
基于MDL的汉语语义选择限制自动获取
2018-03-07 09:22贾玉祥李育光昝红英
郑州大学学报(理学版) 2018年1期
贾玉祥, 李育光, 昝红英
(郑州大学 信息工程学院 河南 郑州 450001)
0 引言
谓语动词对其论元有选择倾向性,称为语义选择限制(selectional preference,SP).比如,“吃”这个动词的主语倾向于选择表示“人或动物”的名词,宾语倾向于选择表示“食物”的名词.可以用函数spr(v,n)表示语义选择倾向,其中:v表示谓语动词;r表示论元类型;n表示名词;sp值为实数,值越大,表示n越适合充当v的论元r.比如,“苹果”比“石头”更适合充当“吃”的“宾语”.语义选择限制知识获取就是学习函数spr(v,n),对任意三元组(v,r,n)进行打分.
语义选择限制是重要的词汇语义知识,除了可以用来判断句子的合法性之外,还具有数据平滑和消歧作用,因此被用于自然语言处理的很多任务,包括句法分析[1]、语义角色标注[2]、词义消歧[3]、机器翻译[4]、隐喻计算[5]等.语义选择限制是很多词汇知识库的重要组成部分,比如英语的VerbNet[6]、汉语的HowNet[7]、现代汉语语义词典[8]等.然而,手工构建的语义选择限制知识库已很难满足自然语言处理的需求,需要从大规模语料中自动获取语义选择限制知识.
语义选择限制获取方法分为两大类:基于语义分类体系的方法与基于分布的方法[14].基于语义分类体系的方法借助语义分类体系(如WordNet),计算谓语对论元语义类的sp值,那么对于未知论元名词,只要它出现在某一个语义类中,就可以赋给它该语义类的sp值.对于语义类sp值的计算,文献[9]使用一个基于KL距离的统计指标,文献[10]基于最小描述长度(minimum description length, MDL)模型,文献[11]则采用基于假设检验的方法,这类方法的优点是可以学习出关于语义类的选择限制知识,易于人类理解,便于集成到词汇知识库中,主要面向语言学研究和词汇知识库构建.基于分布的方法的介绍可参看文献[14].
汉语语义选择限制知识自动获取方面,文献[12-13]利用中文概念词典CCD[15]、HowNet的语义分类体系实现了基于KL距离的汉语语义选择限制的自动获取.文献[13-14]实现了基于LDA和神经网络的方法,则是对基于分布的方法的探索.本文面向词汇知识库建设,利用HowNet的语义分类体系,实现了基于最小描述长度原则的汉语语义选择限制自动获取方法,并与基于KL距离的方法进行了对比.
1 基于MDL的SP获取方法
基于语义分类体系的语义选择限制自动获取的任务是,给定(v,r,n)实例,计算哪些语义类C适合做谓词v的论元r,适合程度是多少,即spr(v,C).因此,SP获取模型包括语义类C的确定及sp值的确定两个方面.本文使用基于语义分类体系和最小描述长度原则的树划分模型进行汉语SP知识的获取.

图1 HowNet(2000版)名词语义分类体系(树)示例Fig.1 An illustrating diagram of the noun semantic taxonymy of HowNet(2000)
1.1 名词语义分类体系(树)的构造
把名词按照语义进行分类,语义类别具有层次结构,形成一棵语义分类树,称为语义分类体系.树中的父节点与子节点是上下位的关系,即父节点是所有子节点的概括,子节点是父节点的细分,所有的名词被划分到相应的节点中.英语常见的语义分类体系有WordNet,汉语常见的语义分类体系有HowNet、现代汉语语义词典、中文概念词典CCD等.图1是HowNet(本文使用的是2000版)的名词语义分类体系的示例,树的根节点是“entity实体”,向下逐层的细分,一共142个节点,其中带“*”号的是叶子节点,其他是非叶子节点.根据名词概念定义中的第一义原,将27 267个名词划分到该语义分类体系中.
一个完美的语义分类体系应该能够让所有的名词都只能被划分到叶子节点,而非叶子节点自身不含有词,其所包含的词由其孩子节点所包含词的并集构成.然而现有的语义分类体系基本都不满足这个条件.比如,在HowNet中,非叶子节点“entity实体”包含有“定心丸”(DEF=entity实体,*AtEase安心)等54个词语.我们对现有语义分类体系进行改造,为所有包含词语的非叶子节点增加一个孩子节点,该孩子节点为叶子节点,把非叶子节点包含的词语下放到孩子节点中,非叶子节点不再包含词语,这样就使得所有词语都被划分到叶子节点.比如,为非叶子节点“entity实体”引入一个作为叶子节点的孩子“entity实体_G”,“定心丸”的定义则改为“DEF=entity实体_G,*AtEase安心”.在HowNet名词语义分类体系142个节点中,有36个非叶子节点,106个叶子节点.对语义分类体系的改造,一共增加叶子节点36个,把非叶子节点中的一共 7 928个词放到了叶子节点上.改造后的语义分类体系一共178个节点,其中非叶子节点36个,叶子节点142个.
HowNet的义原可以进行组合,以形成更细致的语义类别.比如,组合义原“human人,male男”和“human人,female女”代表的语义类,可以作为语义类“human人”的下位概念.HowNet中词语所代表的概念恰是由义原组合来定义的,这样就可以把相关词语划分到新组合的语义类,比如“男子”(DEF=human人,male男)和“妇女”(DEF=human人,female女)分别划分到语义类“human人,male男”和“human人,female女”.根据语义选择限制知识获取的需要,我们暂时只使用178个节点的语义分类体系,而不考虑对语义分类体系的进一步扩展.这样的语义类规模易于人们把握,便于后续知识库的构建.语义分类体系给出了语义类的来源,建立了词语与语义类之间的桥梁,是SP获取模型的数据基础.
1.2 树划分模型
树的划分Γ是树中节点的集合,Γ=[C1,C2,…,Ck],是包含k个节点的划分,这些节点所包含词语的交集为空,并集是语义分类体系中的所有名词.其中有两个特殊的划分,即只有根节点一个元素的划分和所有叶子节点构成的划分.

图2 树划分示例Fig.2 An example of tree cut
假设整棵树如图1所示,则该树一共有图2所示的5个划分:

1.3 基于MDL原则的模型选择
一个语义分类体系有多少个划分,就对应着多少个模型,到底要选择哪一个模型,我们采用最小描述长度原则[16]来选择.最小描述长度原则与奥卡姆剃刀原则类似,认为最简单的模型是最好的.根据该原则,描述长度最小的模型即是最优的模型,对应的语义类及其概率即是要获取的SP知识.

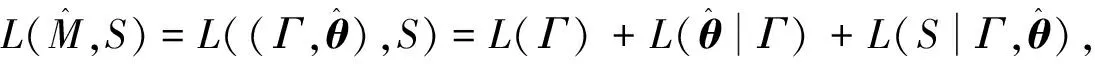
(1)
其中:L(Γ)是模型描述长度,L(Γ)=log2|G|,G是语义分类体系中所有划分的集合.

其中:|S|表示样本集大小;k-1表示模型中的自由参数的数量,等于划分中的节点数k减1.


由于对所有的划分来说,模型描述长度L(Γ)是固定值,不影响描述长度大小的判定,可以不予考虑.因此,总描述长度可以用参数描述长度和数据描述长度之和来表示

(2)
参数描述长度与划分中的节点个数成正比.划分中的节点越靠近根节点,节点数越少,参数描述长度越小.数据描述长度表示模型对样本数据的拟合程度,拟合的越好,数据描述长度越小,反之,越大.节点越靠近叶子,对数据拟合的越好,数据描述长度就越小.因此,参数描述长度倾向于选择靠近根的节点,而数据描述长度倾向于选择靠近叶子的节点.越靠近根节点越抽象,区分度变小,越靠近叶子节点,越具体,概括性不够.两种描述长度的结合是抽象与具体的折中,期望找到一个合适的抽象层次.根据最小描述长度原则,总描述长度最小的划分就是要找的抽象层次.
1.4 模型的实现
给定样本集S,语义分类树的每一个划分对应着一个模型.由于树的划分数量非常多,求出每一个划分的描述长度,然后再选择描述长度最小的那个划分,计算复杂度太高.可以证明,一个深度为d的完全b叉树,其划分个数的量级为O((2b)d-1).我们使用文献[10]提出的一个基于动态规划的高效算法,该算法的时间复杂度是O(N×S),N为树的叶子节点个数,|S|是样本个数.算法的关键是比较父节点与所有子节点的拼接的描述长度,如果父节点的描述长度小,则选择父节点,否则,选择其所有子节点.这是一个递归算法,输入语义分类体系的根节点,就可以得到一个描述长度最小的划分.
使用词语的频率计算语义类的频率f(C)时存在歧义的问题,我们没有进行词义的消歧,而是把词语的频率平均分配到不同的叶子节点语义类中(因为词语只出现在叶子节点),而非叶子节点的频率由其子节点频率之和得到.
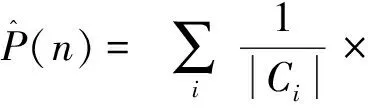
2 实验与分析
选择动宾关系来对语义选择限制知识获取进行评价,评价采用两种方法,一是从个例的角度考察获取的优选语义类情况,二是考察获取的知识在伪消歧任务中的效果,并与文献[13]中基于KL距离的方法进行对比.训练语料为人民日报1995年、1997—2005年共10年的语料[14].
2.1 优选语义类
每一个动词的训练语料(样本集)是单独的,即该动词的动宾搭配实例集,与其他动词的训练语料无关,这样一个动词的选择限制知识的获取不受其他动词的影响.我们可以为每一个动词选择最佳的语义类划分并计算其概率分布.表1是动词“吃”的宾语语义类分布情况,按照概率从大到小降序排列,省略了概率小于0.025的语义类.可见,自动获取的语义类分布与人的认知是基本一致的.排在前两位的语义类“food食品”,“fact事情_G”都是说到“吃”时最容易想到的宾语类别,是“吃”的本义对应的语义类.当然,“吃”是一个多义词,也有一些语义类会对应于“吃”的其他的义项.从表中我们也能看到一些自动知识获取存在的问题.
1) 多义词的问题.比如:“饭”既属于“food食品”也属于“fact事情_G”,“药”既属于“medicine药物”也属于“chemical化学物”,我们没有做词义消歧,而是简单地把词频平均分配到所属的各个语义类,这会带来一定的误差,比如“chemical化学物”也得到了较高的概率.
2) 语义分类体系的使用问题.HowNet中很多词语的定义里都有“part部件”这个义原,比如“肉”(DEF=part部件,%AnimalHuman动物,flesh肉;DEF=part部件,%fruit水果,flesh肉,$eat吃)、“问题”(DEF=part部件,%entity实体,heart心)、“米”(DEF=part部件,%plant植物,embryo胚)等,直接把这些词归到第一义原“part部件”,就造成了“component部分”这个语义类得到了较大的概率,其实把这些词归到第二义原或其他义原对应的语义类更加合理.另一个语义类是“character文字”,即汉字,由于很多单字词都属于这个语义类,如水、山、鱼、米,这样就会使得“character文字”这个语义类得到较高的概率,而此时这个语义类是没有意义的,应该舍弃.第三种情况提示对语义类进行细化可能会更好.比如“material材料”这个语义类,含有词语“粮”(DEF=material材料,?edible食物,#crop庄稼,generic统称)、“米”(DEF=material材料,?food食品,#crop庄稼)、“盐”(material材料,?edible食物,salty咸),如果对“material材料”进行细化,比如考虑第二义原,形成“material材料, edible食物”(食材)这样的下位概念,可能表达会更准确.
3) 文本自动分析存在问题.语义类“human人”作为吃的宾语显然不太合理,这里可能是自动句法分析的问题导致动宾搭配抽取错误.尽管我们看到表中搭配的抽取存在错误(可能来自分词或句法分析),但是自动获取的语义选择限制知识总体上是合理的,反过来还可以过滤不合理搭配,改进句法分析.

表1 动词“吃”的宾语优选语义类分布
2.2 伪消歧
语义选择限制获取模型对动宾搭配打分,合理的搭配得分要高于不合理的搭配,伪消歧(pseudo-disambiguation)方法就是利用这种思想对选择限制获取模型进行评价.对于测试集中的每一个正例(v,r,n),构造反例(v,r,n′),如果spr(v,n)>spr(v,n′),则判断正确,记做win;如果spr(v,n)=spr(v,n′),则记做tie,表示无法判定,随机来区分正反例;否则,判断错误,记做lose.在获取的语义选择限制知识基础上计算spr(v,n),即n所属的语义类中的最大概率为
spr(v,n)=maxC∃nspr(v,C)=maxC∃nP(Cv,r).
(3)
评价指标采用覆盖率cov和正确率acc,所用公式为:
(4)

(5)
一对正例(v,r,n)和反例(v,r,n′)构成一个测试样例,如果n和n′都出现在语义分类体系中,则称该测试样例被覆盖,即正例和反例都有sp值,未覆盖是n或n′未登录的情况.基于语义分类体系的知识获取方法最大的局限就是语义分类体系本身,存在未登录词的问题,覆盖率指标主要反映语义分类体系词语覆盖率的情况.正确率acc考察被覆盖样例的正确率,只有win的情况才算对.
测试数据使用1998年1月的人民日报语料,从中抽取动宾搭配,并通过人工校对选取1 289个作为正例,包括365个动词和379个名词.反例替代词的选择我们采用3种策略,分别为:名词按词频降序排列,选择直接前驱词(pre);名词按词频降序排列,选择直接后继词(post);随机选择(rand).伪消歧实验的初衷是自动构造测试集,以取代人工标注,降低劳动成本,因此,我们没有对反例进行人工校对.为了尽量避免反例恰好合理的情况,我们要求反例在整个搭配集中没有出现过,这样反例就有很大的可能性是不合理的.
表2给出本文基于MDL的方法与基于KL距离方法伪消歧结果的比较.由于两者都是基于语义分类体系的方法且使用同一个语义分类体系,所以覆盖率cov相同,在62%左右.MDL方法标记为win的样本较多,标记为tie的较少,因此正确率acc较高.进一步考察两种方法结果的一致性,用标记完全相同的样本数除以被覆盖的样本数,结果一致性agree值为60%多.结果不一致的情况,在一定程度上也说明两种方法具有相互结合进一步提升效果的可能性.

表2 MDL方法与KL方法结果比较
3 总结
本文面向词汇语义知识库建设,研究基于语义分类体系及最小描述长度原则的汉语语义选择限制获取方法,对现有的名词语义分类体系进行改造,实现了一个高效的算法,在大规模语料上进行SP知识获取.对获取的优选语义类进行了分析,并通过伪消歧实验,将本文方法与基于KL距离的方法进行了比较.实验结果体现了本文方法的有效性,且本文方法与基于KL距离的方法有一定的互补性.
[1] ZHOU G Y, ZHAO J, LIU K, et al. Exploiting web-derived selectional preference to improve statistical dependency parsing[C]//Proceedings of ACL2011, Portland, Oregon, USA, 2011: 1556-1565.
[2] WU S M, PALMER M. Can selectional preferences help automatic semantic role labeling?[C]//Proceedings of Lexical and Computational Semantics (*SEM 2015). Denver, Colorado, USA, 2015: 222-227.
[3] MCCARTHY D, CARROLL J. Disambiguating nouns, verbs, and adjectives using automatically acquired selectional preferences[J]. Computational linguistics, 2003, 29(4): 639-654.
[4] 唐海庆, 熊德意. 基于选择偏向性的统计机器翻译模型[J]. 北京大学学报 (自然科学版), 2016, 52(1): 127-133.
[5] JIA Y X, YU S W. Unsupervised Chinese verb metaphor recognition based on selectional preferences[C]//Proceedings of the 22nd Pacific Asia Conference on Language, Information and Computation (PACLIC 22). Cebu, Philippines, 2008: 207-214.
[6] SCHULER K K. VerbNet: a broad-coverage, comprehensive verb lexicon[D]. Philadelphia:University of Pennsylvania, 2005.
[7] 董振东,董强. HowNet [EB/OL]. [2017-06-05]. http://www.keenage.com.
[8] 王惠, 詹卫东, 俞士汶. “现代汉语语义词典”的结构及应用[J]. 语言文字应用, 2006(1): 134-141.
[9] RESNIK P. Selection and information: a class-based approach to lexical relationships[D]. Philadelphia:university of pennsylvania, 1993.
[10] LI H, ABE N. Generalizing case frames using a thesaurus and the MDL principle[J]. Computational linguistics, 1995, 24(2): 239-248.
[11] CLARK S, WEIR D. Class-based probability estimation using a semantic hierarchy[J]. Computational linguistics, 2002, 28(2): 187-206.
[12] 贾玉祥, 俞士汶. 语义选择限制的自动获取及其在隐喻处理中的应用[C]//第四届全国学生计算语言学研讨会(SWCL 2008). 太原, 2008: 90-96.
[13] 贾玉祥, 王浩石, 昝红英, 等. 汉语语义选择限制知识的自动获取研究[J]. 中文信息学报, 2014, 28(5): 66-73.
[14] 贾玉祥, 许鸿飞, 昝红英. 基于神经网络的语义选择限制知识自动获取[J]. 中文信息学报, 2017, 31(1): 155-161.
[15] 于江生, 俞士汶. 中文概念词典的结构[J]. 中文信息学报, 2002, 16(4): 12-20.
[16] BARRON A, RISSANEN J, YU B. The minimum description length principle in coding and modeling[J]. IEEE transactions on information theory, 2000, 44(6): 699-716.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小学生学习指导(低年级)(2020年10期)2020-11-26
数学小灵通(1-2年级)(2020年9期)2020-10-27
开放教育研究(2020年2期)2020-03-31
小学生导刊(2018年34期)2018-12-18
小学生优秀作文(趣味阅读)(2018年6期)2018-09-19
作文大王·低年级(2017年11期)2017-12-05
学苑创造·A版(2017年1期)2017-01-19
长江学术(2016年4期)2016-03-11
海峡姐妹(2016年1期)2016-02-27
