
基于Hadoop的分布式搜索引擎的研究
2018-03-26 07:14郑睿颖王芷婷
求知导刊 2017年32期
郑睿颖 王芷婷
摘 要:分布式搜索引擎是一种结合了分布式计算技术和全文搜索技术的新型信息搜索系统。它改变了人们获取信息的途径,使得人们能够更快捷、更有效地获取信息。现在它已经深入到网络生活的每一方面,被誉为“上网第一站”。文章在分析当前几种分布式搜索引擎系统的基础上,总结了现在系统的优缺点,针对现有系统的不足,提出了给予Hadoop的分布式搜索引擎。
关键词:Hadoop;分布式搜索引擎;HDFS文件系统
中图分类号:TP391.3
文献标识码:A
一、引言
近年来,随着信息技术科技的进步,人们的生活方式发生了巨大的改变,强大的数据信息化的世界正在逐渐包裹着每一个生活在当下的人们。在人们的日常生活和工作中,信息的获取途径逐渐被网络所取代,而使用者想要快速地对海量信息进行搜索就需要应用一定的媒介,即搜索引擎。与传统的集成式搜索相比,分布式搜索引擎具有更加突出的优势,在这种情况下,积极加强基于Hadoop的分布式搜索引擎研究具有重要意义。
二、基于Hadoop分布式搜索技术
Hadoop是一个由Apache基金会开发的分布式系统基础架构,它的产生是建立在针对Doug Cutting和Yahoo的研究之上。Hadoop对于用户的要求并不高,只要有一定的程序开发基础,即便不了解分布式底层细节,用户依然可以开发分布式程序。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的硬件上。而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS放宽了POSIX的要求,可以以流的形式访问文件系统中的数据。
Hadoop的框架最核心的设计就是HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce为海量的数据提供了计算。
1.HDFS文件系统
开源版本在Google GFS中的体现就是HDFS,该分布式文件系统有高容错性,数据访问中可以实现高吞吐量,能够对高于64MB的大文件进行海量储存。
对于一个HDFS系统来说,硬件故障是常有的事。一个HDFS系统由成百上千个存储数据片段的服务器构成,可想而知,如此庞大的组成部分是很有可能出现故障的,而故障所导致的后果就是部件失效。因此,故障的检测和自动快速的恢复是HDFS一个很核心的设计目标。
在HDFS上运行的程序是有其特定的要求的,那就是必须以流的形式访问数据集。HDFS不能进行用户交互,其处理文件的方式是批量处理。它的特点体现在数据吞吐量上,但对于数据访问的反应时间并没有做过多要求。
HDFS文件系统还有一个显著的特点,即大数据集。在HDFS上运行的应用程序都是拥有着大量数据的。通常情况下,HDFS文件大小为GB级到TB级。HDFS提供的空间是相当大的,一个集群中不仅能支持数百个节点,还可以支持千万级别的文件。
2.MapReduce模型
MapReduce是一种编程模型,在2004年由Google Allo实验室提出。它的功能是作用在集群上,对海量的数据进行并行处理。在Google内部,MapReduce的应用非常广泛,其中包括分布grep、分布排序web访问日志分析、反向索引构建、文档聚类、机器学习和基于统计的机器翻译等。甚至,在MapReduce得到实现之后,它被用来重新生成了Google的整个索引。由此可见,MapReduce具有非常高的性能。
最简单的MapReduce应用程序,至少要包括三个部分:一个Map函数,一个Reduce函数,一个main函数。其中,Main函数的功能是将作业控制和输入/输出结合起来。Hadoop为其提供了大量接口,从而为Hadoop应用程序程序员提供了许多工具,使得操作更方便。另外两个函数就是这个模型的核心操作。Map和Reduce函数实际上处理的都是大量像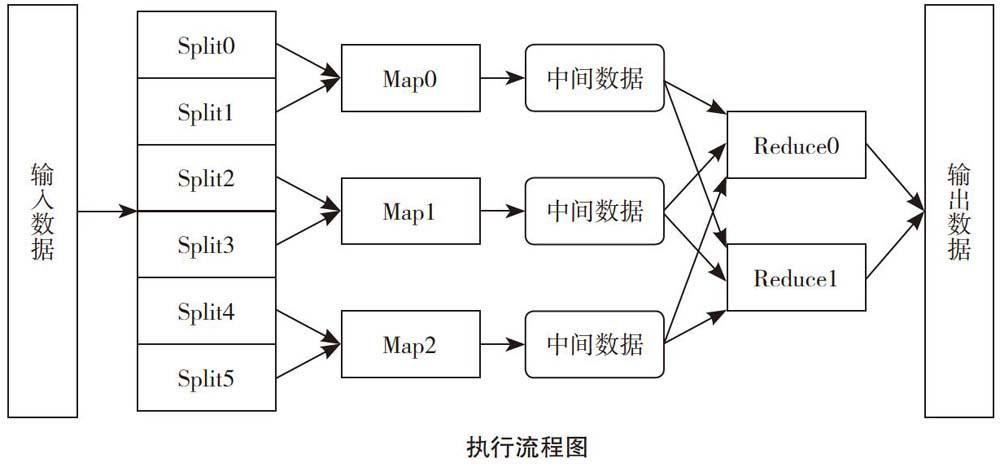
三、分布式引擎的设计与实现
分布式搜索有三个子系统,分别是爬行子系统、索引子系统、查询子系统。系统中利用了MapReduce模型的优点,将上述的三个子系统设计成分布式系统。下面对这三个子系统进行分析。
(1)分布式爬行子系统。其主要功能是对网页数据进行抓取,并进行分析提取链接,生成的链接列表为下一次爬行做准备。爬行子系统设计的核心就是任务调度,其所有的爬行器统一由JobTracker负责调度。
(2)分布式索引子系统。其主要负责的就是计算网页的PageRank值,倒排文档的构建,以及索引文件的分布式存储。此系统为整个搜索引擎的核心。
(3)分布式查询子系统。主要负责的是响应用户查询请求并向用户返回查询结果。查询子系统采用的也是MapReduce模型设计,将Tomcat作为Web服务器,使用Jsp/Servlet技术于用户进行交互。
四、结语
在这个数字信息化大时代,在社会运行过程中都会产生大量数据。如何对这些海量数据进行处理、操作,对用户的要求提出响应,是我们要一直探索和不断研究的。那么,基于Hadoop的分布式搜索引擎的研究就具有重大的意义了。
参考文献:
[1]范晨熙.基于Hadoop的搜索引擎的研究与应用[D].杭州:浙江理工大学,2013.
[2]王振宇,郭 力.基于Hadoop的搜索引擎用户行为分析[J].计算机工程与科学,2011,33(4):115-120.
[3]万 轶.基于Hadoop的搜索引擎关键技术研究[D].武汉:武汉理工大学,2015.
[4]陈 宁,柴向阳,孙 勇.基于Hadoop的海运业分布式搜索引擎的应用研究[J].西安工程大学学报,2015(1):73-77.
[5]余 紅.基于Hadoop的分布式搜索引擎研究[D].北京:北京师范大学,2012.
[6]王俊生,施运梅,张仰森.基于Hadoop的分布式搜索引擎关键技术[J].北京信息科技大学学报(自然科学版),2011,26(4):53-56.
