法
在协同过滤算法中,基于用户协同过滤通过横向对比各用户之间的兴趣相似度可以找出目标用户的兴趣群组,从而使推荐的结果准确性高一些,更注重社会化而缺少一定的个性化;基于物品协同过滤是通过物品间的对比,根据用户历史行为推荐相似物品,更注重个性化,但是推荐的结果准确性较低一些[8]。为了使推荐的结果兼具个性化和更高的准确率,本文将两种协同过滤算法结合起来[9]。
3.1 相似度计算的改进
在利用皮尔森相关系数或者修正余弦相似度计算相似度时虽然很直观,但是没有考虑到两两用户(或物品)之间共同评分项目数目对预测结果的影响。由于数据稀疏性往往比较大,有时会出现两个原本相似较小的用户(或物品)恰好在较少的共同评分项上拥有较大的相似度,从而导致预测不准确[10]。如下表1中用户u1与用户u2的共同评分项只有1项,而用户u1与用户u3的共同评分项有3项,u1与u2的相似度为0.47,u1与u3的相似度为0.45,若直接判定用户u1与用户u2的相似度高于用户u1与u3的相似度显然是不合理的。
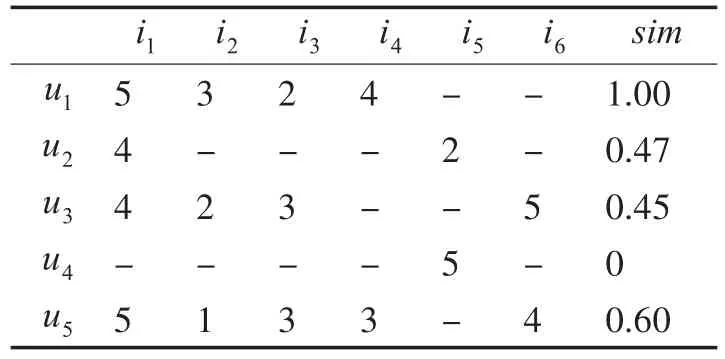
表1 皮尔森相关系数计算用户间相似度
为了使用户(或物品)之间的相似度计算更加合理,结合共同评分项数量对相似度的影响,本文使用加权型的相似度计算方式。用户之间的相似度为用户之间共同评分项数量与该用户和其他用户最大共同评分项数量的比值,再对皮尔森相关系数进行加权;物品之间的相似度为物品之间共同评分项数量与该物品和其它物品最大共同评分项数量的比值,再对修正余弦相似度进行加权。公式分别为
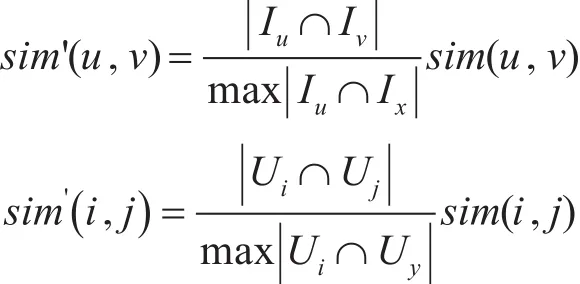
式中,| Iu∩Iv|代表用户u与用户v共同评分过物品的数量,max | Iu∩Ix|代表用户u与其他用户共同评分过物品的数量最大值;|Ui∩Uj|代表共同评分过物品i与物品 j的用户的数量,max| Ui∩Uy|代表共同评分过物品i与其它物品的用户的数量最 大 值 。 由 上 述 公 式 可 知 |sim'(u,v)|≤1 ,|sim'(i,j)|≤1成立。另外,在改进的相似度算法中,由于max | Iu∩Ix|不一定与max| Iv∩Ix|相等,因此会出现 sim'(u,v)≠sim'(v,u)的情况,所以用户 u 与用户v的相似度sim'(u,v)和用户v与用户u的相似度sim'(v,u)是两种独立的相似度,记为独立的两个值;同理,物品i与物品 j的相似度sim'(i,j)和物品 j与物品i的相似度sim'(j,i)也记为两个独立的值。
使用改进后相似度算法计算表1中用户u1与其他用户之间的相似度,并与改进前相似度进行对比,结果如表2所示。
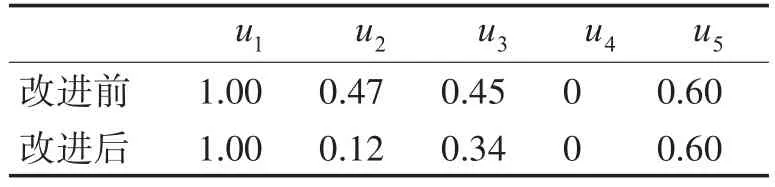
表2 两种方式计算相似度的对比
可以看出相似度算法改进后,u1与u2的相似度 sim'(u1,u2)=0.12 ,u1与 u3的 相 似 度sim'(u1,u3)=0.34 , 通 过 比 较 可 以 得 出sim'(u1,u2)< sim'(u1,u3),从而使近邻的选择更加符合实际要求,减小了共同评分项数量的差距对用户(或物品)之间相似度的影响,有效降低了数据稀疏度对相似度计算的影响。
3.2 近邻集合的选择
在得出用户(或物品)的相似度之后,通常有两种方法来确定近邻集合:一种是通过相似度阈值来选择,凡是大于该阈值的用户(或物品)都视为近邻;另一种则是选取K个相似度最大的用户(或物品)作为近邻[11]。这两种方法都有各自的局限性,本文使用两种方法的混合,在相似度大于阈值γ的情况下选取最大的K个用户(或物品)作为近邻。
基于用户的近邻集合可以表示为
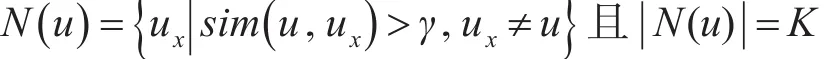
基于物品的近邻集合可以表示为
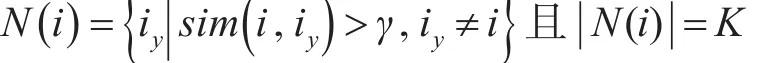
3.3 评分预测
在混合协同过滤算法中,引入权重因子α(α∈[0,1])来平衡基于用户协同过滤和基于物品协同过滤的权重,使推荐结果具有更高的准确度,整体思路可以表示为
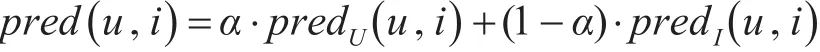
为了进一步提高预测结果的合理性和准确度,本文对权重因子α进行改进。在每个目标用户或目标物品的近邻集合中,K个近邻的相似度大小会对预测的结果有着不同程度的影响,相似度的值越大一般会对预测结果有着更多积极性的影响,反之则反。因此文中再引入一个权衡因子β,β表示为
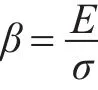
其中,E表示目标用户或目标物品近邻集合中各个近邻相似度的平均值;σ则表示近邻集合中各个近邻相似度的标准差。E的值越大表明近邻集合整体的相似度越大,但是在近邻中也会出现个别相似度较低的用户(或物品),虽然对整体的相似度影响不大,但是对评分的预测会有影响。因此,综合标准差σ来评判近邻集合整体相似度的大小和密集程度,进而衡量近邻集合的整体质量。
对于基于用户协同过滤的权衡因子记为βu,表示为
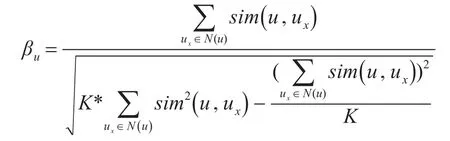
对于基于物品协同过滤的权衡因子记为βi,表示为
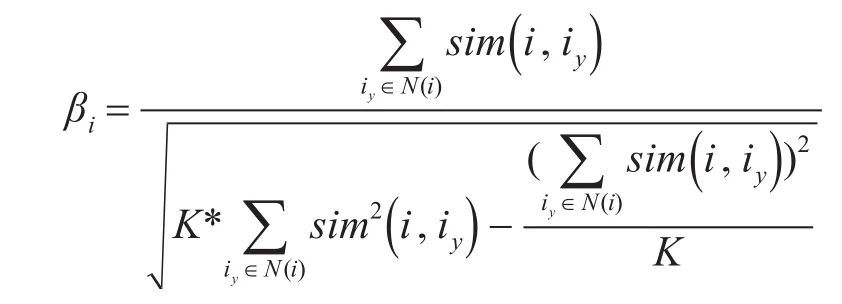
为了将两种协同过滤的权衡因子结合起来,还需要引入一个控制因子 μ(μ∈[0,1])使权重因子α控制在0到1之间,最终得到α的表达式为
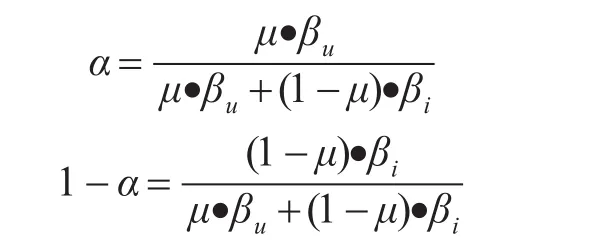
权重因子α决定了混合算法对基于用户协同过滤和基于物品协同过滤算法的依赖程度,当α=1时即为单纯的基于用户协同过滤算法,当α=0时即为单纯的基于物品协同过滤算法。考虑到用户评分数据的稀疏性,实际中一些用户可能没有足够的相似用户,即相似度数值大于阈值γ的近邻个数不足K个,以往的算法会忽略这一问题依旧选择最大的K个相似用户来预测评分,导致预测的准确度大大降低。本文提出的新算法通过以下思路来解决这个问题:
当 ||N(u)=K且 ||N(i)=K时,预测评分由文中提出的混合协同过滤算法计算得出,此时0<α<1;
当 ||N(u)=K且 ||N(i)≠K时,预测评分相当于由基于用户协同过滤算法计算得出,此时α=1;
当 ||N(u)≠K且 ||N(i)=K时,预测评分相当于由基于物品协同过滤算法计算得出,此时α=0;
当 ||N(u)≠K且 ||N(i)≠K时,意味着相似用户和相似物品均不满足要求,因此不予置评,pred( )u,i=0。
4 实验及分析
4.1 实验数据集介绍
本文使用Movie Lens数据集作为实验数据来进行测试,数据集包含943个用户对1682部电影的评分,评分的分数为1到5整数,评分记录总共为100000条。由下式对数据集稀疏度的计算结果可以看出该数据集是非常稀疏的:
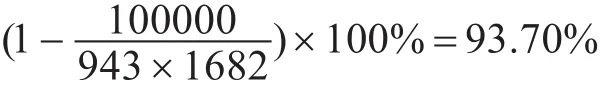
4.2 实验评定标准
本文采用平均绝对误差MAE来评价预测的质量,MAE可以衡量预测值和真实评分之间的平均偏离程度。MAE的值越低,表明预测的精度就越高,计算公式为
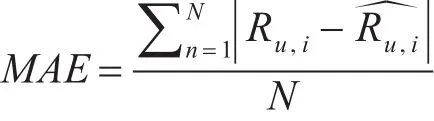
式中,Ru,i表示用户u对物品i的预测评分;Ru,i表示用户u对物品i的真实评分;N表示待预测评分的总数量。
4.3 实验过程
为了减少评分的偶然性带来的数据偏差,本文使用交叉验证对数据集进行实验,从100000条评分中随机抽取20000条评分作为测试集,剩下的80000条评分作为训练集,每次预测重复五次,选取适中的值作为预测结果。
在提出的混合协同过滤中控制因子μ对权重因子α有着直接影响的,因此确定控制因子μ的最佳取值是本实验的重点,同时包括近邻集合个数K的取值对实验结果的影响。因为相似度阈值γ对权重因子α没有直接影响,为了简化实验我们将γ置为0。
实验中,控制因子μ∈[0,1]的取值间隔设置为0.1,将近邻集合个数K分别设置为10、20、30、40、50。得到的实验结果如图1所示。
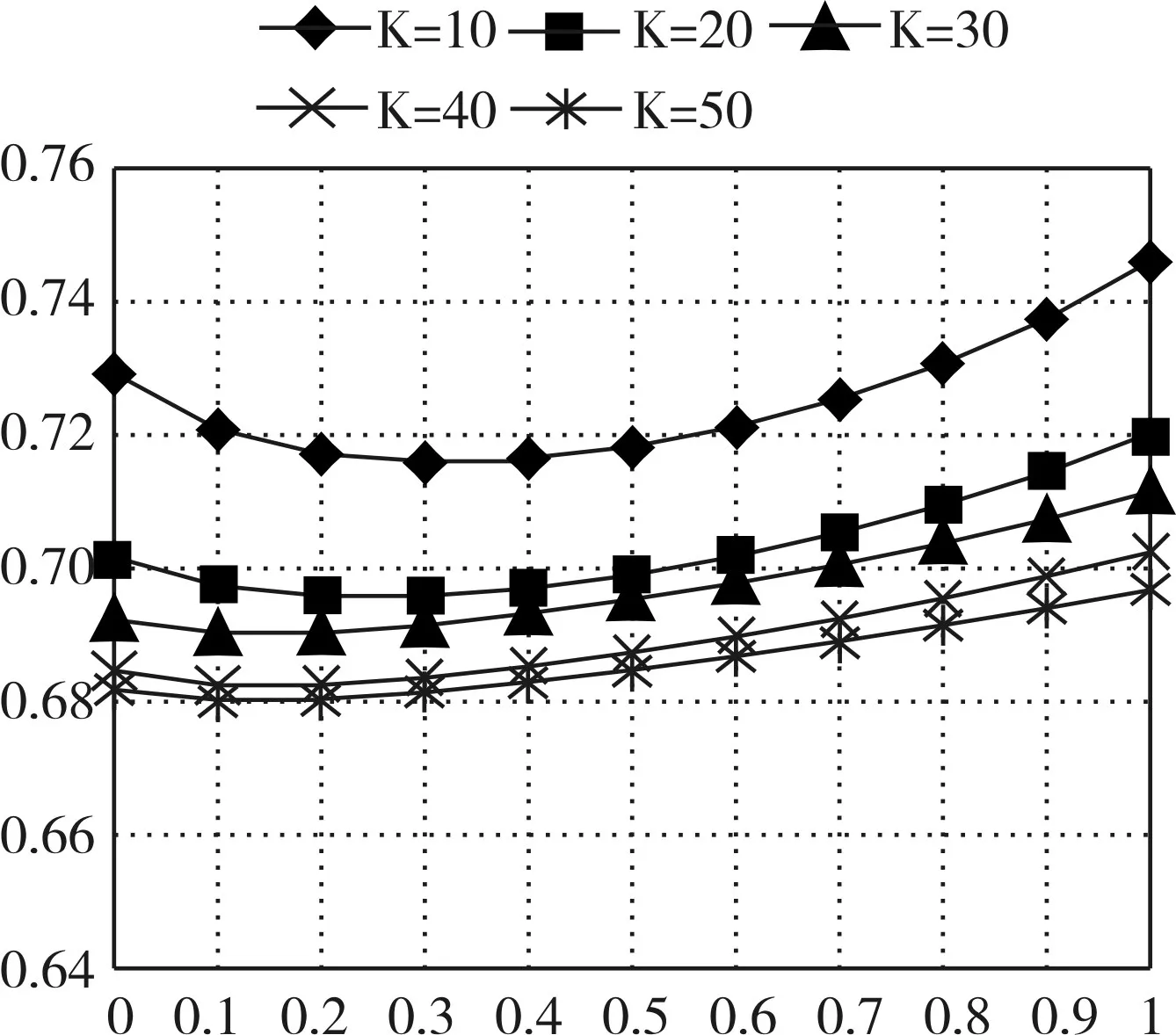
图1 控制因子μ的取值对MAE的影响
从上图中可以看出:通过纵向对比,随着近邻集合个数K的增加,MAE的变化会越来越小趋于稳定;通过横向对比,随着控制因子μ的增加,MAE会先减小后增大。总体上,μ在0.1~0.3之间时MAE的变化趋于平缓,当μ=0.2时取得最优值,近邻集合个数K=50时MAE取得最小值。
在得出控制因子μ的最优值后,进一步验证文中提出的混合协同过滤算法的推荐精准度,将本文提出的混合协同过滤与两种传统的协同过滤进行对比,控制因子μ置为最优值0.2,近邻集合个数K同样从10增加到50,得到的实验结果如图2所示。
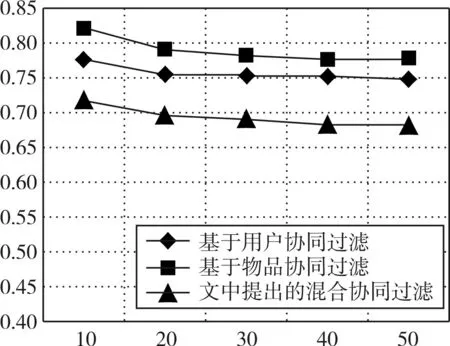
图2 三种不同协同过滤算法的MAE比较
可以看出文中提出的混合协同过滤的实验结果MAE更低一些,因此有着更高的推荐准确度。
5 结语
本文在前人的基础上,针对基于用户协同过滤和基于物品协同过滤的不同优势和缺点,从混合模型的角度切入,对两种基础的协同过滤进行了改进。创新性的将近邻集合中相似度的均值和标准差引入到混合算法中来平衡两种基础协同过滤算法的权重。最后通过实验与两种传统的协同过滤算法进行对比,验证了本文算法的确实提高了预测精度,使推荐更加准确。
[1]刘建国,周涛,汪秉宏.个性化推荐系统的研究进展[J].自然科学进展,2009,01:1-15.LIU Jianguo,ZHOU Tao,WANG Bingcheng.Research progress of personalized recommendation system[J].Progress in Natural Science,2009,01:1-15.
[2]王国霞,刘贺平.个性化推荐系统综述[J].计算机工程与应用,2012,07:66-76.WANG Guoxia,LIU Heping.Summary of personalized recommendation system[J].Computer engineering and Applications,2012,07:66-67.
[3]李桃迎,李墨,李鹏辉.基于加权Slope one的协同过滤个性化推荐算法[J].计算机应用研究,2016,08:1-6.LI Taoying,LI Mo,LI Penghui.Personalized collaborative filtering recommendation algorithm based on weighted Slope one[J].Computer application research,2016,08:1-6.
[4]SCHAFER J B,KONSTAN J A,RIEDL J.E-commerce recommendation application[J].Data Mining and Knowledge Discovery,2001,5(1/2):115-153.
[5]范波,程久军.用户间多相似度协同过滤推荐算法[J].计算机科学,2012,01:23-26.FAN Bo,CHENG Jiujun.collaborative filtering recommendation algorithm based on User's Multi-similarity[J].Computer science,2012,01:23-26.
[6]LIU Qingwen,XIONG Yan,HUANG WenChao.Combining User-Based and Item-Based Models for Collaborative Filtering Using Stacked Regression[J].Chinese Journal of Electronics,2014,04:712-717.
[7]刘庆鹏,陈明锐.优化稀疏数据集提高协同过滤推荐系统质量的方法[J].计算机应用,2012,04:1082-1085.LIU Qingpeng,CHEN Mingrui.Optimization of sparse data sets to improve quality of collaborative filtering systems[J].Computer application,2012,04:1082-1085.
[8]BA Qilong,LI Xiaoyong,BAI Zhongying.Clustering Collaborative Filtering Recommendation System Based on SVD Algorithm[A].Proceedings of 2013 IEEE 4th International Conference on Software Engineering and Service Science[C],2013:5.
[9]黄琼,冯军焕.混合协同过滤个性化推荐算法研究[J].计算机光盘软件与应用,2014,04:111-113.HUANG Qiong,FENG Junhuan.Research on Personalized Recommendation Algorithm Based on hybrid collaborative filtering[J].Computer CD software and application,2014,04:111-113.
[10]ZHANG Ye,SONG Wei.A Collaborative Filtering Recommendation Algorithm Based on Item Genre and Rating Similarity[C]//Proceedings of the 2009 International Conference on Computational Intelligence and Natural Computing(Volume 2),2009:4.
[11]查九,李振博,徐桂琼.基于组合相似度的优化协同过滤算法[J].计算机应用与软件,2014,12:323-328.ZHA Jiu,LI Zhenbo,XU Guiqiong.An optimized collaborative filtering algorithm based on combined similarity[J].Computer applications and software,2014,12:323-328.
Hybrid Collaborative Filtering Algorithm Based on Quality of Similarity
GUO LeiZHANG KunCHENG HongyanYAN Xia
(School of Computer Science&Engineering,Nanjing University of Science and Technology,Nanjing 210094)
In the traditional collaborative filtering algorithm has been facing a cold start and data sparseness and other issues,resulting in the recommendation information is not accurate enough.A new hybrid collaborative filtering algorithm is proposed by analyzing the characteristics of user-based collaborative filtering algorithm and item-based collaborative filtering algorithm.This paper combines the weighted mean of two similar filtering algorithms with the mean and standard deviation of the similarity,and introduces the control factor to improve the precision of the prediction.Experiments are carried out with the Movie Lens dataset,and the average absolute error is used to measure the results.The experimental results show that the proposed algorithm improves the accuracy of the proposed algorithm when the scoring matrix is extremely sparse.
recommendation algorithm,collaborative filtering,similarity
TP301
10.3969/j.issn.1672-9722.2017.11.005
Class Number TP301
2017年5月9日,
2017年6月29日
郭雷,男,硕士研究生,研究方向:机器学习、数据挖掘。张琨,女,博士,教授,研究方向:复杂网络理论与应用、可信计算、网络与信息安全。陈洪雁,女,硕士,助理研究员,研究方向:信息化建设、网络安全。严霞,女,硕士研究生,研究方向:复杂网络,数据挖掘。
猜你喜欢
西北林学院学报(2022年5期)2022-10-04
北京航空航天大学学报(2022年6期)2022-07-02
小学生学习指导(低年级)(2022年5期)2022-05-31
新班主任(2022年4期)2022-04-27
疯狂英语·初中天地(2021年11期)2021-02-16
中等数学(2020年1期)2020-08-24
少年漫画(艺术创想)(2019年2期)2019-06-06
汽车观察(2019年2期)2019-03-15
华人时刊(2018年17期)2018-11-19
民生周刊(2017年19期)2017-10-25
