
基于kd-树的快速邻域分类方法
2018-02-15 05:49张艳芹杨习贝陈向坚
江苏科技大学学报(自然科学版) 2018年6期
张艳芹, 杨习贝, 陈向坚
(1.徐州工程学院 经济学院, 徐州 221018) (2.江苏科技大学 计算机学院, 镇江 212003)
粗糙集理论[1]经历了近40年的发展,因其不同种类的变型[2]易于适应各种结构复杂、种类繁多的数据分析需求,在众多领域得到了成功的应用.在各类粗糙集的扩展模型中,文献[3-5]中提出的邻域粗糙集方法尤其引人关注.这主要是因为邻域粗糙集方法采用距离度量来构建邻域信息粒,不仅可以有效处理连续型数据,还可以对符号型与连续型共存的混合数据进行分析[6-12].除此之外,更为重要的是邻域粗糙集利用半径来控制样本间的距离,以判定不同样本是否属于同一邻域信息粒,因此在不同半径下,自然地为邻域信息粒构建了一个多粒度结构.这种多粒度结构符合人类分层递阶的认知机理与自然思维模式.
以邻域粗糙集模型为基本框架,文献[3-4]中提出了一种基于多数投票原则的邻域分类方法(NC),其过程主要分为基于邻域粗糙集的特征选择和基于多数投票原则的邻域分类两大部分.NC无论是在特征选择阶段,还是在邻域分类阶段,最为关键的步骤是邻域信息粒化.例如利用较小半径所得到的邻域信息粒化在一些分类问题上往往能够展现较好的性能,但这并非绝对事实,当样本分布不平衡时,小半径反而会对小类样本的判定带来困扰.鉴于此,近年来有关邻域信息粒化方法的研究大多以提升邻域分类的准确率为目的,试图探寻一种数据自身性质驱动的邻域半径自适应方法;很少有人注意到良好的邻域搜索方式对提升NC效率的重要现实意义.众所周知,已有的邻域信息粒化方法通过线性扫描来寻找特定样本的邻域空间.当数据规模较为庞大时,线性扫描基于的邻域搜索方式将会因需要遍历所有样本而变得非常耗时.
kd-树作为一种对k维空间中的样本进行存储,以便对其进行快速搜索的树形数据结构,已被广泛应用于聚类分析[13]、图像匹配[14]、信息检索等领域.kd-树是对k维空间进行划分的二叉树,其每个结点对应于一个k维超矩形区域,利用kd-树可以省去对大部分样本的搜索,从而减少搜索的计算量.为此,文中将借助kd-树这一可被用于快速样本搜索的树形结构,提出一种基于kd-树的快速邻域分类方法kdtree-NC,该方法在特征选择与邻域分类两阶段的信息粒化过程中,均采用基于kd-树的快速邻域搜索方式,代替传统NC中的线性遍历搜索.
1 相关工作
1.1 邻域粗糙集
分类学习任务可表示为四元组
定义1[3]给定任意一样本xi∈U,B⊆C,特征集合B下xi的邻域δB(xi)可定义为:
δB(xi)={xj|xj∈U,ΔB(xi,xj)≤δ}
(1)
式中:δ为邻域半径;Δ为度量函数;∀xi,xj,xk∈U,特征集合B下样本间的度量函数ΔB满足:
(1) 非负性:ΔB(xi,xj)≥0, 其中ΔB(xi,xj)=0当且仅当xi=xj;
(2) 对称性:ΔB(xi,xj)=ΔB(xj,xi);
(3) 三角不等式:ΔB(xi,xj)≤ΔB(xi,xk)+ΔB(xk,xj).
目前,已有大量的度量函数被广泛使用[15].给定m维特征空间A={a1,a2,…,am}中的两个样本xi和xj,f(x,ai)表示样本x在第ai维上的特征值,那么曼哈顿距离、欧式距离以及高斯距离分别定义:
(2)
(3)
(4)
在定义1中,δB(xi)是由样本xi在特征集合B下诱导的邻域信息粒,其大小依赖于邻域半径δ的选取,δ越大,将有越多的样本落入到xi的邻域空间中.若特征集合B诱导了一系列的邻域信息粒,则决策系统可被称为邻域决策系统NDS.
定义2[3]给定一邻域决策系统NDS=

(5)
(6)

定义3给定一邻域决策系统NDS=
(7)
式中:|·|为集合的基数;∀πdi∈U/IND(D);πdi为一决策类.
邻域依赖度γ(B,D)度量了特征集合B诱导的粒化空间对决策D上各决策类的近似能力.在邻域决策系统中,邻域依赖度具有单调性,即若B1⊆B2,则γ(B1,D)≤γ(B2,D)成立,在此基础上,可以设计出邻域粗糙集下的特征选择方法.
定义4给定一邻域决策系统NDS=
(1)γ(B,D)=γ(C,D);
(2) ∀B′⊂B,γ(B′,D) ≠γ(B,D).
由定义4可知,条件特征C的约简是保持决策特征D的邻域依赖度不变的最小子集.在实际应用问题中,上述约简的限制条件过于严格,已有学者在对约简条件进行适当放宽的基础上,提出了ε-约简[15],即满足:
(1)γ(B,D)≥(1-ε)·γ(C,D);
(2) ∀B′⊂B,γ(B′,D) < (1-ε)·γ(C,D).
ε-约简旨在保持决策特征D的邻域依赖度变化在一个较小的范围内时,尽可能多地消除冗余或无关的特征,一般而言,ε在0~0.1之间取值.当ε=0时,ε-约简退化为定义4中的约简定义.
1.2 邻域粗糙特征选择
在分类学习任务中,特征选择是一种可以有效地消除冗余和无关特征的技术手段.邻域粗糙集框架下的特征选择旨在找出和原始条件特征集合具有相同刻画能力的最小特征子集[16].
定义5给定一邻域决策系统NDS=
Sigout(ai,B,D)=γB∪{ai},D-γ(B,D)
(8)
Sigout(ai,B,D)反映了特征ai加入特征集合B前后,决策特征D的邻域依赖度的变化程度.基于上述特征重要度的定义,贪心搜索策略可通过迭代,选出邻域决策系统中最重要的特征子集.
算法1:基于邻域粗糙集的特征选择算法
输入:邻域决策系统
输出:特征子集B.
步骤:
(1)B←∅;
(2)∀ai∈C,计算Sigout(ai,B,D),其中γ(∅,D)=0;
(3) 选择特征aj按照:Sigout(aj,B,D)=
max{Sigout(ai,B,D): ∀ai∈C};
(4) 当γ(B,D) < (1-ε)·γ(C,D)时:
(4.1)B←B∪{aj};
(4.2) ∀ai∈C-B,计算Sigout(ai,B,D);
(4.3) 选择特征aj按照:Sigout(aj,B,D)=max{Sigout(ai,B,D): ∀ai∈C-B};
(5)输出特征子集B.
算法1通过迭代,将能够最快速增加邻域依赖度的特征加入到已选特征集合中,直到所选特征下决策特征D的邻域依赖度为原始特征集合的100·(1-ε) %时算法停止.
1.3 邻域分类器
邻域分类器在未知样本的邻域空间内,采用多数投票原则,对未知样本的类别进行判断.邻域分类器在思想上与k近邻算法类似,其不同之处在于邻域分类器用邻域半径替代了近邻样本的个数,且可以有效地处理离散型和混合型数据.
算法2:邻域分类器
输入:训练集(特征选择后)
输出:预测的y的类别.
步骤:
(1) ∀xi∈U,计算距离ΔB(xi,y);
(2) 找出y的邻域δ2内的样本集Uδ2(y);
(3) ∀πdi∈U/IND(D),P(πdi,Uδ2(y))=|πdi∩Uδ2(y)|/|Uδ2(y)|;
(4) πdj=arg max{P(πdi,Uδ2(y)): ∀πdi∈U/IND(D)};
(5) 输出y的预测类别j.
2 分类学习方法
2.1 kd-树的构造与搜索
kd-树是把二叉搜索树推广到多维数据的一种主存数据结构.kd-树是一颗二叉树,可被视作对k维特征空间的一个划分.kd-树的构造相当于不断地采用垂直于坐标轴的超平面对k维特征空间切分的过程,从而形成一系列的k维超矩形区域.
kd-树一般按照如下方式构造:① 构造根结点,根结点对应于包含所有样本的k维特征空间的超矩形区域;② 通过递归,对k维特征空间切分,在超矩形区域上选择某一特定坐标轴和特定切分点,通过垂直于选定坐标轴且经过选定切分点的超平面,将当前超矩形区域划分为左右两个子区域(左子树和右子树),该超矩形区域上的所有样本被划分入左右子区域中.当左右子区域中没有样本时,递归过程终止.
为了使构造的kd-树平衡,通常将各个维特征依次作为选定的坐标轴,切分点采用所有样本在选定坐标轴上的中位数.
算法3:平衡kd-树的构造算法
输入:训练数据集U={x1,x2,…,xn},其中xi=[dim1(xi), dim2(xi),…, dimk(xi)].
输出:平衡kd-树.
步骤:
(1) 选择dim1为坐标轴,以U中所有样本的dim1坐标的中位数为切分点,将根结点对应的超矩形区域切分成左右两个子区域,即用根结点生成深度为1的左右子结点,其中左子结点对应坐标dim1小于切分点的子区域,右子结点对应坐标dim1大于切分点的子区域;
(2) 对于深度为j的结点,选择dimj(mod k)+1为切分的坐标轴,以该结点区域中所有样本的dimj(mod k)+1坐标的中位数为切分点,将该结点对应的超矩形区域切分成左右两个子区域,即用该结点生成深度为j+1的左右子结点,其中左子结点对应坐标dimj(mod k)+1小于切分点的子区域,右子结点对应坐标dimj(mod k)+1大于切分点的子区域;
(3) 返回步骤(2),直到左右两个子区域没有样本;
(4) 输出平衡kd-树.
采用kd-树进行邻域搜索,可以省去对大部分样本点的查找,从而减少搜索的计算量.算法4给出了kd-树下邻域搜索的具体方法.
算法4:kd-树下的邻域搜索算法
输入:已构造的kd-树,目标样本x,邻域半径δ.
输出:x的邻域样本.
步骤:
(1) 从kd-树的根结点出发,通过递归,向下访问kd-树,如果目标样本x当前维度的坐标小于切分点坐标,那么移动到左子结点,否则移动到右子结点,最终到达的叶结点即为包含x的叶节点,如果该叶结点上的样本到x的距离≤δ,则将该样本加入到x的邻域样本中;
(2)通过递归,向上退回,在每个结点进行操作:
(2.1) 如果该结点上的样本到x的距离≤δ,则将该样本加入到x的邻域样本中;
(2.2) 目标x的邻域样本一定存在于该结点一个子结点对应的区域.检查该子结点的父结点的另一个子结点对应区域的样本.检查另一个子结点对应的区域是否与以目标x为球心,以δ为半径的超球体相交.如果相交,可能在另一个子结点对应的区域中存在与x的距离≤δ的点,移动到另一个子结点,通过递归进行邻域搜索;否则,向上退回.
(3) 当退回到根结点时,搜索结束;
(4) 输出x的邻域样本.
2.2 kd-树下快速邻域分类方法
文中提出的基于kd-树的快速邻域分类方法kdtree-NC仍采用特征选择和邻域分类两个阶段,与传统的邻域分类方法NC不同的是,kdtree-NC在邻域信息粒化的过程中,借助可用以实施快速邻域搜索的kd-树这一树形数据结构,代替了NC方法中基于线性扫描的邻域搜索方式,在很大程度上减少了需要查找的样本点,从而降低了邻域信息粒化中的搜索计算量.
在算法1中,步骤(2)和步骤(4.2)都通过循环体迭代,寻找能够最快速增加邻域依赖度的特征,而邻域依赖度刻画了当前特征集合所诱导的粒化空间对各决策类的近似逼近能力,因此,算法1的时间开销主要集中在大量的邻域信息粒化上.在NC方法中,线性遍历的邻域搜索方式的时间复杂度为O(n),而采用kd-树方式进行邻域搜索的平均时间复杂度为O(logn),一般而言,当样本数量远大于特征空间的维度时,kd-树方式进行的邻域搜索较线性遍历方式更为高效.同样,在邻域分类器算法(算法2)的步骤1中,也将先采用算法3来构造一棵左右平衡的kd-树,再借助基于kd-树的邻域搜索算法(算法4)以提高邻域决策的时间效率.
3 性能分析
为了验证基于kd-树的邻域分类方法的有效性,文中选取了18组UCI数据集进行实验分析,数据集的基本信息如表1.文中实验选用配备2.7GHz处理器、4GB内存的PC机,编程环境为Matlab 2016b.实验分为两个部分:① 对NC和kdtree-NC特征选择阶段的时间消耗进行对比;② 分别比较了特征选择前后分类的准确率和特征选择后NC和kdtree-NC方法的分类的时间消耗.

表1 数据集基本信息
图1、2分别展示了邻域半径为0.05和0.10时,NC与kdtree-NC中特征选择的时间消耗,其中黑柱代表NC的时间,白柱代表kdtree-NC的时间.由图1、2不难发现,在绝大多数数据集上,kdtree-NC中特征选择的时间消耗要明显小于NC,仅在Connectionist Bench和Glass Identification数据集上,kdtree-NC特征选择所耗费的时间要略高于NC,其原因在于这两个数据集中的样本数与特征数不满足kd-树快速搜索策略中样本数应远大于特征数这一先决条件.

图1 NC与kdtree_NC特征选择的时间对比(特征选择邻域半径为0.05)Fig.1 Comparision of elapsed time between NC andkdtree_NC based teature selection(neighbor radius is 0.05)
由表1和图1、2可知,随着数据集中样本数与特征数之比的增大,NC与kdtree-NC中特征选择的时间消耗差距也愈发显著.

图2 NC与kdtree_NC特征选择的时间对比(特征选择邻域半径为0.10)Fig.2 Comparision of elapsed time between NC andkdtree_NC based teature selection(neighbor radius is 0.10)
图3、4分别为特征选择邻域半径为0.05和0.10时,对NC与kdtree-NC的分类性能进行对比.在邻域分类阶段,在30个邻域半径(0.01~0.30,间隔为0.01)下,文中比较了NC与kdtree-NC的分类时间消耗.在每个邻域半径点,实验采用了10折交叉验证的方式,分类过程重复10次并记录整个10次分类的总时间.交叉验证中共有10组测试样本集,为此,kdtree-NC方法在分类过程中共需根据对应的10组训练样本集来构建10棵kd-树用于邻域搜索.由图3、4不难发现,在绝大多数数据集的各个邻域半径点上,kdtree-NC的分类时间要远远小于NC的分类时间,这验证了文中提出的kdtree-NC,通过采用kd-树型快速邻域搜索策略,确实能够较大程度地缩小邻域搜索范围,从而有效地提升邻域分类的时间效率.
对kdtree-NC在邻域特征选择前后的分类精度进行了对比,由图3、4可见,在大部分数据集上,特征选择后的邻域分类精度要高于特征选择前,这说明算法1可以有效删除原始特征空间中的冗余信息,进而提高邻域分类准确度.






图3 NC与kdtree_NC分类性能的对比(特征选择邻域半径为0.05)Fig.3 Comparision of classification performances between NC and kdtree_NC(neigbbor radius is 0.05)



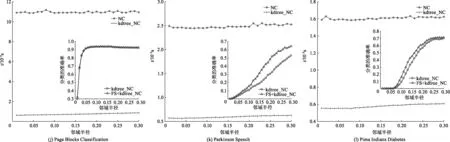


图4 NC与kdtree_NC分类性能的对比(特征选择邻域半径为0.10)Fig.4 Comparision of classification performances between NC and kdtree_NC(neigbbor radius is 0.10)
4 结论
(1) 文中通过kd-树型邻域搜索策略,提出了一种基于kd-树的快速邻域分类方法kdtree-NC,该方法在邻域信息粒化过程中采用了kd-树搜索策略代替了传统邻域分类方法中的线性遍历搜索,有效地降低了邻域搜索的时间开销.
(2) 在18组UCI数据集上的实验结果表明,与传统的邻域分类方法相比,kdtree-NC在特征选择和邻域分类阶段的时间效率都有显著提升.
(3) 在下一步的研究工作中,笔者计划将ball-树搜索结构引入到邻域分类方法中,以解决kdtree-NC在处理高维特征数据时效率急剧降低的不足.
猜你喜欢
农业工程学报(2022年7期)2022-07-09
电子制作(2022年1期)2022-01-28
电子制作(2021年14期)2021-08-21
自动化学报(2018年7期)2018-08-20
自动化学报(2017年4期)2017-06-15
自动化学报(2017年5期)2017-05-14
电子制作(2017年23期)2017-02-02
智能系统学报(2015年4期)2015-12-27
振动工程学报(2014年4期)2014-03-01
现代电子技术(2009年14期)2009-09-05
