
油浸绝缘电气主设备状态量发展趋势预测模型研究
2018-03-31 07:40李正天曹长冲
水电站机电技术 2018年3期
徐 铬,李正天,程 建,万 松,曹长冲
(1.长江电力技术研究中心,湖北 宜昌 443000;2.华中科技大学电气工程学院,湖北 武汉 430000)
1 引言
油浸绝缘电气主设备油中所溶解的气体组分与含量可以直接反映其健康状态。通过对油浸绝缘电气主设备油中溶解气体浓度的数据挖掘,并预测其发展趋势,可使决策者在故障发生前有充裕的时间制定更加合理的状态检修计划,既能保证油浸绝缘电气主设备运行的可靠性以确保电网的安全稳定运行,也可提高电网运行的经济效益。
现代的预测技术是通过智能手段对未知量进行研究的科学,是根据历史数据和当前的状况,通过建立模型,进行定性定量的主观估计和计算,研究某一事物当前各种因素之间的相互关系,寻求事物的发展规律,来推测将来某时刻的状态,为当前决策提供支持。预测技术经过不断发展可分为以下3大类:
(1)统计预测技术包括基于回归分析法的预测技术和基于时间序列分析法的预测技术;
(2)数学预测技术主要有模糊理论预测技术、灰色理论预测技术和支持向量机预测技术;
(3)近年智能算法越来越成为研究的焦点,在预测中也出现很多应用,例如基于神经网络的预测技术、基于遗传算法的预测技术、基于专家系统的预测技术等。
2 预测算法优化
由于预测算法都有自己的局限性,没有哪一种算法能够准确无误地对数据进行预测。在训练数据样本不完善的情况下,预测误差会变得更大。因此,需要将算法进行有机组合,扬长避短,充分发挥算法的优势,将预测误差尽可能地减小。仅用单一预测模型进行预测时,因其考虑角度的局限性、信息选择的片面性以及信息利用程度的差异性,导致其预测精度不高且稳定性差。而组合预测法能很好地综合各种单一预测算法的优势,更大限度地发挥不同方法的优点,做出正确的预测。国内外关于组合预测应用效果最好的是最优权重组合预测。具体步骤是:对于各种单项预测模块,先计算各自的最优权重,形成组合预测模型,然后加权综合求出最终的预测结果。对于最优的标准,多是按照测量误差平方和最小为原则,采用拉格朗日乘子,进行最优权重的计算。设y(t)是一预测对象在t时刻的属性值,t=1,2,…,n。若y(t)有m种预测模型,是第i个预测模型在第t时刻的预测值,则第i个预测模型在第t时刻的预测误差为:

相应的预测误差信息矩阵E为

若 W=(w1,w2,…,wm)T为 m 个预测模型线性组合的加权系数,则组合预测模型形式为:

且w1+w2+…+wm=1。另外在t时刻,组合预测模型的预测误差为

故可得到线性组合预测的误差平方和为

组合预测模型的关键与难点在于权值的分配,最优权重多采用以误差平方和S最小为准则,通过求解如式(6)所示的模型来选择组合权值。

即组合预测模型的最优权重系数为二次规划问题的最优解。为了求解这个问题,引入Lagrange系数λ,分别对W与λ求导并求解得:
即可求得最优权重向量解

但是最优权重组合预测算法也存在着问题。其在计算中,只能考虑单一因素的影响,因而精度还是受限。为了解决这个问题,本项目引入了基于信息熵的组合预测算法,该算法可以综合考虑多项因素的影响,并运用熵权法智能分配各因素的权重,使预测精度进一步提高。本文采用的组合预测模型使用多种评价指标来评判各单一预测方法的预测精度。评价指标j(j=1,2,…,q)的重要性熵值为:

式中Nij为各评价指标参数值相对于各评价指标的接近程度。由于信息熵e(dj)可用来衡量评价指标j信息的有用程度,信息熵越小则评价指标j的有效程度越高,评价指标j的信息效用程度hj=1-e(dj)。利用熵权法计算各评价指标的客观权重,实质上是利用该评价指标信息的效用价值系数来计算的,效用价值系数越高,对评价的重要性就越大,于是得到评价指标j的客观权重值θj:

最后再对预测方法i(i=1,2,3)的权重ωi进行计算:

具体评价预测算法信息熵的指标有:
(1)平方和误差(SumofSquares Error,SSE):

(2)平均绝对误差(Mean Absolute Error,MAE):

(3)均方误差(Mean Square Error,MSE):

式(16)~(18)中,ti指第 i个测量值,pi指第 i个预测值。计算出这些指标之后,利用式(10)~(15)可以计算出各算法这些指标对应的熵值以及各预测算法所占的权重。对充油设备故障诊断分析有价值的特征气体主要有氢气、甲烷、乙烷、乙烯和乙炔。这里以氢气为例,对其含量进行预测分析。为了比较预测值与实测值,采用预测的相对误差δ和平均相对误差来评价算法的预测结果,定义如下:

式(19)及(20)中 y为实际监测值,yˆ为模型预测值,n为样本个数。
3 预测算法相关应用
所提出的预测是基于预测数据和实际数据的对比,实现对真实故障和运行环境变化所带来的数据突变的甄别。将第N天的实测值与基于0~N-1天的实测数据做出的第N天的预测数据进行比对,如果两者偏差较大,存在两种可能,一种是运行工况变化,如变压器突然重载造成预测数据与实测值的暂时性背离。这个重载工况消失以后,后续的实测数据应该将会向基于预测做出的轨线回归。第二种就是实际发生了故障,后续的实测数据将会与基于预测的轨线存在持续性的背离。
基于上述分析,进行第N+1天预测时,应以第N天的预测值而不是第N天的实测值填入预测序列,而预测序列第1~N-1天的值均为实测值,预测得到第N+1天的预测值。如果第N+1天的预测值与其实测值依然吻合,则初步断定第N天的实测值与预测值偏离是扰动引起,则对第N+2天的预测依然是第N天用预测值,其他天均用实测值来进行预测,如果第N+2天的预测值与实测值吻合,那么基本可以断定系统未发生故障,且形成的预测序列是可信序列。如果第N+1天的预测值与其实测值背离,则初步断定第N天的实测值与预测值偏离是故障引起,这时应该调用故障诊断模块进行诊断,判断出具体故障类型。
如果故障比较严重,变压器停运检修,预测结束。如果故障不太严重,变压器带病运行,在误差允许的条件下,将预测数据窗内全部填入实测值进行预测。也可以将之前的预测序列清空,之后的每一天将实测值填入预测序列的数据窗(一般会用到7 d的数据,每天采集一个点),直到数据窗填满,具备预测的条件后再启动新的预测。此时可以对带病运行的变压器是否会发生新的故障或经历扰动进行新一轮的判断。根据异常数据的变化特征,可以将其具体划分为以下两种形式:数据出现突增,并且出现超过注意值的情况。这样的情况下,在线监测系统会发出误报警信号。数据出现大幅度下降,但并未降至0。该情况虽然不会导致误报事件的发生,但是会因为量测值的不准而导致在线监测系统不能准确及时地识别数据的劣化情况,同时将直接影响到趋势预测结果的准确性和可靠性。
针对以上情况,本文提出了不同时间尺度下在线监测异常数据辨识方法,同时将对方法进行程序化并在系统平台中以功能模块体现。
1、投喂时间。开春后,当水温上升到16℃以上,应开始投喂。虾一般夜间进食,每天投喂时间选择下午5-6点。
3.1 长时间窗下异常数据识别
3.1.1辨识原理
在较长时间尺度上对在线监测数据与离线试验数据变化趋势进行对比,可以及时地辨识出在线监测数据质量劣化趋势。为了实现这一功能,本项目构造了表征数据精度的期望偏离度、表征数据离散度的方差以及表征数据背离度的方差变化率这3项辨识指标。
(1)期望偏离度Ex(Expectation)是指在相同时间尺度下在线实时数据与离线试验数据的期望值之差,表征了在线监测装置所获取的数据的精度。

(2)方差Vx(Variance)是指相同时间尺度下在线实时数据与离线试验数据之差的平方和,表征了在线监测装置所获取的数据与离线试验数据之间的离散度。

其中,yi表示在线监测装置获取的设备实时数据。
(3)方差变化率Rx(Ratio of Variance change)是指在线实时数据与离线试验数据方差的变化情况,表征了在线监测装置所获取的数据与离线试验数据之间的背离度。

3.1.2校对步骤
校对步骤具体流程如图1所示。

图1 在线监测数据准确性全自动校对流程
3.1.3校对结果说明
根据本文所构造的3项性能评定指标,下面将对可能出现的几种校对情况进行详细说明。
(1)性能优秀:该标定结果表示在线监测装置获取的数据在精度、方差、方差变化率方面均能符合要求,即精度高、方差与方差变化率小,如图2所示。

图2 校对优秀
(2)性能良好:该标定结果表示在线监测装置获取的数据在精度方面有一定偏差,但在方差及方差变化率方面均能符合要求,如图3所示。

图3 校对良好
(3)性能异常:该标定结果表示在线监测装置获取的数据在精度、方差及方差变化率方面均不符合要求,如图4所示。

图4 校对异常
由图4可知,在线监测获取的数据在某一个时间点或者在整个监测周期内精度不高,离散度与背离度都很大,可以断定该在线监测装置的性能处于异常状态。出现这样的标定结果,主要有两种情况:①由于投运时间较长,性能劣化或受到外界干扰,在线监测装置在某一个时间点起无法获取准确的在线监测数据;②在线监测装置本身不具备或其获取在线监测数据的能力不足,上传到系统的数据为具备一定规律的人造伪数据。
3.2 短时间窗下异常数据识别
在较短时间尺度上对在线监测数据的变化趋势进行判别,可以及时地辨识设备潜在故障或在线装置性能的异常。本项目通过计算在线监测数据日变化率△(有正有负),作为辨识的判断依据:

其中Ci为第i天的在线监测数据,Ci-1为第i-1天的在线检测数据。
对于数据异常突增的情况,设定数据异常识别的启动门限为注意值的80%,即当数值达到了注意值的80%之后再关注,此时:①如果所有气体的在线监测值未超过注意值、日变化率均为正值且超过初步设定的阈值,则表明设备可能存在一定的故障隐患,需要继续跟踪,如果接下来的几天数据继续呈现上升趋势,则提示工作人员注意;②如果部分气体(主要是乙炔)的在线监测值超过注意值,其余气体未超过注意值且日变化率为负或者几乎不变,则表明在线监测系统性能出现了异常(误报警),继续跟踪,如果接下来几天还是类似情况,将提示工作人员,以便联系厂家进行维护。
对于数据出现异常下降的情况,设定数据异常识别的启动门限为注意值的20%,即在数据降低到注意值的20%以下再关注。这样处理的依据主要是考虑如果数据较小的话,波动对变化率的影响很大,如果不设置启动值,那么将会导致频繁发出报警信号。此时,如果所有气体值未超过注意值,日变化率都是负的且大部分超过初步设定的阈值,则表明在线监测系统性能出现了异常。
4 实例分析
北京某220 kV发电厂主变在线监测数据,在线监测以天为单位。从数据样本中可见氢气的含量并不包含突变型数据。使用2012/11/2~2013/5/10的数据进行预测模型的训练样本,预测未来12 d(2013/5/11~2013/5/23)氢气含量的趋势。
由表1可知,本文使用的基于信息熵组合预测算法的平均相对误差不仅远小于RBF神经网络及SVM两种预测模型的平均相对误差,还小于基于最优权值组合预测算法的平均相对误差。各单一预测方法、组合预测及真实值的曲线如图5所示。信息熵与最优权重组合预测的对比如图6所示。
杭州某变压器于2013年7月25日由于轻瓦斯保护报警,运维人员经过排查,发现是内部发生了局部放电故障,经停电维修排除了故障。我们根据在线监测设备回溯了停运前20 d的数据,并对其进行预测。预测结果如图7所示。

表1 RBF神经网络和SVM预测模型的预测值与实际值对比

图5 基于信息熵的组合预测与单一预测方法对比

图6 基于信息熵的组合预测与最优权重方法对比
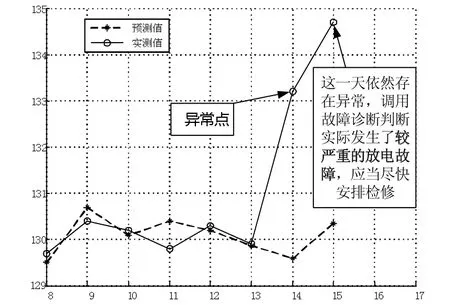
图7 发生实际故障后的预测
由图7可以看出,实际上第14天数据即有异常,但是因为没有超过日产气速率注意值,实际上运维人员只是进行了日常例行监测,并没有进行相关运维措施,直至第19天轻瓦斯保护动作触发报警才开始排查原因,并于第20天停运检修。但是,根据预测,在第14天数据异常后,预测因为预测误差超过门槛值而将预测值填入序列,对第15天进行预测,而在第15天偏差依然较大,即可调用故障诊断模块对原因进行分析,从而诊断出原因。比原有方法提前了5 d。
而郑州某变压器于2010年5月16日出现了气体值异常升高的情况,现场人员介入排查并没有发现原因,采取密切关注的措施,并于6 d后排除故障可能,解除观察。我们也选取了20 d的数据进行了预测。预测结果如图8所示。

图8 对异常工况的预测
由图8可以看出,在出现异常点的第2天气体值即下降到了原有的趋势上,由于气体值仍超过了注意值,目前运维人员仍然需要对这台设备进行密切关注并不断取油样做实验直至确定设备没有问题,工作量将大大增多。但是,如果采用本方法,将在第2天实测值回归后进行初步的非故障预判,并结合之后几天的数据全自动比对,确定是因为异常工况导致的数据突变。基于上述分析,通过预测值与实测值的比对,实现了对突发性故障与异常工况的甄别,显著减少运维人员处理误报警的工作量,并避免对应急检修资源的滥用,对于实际发生的突发性严重故障也可以在1 d之内给出确切结论,合理安排停运及应急检修。
5 结论
本文研究了油浸绝缘电气主设备状态量发展趋势预测模型。提出了基于信息熵的组合预测方法,针对预测结果的应用问题,提出了区别变压器故障与工况改变的预测应用方法。同时针对现场调研所了解到的实际生产问题,有针对性地展开了研究,提出了相应的解决方法。最后,通过实际案例计算分析,证明了预测模型的可行性。
参考文献:
[1]阮羚,谢齐家,高胜友,等.人工神经网络和信息融合技术在变压器状态评估中的应用[J].高电压技术,2014,40(3).
[2]史清,杨建平,谢励耘,等.油浸式变压器绝缘试验与异常状态识别[J].上海电力,2013(3):184-187.
[3]陈英.变压器绝缘老化判据及实用化预测模型的研究[D].武汉:华中科技大学,2009.
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01
今日农业(2021年19期)2022-01-12
环境保护与循环经济(2021年7期)2021-11-02
哈尔滨轴承(2020年1期)2020-11-03
国外核新闻(2020年8期)2020-03-14
中国奶牛(2019年10期)2019-10-28
电子制作(2018年23期)2018-12-26
雷达学报(2017年6期)2017-03-26
池州学院学报(2015年3期)2016-01-05
郑州大学学报(理学版)(2014年2期)2014-03-01
