
基于查询关联模型的排序支持向量机方法
2018-01-01 10:21张潇霄
科学与财富 2017年30期
关键词:信息检索
张潇霄

摘要:排序学习是信息检索、机器学习和数据挖掘等领域的重要研究课题,其核心任务是建立排序损失函数并进行优化而获得排序模型。近年来,排序支持向量机RSVM(ranking support vector machine)以其理论性和有效性,被广泛应用到如文本检索、网页搜索、自然语言处理等领域。然而,基于排序偏序对构建损失函数的排序支持向量机算法具有以下不足:1)在不同的查询偏序对数目不同时,模型训练过程将偏向偏序对多的查询;2)其损失函数的优化过程并未考虑到排序性能评价指标。上述缺点导致排序支持向量机在实际应用中性能受到局限。因此,本文提出基于查询关联模型的排序支持向量机模型,在查询的偏序对数目均一化的基础上,加入反映排序性能评价指标的查询关联模型对排序模型进行正则化,并推导出高效的策略获取排序模型。实验结果表明,本文提出的方法在多个数据集上排序性能较好,优于传统排序支持向量机、均一化偏序对数目的排序支持向量机等算法。
关键词:信息检索;排序学习;查询关联模型;排序支持向量机
排序在信息检索和数据挖掘等领域中诸多应用中均占据重要地位[1]。近年来,使用机器学习技术来进行排序已发展为新的研究分支“排序学习”,是目前信息检索、数据挖掘、机器学习和生物计算等领域研究的热点问题。不失一般性,本文以信息检索为例进行排序学习的研究。
在信息检索中,排序学习的主要过程为:“查询-文档”对集合被标注后,分为训练集、验证集、测试集;排序模型由训练集训练生成,通过验证集进行参数调节,最终由测试集进行测试并采用MAP[1]和NDCG[2]等指标进行评估。排序学习将传统排序问题转化为从排序特征到标注的学习问题,通过对不同任务或应用进行具体分析,建立不同的排序数学模型和损失函数并进行优化,可以获得适用于不同任务或应用的排序模型。
现有的众多排序算法如Prank[3]、Rank SVM等,排序支持向量機(RSVM)是主流的方法之一,其排序性能好而且理论性强。RSVM也具有不足之处:1)当不同的查询偏序对数目不同时,模型训练过程将偏向偏序对多的查询;2)其损失函数的优化过程并未考虑到排序性能评价指标。上述缺点导致RSVM在实际应用中性能受到局限。
本文在IRSVM的工作基础上,提出基于查询关联模型的排序支持向量机来弥补第二个不足之处。具体地,在查询偏序对数目均一化的基础上,加入反映排序性能评价指标的查询关联模型对排序模型进行正则化。实验结果表明,本文提出的方法在多个数据集合上排序性能较好,优于传统排序支持向量机(RSVM)、均一化偏序对数目的排序支持向量机(IRSVM)等算法。
1 排序支持向量机模型及分析
1.1 排序支持向量机模型
令 为“查询-文档”对的特征向量空间, 代表特征维数,
代表特征向量空间对应的标注值, 代表标注等级,用
表示一个“查询-文档”对的特征和标注。
给定训练集合 ,每一个查询 均对应自身的文档集合,可表示为 ,整个训练集合可表示为 。
排序学习模型通过训练集上学习得到排序函数 ,满足当标注
时, ,其中 表示偏序关系。整个训练过程在排序函数空间 中寻找最小化损失的函数 :
(1)
在排序支持向量机(RSVM)模型中 是特征 的线性函数 ,其中 表示点积。基于已有训练集合S,RSVM生成新的训练数据集S',对S中同一查询下的具有不同标签 , 的特征 ,构建 ,满足当 时 ,否则为 。为表示简便,将 表示为 ,其中 代表所有生成偏序对个数。RSVM的模型如下[4][5]:
(2)
其中 为 范数的模型复杂度惩罚项, 为松弛变量, 为用于平衡模型复杂度和偏序对损失的参数,训练优化后会得到排序模型w*,最终用于测试时 。
1.2 模型分析讨论
对公式(2)的分析得出,RSVM存在以下问题:
1)当不同的查询其偏序对数目不同时,模型训练过程将偏向偏序对多的查询。
针对上述问题,Cao[6]等人提出IRSVM算法,对不同查询下的文档偏序对个数进行均一化,从而使得所有查询在优化时被同等对待,其模型描述如下[4]:
(3)
其中 表示样本 所在查询的偏序对个数。
2)RSVM损失函数的优化过程并未考虑到排序性能评价指标。由公式(2)的形式化描述可知,在损失函数中并未考虑到通用的评价指标,如MAP[1],NDCG[2]等因素,模型的损失和惩罚都建立在偏序对的基础上。另一方面,现有工作中并无在RSVM上加入性能评价指标优化项。本文基于实验,提出利用查询关联模型替代排序评价指标,选择出反映排序评价指标的关联模型并直接融入RSVM 的优化目标,且推导出高效的优化策略得出最终模型。
2 查询关联模型评估及改进排序支持向量机模型
2.1 查询关联模型评估策略
对于训练集中每一个查询 ,利用RSVM等排序学习算法可学习得到模型 ,我们称之为查询关联模型。在训练集和测试集独立同分布的前提下,训练数据集上获得较好排序性能查询关联模型 ,在测试数据集上的性能也较好,我们通过实验发现,该结论在多个真实数据集上成立。
另一方面,在实验中我们还发现,排序关联模型之间的余弦相似性与排序性能之间具有相关性。
本文指出,在训练集上,每一个查询关联模型的排序性能以及与其它查询关联模型的余弦相似度可以用于衡量排序模型在测试集上的性能,进而可以利用查询关联模型反映性能评价指标,且上述两种方法均可以用于对查询关联模型进行评估:1)根据查询关联模型在训练集上的排序性能评价进行评估;2)根据查询关联模型与训练集上其它查询关联模型的余弦相似度进行评估。
2.2 基于查询关联模型正则化的排序支持向量机
利用上述评估策略,可以对训练集合上的所有查询的关联模型进行评分,获取得分最高的前 个查询关联模型,利用其线性加权和,对IRSVM进行改进,反映出排序性能评价指标的影响。具体地,采用前 个查询关联模型的线性加权和,对排序模型进行正则化:
(4)
公式(4)中,在 范数的模型复杂度惩罚项基础上加入了前 个查询关联模型进行正则化,保证最终训练得到的模型与前 个查询关联模型相近,从而调节偏序对损失与反映性能评价指标的查询关联模型。其中 可以进行调节。对于公式(4)的求解,结合KKT条件,可以转化为其对偶形式,利用二次规划进行求解[5]:
(5)
其中, 是拉格朗日乘子, 代表数据集中所有偏序对个数, ,
。由于篇幅所限,从公式(4)推导至公式(5)的过程不详细展开。
在具体实验中,由于需要验证集进行调参,直接采用公式(5)进行优化的复杂度较高,因此,我们对公式(4)进行了简化。具体地,将公式(3)训练得到的模型表示为 ,将前K个查询关联模型之和 表示为 ,则公式(4)的其最优解的形式可以简化为: , 的范围为[0,1]。
定理一:公式(5)等价于下式:
(6)
证明:展开公式(4)中优化目标的第一项
其中 ,在优化过程中是常数,可被约去,故整体优化目标(5)式可转化成:
(10)
可进一步转化为:
(11)
由于C为可调节参数,故第二项中分子k可被省略。
证毕。
此时,从(6)式可以得出优化模型结果将为公式(4)中的最优模型 与前 个查询关联模型的线性加权和 的组合,故可以进一步简化为 ,其中公式(6)中 之前的系数分子 可被 替代。此时,参数 的调节转化为参数 的调节,从优化原来的由训练集合中的样本的二次规划问题转化为简单的线性组合,大大减少了时间复杂度。从时间上,对于具有N个查询的训练集,设平均每个查询的样本个数为 ,则训练N个查询关联模型的时间复杂度为 ,通常情况下大大小于训练RSVM的时间 ,因为后者为前者的N倍,故加入 的时间复杂度较小。
简化后的 ,结合均一化后偏序对损失的
和反映性能评价指标的 ,在大多数 不能达到最优排序性能的情况下利用 进行正则,通过调节参数 ,减少过拟合,增加模型泛化性,达到更好的排序效果。
3 实验结果与分析
本文在公共数据平台LETOR[7]上的4个数据集进行实验和分析,验证本文提出方法的有效性。
3.1 数据集介绍
本文实验采用的数据集分别为OHSUMED,TREC Topic Distillation 2004(TD2004),Named page finding 2004(NP2004),Homepage Finding 2004(HP2004)。其中,OHSUMED具有106个查询与16,140个“查询-文档”标注对,其中标注分为3个等级:相关,半相关,不相关。TD2004,NP2004和HP2004均具有75个查询,其中“查询-文档”对的标注分为2个等级:相关与不相关。每个数据集上的排序特征不尽相同,以词频(TF),逆文献词频(IDF),Pagerank等排序因子为特征,具体可参见文献[7]。每个数据集均采取5折交叉验证的方式进行实验,并取5折平均结果作为最终实验结果进行对比。
3.2 评价指标
在本文的实验中,主要使用MAP和NDCG来评价排序的性能。
MAP(Mean Average Precision)[1]是在查准率、召回率的基础上派生出的评价指标,用来衡量算法对多个查询的平均排序结果。MAP的计算公式为:
(12)
其中j表示排序的位置,M是检索到的文档总数,Precision(j)是前j个检索到的文档的查准率,pos(j)是一个0-1函数,如果排在第j个文档是相关的,其值为1,否则为0。
NDCG[2](Normalized Discounted Cumulative Gain)在传统评价标准的基础上,考虑了相关性的等级和排序位置的影响,强调评价排序結果中顶部序列的准确性。对于给定一个查询q,第k位的NDCG值NDCG@k的计算公式为:
(13)
其中r(j)是第j个文档的级别,Nk是归一化参数,使得在第k位上的最优排序的NDCG@r的值始终为1。
3.3 实验结果
本文采用的基准方法有RSVM,IRSVM,RBoost,ListNet。为简便起见,本文提出的算法表示为Top-K。其中C参数在一个数据集合上相近,在5个交叉集上略有不同,在OHSUMED上约为10,TD2004上约为1,NP2004上约为0.5,HP2004上约为10。k的设定在OHSUMED和HP2004上为10,TD2004和NP2004上为40。对于查询关联模型的评估策略,OHSUMED采用NDCG@5,TD2004和HP2004采用MAP,而NP2004采用NDCG@10,评估策略均通过验证集进行调整,从验证集中挑选达到MAP指标最高的策略进行最终测试。a的选取,在OHSUMED为0.2,在TD2004上为0.1,在NP2004上为0.8,在HP2004上为0.05。在上述4个数据集上的实验参数调节表明,使用评价指标的评估策略在验证集与测试集MAP的性能表现均优于余弦相似度的评估策略。
表1列举出4个数据集上,不同算法的MAP的对比值,每个数据集上最高性能被加粗显示。从表1可知,Top-K算法的MAP在NP2004和HP2004上较好,在TD2004数据集上高于RSVM,IRSVM,且与ListNet具有可比性。IRSVM在所有数据集上MAP均高于RSVM,且从后面的实验结果中可知,IRSVM在大部分数据集上的NDCG性能也高于RSVM。
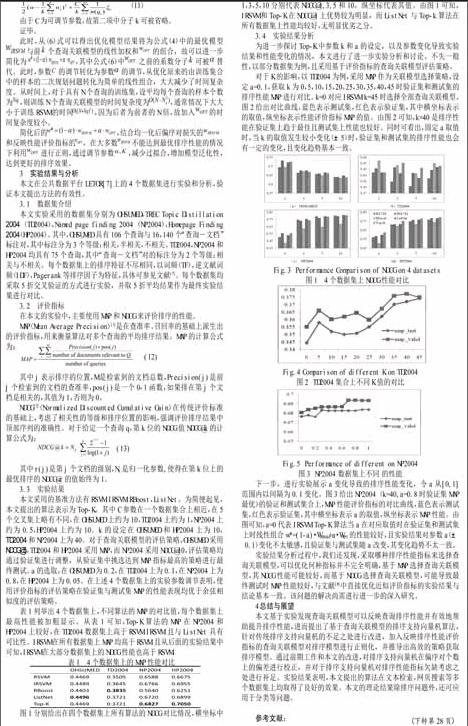
圖1分别给出在四个数据集上所有算法的NDCG对比情况,横坐标中1,3,5,10分别代表NDCG@1,3,5和10,纵坐标代表其值。由图1可知,IRSVM和Top-K在NDCG@1上优势较为明显,而ListNet与Top-k算法在所有数据集上性能均较好,无明显优劣之分。
3.4 实验结果分析
为进一步探讨Top-K中参数k和a的设定,以及参数变化导致实验结果和性能变化的情况,本文进行了进一步实验分析和讨论。不失一般性,以部分数据集为例,且采用基于评价指标的查询关联模型评估策略。
对于K的影响,以TD2004为例,采用MAP作为关联模型选择策略,设定a=0.1,获取k为0,5,10,15,20,25,30,35,40,45时验证集和测试集的排序性能MAP进行对比。k=0对应IRSVM,k=45时选择全部查询关联模型。图2给出对比曲线,蓝色表示测试集,红色表示验证集,其中横坐标表示 的取值,纵坐标表示性能评价指标MAP的值。由图2可知,k=40是排序性能在验证集上趋于最佳且测试集上性能也较好。同时可看出,固定a取值时,当k的取值发生较小变化(±5)时,验证集和测试集的排序性能也会有一定的变化,且变化趋势基本一致。
下一步,进行实验展示a变化导致的排序性能变化,令a从[0,1] 范围内以间隔为0.1变化。图3给出NP2004(k=40,a=0.8时验证集MAP最优)的验证和测试集合上,MAP性能评价指标的对比曲线,蓝色表示测试集,红色表示验证集,其中横坐标表示a的取值,纵坐标表示MAP性能。由图可知,a=0代表IRSVM,Top-K算法当a在对应取值时在验证集和测试集上时线性组合w*=(1-a)·WIRSVM+a·WOPT的性能较好,且实验结果对参数a(±0.1)变化不太敏感,且验证集与测试集随a改变,其变化趋势不太一致。
实验结果分析过程中,我们还发现,采取哪种排序性能指标来选择查询关联模型,可以优化何种指标并不完全明确,基于MAP选择查询关联模型,其NDCG性能可能较好,而基于NDCG选择查询关联模型,可能导致最终测试时MAP性能较好,与文献[8]中直接优化近似评价指标的实验结果与结论基本一致。该问题的解决尚需进行进一步的深入研究。
4 总结与展望
本文基于实验发现查询关联模型可以反映查询排序性能并有效地帮助提升排序性能,进而提出了基于查询关联模型的排序支持向量机算法,针对传统排序支持向量机的不足之处进行改进,加入反映排序性能评价指标的查询关联模型对排序模型进行正则化,并推导出高效的策略获取排序模型。通过前期工作和本文的改进,对排序支持向量机在偏序对个数上的偏差进行校正,并对于排序支持向量机对排序性能指标欠缺考虑之处进行补足。实验结果表明,本文提出的算法在文本检索,网页搜索等多个数据集上均取得了良好的效果。本文的理论结果除排序问题外,还可应用于分类等问题。
参考文献:
1.Baeza-Yates,R.,Ribeiro-Neto B. Modern Information Retrieval [M]. Boston, MA: Addison-Wesley Longman Publishing Co: 1999
2.Jarvelin,K.and Kekalainen,J.Cumulated Gain-based Evaluation
of IR Techniques.[J]. ACM Transactions on Information Systems, 2002, 20(4):422-446
3.Crammer,K.,and Singer, Y. PRanking with ranking[C]// Proc of the 14th Conference on Neural Information Processing Systems. British Columbia, Canada: ACM 2001: 641-647
4.Herbrich, R.,Graepel,T.,and Obermayer,K.Large margin rank boundaries for ordinal regression[M].Smola, A., Bartlett, P.,Scholkopf,B.,and chuurmans, D.,eds.,Advances in Large Margin Classifiers. MIT Press, 2000: 115-132.
5.Joachims, T. Optimizing Search Engines Using Click-through Data[C]// Proc of the 8th ACM SIGKDD Conference. New York, USA: ACM 2002: 133-142
6.Cao, Y., Xu, J., Liu, T.-Y., et al. Adapting ranking SVM to document retrieval[C]// Proc of the 29th ACM SIGIR Conference. Seattle, USA: ACM, 2006: 186-193
7.Liu, T., Xu, J.Qin, T.,et al. LETOR: Benchmark Dataset for Research on Learning to Rank for Information Retrieval.[C]// Proc of the 30th ACM SIGIR Conference. Netherland: ACM, 2007
8.Qin, T., Liu, T.-Y., Li, H. A general approximation framework for direct optimization of information retrieval measures.[R] MSR-TR-2008-164, Microsoft Research, 2008
猜你喜欢
吉林化工学院学报(2021年8期)2021-09-06
科教导刊·电子版(2021年30期)2021-01-03
电脑与电信(2018年11期)2018-02-16
山西青年(2018年5期)2018-01-25
新闻传播(2016年18期)2016-07-19
新闻传播(2016年11期)2016-07-10
现代计算机(2016年11期)2016-02-28
地理与地理信息科学(2015年4期)2015-10-13
教育与职业(2014年36期)2014-04-17
河南科技(2014年11期)2014-02-27
