
基于属性相关性分析的高校学生成绩分析应用研究
2018-01-29 07:46金诗谱
西安文理学院学报(自然科学版) 2018年1期
金诗谱
(安徽城市管理职业学院 实验实训中心,合肥 230001)
近几十年,数据挖掘应用在国内很多领域都有了较大的发展,唯独高等教育领域的应用还不够多,不够深入[1].当前大多数教育从业者应用意识不强,从而白白浪费了能带来巨大效益的数据资源.
1 决策树及C5.0算法
1.1 决策树
决策树(Decision Tree)是指在各种事物和状况的发生几率已经知晓的情况下,通过构建决策树来准确计算净现值的一个概率,进而对系统的风险进行评估,准确预估各种情况可行性的一种方法[2].该模型主要起预测作用.
1.2 C5.0算法
C5.0的工作原理是根据所提供的最大信息增益的字段来分割样本[3].该算法依据各不相同的字段对子样本进行进一步分割,该过程持续循环,直至无法分割为止[4].其算法伪码如下:输入:J={(x1,y1),…(xm,ym)…,(xn,yn)},xm∈X,ym∈Y;训练轮数为I;初始化分发权值向量:
for i=1,…,I:
(1)采用分发权值向量 Di训练基分类器hi=R(x,y,Di);R为弱分类算法[5];
(2)错误率计算:e=∑(hi(xm)≠ym)Dm
(3)if e≥0.15,break;
(4)基分类器权值计算hi:wi∈w;
(5)权值更新:Di+1(m)=Di(m)×F(e)
(6)将多个基分类器进行联合,输出最后的分类器[6].
其中:xm∈X,ym∈Y,xm代表由相关数据属性构建的向量,ym则代表数据的类别;Di通常叫做数据分发权值向量,wi表示分类器权值,F(x)又被称做更新函数[7].
2 基于属性相关性分析方法的建模过程
采用基于属性相关性分析的决策树构建技术VA-C5.0,在数据的预处理阶段,对数据属性进行相应的分析,根据结果过滤部分属性,同时结合算法来构建决策树,最后通过对比,从精度和时间效率上验证我们改进方法的优越性.数据挖掘流程为:源数据—预处理(属性相关性分析)—建立模型.
2.1 确定数据挖掘对象和目标
基于多年经验,计算机文化基础这门课程,对学生成绩存在可能影响的因素有计算机熟练情况、考试心态、课程兴趣、预习情况、理论课效果、实践课效果、课余上机量、作业完成情况、出勤情况、考前复习时间10个因素.通过数据,对以上因素进行分析,找出主要因素,以及学生成绩为优良,不合格的相关内在影响因素.
2.2 模型的选定
使用VA-C5.0分析方法,通过对采集到的主客观数据的分析学习,得到相应的决策树模型.最终,从根节点到叶子节点的每条路径也就是一条具体的规则,整棵决策树也就相当于很多不同规则的集合.
2.3 数据采集
由教师和学生一起采集数据,2014年共收集了两个学期共1 135人的数据.2015年收集了两学期共1 019人的数据.首先利用2014,2015年的数据建立数据挖掘模型.
2.4 数据预处理
本阶段预先对相关数据进行前期的必要处理.
2.4.1 数据清理与数据集成
把两个学期的数据中的含有缺失值的记录删除.在这里,直接采用忽略元祖的方法,删除掉含有缺失值的记录共188条.有效数据1 966条.
采集的2014年和2015年两年的数据,原始样本总数2 154,经过处理后参加模型构建的有效样本数为1 966,样本的有效率为91.3%.
2.4.2 数据离散化
用于分类的决策树算法需要离散化的数据,我们根据时间的多少,把考前复习时间离散化为“从不”,“一般”,“多”.课余上机量离散化为“无”,“一般”,“多”.期末成绩属性离散化为“不及格”,“及格”,”良好”,“优秀”.最终经过数据清理,数据集成和数据规约后的成绩数据共有1 966条实例.
2.5 VA-C5.0属性相关性分析方法具体实施
属性相关性分析是对数据属性进行相关分析,从而检索出那些对挖掘模型有利的数据,过滤掉部分不利于挖掘模型精度和时间效率的属性的一种方法.
2.5.1 进行属性相关性的图形分析
我们查看各个属性在期末成绩上的分布,进而用条形图的形式进行直观展现(图1).

图1 考前复习时间相关性分析图
举例考前复习时间相关性分析如图1,其他分析类似操作,此处就不一一列出.
2.5.2 通过关系矩阵分析
查看各字段和期末成绩字段的关系.对所有字段和期末成绩字段之间的关系通过矩阵来进行展示,举例说明预习情况和期末成绩的关系,如图2.
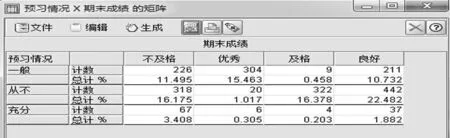
图2 预习情况和期末成绩的关系矩阵
从矩阵中可以看出,预习情况对期末成绩影响很小.其他属性操作类似.所有分析结束,可得出学号,计算机熟练情况,预习情况这3个属性对期末成绩基本无影响,应予以去除.
2.5.3 去除相对无关联字段,进行数据分区
使用过滤节点,过滤掉学号、计算机熟练情况、预习情况3个无关联字段.
此处用2014年和2015年的数据来作为训练分区数据,用来构建模型.
2.6 使用VA-C5.0建立决策树模型
我们使用VA-C5.0挖掘方法,对最终数据进行挖掘,得到生成树模型,进而生成出规则集.然后通过对生成的规则集进行分析研究,可以得出很多造成期末成绩优良,不及格的相关因素,以及他们之间的相互关系.列举部分得到的规则如下:
(1)IF考前复习时间=“多”AND实践课效果=“很好”AND考试心态=“很好”期末成绩优秀率100%.
(2)IF考前复习时间=“多”AND实践课效果=“很好”AND考试心态=“好”AND作业完成情况=“很好”AND课程兴趣=“浓厚”期末成绩优秀率98.36%.
(3)IF考前复习时间=“多”AND实践课效果=“很好”AND考试心态=“好”AND作业完成情况=“好”期末成绩优秀率95.78%.
(4)IF考前复习时间=“一般”或“从不”,期末成绩优良率为0;
(5)IF考前复习时间=“一般”AND作业完成情况=“差”,不及格率为98.86%.
3 与传统流程挖掘方法对比
3.1 传统流程构建决策树
我们把基于C5.0传统流程构建决策树的方法称之为C5.0方法.前期的分析及过滤字段操作取消,其他步骤及数据均相同.这样根据结果梳理下涉及到预习情况和计算机熟练情况的规则:
(1)IF考前复习时间=“一般”AND作业完成情况=“一般”AND课程兴趣=“一般”AND预习情况=“从不”期末成绩及格率100%.
(2)IF考前复习时间=“一般”AND作业完成情况=“一般”AND课程兴趣=“一般”AND预习情况=“一般”期末成绩及格率58.3%.
(3)IF考前复习时间=“多”AND实践课效果=“很好”AND考试心态=“好”AND计算机熟练情况=“不熟练or熟练or很熟练”期末成绩优良率都是100%.
通过规则可以看出,这两项对规则的合理性和高效性都产生了较负面的影响.

图3 VA-C5.0模型和C5.0模型预测结果对比图
3.2 两次不同方法的实验精度对比
依次通过两种挖掘方法产生的模型来预测2016年学生的成绩,然后再与真实成绩进行比对,比较两次挖掘的精度.1 118条挖掘数据中,基于VA-C5.0改进后的挖掘模型预测结果正确的有1 061条,错误的57条,预测精度94.9%.基于C5.0未改进挖掘模型预测正确的有1 016条,预测错误的102条,预测精度90.9%.接着我们随机选取200,400,600,800,1 000个样本,验证两种方法预测值的准确个数,得到的折线图如图3,从折线图我们可以看出,随着样本数的逐渐上升,基于VA-C5.0的模型预测精度与基于C5.0的模型预测精度之间的差距逐渐拉大.
3.3 模型构建时间效率对比
通过对模型构建所需时间的分析,基于C5.0的模型构建时长约为基于VA-C5.0的模型构建时长的2倍.由此可以看出,VA-C5.0模型建模时间比C5.0要快.如果数据量进一步加大,差距会更加明显.
4 结语
经过对比可以发现,改进的基于属性相关性分析的VA-C5.0挖掘方法,不论从模型构建的时间,以及模型预测的精确度上,都有一定的提高.同时,该方法可适用于高校很多课程,进而产生较大的实际效益.
[1] 袁小玲,李瑞.数据挖掘技术在高职院校学生成绩管理中的应用分析与探究[J].电子测试,2014(13):78-79.
[2] 柴宏涛,李建华,沈迪.基于ID3算法的信息资源分类管理映射模型研究[J].计算机工程与设计,2013,34(3):1082-1086.
[3] 张宇,张之明.一种基于C5.0决策树的客户流失预测模型研究[J].统计与信息论坛,2015(1):89-94.
[4] 康波,刘胜强.基于大数据分析的互联网业务用户体验管理[J].电信科学,2013,29(3):32-35.
[5] 谢红跃,方昱春,蔡起运.一种新的改进AdaBoost弱分类器训练算法[J].中国图象图形学报,2009,14(11):2411-2415.
[6] 李荣陆,胡运发.基于密度的kNN文本分类器训练样本裁剪方法[J].计算机研究与发展,2004,41(4):539-545.
[7] 徐安.基于威布尔分布的更新函数确定方法研究[J].山东交通学院学报,2006,14(3):16-19.
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25
小雪花·小学生快乐作文(2019年12期)2019-02-06
电子制作(2018年16期)2018-09-26
证券市场红周刊(2018年3期)2018-05-14
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
小说月刊(2015年6期)2015-04-23
郑州大学学报(医学版)(2015年1期)2015-02-27
航天返回与遥感(2014年5期)2014-07-31
