
基于样本邻域保持的代价敏感特征选择*
2018-04-13 07:29余胜龙
数据采集与处理 2018年2期
余胜龙 赵 红
(闽南师范大学粒计算及其应用重点实验室,漳州,363000)
引 言
在当前的数据时代,无论在数量还是在维度上,数据的产生都是多种多样的,而且数据也越来越大。如在医学、天文和文本等领域,高维数据给数据分析带来了诸多挑战。因此,数据降维[1]成为机器学习中一个必不可少的过程,而特征选择是主要的降维技术之一。特征选择是通过选取能表示所有特征的一个较小的特征子集。从数据是否带有标签来看,特征选择可以分为有监督和无监督两种。有监督的特征选择是利用标签信息评价特征的重要度来进行选择,运用比较广泛的有监督特征选择算法有Fisher Score[2],Relief和ReliefF[3]。无监督的特征选择算法[4]是根据自己数据特征的关系来进行特征选择。
一部分有监督特征选择算法以追求高精度为目的,却忽略了误分类代价或默认误分类代价相同。然而,在现实应用中,不同的误分类通常会导致不同的误分类代价。例如,在交易过程中存在两种类型的误分类。类型Ⅰ定义为将正常交易误分为欺骗交易;类型Ⅱ定义为将欺骗交易误分为正常交易。类型Ⅰ的错误代价是工作人员重新审查交易;类型Ⅱ的错误代价是造成了巨大的金钱损失。显然,类型Ⅰ导致的错误代价要小于类型Ⅱ导致的错误代价。另一部分有监督特征选择算法以选择有益的特征为目标,假设不同类别的样本具有相等的权重,这种认为数据本身有均衡样本类别的想法会导致在数据具有不均衡的样本类别时,有监督特征选择算法的效果大打折扣。因此在现实应用中必须考虑数据类别不均衡问题。
20世纪90年代,代价信息被考虑到算法中,因而提出了代价敏感学习,它是机器学习领域十大研究热点之一[5]。至今,众多研究人员提出了许多代价敏感学习算法[6-8]来解决代价敏感问题和类不均衡问题,并在不同研究领域证实了算法的有效性[9-11]。现实应用中的代价主要分为两类:误分类代价和测试代价。其中,误分类代价可分为:基于样本的误分类代价[12]和基于类别的误分类代价[13]。本文的算法主要是在基于类别的误分类代价基础上再引入邻域实现的[14-16]。
邻域在特征选择中有着广泛的应用。文献[17]提出一种基于邻域粗糙集的测试代价属性约简,但其代价设置未考虑与邻域大小的关系。本文利用邻域可以保持样本局部结构的性质,同时引入代价敏感,提出一种新的基于样本邻域保持的代价敏感特征选择算法(Cost sensitive feature selection based on sample neighborhood preserving,CSFN-SNP)。首先,根据邻域保持局部结构的性质得出邻域矩阵[18];其次,引入代价矩阵和样本重要度,在邻域矩阵上计算每个特征的分数,并对每个特征分数使用排序算法进行排序,从而返回特征排序。实验结果表明,提出的代价敏感特征选择算法具有很好的性能。
1 相关工作
在现实应用中,不同的误分类通常会导致不同的误分类代价。现假设有c类数据样本,并且,假设将第i类(i∈{1,2,…,c-1})数据样本误分类为第c类数据样本造成的代价要高于将第c类数据样本误分类为第i类数据样本的代价。基于该假设,将第1类到第c-1类设为“组内”类,将第c类设为“组外”类。根据文献[9],这样的误分类代价可分为3类:
(1) 误识别代价CII:将“组内”类中某一类的数据样本误分类为“组内”类中另一类数据样本产生的代价;
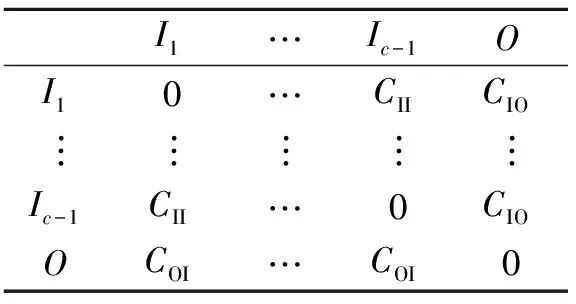
表1 代价矩阵
(2) 误接受代价COI:将“组外”类数据样本误分类“组内”类数据样本所产生的代价;
(3) 误拒绝代价CIO:将“组内”类数据样本误分类“组外”类数据样本所产生的代价。
由常识可知,代价CIO,CII和COI的值一般不相等。令Cost(i,j)(i,j∈{1,2,…,c})为将第i类样本误分为第j类样本的代价,可以构建如表1所示的代价矩阵C。正确预测则没有代价,即对角元素全是0。但在现实应用中,代价矩阵通常由用户或该领域的专家给出。根据代价矩阵,定义函数f(α)来衡量第α(1≤α≤c)类样本的重要度,即
(1)
2 基于邻域的代价敏感特征选择
本节提出了一种基于样本邻域保持的代价敏感特征选择算法CSFN-SNP,该算法是在代价敏感信息的基础上引入邻域,使得每个样本的邻域内存在k个节点的邻接矩阵,并且每个样本的每个特征都在其自己的邻域上讨论,保持了样本的局部结构,可以得到较优的特征子集。

首先对数据集进行正规化处理,其次构造邻域矩阵G={G1,G2,…,Gn},其中Gi表示第i个样本。构造邻域矩阵G有两种方法:(1)K近邻(Knearest neighbor,KNN): 如果xi和xj是K近邻。(2)ε近邻(εneighborhood):如果第i个样本和第j个样本之间满足‖xi-xj‖≤ε。
在实际应用中,第2种方法很少用,因为很难找到一个好的ε。本文使用第1种方法KNN来构造邻域矩阵G。在此基础上再引入代价,第r个特征的CSFN得分Cr(Cr越小越好),即有
(2)
(3)
Cr=Sr-Hr
(4)
式中:定义M={(xi,xj)|xi,xj属于同一类别},C={(xi,xj)|xi,xj属于不同类别};λ为一权重参数,用以调节样本误分类代价矩阵的权重。
本文提出的CSFN-SNP算法的时间复杂度为O(nm2+nc),其算法步骤表述如下。
算法1基于样本邻域保持的代价敏感特征选择
输入:数据集Xn×m,标签Y=[y1,y2, …,yn],参数k和λ
(1) 计算每个样本之间的相互距离,根据邻域的性质,找到每个样本的k近邻(包括样本自己),得到每个样本的邻域矩阵Gi(1≤i≤n);
(2) 根据表1和式(1)分别得出代价矩阵C和样本重要度f(α);
(3) 在每个邻域矩阵Gi的基础上,根据式(4)逐一计算出每个特征的得分Cr(1≤r≤m);
(4) 对得到的Cr进行排序,并返回特征排序,选取前d个特征。
3 算法性能对比实验
3.1实验设置
为了验证本文算法的有效性,将其和现有的代价敏感特征选择算法在UCI数据集上做了相关的对比实验。这8个UCI数据集分别是Heart,Australian,German,Wpbc,Vehicle,Glass,Landsat和Segment。为了准确反映CSFN算法在类不均衡情况下的性能,Vehicle,Glass,Landsat和Segment数据集的类别数是不均衡的。表2给出了数据集的详细信息。所有实验均在MATLAB平台上实现。选取的现有代价敏感特征选择算法包括
(1) Baseline:选择所有的特征。
(2) 基于最大方差的代价敏感特征选择算法(Cost-sensitive variance score,CSVS)[19]:目标是找到组内样本距离样本中心尽可能比组外样本距离样本距离中心近的特征。
(3) 基于约束保持的代价敏感特征选择算法(Cost-sensitive constraint score,CSCS)[19]:利用同一类别样本间距小于不同类别样本间距的特征进行逐一打分。

表2 数据集信息
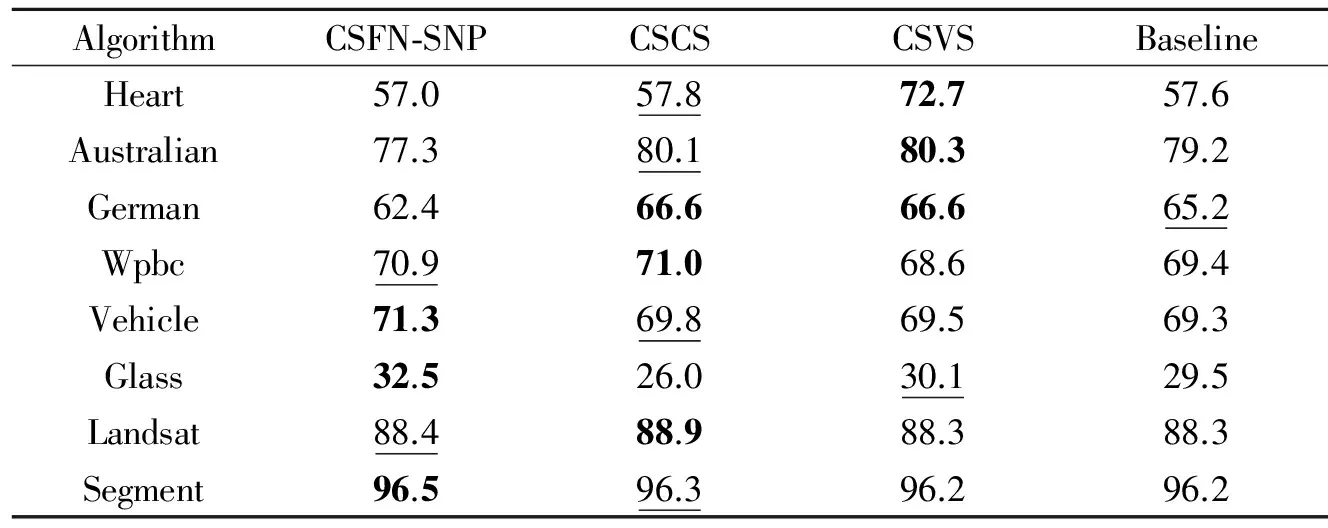
对于算法CSFN-SNP和CSCS,用网络搜索策略来调节参数λ,设定参数集合为{1 000,100,10,1,0.1,0.01,0.001}。CSFN-SNP算法的近邻参数k设置为5。设置CII,COI和CIO的值分别为1,2和20。对选择的特征子集使用1-NN来分类,同时将得到的误分类代价和分类精度作为参考指标。实验结果为5次5折交叉验证结果的平均值。结合特征选择数和参数,将每个算法的最佳实验结果分别在表3和表4中列出,表3列出了最小误分类代价和所对应的特征数,表4列出了分类精度,并且在表3和表4中最佳结果使用粗体来标出,次好的结果用下划线标出,代价旁边括号内表示对应最小代价的特征数。图1显示了4种算法在8个数据集上随特征数变化而得到的误分类代价的对比结果。

表3 不同特征选择算法的误分类代价
表4 不同特征选择算法的分类精度
Tab.4 Accuracy of different feature selection algorithms
%

图1 4种算法在8个数据集上的误分差代价对比Fig.1 Misclassification cost contrast for four algorithoms on eight datasets
3.2 结果分析
从表3可以看出,算法CSCS和CSVS在特征选择时,有较小的误分类代价和与之对应的特征数。而本文提出的CSFN-SNP算法使得每个样本保持局部的结构,可以比CSCS和CSVS算法在8个数据集上获得更小的误分类代价,且CSFN-SNP算法在获得最小误分类代价时所需要的特征数大部分小于CSCS和CSVS算法在达到最优性能时所需的特征个数。结合表3和表4,可以得出误分类代价和分类精度有些关联,但并不是误分类代价越小,分类精度就会越高。说明本文的算法是使误分类代价尽可能小的情况下而得出尽可能高的分类精度,也说明了误分类代价是更重要的评价指标。从表3和图1可以得出,CSFN-SNP与对比算法能较快地选出误分类代价最低时的特征数。
4 结束语
在现实世界中误分类代价一般是不相同的。本文在考虑到误分类代价的同时引入邻域,并且通过邻域保持局部几何结构的性质,提出了基于样本邻域保持的代价敏感特征选择算法CSFN-SNP,引入的邻域矩阵在降维时既能用来保持原始数据的局部几何结构,又能充分利用其类别信息。为了验证该算法的有效性,将其与已有的代价敏感特征选择算法与CSCS,CSVS和Baseline作对比,实验结果表明CSFN-SNP具有更优的性能。下一步工作将同时考虑测试代价和误分类代价,以建立更好的模型应用于实际生活中。
参考文献:
[1]Liu H,Motoda H. Feature selection for knowledge discovery and data mining[M]. Netherlands:Springer Science & Business Media,2012.
[2]Duda R O,Hart P E,Stork D G. Pattern classification[M].New Jersey:John Wiley & Sons,2012:117-120.
[3]Robnik-Sikonja M,Kononenko I. Theoretical and empirical analysis of Relief and ReliefF[J]. Machine Learning,2003,53(1/2): 23-69.
[4]Mitra P,Murthy C A,Pal S K. Unsupervised feature selection using feature similarity[J]. Pattern Analysis and Machine Intelligence,IEEE Transactions on,2002,24(3): 301-312.
[5]Saitta L,Geibel P. Machine learning: A technological roadmap[M]. Netherlands:Department of Social Science Informatics,University of Amsterdam,2001.
[6]Chawla N V,Bowyer K W,Hall L O,et al. SMOTE: Synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research,2002,16: 321-357.
[7]Kubat M,Matwin S. Addressing the curse of imbalanced training sets: One-sided selection[C]∥Proceedings of the Fourteenth International Conference on Machine Learning. Nashville, Tennessee, USA:Morgan Kaufmann,1997:253-259.
[8]Ting K M. An empirical study of MetaCost using boosting algorithms[J]. Lecture Notes in Computer Science,2000,1810:413-425.
[9]Zhang Y,Zhou Z H. Cost-sensitive face recognition[J]. Pattern Analysis and Machine Intelligence,IEEE Transactions on,2010,32(10): 1758-1769.
[10] Zhou Zhihua,Liu Xuying. On multi-class cost-sensitive learning[J]. Computational Intelligence,2010,26(3): 232-257.
[11] Liu Xuying,Zhou Zhihua. Learning with cost intervals[C]∥ Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Washington:ACM,2010:403-412.
[12] Zadrozny B,Elkan C. Learning and making decisions when costs and probabilities are both unknown[C]∥ Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. America San Francisco:ACM, 2001:204-213.
[13] Domingos P. MetaCost: A general method for making classifiers cost-sensitive[C]∥Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Diego:ACM,1999:155-164.
[14] Wang Fei,Zhang Changshui. Label propagation through linear neighborhoods[J]. Knowledge and Data Engineering,IEEE Transactions on,2008,20(1): 55-67.
[15] 徐久成,李涛,孙林,等. 基于信噪比与邻域粗糙集的特征基因选择方法[J]. 数据采集与处理,2015,30(5): 973-981.
Xu Jiucheng,Li Tao,Sun Lin,et al. Feature gene selection based on SNR and neighborhood rough set[J]. Journal of Data Acquisition and Processing,2015,30(5): 973-981.
[16] 叶鑫晶,李洁,王颖,等. 基于边缘邻域的乳腺肿块特征提取算法[J]. 数据采集与处理,2015,30(5): 993-1002.
Ye Xinjing,Li Jie,Wang Ying,et al. Mammographic mass feature extraction algorithm based on edge of neighborhood[J]. Journal of Data Acquisition and Processing,2015,30(5): 993-1002.
[17] Zhao Hong,Min Fan,Zhu William. Test-cost-sensitive attribute reduction based on neighborhood rough set[C]∥ Granular Computing (GrC),2011 IEEE International Conference on. Tsukuba, Japan:IEEE,2011: 802-806.
[18] Yang Yi,Xu Dong,Nie Feiping,et al. Image clustering using local discriminant models and global integration[J]. Image Processing,IEEE Transactions on,2010,19(10): 2761-2773.
[19] Miao Linsong,Liu Mingxia,Zhang Daoqiang. Cost-sensitive feature selection with application in software defect prediction[C]∥ Pattern Recognition (ICPR),2012 21st International Conference on. Kaohsiung, China:IEEE,2012: 967-970.
猜你喜欢
陕西师范大学学报(自然科学版)(2022年3期)2022-06-07
吉林大学学报(理学版)(2020年3期)2020-05-29
自动化学报(2018年7期)2018-08-20
海峡姐妹(2017年12期)2018-01-31
作文与考试·初中版(2017年12期)2017-04-19
电子制作(2017年23期)2017-02-02
周口师范学院学报(2016年5期)2016-10-17
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
中学生(2015年12期)2015-03-01
