
序信息系统下的程度可区分关系研究
2018-04-04 08:42汪琳娜四川工商学院电子信息工程学院四川成都6745西南交通大学信息科学与技术学院四川成都6756四川工商学院云计算与智能信息处理重点实验室四川成都6745
西华大学学报(自然科学版) 2018年2期
汪琳娜,杨 新(.四川工商学院电子信息工程学院,四川 成都 6745;2.西南交通大学信息科学与技术学院,四川 成都 6756;3.四川工商学院云计算与智能信息处理重点实验室,四川 成都 6745)
1979年Zadeh提出信息粒化(information granulation)的概念[1],试图用信息粒化思想去发现知识。此后出现了采用粒化模型来解决实际问题的情况,例如:1982年Pawlak提出用粗糙集(rough set)理论处理不确定性问题[2];1990年张钹等提出采用商空间(quotient space)模型解决信息融合、路径规划和推理等问题[3];1996年Zadeh提出了采用词计算(computing with words)模型来进行计算及推理[4];Lin 正式提出粒计算(granular computing)一词[5-7],其后Zadeh根据粒计算思想,指出人类认知由粒化、组织、因果3部分构成,知识粒化成粒子,然后又可按照某种关系组织在一起,进而揭示原因和结果的联系[8]。目前粒计算已经成为人工智能计算领域中解决知识发现和模拟人类认知的有效方法。知识的粒化是如何把知识从整体分解为部分,这已经成为当前粒计算研究的热点问题。
Pawlak提出的经典粗糙集模型是利用不可区分关系(indiscernibility relation),即等价关系,对论域进行划分,得到不可区分的等价类,然后在近似空间中构造上下近似算子来逼近边界模糊的集合,从而发现不确定性知识。在经典粗糙集理论中,知识粒化依赖于不可区分关系(等价关系),当把完备信息系统过渡到不完备信息系统时,需要对等价关系进行泛化,对自反性、对称性和传递性重新组合得到其他二元关系,如Kryszkjewicz[9]提出的容差关系,Stefanowski等[10]提出的量化容差关系,王国胤[11]提出的限制容差关系,黄兵等[12]提出的基于集对联系度的容差关系,Grzymala-busse[13]提出的特征关系。其后,众多学者提出了不完备系统下的各种二元关系,但完备信息系统下的粒化关系研究却较少。
在完备信息系统下,在基于不可区分关系的各种粗糙集里,如果2个对象存在某一属性不相等,则2个对象一定不在同一等价类;但是在实际完备信息系统粒化过程中,有可能会出现每一个对象是一个等价类的知识粒度最细情况。此时,粒化结果显然不利于对信息的处理,需要进一步对对象的相似性进行刻画,即如果对象满足一定相似精度,在属性不完全相等的情况下也可以分到同一类。Yao等[14]对粗糙集中的可区分关系(discernibility relation)和不可区分关系展开对立分析,提出了4种对象间的关系,即强不可区分关系、弱不可区分关系、强可区分关系和弱可区分关系,并基于以上关系提出了3种属性约简的方式。秦克云等[15]提出采用程度不可区分关系的概念来刻画信息系统中对象的可区分性程度的差异。本文在程度不可区分关系的基础上,提出了程度可区分关系,并针对名义型数据在序信息系统中考虑属性值的相似程度,进一步提出了改进的程度可区分关系,研究在信息粒度较细的情况下如何通过刻画属性值间的差异来进行更好的决策和分类。
1 不可区分关系和可区分关系

定义2[14]设信息系统S=(U,A,V,f),强不可区分关系、弱不可区分关系、强可区分关系、弱可区分关系分别定义为:
IND(A)={(x,y)∈U2|∀a∈A,f(a,x)=f(a,y)};
WIND(A)={(x,y)∈U2|∃a∈A,f(a,x)=f(a,y)};
DIS(A)={(x,y)∈U2|∀a∈A,f(a,x)≠f(a,y)};
WDIS(A)={(x,y)∈U2|∃a∈A,f(a,x)≠f(a,y)}。
(1)
其中,强不可区分关系IND(A)是U上的一个等价关系,表示U上任何2个对象在所有属性上属性值都相等,满足自反、对称、传递性质。通过IND(A)可以对U进行划分,记为U/IND(A),对于任意1个对象x∈U,[x]A表示在IND(A)划分下包含x的等价类,即[x]A={y∈U|(x,y)∈IND(A)}。为方便,简记等价关系为RA,等价类为[x]。
弱不可区分关系WIND(A)表示任意2个对象至少在一个属性上属性值相同,满足自反、对称性质,但不满足传递性质。
相对于不可区分关系,强可区分关系DIS(A)表示2个对象在所有属性上都不相等,满足对称性质,但不满足自反、传递性质。弱可区分关系WDIS(A)表示2个对象至少在一个属性上属性值不相等,同样满足对称性质,但不满足自反、传递性质。
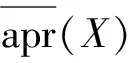

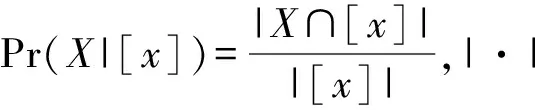
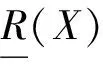
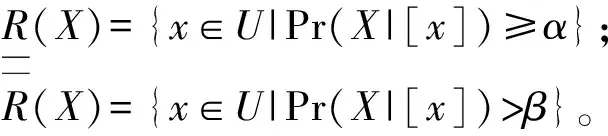
其中,关于X的(α,β)正域、边界域、负域定义为:
POS(α,β)(X)={x∈U|Pr(X|[x])≥α};
BND(α,β)(X)={x∈U|β NEG(α,β)(X)={x∈U|Pr(X|[x])≤β}。 定义5[15]设信息系统S=(U,A,V,f),对于任意B⊆A,由B诱导的程度不可区分关系GINDB(A),是U上的二元模糊关系,即GINDB:U×U→[0,1],且对于任意x,y∈U,有 从定义中可以看出,程度不可区分关系GINDB(A)表示B中不能区分x和y的属性在B中所占的比例,且满足自反和对称性质,不满足传递性质,用来刻画对象间不可区分的程度。相反,如果要刻画对象间可区分关系,可以得到程度可区分关系为 显然有 GINDB(x,y)+GDISB(x,y)=1, (7) 且程度可区分关系GDIS(B)满足自反和对称性质,不满足传递性质。 当GIND(A)=0,GDIS(A)=1时,程度不可区分关系GIND(A)和程度可区分关系GDIS(A)同时泛化为强可区分关系DIS(A);当0 程度不可区分关系GIND(A)是从对象间属性相等的程度来描述不可区分的程度。程度可区分关系GDIS(A)是从对象间属性不相等的程度来描述可区分程度。虽然从程度不可区分关系可以直接得到程度可区分关系,但是2种关系的分析视角不同,会导致对知识进一步粒化的方法和结果不同。 如果假设一个程度阈值δ和δ′,0≤δ≤1,0≤δ′≤1,则δ-程度不可区分关系定义为 GINDδ(A)={(x,y)∈U|GINDA(x,y)≥δ}。(8) δ′-程度可区分关系定义为 GDISδ′(A)={(x,y)∈U|GDISA(x,y)≤δ′}。(9) 下面分别给出基于δ-程度不可区分关系GINDδ(A)和基于δ′-程度可区分关系GDISδ′(A)的概率粗糙集的定义。 (10) (11) 当δ=1,δ′=0时,δ-程度不可区分关系GINDδ(A)和δ′-程度可区分关系GDISδ′(A)同时泛化为强不可区分关系IND(A);当0<δ<1时,δ-程度不可区分关系GINDδ(A)泛化为弱不可区分关系WIND(A)。当0<δ′<1时,δ′-程度可区分关系GDISδ′(A)泛化为弱可区分关系WDIS(A)。 为分析比较程度不可区分关系GINDδ(A)和程度可区分关系GDISδ′(A),下面先给出关系矩阵的定义,然后通过例子说明2种关系间的区别和联系。 定义7设信息系统S=(U,A,V,f),RrA表达U上任意2个对象间的关系,对∀x,y∈U,关系矩阵可以定义为: 例1设一个学生成绩信息表,对象集U={x1,x2,x3,x4,x5},分别代表不同的学生,属性集A={a1,a2,a3,a4},分别代表语文、数学、英语、历史,每个属性的值域为{1,2,3,…,6,7},代表成绩的优劣程度,从1到7分别表示{非常差,比较差,一般差,中等,一般好,比较好,非常好}。信息表如表1所示。 根据上文提到的4种关系IND(A)、WIND(A)、DIS(A)、WDIS(A)的定义,可以分别得到在强不可区分关系、弱不可区分关系、强可区分关系和弱可区分关系下对象间的关系矩阵: 显然,不可区分关系和可区分关系存在联系,弱不可区分关系包含强可区分关系,弱可区分关系包含强可区分关系,即: IND(A)⊆WIND(A); DIS(A)⊆WDIS(A)。 如果考虑互补关系,则有: WDIS(A)=INDC(A); WIND(A)=DISC(A)。 由表1可知,由强不可区分关系IND(A)划分得到的等价类为 U/IND(A)={{x1},{x2},{x3},{x4},{x5}}。 由强可区分关系DIS(A)得到: DISA(x1)=∅; DISA(x2)=∅; DISA(x3)=∅; DISA(x4)={x5}; DISA(x5)={x4}。 在弱不可区分关系WIND(A)得到: WINDA(x1)={x1,x2,x3,x4,x5}; WINDA(x2)={x1,x2,x3,x4,x5}; WINDA(x3)={x1,x2,x3,x4,x5}; WINDA(x4)={x1,x2,x3,x4}; WINDA(x5)={x1,x2,x3,x5}。 在弱可区分关系WDIS(A)得到: WDISA(x1)={x2,x3,x4,x5}; WDISA(x2)={x1,x3,x4,x5}; WDISA(x3)={x1,x2,x4,x5}; WDISA(x4)={x1,x2,x3,x5}; WDISA(x5)={x1,x2,x3,x4}。 由以上计算可知:在强不可区分关系IND(A)下产生了最细的划分,每个对象两两之间都是可以区分的;在强可区分关系DIS(A)下,只有对象x3和x4之间的每个属性都不相等,而其他对象容差类都是空集;在弱不可区分关系WIND(A)和弱可区分关系WDIS(A)下,对对象间关系的容忍又过大。此时4种关系均不利于进一步分类和决策。 注意到对象x1、x2、x3之间只在a1属性下可区分,其他属性均不可区分。为体现不可区分的程度,根据GINDδ(A)的定义,设δ=3/4,计算得到δ-程度不可区分关系GINDδ(A)下对象间的关系矩阵为 因此,由δ-程度不可区分关系可得到: 可以看出,无论如何改变阈值δ,对象x1、x2、x3的不可区分程度始终相同,如果要进一步刻画对象间的相似度,只能考虑对象x1、x2、x3在属性a1下的取值差异,即属性值的可区分程度;因此,有必要从可区分程度研究知识粒化。观察表1可以发现,在属性a1下x2和x1、x3属性值相差较大,但是x1和x3属性值相差较小,即学生x1和x3在语文上成绩相差不大,但是学生x2和学生x1、x3在语文上成绩相差太大,如果考虑具体分类和决策问题,显然x1和x3应该划分到同一类,但如果考虑在语文属性下的差异程度,此时x2不适宜与x1、x3在同一类。为了进一步刻画对象间的可区分程度,下面提出一种基于序信息系统的改进程度可区分关系。 程度可区分关系主要是刻画对象间可区分的程度。考虑进一步刻画对象间可区分程度,下面在序信息系统中针对名义型数据,考虑属性值的差别定义改进的γ-程度可区分关系。 定义8设一个序信息系统S=(U,A,V,f),假定所有的条件属性值都是整数名义型,且属性值都是递增或递减偏好有序的,即∀ai∈A,Vai={v1,v2,…,vj,…,v|Vai|},vj∈N+且v1v2…v|Vai|或v1≻v2≻…≻v|Vai|,和≻代表偏好关系。对于任意的条件属性集合B⊆A,设γ是程度阈值,0≤γ≤1,改进的γ-程度可区分关系IGDISγ(B)可定义为 IGDISγ(B)={(x,y)∈U|IGDISB(x,y)≤γ}。 (13) 式中: 其中,|Vai|是属性ai值域的取值个数,abs表示取绝对值。 从定义可知,∀x,y∈U,0≤IGDISB(x,y)<1。γ-程度可区分关系IGDISγ(B)满足自反和对称性质,但不满足传递关系。当γ=0时,γ-程度可区分关系IGDISγ(B)退化为等价关系IND(B)。 改进的γ-程度可区分关系IGDISγ(B)主要针对整数名义型数据,可以在序信息系统下进一步刻画对象间的相似度。下面给出基于改进的γ-程度可区分关系IGDISγ(B)的概率粗糙集模型的定义。 定义9设信息系统S=(U,A,V,f),IGDISγ(A)是改进的γ-程度可区分关系,给定一对阈值(α,β),并且满足0≤β<α≤1,对于任意的X⊆U,则关于X的概率粗糙集的上下近似集定义为: 定理1设X,Y⊆U,则上述概率粗糙集的上下近似算子满足以下性质: 根据改进的γ-程度可区分关系IGDISγ(A),以表1为例计算可得: 由此可看出,x1,x2,x3相互间的可区分程度得到进一步刻画。取γ=2/28,计算得到程度可区分关系矩阵 进而得到: 观察发现,在改进的γ-程度可区分关系GDISBγ下,x2和x1、x3没有在同一类。这是由于x2和x1、x3虽然在属性a2、a3、a4下相同,但是在属性a1下的属性值相差较大。 如果取γ=3/28,可以得到: 观察发现,当水平γ增大时,对象间的可区分容忍程度变大,此时知识粒可能变大也可能不变。 为解决粒化过程中知识粒度过细带来的分类和决策问题,通过分析信息系统下的不可区分关系和可区分关系,在程度不可区分关系的基础上,逆向考虑对象间的可区分程度,提出了γ-程度可区分关系。为进一步刻画对象在属性值上的差异程度,针对整数名义型数据,在序信息系统中提出了一种改进的γ-程度可区分关系,并且定义了基于改进的γ-程度可区分关系的概率粗糙集模型。基于程度可区分关系下一步可在不完备信息系统下讨论,还可以在考虑属性重要度的情况下刻画对象间的可区分程度。 [1]ZADEH L A. Fuzzy sets and information granularity in advances in Fuzzy set theory and applications [M]. Amsterdam: North-Holland Publishing, 1979. [2]PAWLAK Z. Rough set [J]. International Journal of Computer and Information Science, 1982, 11(5):341. [3]张钹,张铃.问题求解理论及应用 [M].北京:清华大学出版社,1990. [4]ZADEH L A. Fuzzy logic-computing with words [J]. IEEE Trans on Fuzzy Systems, 1996, 4(2):103. [5]LIN T Y Y.Granular Computing [R]. [S.l.]:Announcement of the BISC Special Interest Group on Granular Computing, 1997. [6]LIN T Y Y.Granular computing on binary relations I: data mining and neighborhood systems [J].Rough Sets in Knowledge Discovery,1998(2):165. [7]LIN T Y Y. Data mining and machine oriented modeling: a granular computing approach [J]. Journal of Applied Intelligence, 2000, 13(2):113. [8]ZADEH L A. Towards a theory of fuzzy information granulation and its centrality in human reasoning and fuzzy logic [J]. Fuzzy Sets and Systems, 1997, 90(2):111. [9]KRYSZKIEWICZ M. Rough set approach to incomplete information systems [J]. Information Sciences,1998,112(1): 39. [10]STEFANOWSKI J, TSOUKIAS A. Incomplete information tables and rough classification [J]. Computational Intelligence, 2001, 17(3):545. [11]王国胤.Rough集理论在不完备信息系统中的扩充 [J].计算机研究与发展, 2002, 39(10):1238. [12]黄兵,周献中.基于集对分析的不完备信息系统粗糙集模型 [J].计算机科学, 2002, 29(9):1. [13]GRZYMALA-BUSSE J W. A rough set approach to data with missing attribute values [C]//Proceedings of the 1st International Conference of Rough Sets and Knowledge Technology (RSKT2006).chongqing: Springer-Verlag Berlin, Heidelberg,2006:58-67. [14]YAO Y Y, ZHAO Y. Conflict analysis based on discernibility and indiscernibility [J]. IEEE Symposium on Foundations of Computational Intelligence, 2007, 177 (22):302. [15]秦克云,罗珺方.基于程度不可区分关系的粗糙集模型[J].计算机科学,2015,42(8):240. [16]YAO Y Y. Probabilistic rough set approximations [J]. International Journal of Approximate Reasoning, 2008, 49(2): 255.2 程度不可区分关系和程度可区分关系
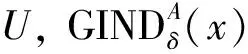

3 改进的程度可区分关系
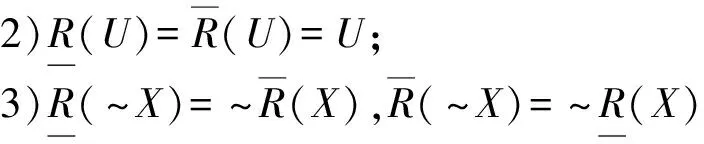
4 结束语
猜你喜欢
舰船科学技术(2022年20期)2022-11-28农机科技推广(2022年7期)2022-08-16中国现代中药(2021年7期)2021-09-06科教导刊·电子版(2021年6期)2021-05-06河南农业科学(2020年7期)2020-07-22广西农学报(2019年4期)2019-11-26奥秘(创新大赛)(2019年3期)2019-03-13作文评点报·低幼版(2018年17期)2018-07-12百科探秘·航空航天(2016年5期)2016-11-07现代计算机(2016年17期)2016-02-28
