
基于DPC算法与模块密度的改进Chameleon算法
2018-01-24 08:15宫峰勋马艳秋
中国民航大学学报 2017年6期
宫峰勋,邢 晨, 马艳秋
(中国民航大学a.电子信息与自动化学院;b.科技处,天津 300300)
聚类分析是目标分群问题的重要解决方法,是将数据对象划分成子集的过程。Chameleon算法是一种基于图的层次聚类的重要算法,具有聚类精度较高的优点。文献[1]给出了Chameleon算法具体的实现方法,指出Chameleon算法存在时间复杂度较高的缺点。文献[2]引入近邻传播聚类算法(AP算法),改进了Chameleon算法对于输入参数敏感的缺点,在处理大数据集及高维度数据集上更加快速、高效。文献[3]引入k-means算法,改进了Chameleon算法时间复杂度较高的缺点,能适用于文本对象的聚类。但是,文献[1-3]所述算法具备共同缺点——需根据先验知识预先指定聚类数目,上述算法才能终止聚类处理。因此,本文提出一种基于DPC算法(DPC,density peaks clustering)与模块密度函数的改进Chameleon算法,核心是根据数据对象的分布特征估计目标最佳聚类数目,即在第一阶段使用Alex Rodriguez提出的DPC算法建立子簇,第二阶段采用模块密度函数确定最佳聚类数目,代入传统Chameleon算法完成目标聚类。
基于DPC算法与模块密度函数的改进Chameleon算法的优点体现在以下两个方面:①在子簇建立过程中考虑数据的密度信息,DPC算法的引入简化了算法;②在子簇聚类过程中考虑子簇的互联性和近似度信息,在无需指定聚类数目的基础上可自适应得出最佳聚类数目,自动终止算法。仿真实验表明,本文算法较Chameleon算法在聚类正确率、运行时间、输入参数敏感程度等性能上得到了提高。
1 Chameleon算法改进及其结果分析
传统Chameleon算法是一种两阶段算法,其中第一阶段主要完成k-最近邻图的构造与分割过程。k-最近邻图简称Gk图[4],Gk图的构建是将所有数据点都与前k个最近邻的对象间进行边的连接。hMetis算法(多层超图算法)[5]将Gk图划分成一系列互相之间没有连接的子簇。第二阶段主要进行子簇合并,算法通过相对互连性函数和相对近似度函数来决定两个子簇之间的相似度,选择使相似度函数最大的两个子簇进行合并。
1.1 Chameleon算法第一阶段改进原理
Chameleon算法第一阶段引入DPC算法,DPC算法首先刻画聚类中心,再将其他数据点进行进一步指派从而实现数据集的聚类,具体过程如下。
1)密度峰值算法聚类中心的选取
在聚类中心选取中,首先计算所有数据点的局部密度ρi和距离函数δi,这两个函数对聚类中心的选取起到了决定性作用。DPC算法中两个函数的定义如下:
a)局部密度[6]ρi

其中:当 x < 0 时,则 χ(x)=1,当 x ≥ 0 时,则 χ(x)=0;dij是数据点i与数据点j之间的距离;dc为截断距离,截断距离是一个基于全局的量,在实验中使用百分比表示参数dc的值,其值需要人为指定。以dc取5%为例,截断距离dc是通过对所有dij进行升序排列,dc为该排列的参数百分比上的数占总数5%的位置距离数值。ρi表示的是数据集中与此数据点之间距离小于dc的数据点的个数。
b)距离函数[6]δi

该距离的定义是:取比该点局部密度大的所有点的最小距离,对于局部密度存在极值的数据点δi为其他所有的数据点与它的最大距离。
以ρi和δi为坐标轴的图被称为决策图,如图1所示。
具体步骤是:将所有点的局部密度ρi按照由高到低排列,使用两个函数确定聚类中心,一般选取局部密度与距离函数乘积较大的点作为聚类中心。
2)密度峰值算法剩余点的类别指派
I’ve been here since the end of June.自6月末以来我就一直待在这儿。
剩余点的类别按照其编号由小到大逐个进行,剩余点的类别指派原则是:当前数据点的类别标签应与其距离最近且局部密度高于此数据点的点一致。可以发现这种类别指派的特点,其在简化数据点之间关系的同时又考虑了数据点之间的密度与距离函数。

图1 DPC算法决策图举例Fig.1 Example of DPC decision graph
DPC算法在选定聚类中心后,让周围的点采取“跟随”策略[7],聚类到密度比自己大的最近邻所在的簇,这种单链条的指派方式,相当于一个数据与其他数据连接边的条数是1,其简化了后续的聚类步骤,所以DPC算法非常适合于数据的预处理,这也是采用DPC算法对Chameleon算法第一阶段进行改进的原因。
1.2 Chameleon算法第二阶段改进原理
Chameleon算法第二阶段的主要缺陷是子簇合并时算法终点即最终聚类数目需要人为设定。最终聚类数目的设定对数据的了解程度要求较高,如果最终聚类数目设定错误,其对于算法的正确性影响显著。本节针对Chameleon算法第二阶段的局限性进行改进,以达到改进算法可自动确定最佳聚类数目的目的。
Chameleon改进算法第二阶段是在传统Chameleon算法第二阶段中利用相对互连性函数和相对近似性函数[8]进行子簇合并的基础上,引入模块密度函数来完成子簇的合并过程。相对互连性函数RI和相对近似性函数RC的定义如下:
定义1

其中:EC(Ci,C)j为连接簇Ci和Cj的所有边的权重和;EC(C)i为把簇Ci划分为两个大致相等部分的最小等分线切断的所有边的权重和。
定义2

网络中的社团结构划分[9]与聚类问题在数学模型上类似,网络中社团网络结构的划分问题,主要目的就是精准地定义社团,在划分之后进而进行定义的过程。在社团网络中,社团划分中的一个重要指标就是模块密度函数[10]。若社团网络划分为m个社区,定义一个m阶对称矩阵e,其元素eij是网络中将节点i中的顶点链接到社区j中的顶点的所有边的分数。在网络G=(V,E)中,V表示其结点的集合,E表示结点间连接边的集合。模块密度函数[11]的定义如下

Chameleon算法是一种层次聚类算法,可采用层次聚类算法中的树状图来进行社团网络分析,其旨在基于相似性的各种度量或顶点之间的连接强度来发现社团,随后使其自然划分。
图2为计算机生成的3个社区的网络样本进行聚类时树状图与模块密度函数对应关系仿真结果。图2左树状图底部图形表示网络的各个顶点,当进行逐层聚类时,顶点连接在一起以形成更大的社区,直到到达顶部,即所有的社区都连接在一起为止,树状图中任何层的截线表示该级别的社区结构。图2右表示模块密度与聚类数目的关系,模块密度函数在所划分的社区内部连接强度最强时达到最大值。图2左将社区顶点数为12的3个社区的网络样本通过引入模块密度函数的Chameleon算法将网络样本中的顶点自动分为3个社区,在图2右中模块密度在截线标注的最佳划分位置到达峰值,得到最佳聚类数目为3,与初始社团数相同,模块密度函数可自动确定最佳聚类数目,其正确性得以说明。
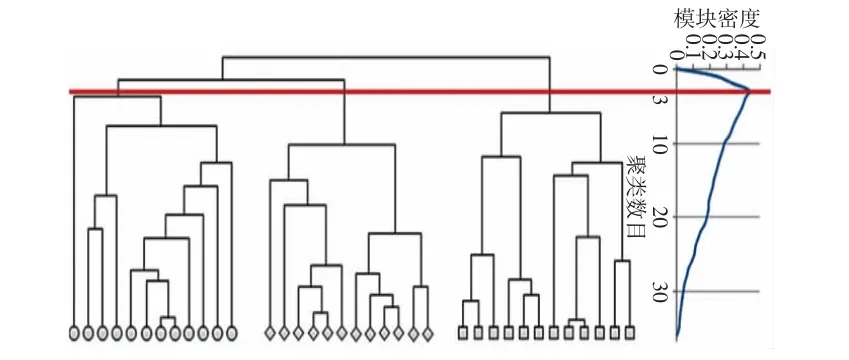
图2 模块密度函数曲线与树状图关系Fig.2 Relationship between module density and tree diagram
1.3 Chameleon算法性能分析
Chameleon算法性能分析首先在真实数据集——IRIS数据集和WINE数据集上进行,IRIS数据集和WINE数据集来自标准数据集UCI[12]。数据集特征如表1所示。

表1 实验数据集特征Tab.1 Experimental dataset features
对于传统Chameleon算法,在第一阶段,Gk图构建时k值的选择对聚类结果存在着一定的影响,随着k值的变化,数据集正确率变化明显,然而对于Chameleon改进算法,第一阶段引入DPC算法后正确率变化较传统Chameleon算法更加平稳且具有更高的正确率,仿真结果如图3所示。
图3为IRIS数据集和WINE数据集上Chameleon算法和dc值取2%时Chameleon改进算法仿真结果的对比,Gk图构建中建立与k个最邻近对象间进行边的连接时,k值的大小势必影响Chameleon算法中hMetis算法图的分割结果,造成最终聚类正确率的差异,由此可见传统Chameleon算法对于参数的选择稳健性较低。对于Chameleon改进算法,其稳健性和正确率都具有明显的提升。
表2为传统Chameleon算法和Chameleon改进算法两阶段运行时间对比,第一阶段与第二阶段的时间都有了明显的降低,算法性能得以提高。其原因是Chameleon改进算法引入DPC算法决策图构建时采用单链条的连接方式,每个数据点的类别与和其最为相近的一个数据点相同,等同于给数据点仅加上一条带权重的边,这种更简单的连接方式意味着后续聚类步骤的简化,大大减少了运行时间。
1.4 改进算法步骤与仿真结果分析
Chameleon改进聚类算法分两个阶段,算法具体步骤如下:

图3 IRIS数据集和WINE数据集的仿真结果Fig.3 Simulation results of IRIS and WINE

表2 算法运行时间结果Tab.2 Operation time results
1)计算各数据点的相似度,构建Gk图作为权重保存;
2)用决策图代替传统Chameleon算法中hMetis算法进行割图,将图划分为大量的子图,将这些产生的子图作为原始簇;
3)计算此时的模块密度函数Q;
4)根据传统Chameleon算法第二阶段相似度函数进行子簇合并;
5)计算模块密度值,判断模块密度Q值是否出现下降,若下降转6),若未下降转4);
6)提醒用户如果继续聚类,可能影响聚类结果的质量。如果继续聚类,转到步骤4)。否则,终止聚类操作,撤销此次合并操作,输出合并子簇前的聚类结果。
为验证Chameleon改进算法的性能,选用多个数据集进行分析。Jain数据集和Spiral数据集来自文献[5],数据集特征如图4所示。
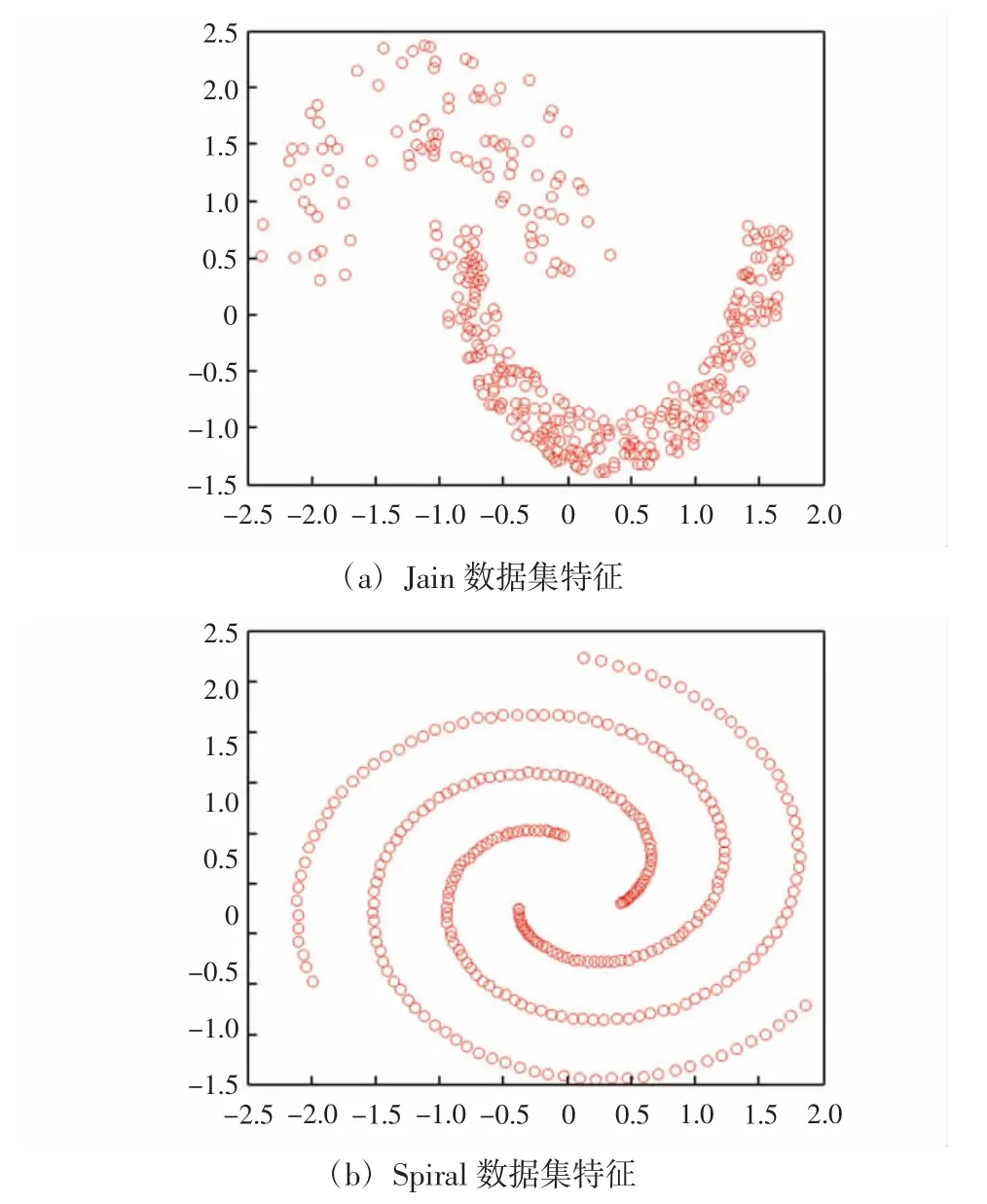
图4 实验数据集特征Fig.4 Experimental dataset features
对于Chameleon改进算法而言,其需要输入参数:截断距离dc和k-最近邻图构建中的k值。下面用上述数据集来验证Chameleon改进算法对于输入参数的稳健性。
图5是DPC算法与Chameleon改进算法在Jain数据集仿真结果对比。如图 5(a)~图 5(c)所示,DPC算法对于dc的选择敏感,其值对聚类效果存在一定影响。图5(d)为当k=20时,dc选取 2%、5%、10%的聚类结果,相同的聚类效果显现了算法对于参数dc的稳健性。在Chameleon改进算法中dc的选取并未对聚类结果造成影响。其次,对于图5(d)也验证了模块密度函数的有效性,自动确定最终聚类数目为2时算法终止。

图5 Jain数据集仿真结果对比Fig.5 Comparison of simulation results on Jain
Spiral数据集为一种流线型数据集,由于其形状的特殊性,很多算法对其不敏感。传统算法与改进算法的仿真结果对比如图6所示。对比图6(a)和图6(b),由于传统Chameleon算法对于k-最近邻图构建中的k值敏感,所以结果受其影响较大,因为k值的不同直接造成数据权重的不同,而后会影响割图时的优先顺序。图 6(c)为 Chameleon改进算法在 k取 3、5、8时的仿真结果。首先,在k值不同时仿真结果一致,Chameleon改进算法对于k-最近邻图中的k值并不敏感。对于流线型数据集,Chameleon改进算法相比于Chameleon算法敏感程度更高,其可以准确地进行聚类,这也是在第一阶段对于k-最近邻图分割时采用DPC算法的优势之一。其次,多次实验表明,改进算法在模块密度函数的作用下,可以自动确定最佳聚类数为3,进而将数据集分为3类,得到准确的聚类结果。

图6 Spiral数据集仿真结果对比Fig.6 Comparison of simulation results on Spiral
表3中数据表示在选取不同k值和dc时的聚类实验结果,Chameleon改进算法具有更短的执行时间、不受输入参数的影响且聚类精度较Chameleon算法有明显提高。
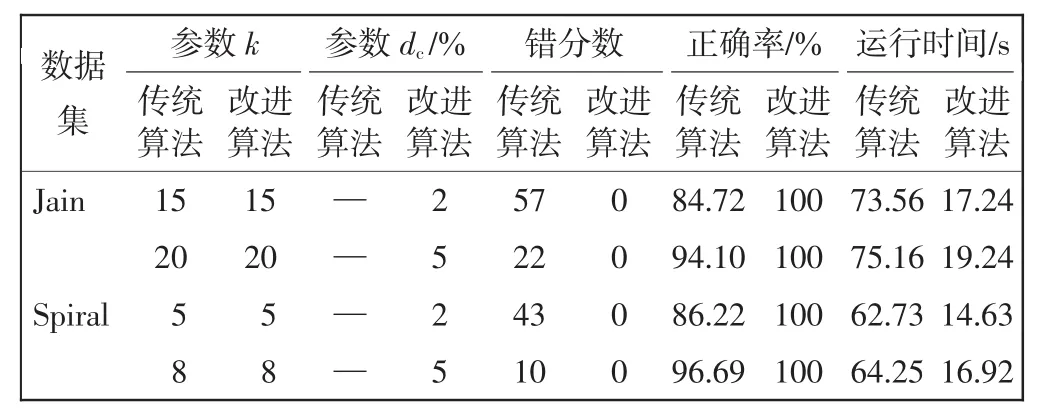
表3 Chameleon传统算法与Chameleon改进算法仿真结果对比Tab.3 Comparison of simulation results between Chameleon algorithm and improved-Chameleon algorithm
总结上述内容可以得出,Chameleon改进算法实现了对两阶段的改进,大大减少了运行时间,对于参数截断距离dc选择不同的情况下可得相似或相同的聚类结果,且可以自适应得出最佳聚类数目,较传统Chameleon算法有了明显的改进。
2 结语
针对Chameleon算法对于输入参数稳健性较低且无法自动确定最佳聚类数目的问题,本文提出了基于DPC算法与模块密度函数的聚类算法。在构建k-最近邻图时,k值对于Chameleon改进算法影响较小,同时在分割k-最近邻图时由于DPC算法采用“跟随”的方式,算法更加简便,大大减少了运行时间。尤其是由于DPC算法的引入,使得Chameleon改进算法对于流线型数据集的敏感程度大幅提高。在k-最邻近图分割后形成的子簇进行合并时,模块密度函数的引入使得算法无需输入最终聚类数目,模块密度函数可自适应得出最佳聚类数目即算法的终止条件。
[1]KARYPIS G,HAN E H,KUMAR V.Chameleon:hierarchical clustering using dynamic modeling[J].IEEE Computer,1999,32(8):68-75.
[2]吴雲玲.结合AP算法的Chameleon聚类算法研究[D].长春:东北师范大学,2014.
[3]黄文江,李 翔,林 祥.基于Chameleon算法的文本聚类技术研究[J].计算机技术与发展,2010,20(6):1-4.
[4]毕 鹏.改进的Chameleon层次聚类算法在目标分群中的应用研究[D].杭州:浙江大学,2009.
[5]魏小凤,胡继承,罗永恩.基于超图模型的软件模块自动划分[J].计算机工程,2016,42(1):71-76.
[6]RODRIGUEZ A,LAIO A.Clustering by fast search and find of density peaks[J].Science,2014,344(6191):1492-1496.
[7]WANG S,WANG D,LI C,et al.Clustering by fast search and find of density peaks with data field[J].Chinese Journal of Electronics,2015,25(3):397-402.
[8]薛文娟,刘培玉,刘 栋.引入共享近邻加权图的Chameleon算法[J].计算机应用,2012,32(10):2884-2887.
[9]张 娜.复杂网络社区结构划分算法研究[D].大连:大连理工大学,2009.
[10]付立东.复杂网络社团的谱分检测方法[J].计算机工程,2011,37(1):31-33.
[11]ARENAS A,DANON L,DIAZ-GUILERA A,et al.Community analysis in social networks[J].The European Physical Journal B,2004,38(2):373-380.
[12]School of Computing University of Eastern Finland.Clustering Datasets[EB/OL].[2017-03-26].http://cs.uef.fi/sipu/datasets/.
猜你喜欢
中学生数理化·八年级物理人教版(2021年12期)2021-12-31
中学生数理化·八年级物理人教版(2021年12期)2021-12-31
小猕猴智力画刊(2021年6期)2021-08-05
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
作文大王·低年级(2016年3期)2016-03-11
现代计算机(2016年17期)2016-02-28
制导与引信(2015年1期)2015-04-20
