
基于Bloomfilter降低云数据库网络延时的影响
2018-01-19 11:35刘淑平李仲游
软件导刊 2018年10期
刘淑平 李仲游

摘要:为了改善服务器端系统登录模块运行环境, 采用云数据库解决方案,但该方式可能引发额外的网络延时消耗,导致系统性能下降。基于Bloom filter算法设计过滤器,提前判定数据是否在数据库中,能够减少数据库读取次数,进而降低网络延时带来的额外性能损耗。结合Redis良好的分布式性能及持久化方案对Bloom filter进行管理。实验结果表明,当查询非命中率达到0.5%时,可以有效降低系统整体网络延时及响应延时。得出结论:采用基于Bloom filter的过滤器对数据是否在数据库中进行判定,能够降低网络延时带来的影响,从而提高系统整体响应性能。
关键词:云数据库;Bloom filter;Redis;网络延时
DOIDOI:10.11907/rjdk.181296
中图分类号:TP391
文献标识码:A 文章编号:1672-7800(2018)010-0183-04
英文摘要Abstract:To reduce the performance loss of the login module caused by the network delay running on cloud database.,we use the filter which base on Bloom filter to judge if each data have been load in database or not to reduce the number of database read so that the performance loss caused by the network delay can be reduced. Bloom filter is managed by Redis distributed version which can promise high availability. Experiment results show that when the total query proportion of missing Sql query is more than 0.5% in the database base, the overall system network delay can be effectively reduced by using Bloom filter and the overall system response delay can be reduced. Thus we can get a conclusion that the filter based on Bloom filter can reduce the impact of network delay and improve the overall system response.
英文关键词Key Words:cloud database;Bloom filter; Redis;network delay
0 引言
近年来,云数据库技术发展迅速。与传统数据库相比,云数据库具有以下优势[1]:①高可用性,异地多机热备份;②低维护成本,无需维护数据库运行服务器,运维交由云厂商负责;③具有弹性伸缩配置等特性,无需数据迁移,可根据需要提高数据库运行硬件配置。因此,越来越多公司采用云数据库中的RDS(relational Database Service)服务代替企业内部自建的Mysql、Oracel、Sql Server、Postgre Sql等数据库服务器。然而,由于云数据库是通过网络提供服务的,所以服务器访问数据可能出现网络延时现象。所以如何降低网络延时的影响,使服务器更高效地对外提供服务,是一个亟待解决的问题。
对于云数据库运行环境,网络延时的优化可以从两个角度出发:①请求服务器端;②云数据库服务端。但依靠云数据库服务端优化网络延时需要云厂商配合,实现难度较高。因此,本文从请求服务器端优化角度出发,借鉴现有的Hbase[5]、Spark、Tensorflow等系统中的过滤器(filter)思想[7],利用Bloom filter算法实现过滤器[13],同时结合Redis对数据库数据存在与否进行判断[6],以减少不存在的数据访问数据库的消耗,进而弥补网络延时带来的系统总体损失。
1 相关技术
1.1 Bloom filter
Bloom filter由Burton Bloom于1970年提出,該算法基于哈希算法原理,用于判断一个元素是否在集合中,具有高效、占用内存少的优点。但是标准Bloom filter具有容量固定的缺陷,需要通过再次定义并扩大Bloom filter容量的方法加以解决。Bloom filter属于概率性数据结构(probabilistic data structure),可适用于允许有假阳性(false positive)、不允许有假阴性(false negative),并且无需知道元素出现次数的场合。因此,Hbase底层利用Bloom filter判断数据是否在数据库中。Bloom filter具有许多变种,如动态增长Bloom filter[9]、Counting Bloom filter、Cuckoo filter[4]等,但是变种Bloom filter可能产生新的问题,如Counting Bloom filter会增加内存占用,动态增长Bloom filter会导致假阳性几率增加,Cuckoo filter基于多维数组进行存储不利于管理等。因此,本文采用标准Bloom filter,标准Bloom filter原理及具体实现如下:
1.1.1 标准Bloom filter原理
Bloom filter具有H1,H2…Hk共K个相互独立的散列函数,其值域为{0,1,…,m-1},还需一个长度为M的数组作为散列表(数组中每一位只能为0或1),初始化时数组每一位都为0。对于任意一个数据对象x (x∈S,S为一个具体数据对象集,x为S中一个数据对象) ,将第i(1≤i≤k)个哈希函数映射的位置Hash i(x) 置为 1。 同理,当需要插入一个数据对象S时,步骤如下:①假设{x1,x2..,xn}∈S,对于任意一个x∈{x1,x2..,x3},分别计算出{hash1(x),hash2(x),…,hashk(x)};②将计算出散列函数值对应的散列表位置都置为 1。类似地,需要判断任意一个数据对象Q是否在Bloom filter中,重复上述步骤①,然后对比计算散列函数对应的散列表位置是否都为 1,若全為1表明Q在Bloom filter表达的数据集合中,反之则不存在。
1.1.2 初始化操作
(1)初始化一个长度为M的数组作为散列表,默认初始化数组中每一位为0,数组每一位也只允许两种状态:0或1。该表达方式刚好对应内存底层实现1bit位的定义。因此,出于节省空间考虑,可以用1bit位直接映射数组每一位,而不是用32bit表达数字[11]。
(2)初始化K个相互独立且值域都在{0,1,…,m-1}范围内的哈希函数,用于元素哈希映射[16]。
(3)对于任意一个x,其中x∈{x1,x2..,xn}∈S,先利用MD5或SHA-1(一般工业应用上选用Murmur3算法)等杂凑算法将不定长的内容x映射为一固定长度的字符串str。对于str中的每一位,计算K个哈希函数对应的散列表位置,并将散列表对应位置置为1[14]。如果散列表对应的位置已置为1,则不作任何修改。该状况也称为冲突,冲突的出现是假阳性出现的必要条件。
1.1.3 数据存在检验
该方式类似于数据集合的载入操作,不同之处在于数据检验时不需要将散列表对应位置置为1,只需判断所有映射在散列表中的数据是否为1。极端情况下,数据并不存在于数据集合中,但由于数据集合某次映射将散列表某位改变为1,假如所有用于数据存在检验的散列表映射位都为1,则出现了误判现象(即假阳性出现的原因)[12]。
1.2 Redis
Redis是一种基于内存的 Key-Value 数据库产品,其支持多种数据类型的存储: 字符串(string) 、 链表(list)、集合(set) 、有序集合与哈希类型(利用Redis中的哈希类型实现Bloom filter)。各种类型都支持多种操作,还提供了部分数据结构原子性操作功能。由于数据都保存在内存中,为了保障数据安全,Redis还实现了数据持久化操作,其可以定期将内存中更新的数据异步写入磁盘,同时不影响对外服务。在此基础上,Redis还具有主从复制功能,这对于预防单点故障及提高负载能力有很大帮助。利用该特性,可以将Bloom filter顺利部署到多个机器上,从而实现分布式部署。Redis的出现在很大程度上弥补了 Memcached 的不足,其不仅支持更加丰富的数据类型与操作,而且在读写效率上也比Memcached 更胜一筹。
2 问题分析
2.1 网络延时原因分析
以国内某云厂商为例,如图1所示,所有的数据库请求都需要通过ECS(服务器端)传输到RDS(云数据库端)。其中有多个环节,包括:ECS(云主机)→DNS→SLB→Proxy→RDS(云数据库),而ECS自建数据库是ECS→ECS,RDS的网络链路比ECS自建数据库多3个网络链路环节。这些网络链路的网络延时即为RDS对外服务的网络延时。为了简化测算,本文采用ECS到RDS服务的SLB网络延时作为网络延时,RDS内部网络延时对外视作透明。
2.2 网络延时测算
2.2.1 测算环境
(1)服务器:阿里云(默认配置为ECS.xn4.small)。具体配置如下:CPU为Intel Xeon E5-2682v4 1核,内存为 1GB,硬盘为1240 IOPS 40GB高效云盘,系统为 Centos 7.3。
(2)云数据库:阿里云RDS(通用型)。具体配置如下:CPU为1 核,内存为1GB(单机基础版),硬盘为20GB,数据库为MySQL 5.7。
2.2.2 测试方式
具体测试步骤如下:
(1)在数据库中建立测试库test,test下建立测试表user_login。以12位定长int数据结构字段id为主键,45位不定长数据结构字段str作为模拟用户登录表。
(2)在ECS端随机插入1千万条用户信息。
(3)从RDS端抽取一百万条不重复主键ID,放入ECS中。ECS逐次查询这些用户信息(查询用户都存在于数据库内),模拟线上登录,采集并监控RDS运行状态,每隔5s(减缓监控压力,以避免影响查询性能)采集一次,如图2所示。RDS命中数据查询性能如表1所示。
(4)在ECS端随机生成不存在于数据库中的ID共一百万条,逐条输入以模拟线上输入错误,采集并监控RDS运行状态,每隔5s(减缓监控压力,以避免影响查询性能)采集一次,RDS不命中数据查询性能如表2所示。
(5)通过Linux自带的ping命令每隔1s采集一次ECS到SLB的延时,采集时长为86 400s(24h整),网络延时数据如表3所示。
(6)为了简化实验,利用Python实现Bloom filter算法并测试Bloom filter性能,对应Bloom filter(1 000w次测试性能)数据如表4所示。
综上所述,查询平均耗时为1.193ms,网络平均耗时为0.108ms。查询总耗时为1.193+0.108=1.301ms,其中网络耗时占0.108/1.301≈8%。因此,减少网络延时对于降低查询总体延时,以及改进登录模块总体耗时具有重要意义。
3 登录模块改进方案
3.1 模块改进方案
改进前的登录模块结构如图3所示,为了提高代码复用率,实现高内聚、低耦合的设计理念,对于登录模块的改进将会通过改进数据库中间件加以实现,以实现功能与代码的复用[10]。对数据库中间件运行机制改进如下:①初始化数据库连接池;②生成独立任务队列,并初始化数据缓存;③开启队列监听,当有任何任务进入队列,先查询数据是否在缓存中,如果缓存命中,返回缓存结果,否则,立即对RDS执行相应的Sql请求。如果是核心业务请求,则通过持久化技术将请求保持在磁盘上;④RDS返回Sql请求,中间件按照请求参数判断是否缓存请求结果,并且设定缓存有效期;⑤中间件将结果返回到模块的相应进程中。改进后流程如图4所示。
3.2 模块改进方案性能测试
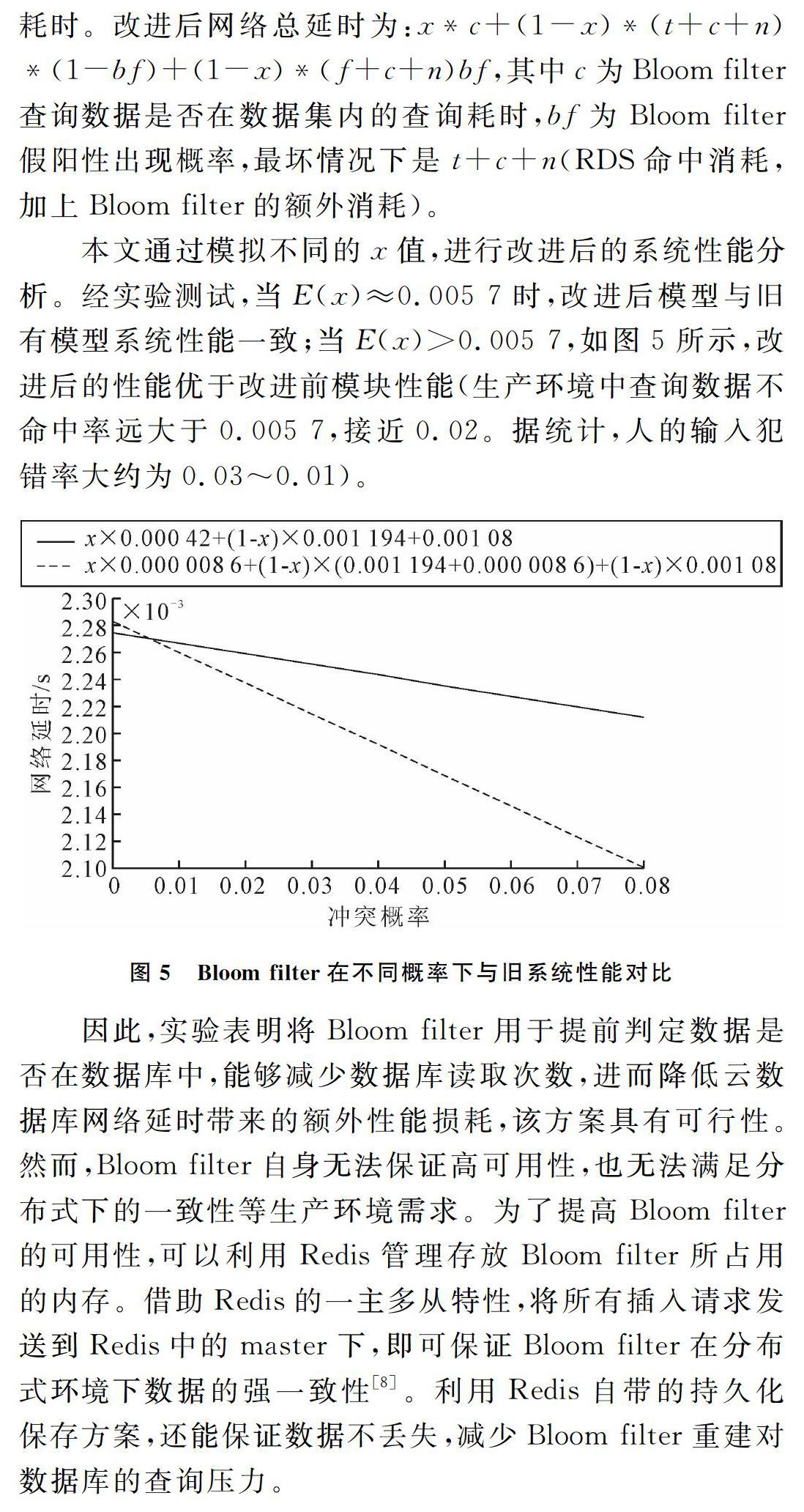
实验时所有实验环境都关闭缓存,避免緩存的命中率干扰实验的准确性与公平性。改进前网络总延时为:x*f+(1-x)*t+n,x为数据不存在于数据库中的数学期望值概率,f为Sql查询数据库中不存在数据的查询耗时,t为查询数据库中存在数据的查询耗时,n为网络传输耗时。改进后网络总延时为:x*c+(1-x)*(t+c+n)*(1-bf)+(1-x)*(f+c+n)bf,其中c为Bloom filter查询数据是否在数据集内的查询耗时,bf为Bloom filter假阳性出现概率,最坏情况下是t+c+n(RDS命中消耗,加上Bloom filter的额外消耗)。
本文通过模拟不同的x值,进行改进后的系统性能分析。经实验测试,当E(x)≈0.005 7时,改进后模型与旧有模型系统性能一致;当E(x)>0.005 7,如图5所示,改进后的性能优于改进前模块性能(生产环境中查询数据不命中率远大于0.005 7,接近0.02。据统计,人的输入犯错率大约为0.03~0.01)。
因此,实验表明将Bloom filter用于提前判定数据是否在数据库中,能够减少数据库读取次数,进而降低云数据库网络延时带来的额外性能损耗,该方案具有可行性。然而,Bloom filter自身无法保证高可用性,也无法满足分布式下的一致性等生产环境需求。为了提高Bloom filter的可用性,可以利用Redis管理存放Bloom filter所占用的内存。借助Redis的一主多从特性,将所有插入请求发送到Redis中的master下,即可保证Bloom filter在分布式环境下数据的强一致性[8]。利用Redis自带的持久化保存方案,还能保证数据不丢失,减少Bloom filter重建对数据库的查询压力。
4 结语
本文针对采用云数据库解决方案改善登录模块运行
环境后,导致额外网络延时消耗的问题,详细分析了云数据库网络延时带来的系统消耗以及Bloom filter的系统消耗,论证了利用Bloom filter提高模块整体性能的可行性,并且通过模拟不同数据的命中概率,给出不同数据命中概率下的具体性能表现,从而降低了登录模块整体耗时,提高了系统整体响应性能。
参考文献:
[1] 林子雨,赖永炫,林琛,等.云数据库研究[J].软件学报,2012,34(5):1148-1166.
[2] CORMODE G. Count-min sketch[J]. Encyclopedia of Algorithms, 2009,29(1):64-69.
[3] FAN B, KAMINSKY M, ANDERSEN D G. Cuckoo filter: better than bloom[J].The magazine of USENIX & SAGE, 2013,38:36-40.
[4] 吕健波,戴冠中,慕德俊.绝对延迟保证在Web应用服务器数据库连接池中的实现[J].计算机应用研究,2012,29(5):1838-1841.
[5] 刘元珍.Bloom filter及其在网络中的应用综述[J].计算机应用与软件,2013(9):219-220.
[6] 徐爱萍,王波,张煦.基于Hbase的时空大数据关联查询优化[J].计算机应用与软件,2017,34(6):37-42.
[7] 罗军,陈席林,李文生.高效Key-Value持久化缓存系统的实现[J].计算机工程,2014,40(3):33-38.
[8] BHUSHAN M, BANERJEA S, YADAV S K. Bloom filter based optimization on Hbase with MapReduce[C].International Conference on Data Mining and Intelligent Computing. IEEE, 2014:1-5.
[9] 李文昊.基于确定性执行策略的分布式数据库中间件的设计与实现[D].太原:太原理工大学,2016.
[10] 王韧,朱金连,周亮,等.中间件技术在移动应用数据库开发中的运用[J].电子设计工程,2015(2):170-172.
[11] MOSHARRAF N, JAYASUMANA A P, RAY I. Compacted bloom filter[C].International Conference on Collaboration and Internet Computing. IEEE, 2017:304-311.
[12] 冯锋,吴杰.基于Bloom filter的RFID中间件数据过滤算法研究[J].计算机应用研究,2015(5):1441-1444.
[13] 张进,邬江兴,刘勤让.4种计数型Bloom filter的性能分析与比较[J].软件学报,2010,21(5):1098-1114.
[14] MOSHARRAF N, JAYASUMANA A P, RAY I. Compacted bloom filter[C]. IEEE, International Conference on Collaboration and Internet Computing. IEEE, 2017:304-311.
(责任编辑:黄 健)
