
结合码本优化和特征融合的人体行为识别方法
2018-03-05 02:09石爱辉曹雪虹
计算机技术与发展 2018年2期
石爱辉,程 勇,曹雪虹,
(1.南京邮电大学 通信与信息工程学院,江苏 南京 210003;2.南京工程学院 通信工程学院,江苏 南京 211167)
0 引 言
人体行为识别研究在智能监控、人机交互等领域具有广阔的应用前景,因而受到越来越多的研究者关注。在实际应用中,由于视频中人体行为动作的多变性、复杂的背景以及摄像机的视角变化等因素,人体行为识别仍是计算机视觉领域的难点和热点问题[1-2]。
近些年涌现了大量的人体行为识别算法,例如基于模板匹配的方法,其主要思路是将不同种类行为视频序列提取的特征数据建立相应的模板,识别时将待测视频提取的特征数据与模板进行比较匹配。这种方法虽然计算量小,实现相对简单,但需要存储各种动作视频的特征数据作为模板,存储代价较大[3]。基于光流的方法,主要利用光流这种基于视频中帧与帧之间变化的运动信息。文献[4]提出在基于视频的人体行为识别过程中,可以将视频序列中的光流信息转化为更能明显区分不同动作差异的运动特征,利用不同层面的运动特征参数表示视频序列中的光流信息。基于兴趣点的方法是利用histogram of oriented gradient (HOG)[5]和histograms optical flow (HOF)[5]等描述子对视频中检测到的时空兴趣点局部区域进行描述。由于时空兴趣点是对视频中运动显著区域的描述,包含了丰富的动作细节信息,因此具有较好的抗噪声性能。
文献[6]提出基于密集轨迹的人体行为识别方法,即通过跟踪光流场密集采样的特征点来获得轨迹,并计算轨迹位移向量及其轨迹中子时空块的梯度方向直方图(HOG)、光流直方图(HOF)和运动边界直方图(MBH)[7]作为视频序列的底层局部特征描述子,然后将这些局部特征描述子作为视觉词袋模型(BoVW)[8]的输入获得视频序列的全局表达,最后将这种视频全局表达作为支持向量机的输入进行分类识别,取得了较好的识别效果。
在目前的行为识别算法中,基于视觉词袋模型的方法是研究热点之一。在传统的视觉词袋模型中,对所有视频的一部分局部特征描述子进行一次k-means聚类而形成的码本,其视觉词汇并不具有很好的代表性。而有效的字典学习是视觉词袋模型的关键步骤,文中提出对视频中提取的局部特征描述子根据取自不同视频和不同种类动作进行两层k-means聚类,形成更有代表性和区分度的码本。特征融合是一种使得特征描述鲁棒性更强的有效方法,对于视频中提取的两种局部特征描述子HOG和HOF,在分别形成全局视频表达后进行融合,融合后的全局视频表达特征更具有区分性和鲁棒性。
1 文中算法
1.1 算法框架
文中算法框架如图1所示。首先对视频中的时空兴趣点进行检测,然后利用HOG和HOF作为局部特征描述子对兴趣点进行描述,接着将HOG和HOF描述子分别作为词袋模型的输入,得到两种不同的视频级全局表达,将这两种视频级全局表达进行融合作为最终的视频级表达特征,最后将其代入到支持向量机中对行为动作进行分类。
1.2 局部特征描述子
在人体行为识别的课题研究中,由于进行实验仿真所使用到的数据库中的视频相对简单和稳定,因而不需要对其中的人体进行跟踪和检测,所以对视频提取局部特征是一种常见的方法。
对于视频中的时空兴趣点,一种具有鲁棒性好、适应性强的时空特征被广泛使用,其通过Harris角点检测[9]扩展到包括时间维的三维空间即Harris-3D获得。Harris角点检测的基本原理是选择不同尺度的局部空间,计算其中每个像素二阶矩阵的特征值,对于某个像素点的特征值为局部最大值时被视为角点。对于包括时间维的三维空间,其中的尺度空间包括空间尺度和时间尺度,对于被认为是时空兴趣点的像素点在空间域和时间域会同时有显著的变化,因此在时空域上表示一个图像序列V(·),利用其与高斯核函数作卷积获得其尺度空间表示:

(1)
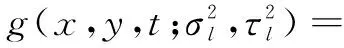
(2)
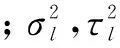
参照Harris角点检测的像素二阶矩阵,在时空尺度空间的二阶矩阵可表示为:
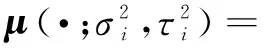
(3)

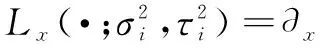
(4)
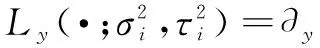
(5)
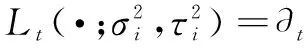
(6)
假设λ1,λ2,λ3为μ矩阵的特征值,则时空兴趣点由推广的Harris响应函数的局部最大值处定义:
H=det(μ)-ktrace3(μ)=λ1λ2λ3-
k(λ1+λ2+λ3)3
(7)
视频中兴趣点可以根据参数进行多尺度提取,检测到兴趣点后,为了在兴趣点处提取HOG/HOF特征,文献[10]在特征点处抽取大小为(2kσi;2kσi;2kτ)的局部视频块(k=9),然后将其分成空时为3*3*2的网格。对于每个网格,将梯度方向量化为4,光流方向量化为5(其中包含一个静止方向),从而一个时空兴趣点可以通过72维的HOG和90维的HOF来加以描述。
1.3 码本优化
传统的BoVW中利用全局描述子对视频进行描述,主要分成三个步骤:首先利用k-means聚类算法对视频中获取的局部特征描述子进行聚类形成字典,然后根据底层特征描述子和字典形成频率直方图对视频进行描述,最后对直方图进行归一化处理后作为视频的中层表达。在视觉词袋模型中对视频提取的特征描述子进行聚类形成字典时,文中提出对视频中提取的特征描述子进行两层聚类优化码本,提高码本的表达能力。其中两层k-means聚类的过程如图2所示,首先对训练集中的每一个视频提取的HOG和HOF特征描述子分别进行k-means聚类,聚类数目为视频中,兴趣点数目的25%,然后对同种行为动作的视频的聚类结果再进行k-means聚类,聚类数目大小为K,最后将所有动作种类的聚类结果作为视觉词汇连接成码本,这样的码本更有代表性和区分度。除此之外,两层k-means聚类还能够降低对实验仿真内存的要求并减少聚类所花的时间。其中K的大小可以根据仿真实验的效果在一个范围内进行选择。
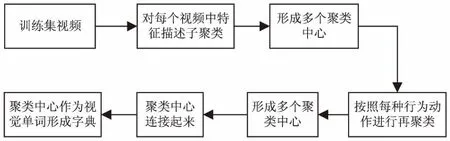
图2 对每个视频以及每种动作进行聚类的流程
图3是分别使用传统聚类方法形成的码本和优化码本在KTH数据库中鼓掌和挥手动作的直方图表示。利用以上构建的字典,视觉单词的位置与相应的行为动作之间有了对应关系,从而改变了直方图的分布情况。与传统词袋模型中使用的码本相比,在一定程度上提高了同种动作视频的视觉单词直方图分布的相似程度,而使得不同动作类别的视觉直方图分布的差异明显。
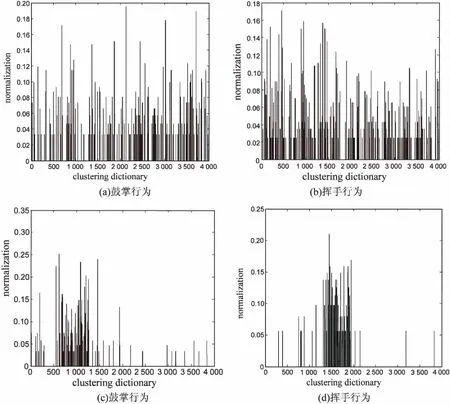
图3 两种不同行为直方图的表示
1.4 视频表达级特征融合
HOG特征描述子包含了视频图像中的表观形状信息,而HOF特征描述子包含了视频图像中的运动信息。但文献[11]的实验结果表明,仅仅使用HOF特征描述子比使用HOF和HOG特征描述子在描述子级融合的效果好,对于描述子级融合是将描述视频中局部特征的多个描述子串联在一起形成单个的描述子,然后将其送入到BoVW框架中获取全局视频表达。针对这种情况,文中将HOF和HOG描述子在视频表达级层面进行融合,其过程如图4所示。视频表达级的融合是将描述视频中局部特征的HOF和HOG描述子分别送入BoVW框架中获取到两种不同的视频全局表达,然后对这两种视频全局表达进行融合作为最终的视频表达级特征。对于HOG和HOF这两种不同的特征描述子,在形成视频表达级描述子相关性较大时,视频表达级层面上的特征融合比在局部特征描述子级层面上的直接融合效果要好。
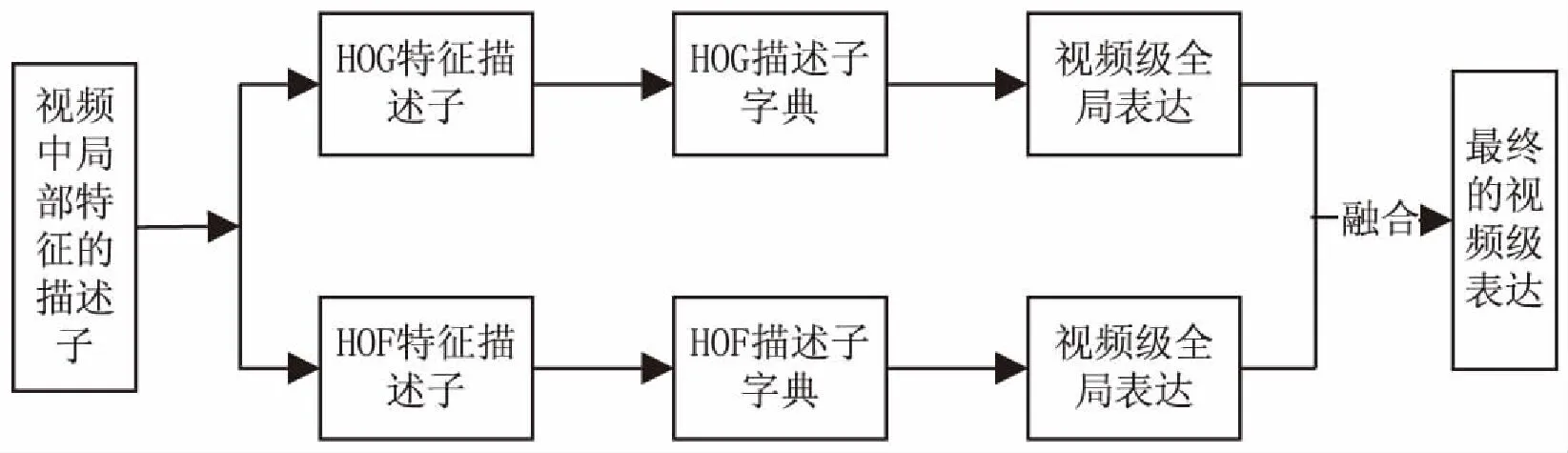
图4 视频级表达特征融合方法
1.5 支持向量机分类器
使用支持向量机(SVM)分类器进行分类识别。SVM的主要思想:在空间H中,如果要将训练数据集(x1,y1),(x2,y2),…,(xm,ym)分成两类yi∈{-1,+1},对于所有能将数据集分成两类的超平面wx+b=0,选择一个最优决策超平面使得该平面两侧距离该平面最近的两类样本之间的距离最大化,其中w和b的值可以通过Lagrange乘数αi求解约束条件下的极小值问题求得[12]。
(8)
其中,对应非零αi的xi向量称为支持向量。引入核函数K(x,y)巧妙地解决了在高维空间中的内积运算,较好地解决了非线性分类问题。文中使用的是线性核函数。
2 实验仿真分析
2.1 数据集
为了验证文中算法的有效性,选择两个比较经典的数据集(KTH和Weizmann)进行仿真实验。
KTH数据集包括6类行为动作(walking、jogging、running、boxing、hand waving、hand clapping),是由25个不同的人在4种不同场景下(室内、室外、尺度变化和衣着变化)采集完成。所有视频背景相对静止,摄像机的运动比较轻微,视频的帧率为25帧/s,分辨率为160x120,整个数据集包含了599个视频文件。将其中16人的所有动作视频作为训练集,其余9人的所有动作视频作为测试集。最后的识别率是由测试集中所有被正确识别出的视频个数计算得到。
Weizmann数据集包括10种不同类型的行为视频(bend、jump、jack、pjump、run、side、skip、walk、wave1、wave2),每种动作由9个不同的人所展示,采用的方法是将其中1人的所有动作视频作为测试集,其他人的所有动作视频作为训练集,循环9次,最后将平均正确率作为识别率。
2.2 实验结果
图5分别是使用一次k-means方法和使用两次k-means方法对局部特征描述子进行聚类,构建不同数量的视觉词汇在KTH和Weizmann数据集上的识别率对比曲线。可以看出,在不同数量的视觉词汇下,使用优化后的码本的识别率明显高于使用传统聚类方法形成的码本的识别率。Weizmann数据集中的视频序列的长度较短,视频中提取的时空兴趣点的数目也较少,在构建码本时视觉词汇的数量也相应减少,导致在Weizmann数据集上的识别率明显低于KTH数据集上的识别率。
同时,识别率总体上是随着码本大小增加而不断提高,当码本到达一定的数目后识别率基本保持不变。而当字典过大时,一些视频中的时空兴趣点较少对应到码本上,词汇减少不能有效地描述视频。相较于使用传统的聚类方法形成的码本,码本优化后在KTH和Weizmann数据集上的识别率提升了3%左右,证明了文中方法的有效性。
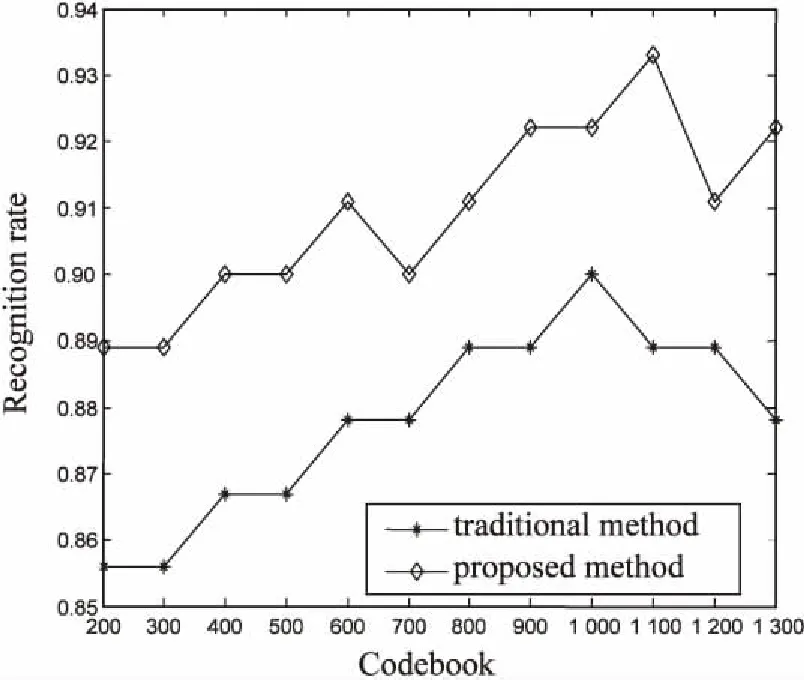
(a)使用一次k-means方法
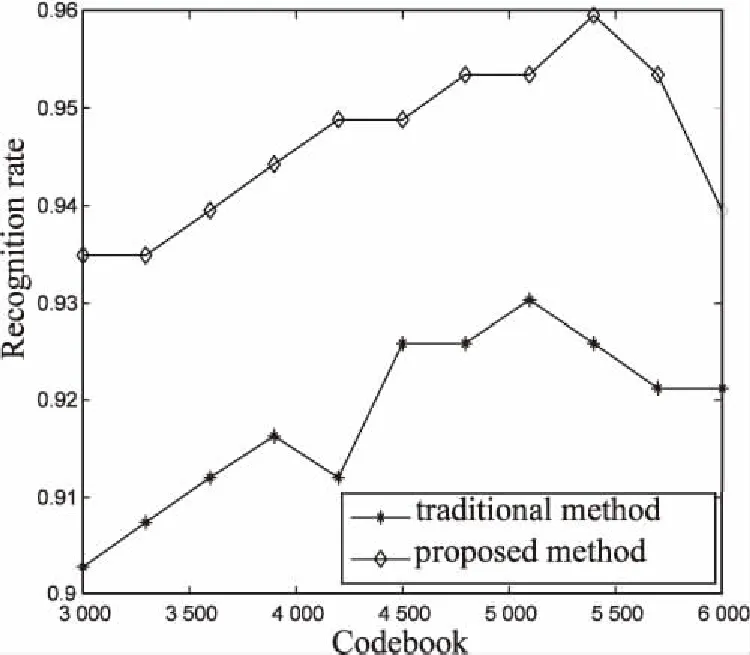
(b)使用两次k-means方法
使用单个HOF特征描述子以及优化后的码本形成的频率直方图作为视频表达级描述子在KTH和Weizmann数据集上的识别率,分别为95.8%和93.3%。而使用HOG和HOF特征描述子以及各自优化后的码本形成的两种频率直方图融合作为最终的视频表达级描述子在Weizmann与KTH数据集上仿真实验效果最好时的识别率,分别为96.7%和94.4%。从实验结果可以看出,结合码本优化和视频表达级特征融合的方法与传统方法相比,在KTH与Weizmann数据集上的识别率均有不同程度的提升,表明了该方法的有效性。
表1列出了文中方法与近年来人体行为识别研究课题在KTH和Weizmann数据集上识别率的比较。与其他方法相比,文中方法在这两个数据库上均取得了较高的识别率。
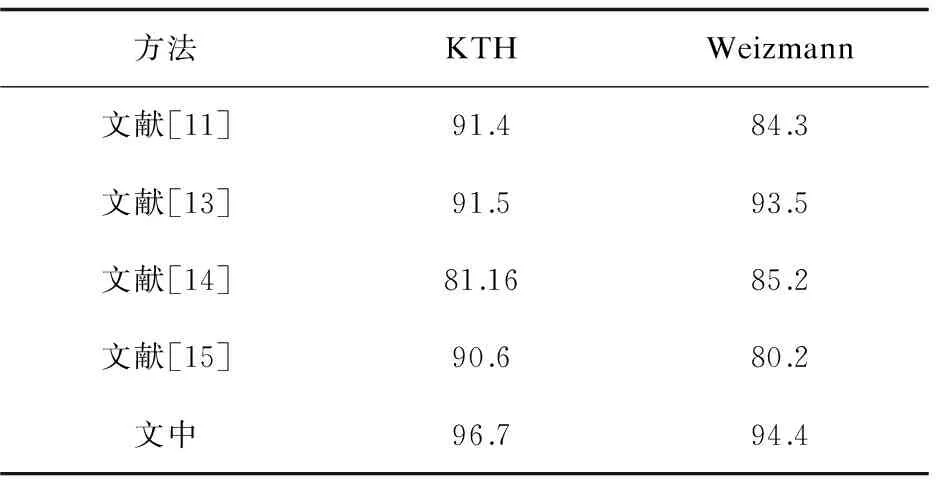
表1 各算法平均识别率对比 %
3 结束语
为了提高视觉词袋模型应用在人体行为识别研究课题的识别率,引入了一种结合多层k-means聚类与视频级表达特征融合的行为识别算法,降低了对内存的要求并减少了聚类所用的时间,可以更有效地描述视频。仿真结果表明,该方法在两个经典数据集上的识别率高于大多数算法。针对如何提高易混淆动作的识别率以及选用其他编码方法替代VQ编码将是下一步的研究工作。
[1] 王 博,李 燕.视频序列中的时空兴趣点检测及其自适应分析[J].计算机技术与发展,2014,24(4):49-52.
[2] 刘雨娇,范 勇,高 琳,等.基于时空深度特征的人体行为识别算法[J].计算机工程,2015,41(5):259-263.
[3] 李瑞峰,王亮亮,王 珂.人体动作行为识别研究综述[J].模式识别与人工智能,2014,27(1):35-48.
[4] ALI S,SHAH M.Human action recognition in videos using kinematic features and multiple instance learning[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2010,32(2):288-303.
[5] WANG H,YI Y.Tracking salient key points for human action recognition[C]//IEEE international conference on systems,man,and cybernetics.[s.l.]:IEEE,2015:3048-3053.
[6] WANG Heng,KLASER A,SCHMID C,et al.Action recognition by dense trajectories[C]//Proceedings of IEEE international conference on computer vision and pattern recognition.Washington D C,USA:IEEE Press,2011:3169-3176.
[7] LI Q,CHENG H,ZHOU Y,et al.Human action recognition using improved salient dense trajectories[J].Computational Intelligence & Neuroscience,2016,2016:6750459.
[8] FARAKI M,PALHANG M,SANDERSON C.Log-Euclidean bag of words for human action recognition[J].IET Computer Vision,2015,9(3):331-339.
[9] HARRIS C,STEPHENS M.A combined corner and edge detector[C]//Proceedings of alvey vision conference.[s.l.]:[s.n.],1988:147-151.
[10] LAPTEV I,MARSZALEK M,SCHMID C,et al.Learning realistic human actions from movies[C]//IEEE computer society conference on computer vision and pattern recognition.[s.l.]:IEEE,2008:1-8.
[11] KLASER A,MARSZALEK M,SCHMID C.A spatio-temporal descriptor based on 3D-gradients[C]//British machine vision conference.[s.l.]:[s.n.],2008:995-1004.
[12] 边肇祺,张学工.模式识别[M].第2版.北京:清华大学出版社,2000:296-303.
[13] LU M,ZHANG L.Action recognition by fusing spatial-temporal appearance and the local distribution of interest points[C]//International conference on future computer and communication engineering.[s.l.]:[s.n.],2014:75-78.
[14] DOLLAR P,RABAUD V,COTTRELL G,et al.Behavior recognition via sparse spatio-temporal features[C]//IEEE international workshop on visual surveillance & performance evaluation of tracking & surveillance.[s.l.]:IEEE,2005:65-72.
[15] TU H B,XIA L M,WANG Z W.The complex action recognition via the correlated topic model[J].Scientific World Journal,2014,2014:810185.
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
湘潭大学自然科学学报(2022年2期)2022-07-28
安徽电子信息职业技术学院学报(2020年5期)2020-11-13
摄影之友(影像视觉)(2018年12期)2019-01-28
赢未来(2018年4期)2018-09-27
科技视界(2018年32期)2018-02-21
课程教育研究·新教师教学(2017年6期)2017-10-17
中国高新技术企业(2017年5期)2017-05-05
初中生世界·八年级(2017年3期)2017-03-24
软件(2016年6期)2017-02-06
