
基于朴素贝叶斯网络的微博话题追踪技术研究∗
2017-12-18 06:22冯军军贺晓春王海沛
计算机与数字工程 2017年11期
冯军军 贺晓春 王海沛
(四川信息职业技术学院 广元 628017)
基于朴素贝叶斯网络的微博话题追踪技术研究∗
冯军军 贺晓春 王海沛
(四川信息职业技术学院 广元 628017)
根据微博的特点,提出了基于朴素贝叶斯网络模型的微博话题追踪算法,在改进型DF的文本特征选择方法的基础上,通过构建朴素贝叶斯网络模型,设计并实现对微博话题的追踪系统。实验结果表明,基于朴素贝叶斯网络的微博话题追踪系统具有分类简单、高效的优点,特别适合对微博热门话题进行追踪。
朴素贝叶斯网络;微博;话题追踪
1 引言
随着微博的兴起,微博作为个人、机构以及其它媒体的信息发布交流平台的作用不断提升,广大网民的舆论主战场逐渐转向微博平台这些数以亿计的微博信息中蕴藏着巨大的价值,因此加强微博舆论的研究对经济、社会、政治的稳定与发展有着重要的积极作用[1]。目前,微博平台具有数据量大、动态更新快、内容实时性强等特点[2],基于关键字的检索返回的信息冗余度高,相关的信息未进行有效地组织,人们对某些事件难以做到全面的把握。在此背景下,研究人员开始关注微博话题追踪技术,微博话题追踪旨在追踪已知微博话题的后续事件[3~4]。本文将在新闻话题检测与追踪技术上所采用的朴素贝叶斯网络模型应用到微博话题。它能够在热门话题检测任务(单位时间内微博的转发量、评论数等超过设定的阈值)完成的基础上,实现快速追踪热门话题后继事件的发展动态,具有算法简单、识别率高、快速的特点。其关于微博内容、关键词、话题之间的关系用朴素贝叶斯网络描述如图1所示。
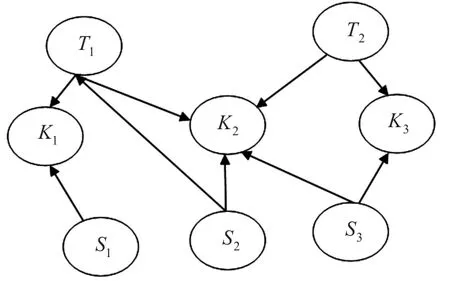
图1 描述微博内容(S)、微博话题(T)和关键字(K)的贝叶斯网络
2 朴素贝叶斯网络
2.1 贝叶斯定理
P(A|B)表示事件B发生下事件A发生的条件概率,其基本求解公式如下
其中P(AB)表示事件A、B同时发生的概率。P(B)属于先验概率,表示事件B发生的概率。贝叶斯定理提供了一种由P(B)、P(A)和P(A|B)来计算后验概率P(B|A)的方法,其基本关系是:
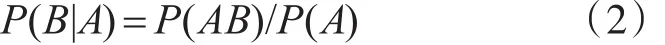
贝叶斯定理的推广:对于多变量(N>2),贝叶斯定理同样成立,式(3)给出变量的个数N=3时,根据式(2)导出的贝叶斯定理。
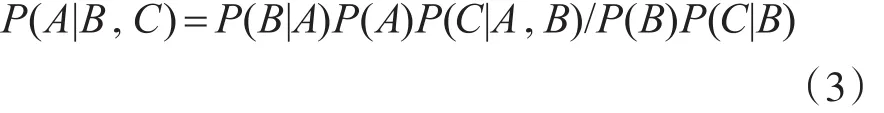
2.2 朴素贝叶斯网络的定义及其性质
贝叶斯网络的拓扑结构是一个有向无环图,G=<V,E>,其中V表示随机变量的集合,集合中的每一个元素对应贝叶斯网络中唯一的节点,E表示随机变量之间的条件依赖,用条件概率表集合来表示,它存储了对于其所有直接前驱节点的联合条件概率。贝叶斯网络有一个重要的性质,每一个节点在其直接前驱节点确定后,这个节点条件独立于其所有非直接前驱前辈节点。这个性质很类似Markov过程。式(4)给出了贝叶斯网络中多个随机变量的联合条件概率计算公式。
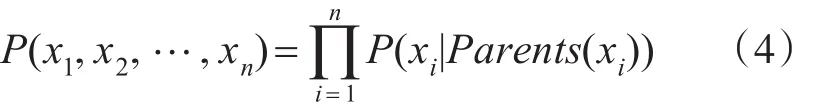
其中Parents(xi)表示(xi)的直接前驱节点的联合,其值可以从相应条件概率表中查到。
不同于贝叶斯网络,朴素贝叶斯网络基于贝叶斯网络,它假设类别属性之间是条件独立,是一种约束型贝叶斯网络。两者的分类原理是相似的,都是建立在统计概率学基础之上的,已知待分类样本的先验概率,结合贝叶斯定理计算待分类样本所属类别的概率,计算所得最大值则作为待分类样本的类别。图2和图3分别给出了贝叶斯网络和朴素贝叶斯网络的模型图。
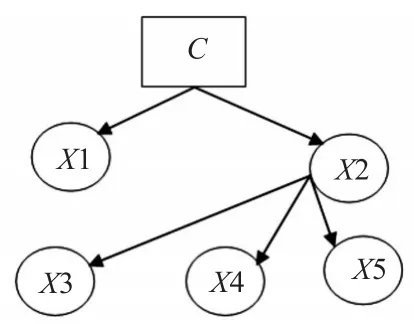
图2 贝叶斯网络模型图

图3 朴素贝叶斯网络模型图
2.3 基于朴素贝叶新网络模型的话题追踪应用分析
基于朴素贝叶斯网络的话题追踪,实际是一个文本分类,分类步骤可以分为以下两步:1)根据己知话题的训练样本,通过训练得到朴素贝叶斯网络的结构和参数,但是需要指出的是结构和参数的训练通常是交替进行的;2)利用训练得到的朴素贝叶斯网络对待分类项(未知类别的测试微博文本)进行分类。下面使用朴素贝叶斯网络模型来对话题的追踪应用进行分析,为了简单起见,对朴素贝叶斯网络模型的结构做了适当的简化,如图4所示。
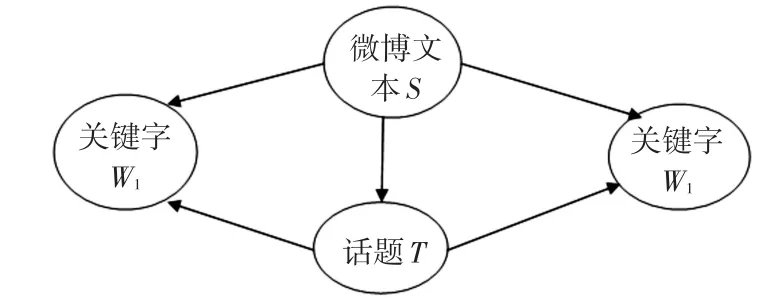
图4 描述微博文本、话题和关键字的朴素贝叶斯网络
图4 是一个有向无环图(DAG),图中每个节点表示一个随机变量,而有向弧则表示指向结点影响被指向结点。根据朴素贝叶斯网络模型可知,可以用先验概率表示没有前驱节点的节点,而对于有直接前驱节点的,在构建朴素贝叶斯模型的结构时,其条件概率一般是已知的,假设已知报道S={W1,W2},S属于待分类项,T属于某一话题,计算报道S所属的话题类别P(T|S),可以利用贝叶斯式(5):
P(T|S)=P(T|W1,W2)=P(W1|T)(T)P(W2|T)/P(W1W2)(5)
3 基于朴素贝叶斯网络的微博话题追踪
针对微博话题追踪任务和微博文本的特点[5~6]。本文提出了基于朴素贝叶斯网络的话题追踪流程图,如图5所示,首先确定朴素贝叶斯网络模型的结构,根据训练语料(需要人工标记)训练贝叶斯网络模型结构和参数,形成贝叶斯网络分类器,然后从微博文本集中抽取一篇微博,抽取特征词并计算其权重[7],形成事件报道模型,结合贝叶斯分类器,计算该微博所属话题类别,从而实现微博话题追踪[8]。
3.1 基于朴素贝叶斯网络的微博话题追踪流程
结合图5可知,朴素贝叶斯网络模型的话题追踪具体步骤[9~13]:
1)已知训练微博文本集 D={d1,d2,d3,…,dn}每一个训练样本 dj={f1,f2,f3,…,fn},每个 fk为 dj的 一 个 特 征 属 性 , k∈{1,2,3,…,n} ,j∈{1,2,3,…,n}。对于从事件报道库抽取的微博(非训练样本),xj={t1,t2,t3,…,tn}为一个待分类项。
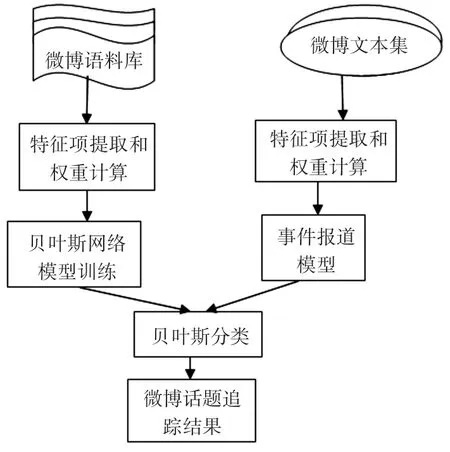
图5 基于朴素贝叶斯网络模型的微博话题追踪流程图
2)有类别的话题集合 C={c1,c2,c3,…,cn},其中Ck∈C话题类别变量,分类的任务就对未知话题的事件报道样本 xj={t1,t2,t3,…,tn}来预测它的所属话题类别C,如式(6)所示。
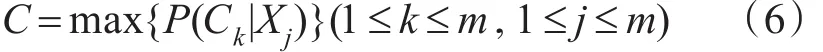
3)根据贝叶斯定理,对式(6)进行展开,如式(7)所示,其中 P(Xj)为某一常数,只需计算P(Xi|Ck)P(Ck),P(Ck)一类别Ck出现的概率,可以通过训练样本估计得到,若样本均衡,该值是一个定值。
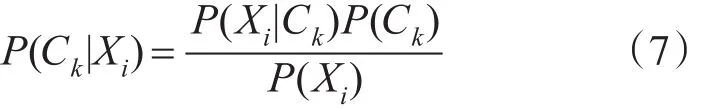
4)计算P(Xi|Ck),如式(8)所示。在计算的过程中,贝叶斯网络模型引入了一些独立性假设:朴素贝叶斯网络特征属性节点的状态相互独立。
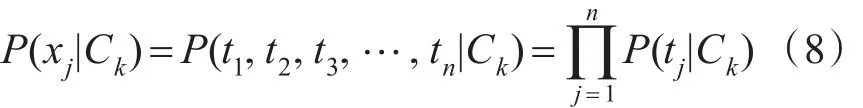
其中P(tj|Ck)表示类别Ck中出现ti的概率,它的值等于特征属性词ti在类别Ck中出现的次数与类别Ck所有特征词出现总数的比值,相关值可以通过查询朴素贝叶斯训练参数表得到。
5)求出C=Max{P(tj|Ck)},k∈{1,2,3,…,n}。
对于步骤4)中P(tj|Ck)的值可以通过在训练朴素贝叶斯网络模型的时候得到,具体的训练步骤如图6所示。
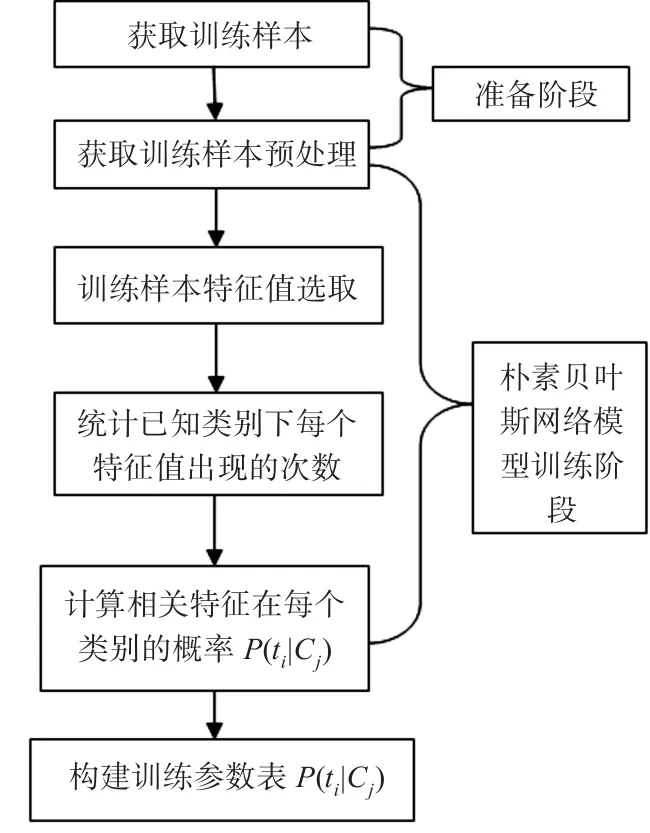
图6 朴素贝叶斯网络模型训练流程图
3.2 估计类别下特征属性的划分条件及Laplace校准
由图6可知,在微博话题追踪的模型中,朴素贝叶斯网络分类的关键步骤在于计算P(tj|Ck)各个类别下每个特征词出现的次数,可以通过查询朴素贝叶斯网络训练参数表得到,但是如果出现某个类别下某个特征项划分没有出现时,即P(tj|Ck)=0这种情形,那么朴素贝叶斯网络模型的分类效果将大大降低。本文则通过引入Laplace校准进行数据平滑,具体实现过程:在训练样本阶段将所有类别下的特征属性的出现频次初始化为1,同时将某一类别下所有的特征词出现的次数初始化为n,n表示特征词的个数。当n充分大时,可以忽略对结果产生的影响。
4 实验设计与结果分析
4.1 数据集
本文实验所使用的微博语料库来自爬萌中国[14],选取2015年1月至2015年12月之间的特定主题微博作为语料库,语料库中选取了300篇微博,选择其中50篇人工标记过的微博作为训练样本,另外250篇作为测试样本,其中选取的训练报道针对5个话题,其中训练集和测试集不存在任何重复的样本。语料的各话题的新闻报道分布如表1所示。
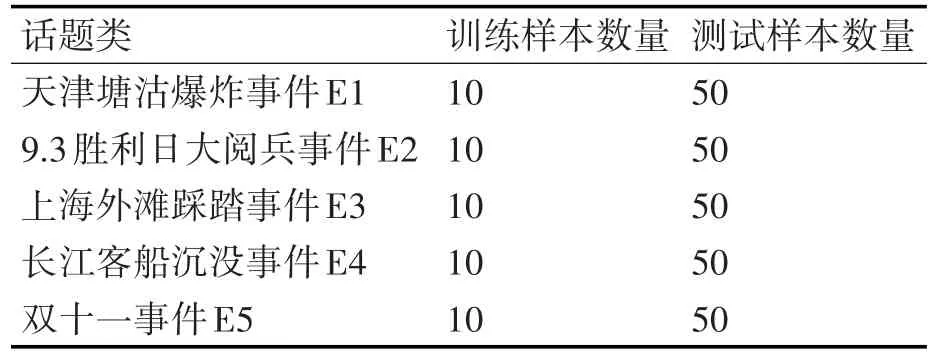
表1 各话题的微博文本分布
4.2 微博文本预处理
根据新浪微博的特点,使用了NLPIR汉语分词系统,对微博文本流进行文本预处理,本次试验选择基于改进型DF的微博文本特征选择方法,用命名实体向量空间模型来表示话题的特征向量F={f1/w1,f2/w2,…,f7/w7},特征属性依次表示一篇微博中日期名、地名、人物名、数词、专有名词、机构名、名词的词向量模型及分类命名实体的词频[15~17],如发生在2015年的天津塘沽爆炸事件的一篇微博如表2所示。

表2 天津塘沽爆炸事件
4.3 实验评价
话题追踪的性能都可以用误报率PMiss和漏报率PFA来表示。CDet就是PMiss和PFA加权求和的结果,计算公式如式(9)所示。
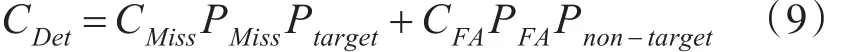
其中,CMiss是系统的错误识别代价,是微博话题追踪系统性能的重要指标,CMiss是未识别代价,CFA是误报的代价。在本文中基于朴素贝叶斯网络的微博话题追踪的过程中,未识别的代价要高于误报的代价,分别取CMiss=10和CFA=1。
Ptarget表示某个话题出现的概率,有Pnon-target=1-Ptarget。PMiss表示未识别率,PFA表示错误识别率。根据式10对CDet做归一化处理。
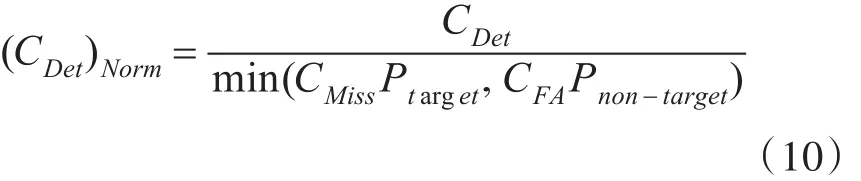
式(10)表明,(CDet)Norm值越小,微博话题追踪性能越好。
4.4 实验结果与相关分析
实验参数选取:Ptarget=0.02,CMiss=1,CFA=0.1,En表示事件序列,使用朴素贝叶斯网络模型得到的实验数据如表3所示。
实验和评测结果表明,基于朴素贝叶斯网络模型能够有效实现微博话题的追踪。
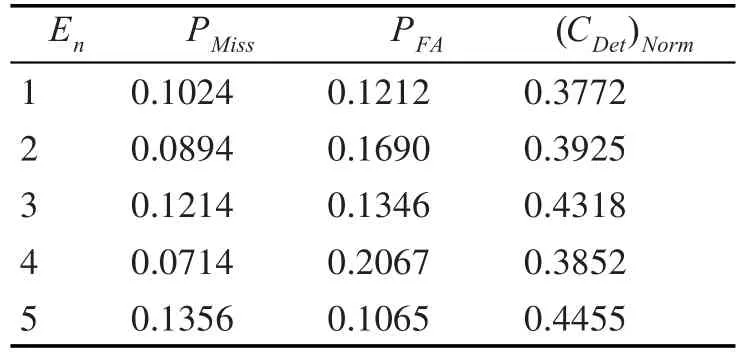
表3 基于朴素贝叶斯网络模型的话题追踪结果
5 结语
本文通过实验的方法验证了基于朴素贝叶斯网络模型微博话题的追踪模型具有算法简单高效、分类效果好,发现其特别适合对热门微博话题的追踪。基于改进型DF的微博文本特征选择方法保留了描述微博事件的主要特征属性—日期名、地名、人物名、数词、专有名词、机构名、名词。这些特征词的属性对描述一个话题的贡献度特别大,而且当特征属性充分多时,朴素贝叶斯网络模型对于个别特征属性表现出极大的抗干扰性,但同时也提高了计算量。
[1]赵新辉,郭瑞.基于数据挖掘技术的网络舆情智能监测与引导平台设计研究[J].电脑知识与技术,2012,8(1):1-2,4.ZHAO Xinhui,GUO Rui.Design and research of intelligent monitoring and guidance platform for network public opinion based on Data Mining Technolog[J].Computer Knowledge and Technology,2012,8(1):1-2,4.
[2]CNNIC.2016第37次中国互联网发展状况统计报告[EB/OL].http://www.cnnic.net.cn/hlwfzyj/hlwxzbg/201601/P020160122469130059846.pdf,2016-63.CNNIC.Thirty-seventh China Internet Development Statistics Report in 2016[EB/OL].http://www.cnnic.net.cn/hlwfzyj/hlwxzbg/201601/P020160122469130059846.pdf,2016-63.
[3]王国华,郑全海,王雅蕾,等.新浪热门微博的特征及用户转发规律研究[J].情报杂志,2014(4):117-121.WANG Guohua,ZHENG Quanhai,WANG Yalei,et al.Research on the Characteristics and Users'Retweeting Rules of Top Trending Micro-blogson Sina[J].Journal of Intelligence,2014(4):117-121.
[4]徐晓东,肖银涛,朱士瑞,等.微博社区的谣言传播仿真研究[J].计算机工程,2011,37(10):272-274.HU Xiaodong,XIAO Yinchao,SHU Shirui,et al.Simulation Investigation of Rumor Propagation in Microblogging Community[J].Computer Engineering,2011,37(10):272-274.
[5]许志凯,徐志明,李栋,等.面向互联网新闻的话题检测与追踪[J].智能计算机与应用,2011(3):59-61,65.XU Zhikai,XU Zhiming,LI Dong,et al.Topic Detection and Tracking for News Web Pages[J].Intelligent Computer and Applications,2011(3):59-61,65.
[6]李爽.从微薄中挖掘有用信息[J].网络与信息,2011(6):98-102.LI Shuang.Mining useful information from micro-blog[J].Network and Information,2011(6):98-102.
[7]刘庆和,梁正友.一种基于信息增益的特征优化选择方法[J].计算机工程与应用,2011,47(12):130-132,136.LIU Qinghe,LIANG Zhengyou.Optimized approach of feature selection based on information gain[J].Computer Engineering and Applications,2011,47(12):130-132.
[8]刘海峰,苏展,刘守生,等.一种基于词频信息的改进CHI文本特征选择[J].计算机工程与应用,2013,(22):110-114.LIU Haifeng,SU Zhan,LIU Shousheng.Improved CHI text feature selection based on word frequency information[J].Computer Engineering and Applications,2013,49(22):110-114.
[9]张春,郭明亮.大数据环境下朴素贝叶斯分类算法的改进与实现[J].北京交通大学学报,2015(39):35-41.ZHANG Chun,GUO Mingliang.Research and realization of improved native Bayes classification algorithm under big data environment[J].Journal of Beijing Jiaotong University,2015(39):35-41.
[10]葛顺,夏学知.基于聚类的朴素贝叶斯分类无监督学习方法[J].舰船科学技术,2016(38):112-116.GE Shun,XIA Xuezhi.Unsupervised learning method of native Bayesian network classifier based on clustering[J].Ship Science and Technology,2016(38):112-116.
[11]贺鸣,孙建军,成颖.基于朴素贝叶斯的文本分类研究综述[J].情报科学,2016(34):147-154.HE Ming,SUN Jianjun,CHENG Ying.Text Classification Based on Naive Bayes:A Review[J].Information Science,2016(34):147-154.
[12]张泽鑫,李俊,常向青.基于特征加权的朴素贝叶斯流量分类方法研究[J].高技术通讯,2016(26):119-127.ZHANG Zexin,LI Jun,CHANG Xiangqing.Internet traffic classification using the attribute weighted naive Bayes algorithm algoritltm[J].High Technology Letters,2016(26):119-127.
[13]赵文涛,孟令军,赵好好,等.朴素贝叶斯算法的改进与应用[J].测控技术,2016(35):143-147.ZHAO Wen-tao,MENG Lingjun,ZHAO Haohao,et al.Improvement and Applications of the Naive Algorithm[J].Measurement and Control Technology,2016(35):143-147.
[14]中国爬萌.爬萌数据[EB/OL].http://www.cnpameng.com/,2015-11.China Clima.The data of Climb[EB/OL].http://www.cnpameng.com/,2015-11.
[15]任晓东,张永奎,薛晓飞.基于K-Modes聚类的自适应话题追踪技术[J].计算机工程,2009(9):222-224.REN Xiaodong,ZHANG Yongkui,XUE Xiaofei.Adaptive Topic Tracking Technique Based on K-Modes Clustering.Computer Engineering,2009,35(9):222-224.
[16]孙曰昕,马慧芳,师亚凯,等.融合词语关联关系的自适应微博热点话题追踪算法[J].计算机应用,2014,34(12):3497-3501.SUN Yuexin,MA Huifang,SHI Yakai,et al.Self-adaptive microblog hot topic tracking method using term correlation.Journal of Computer Applications,2014,34(12):3497-3501.
[17]马海兵,毕久阳,郭新顺.文本分类方法在网络舆情分析系统中的应用研究[J].情报科学,2015,33(5):97-101.MA Haibing,BI Jiuyang,GUO Xinshun.Applications of Text Classification in Network Public Opinion System[J].Information Science,2015,33(5):97-101.
Research on Micro-blog Topic Tracking Based on Naive Bayesian Network
FENG Junjun HE Xiaochun WANG Haipei
(Sichuan Information Technology College,Guangyuan 628017)
According to the characteristics of micro-blog,this paper proposes micro-blog topic tracking algorithm based on naive Bayesian network model,and at the base of the foregoing improved DF text feature selection method,the micro-blog topic tracking system is designed and implemented.The experimental results show that micro-blog topic tracking system based on the naive Bayesian network model is simple,efficient,especially suitable for tracking hot topics on micro-blog.
naive Bayesian,micro-blog,topic tracking
TP391.1
10.3969/j.issn.1672-9722.2017.11.034
Class Number TP391.1
2017年5月2日,
2017年6月23日
冯军军,男,硕士,助教,研究方向:嵌入式系统及应用和信息安全技术。贺晓春,男,讲师,研究方向:网络安全。王海沛,男,硕士,助教,研究方向:云计算应用和数据分析。
猜你喜欢
作文大王·低年级(2022年3期)2022-03-19
小资CHIC!ELEGANCE(2021年36期)2021-10-15
法律方法(2021年4期)2021-03-16
法律方法(2021年4期)2021-03-16
四川文学(2020年11期)2020-02-06
当代陕西(2019年23期)2020-01-06
当代陕西(2019年9期)2019-05-20
小学生作文·小学低年级适用(2018年12期)2018-04-11
智富时代(2018年11期)2018-01-15
智富时代(2018年11期)2018-01-15
