
国内外数字文献资源聚合研究现状及述评
2018-04-18 08:04迟海琭内蒙古农业大学图书馆哈尔滨工业大学图书馆
图书馆理论与实践 2018年3期
克 非,迟海琭(.内蒙古农业大学图书馆;.哈尔滨工业大学图书馆)
1 数字资源聚合研究背景扫描
近年来,用户对数字资源的需求向细粒度方向发展,用户关注的是问题的直接解决,而非图书馆提供不同检索途径获得的相关文献。图书馆急需对现有资源进行深度组织和标引,并通过语义网技术和关联数据技术实现资源组织向广度不断拓展、向深度不断延伸。目前,数字资源中最大的一部分是商业数字资源,而各商业数字资源提供商之间的元数据和资源组织方式不同,对图书馆资源聚合和知识服务形成了制约。为此,业内开展了从资源整合、资源的单一维度聚合、资源多维度聚合、资源多维度聚合的有机融合以及资源的深度聚合等相关研究。
对图书馆馆藏各类资源进行组织和标引,对数字资源进行深度挖掘,从大规模数据集中进行知识分析、知识获取、知识挖掘、知识发现、知识创新和知识服务,是当今图书馆数字资源服务的核心。图书馆传统资源服务的不足需要通过数字资源聚合提升图书馆知识组织和知识服务能力,通过数字文献资源聚合实现资源的深度和广度聚合已成为图书馆提供知识服务的必由之路。本研究通过对国内外现有相关文献成果的梳理和分析,在此基础上进行归纳和总结,以期发现国内外数字资源研究的进展及其不足,针对目前研究的不足提出相关对策和建议,为数字资源聚合的相关研究提供新的思路和视角。
2 国内数字资源聚合研究现状
2.1 数据来源及获取
国内研究选择CNKI期刊总库作为基础数据源。为准确和有效地获取相关的文献资源,本研究围绕数字资源聚合及其在实施过程中可能涉及的理论、技术和方法等关键词进行相关文献检索、分析和获取。为了实现此目的,中文文献检索式采用“(SU=聚合)AND(SU=文献资源OR SU=数字资源OR SU=信息资源OR SU=数字文献 OR SU=数据)”,[1]通过专业检索,共检索到172条记录,去除不相关领域的文献和会议通知广告等信息,剩余162条。本研究的数据清洗不同于以往对数据结果的处理方式,而是保留了除上述提到的与本研究明确不相关的文献外的其他相关文献,为资源聚合研究的进一步深入分析奠定基础。按照共词分析的要求,以EndNote格式输出检索结果数据。
2.2 共词频次统计分析
对于不同研究领域的相关研究成果均会有作者著录的关键词。作者提供的关键词对研究成果进行深度揭示,突出研究成果的研究主题、研究方法和研究结果。CNKI对研究成果按学科分类、主题分类、基金分类、期刊分类、期刊类别等进行聚合。共词分析(Co-word Analysis)是通过对反映文献主题内容的关键词进行统计分析,研究文献内在联系和科学结构。[2]对关键词列表、标题、摘要等进行提取,结合研究者的经验在选词个数和词频高度平衡的基础上结合齐普夫第二定律辅助判定高频词。运用共词分析工具对162篇论文关键词进行共词分析,出现4次以上的关键词共20个(见表1)。
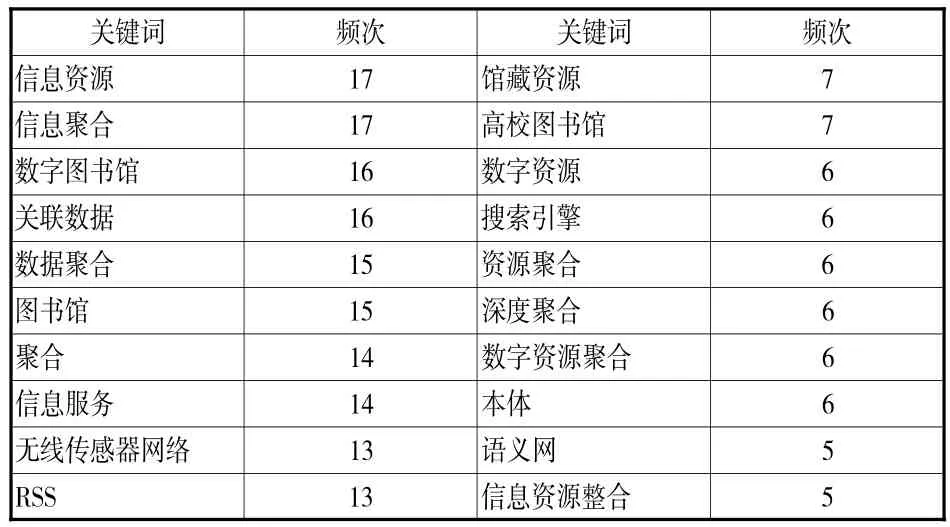
表1 频次大于4的中文关键词分布
通过表1可知,目前在国内资源聚合研究领域,成果较多的是“信息资源聚合”、“信息聚合”、“数字图书馆资源聚合”;运用的方法有“关联技术”、“RSS技术”、“本体技术”和“语义网技术”;资源聚合研究主要集中在“图书馆资源聚合”、“高校图书馆资源聚合”、“馆藏资源聚合”、“数字资源聚合”、“搜索引擎的资源聚合”;在资源聚合研究中“无线传感器网络资源聚合”是关注比较多的,另外关注度较多的是“资源的深度聚合”。
2.3 构建关键词共词图谱
共词分析通过高频主题词共现、关键词共现、作者共现、甚至文献内容的其他标识共现等为研究某学科领域的结构和特点、发现其研究前沿提供支持手段,所有方法均有一个共同的原理,即共现的聚类分析。[3]其原理是对一组词两两统计它们在同一篇文献中出现的次数,在此基础上对这些词进行聚类分析,聚类结果可以反映出这些词之间的亲疏关系,进而分析这些词所代表的学科和主题的结构变化,也就是说选取的词对中,两个词共同出现的频率越高,则这两个词的关联强度越高。通过运用共词软件绘制本研究的共词关系图谱,进一步对本研究的相关成果进行深入分析。在绘制共词关系图谱时,并没有严格按照对频次大于某一特阈值的关键词进行共词分析,而是对所有符合条件的关键词进行共词分析(见图 1)。

图1 相关中文文献关键词共现图谱
从共现关键词图谱结构上看,96个关键词分成了3个较为分明的版块:① 共现集中区域,这一区域的研究成果多,共现关系复杂;② 孤立化呈现区域,这个区域有4个独立的孤立化呈现区域;③ 单个关键词区域,为了图谱的整洁,图1已去处独立化呈现的关键词。这3个版块代表的研究领域的重点不同,对于实际研究拓展具有很好地指导作用。
2.4 共现关键词图谱分析
(1)研究成果较多的领域。现有研究成果较多的集中在图1较小椭圆标注的领域,主要有:“聚合”、“RSS”、“网络信息资源聚合”、“图书馆资源聚合”、“高校图书馆资源聚合”、“馆藏资源聚合”、“数字文献资源聚合”、“资源深度聚合”、“关联数据聚合”、“语义网资源聚合”、“信息聚合”、“数字图书馆聚合”、“信息资源聚合”、“数字文献资源聚合”、“本体聚合”。“无线传感器网络资源聚合”与其他文献共现的次数也比较多,说明目前在该领域的研究中已被相关学者和专家关注,未来可能成为资源聚合研究的一个重要方向。在该领域中节能、能耗、分簇和网络生命周期方向的成果已出现。
(2)分散不成关系的领域。现有研究成果分散没有和资源聚合形成联系的孤岛研究领域主要集中在以下部门。① 海事部门,[4]有关云计算机平台的构建意义和研究方法,如图1左上角可以看出4个关键词两两形成关系,共同组成一个小的研究领域,但是在现有文献中并没有与资源聚合主体文献形成实质联系。说明这一领域的研究也是未来研究的一个方向,在海事领域通过构建云计算平台实现各类资源聚合,并应用到海事业务中。② 通信行业,[5]在图1左上方第2个椭圆标注的是中国联通和互联网发展,说明在通信业务中也开始关注资源聚合,并进行相关研究,以期通过互联网的发展推动通信业务的进程。③ 地理信息,[6]该领域研究也开始关注资源聚合,通过地理信息聚合绘制天地图,从而为旅游服务系统应用,并为旅游业的发展改进创造条件。④ 报网行业,[7]通过报网互动研究聚合非专业性,实现受众参与。可见传统的报纸业也开始关注资源聚合,并通过网络与受众互动,在此期间注意非专业性的聚合,为报网互动提供理论基础和实践指导。
(3)共现未揭示出的领域。虽然通过表1揭示出了共现关键词的主要部分,但是由于受到词频数的限制,一些关键的共现关系并未揭示出来。这些领域主要涉及到如下几个方面。① 数据聚合,在资源聚合研究中,已开始出现细粒度资源聚合的相关文献。这使得资源聚合向深度聚合方向迈进。该领域研究涉及到数据的采集、自组织等。通过图谱发现该领域有两个方向:一个是代表了传统意义上的资源聚合,另一个代表了通信领域的数据聚合,在这两个方向的研究已经形成了关联关系。② 知识发现,资源聚合的目的之一是实现知识发现,不同类型的资源聚合研究领域都或多或少与知识发现形成了共现,如语义、信息聚合、关联数据、信息共享等。③可视化研究,资源聚合结果的展示方式之一就是通过可视化方式呈现揭示出不同研究领域之间的相关关系,为理论研究和实证研究提供线索和思路。④ 社会网络分析,已作为数字资源聚合的方法之一,在资源聚合中被逐渐关注和应用。⑤ 数据采集,作为聚合原料的数据,采用什么方法有效地采集也是研究中比较关注的一个方面。
(4)孤立化呈现的关键词。由于在图谱的制作中没有去掉共现频次较少的关键词,所以在图谱显示中出现了孤立化的关键词,分别是“低利用率文献”、“信息资源聚合”、“南方报业”、“创新”和“媒介”。在以往的研究中更关注的是共现频次较大的关键词,本研究特意关注了孤立化形式呈现的关键词。通过对孤立化关键词的分析,我们可以发现在资源聚合的研究中个别学者对低利用文献进行了关注,试图通过资源聚合的方法提高低利用率文献的利用率。信息资源聚合虽然以孤立化形式呈现,但在实际研究中已设计信息资源聚合,只是尚未在二者之间出现共现的关键词。南方报业的孤立化现象表明了在报业中开始关注资源聚合,试图通过资源聚合的方式更好地开展服务,迎来报业发展的又一个春天。创新和媒介的孤立化呈现表明,有关学者正在研究通过资源聚合实现创业或者媒介需要通过资源聚合进一步创新发展。
2.5 国内研究的主要内容
(1)资源聚合的理论研究。从目前现有研究成果来看,数字资源聚合的基础理论和体系研究较少。毕强等[8]学者从哲学和图书情报学视角探究数字资源聚合的思想和理论基础。从概念聚类、概念关联、知识关联3个层次阐述数字资源聚合方法,构建数字资源聚合的方法体系。以柏拉图、波普尔、布鲁克斯、加菲尔德等人的思想为基础,指出以本体、关联数据、社会网路分析等方法为数字资源聚合研究提供方法支撑的研究,并提出数字资源聚合的科学系统发展需要兼顾理论和方法,同时还要兼顾技术创新、维度扩展、方法深度融合等问题,最终真正将数字资源聚合由理论转向实际应用需要多学科、多领域、多维度、多视角、多方法的交叉融合。余厚强和邱均平[9]指出众多替代计量指标处在离散状态,不利于利益相关者对替代计量学的理解,也使得替代计量研究呈现非系统化特点。构建了学术成果影响力产生模型,发现了不同层次替代计量指标的转化关系,并在每层增加了程度维度,使每个既有替代计量指标在整个分层体系中得到定位。总结了替代指标聚合的3种方法,指出数学处理的聚合强度最高。
(2)资源聚合的方法研究。郭少友和李庆赛[10]通过UMLS语义命题的抽取过程涉及浅层句法分析、概念映射、谓词识别与语义命题生成等环节。两种以UMLS语义命题为基础的医学信息资源聚合方法——用知识单元作为资源单位的聚合方法和用文档关联数据作为资源单位的聚合方法,其聚合结果分别是知识网络和文档网络。邱均平和王菲菲[11]从共现与耦合的理论原理出发,着眼于计量学中共现与耦合方法在馆藏资源聚合中的应用,从4个维角度探讨了典型的八种馆藏文献资源聚合模式,串联了资源与用户之间的整个路径。毕强等[12]在梳理基于语义的数字资源深度聚合研究现状的基础上,引入超网络理论,分析数字资源超网络中的语义关系类型,探讨基于语义的数字资源超网络深度聚合的流程和方法,总结基于语义的数字资源超网络聚合的模式。王丽伟等[13]认为领域本体自身结构的复杂性和领域本体之间的异构性,使领域本体映射方法成为实现本体映射的难点之一。提出多领域本体映射与聚类理论模型,并以该模型为指导,选取药物领域本体进行映射实例研究,提出了两个领域本体之间映射的一种新方法,为数字资源的语义互联提供新思路。
(3)资源聚合的深度研究。刘晓娟等[14]从语义网技术的视角探讨了图书馆数字资源深度聚合对其资源利用的推动力。从本体和关联数据技术出发,探索了图书馆的数字资源与外部资源在语义层次上进行深度聚合的过程,并对现有的数字资源深度聚合工具进行了调研。最后对图书馆数字资源深度聚合所面临的挑战及未来发展方向做了总结与展望。赵蓉英和柴雯[15]以计量分析中的耦合关系为例,探讨了耦合关系的语义特性及其对数字资源深度聚合能力,提出了基于耦合关系的馆藏数字资源语义化聚合模型,并进行实证研究。李劲等[16]针对“信息孤岛”和“资源超载”在当今馆藏数字资源建设中普遍存在的现象,提出了基于语义的馆藏资源聚合模型,更好地满足用户的各种信息需求,进而提高了馆藏资源的利用率。
(4)资源聚合的融合研究。马鸿佳等[17]在对主题词表、本体、关联数据、文献计量、分众分类及社会网络分析法进行特征及优劣势分析的基础上,从方法融合视角对数字资源聚合方法的融合趋向进行了归总,并进一步梳理了方法融合的具体作用机理及应用领域,以拓展数字资源聚合方法融合研究的新方向。王伟和许鑫[18]在方法上综合关联数据聚合与分众分类聚合的优势,取其所长,试图从宏观与微观上全面展现徽州文化数字资源的知识信息。同时在聚合内容上,实现内容来源多元化的徽州文化数据资源的关联数据聚合,展示基于内容的多维度聚合。陈晓美等[19]从资源聚合方法的融合互补入手,在分析社会网络分析和分众分类法资源聚合的优劣势基础上,尝试将社会网络分析和分众分类法结合起来,深入分析了两者融合互补的机理,提出了实现两者融合互补的主要方向。
(5)资源聚合的计量研究。王菲菲和邱均平[20]对计量分析与语义本体进行全面深入的类比分析,进而提出数字文献资源计量语义化理论框架;对基于计量分析的语义化机理与模式进行分解阐述,进一步构建系统化的数字文献资源计量语义化模型,该模型由数字文献资源元数据构建、信息计量与统计分析、计量语义化分析、计量语义知识提取与发现、计量语义化应用五个模块组成,具有易操作多功能、可扩展便推理、互操作广应用等特点。王菲菲[21]从综合发文与引文这两个相互对应的角度,融合作者合作网络分析、作者关键词耦合分析、作者共被引分析、作者文献耦合分析、作者互引网络分析等方法,形成了一种综合视角下的学术共同体与主题结构发现以及作者学术交流与贡献影响力的比较分析框架,然后利用该思路对科学计量学这一领域进行探索研究;实现了科学计量学领域内核心作者所构成的不同层面的研究群体划分以及主题结构发现,并利用社会网络的中心性测度对他们在不同维度的影响力情况和综合影响力进行了规范处理与测度分析,进而得出了该领域最有影响力的作者排序。
3 国外数字资源聚合研究现状
3.1 数据来源及获取
国外研究的数据源选择汤森路透集团的Web of Science平台进行文献的搜集和整理,围绕数字资源聚合及其在实施过程中可能涉及的Theory、Technology和Method等关键词进行相关文献的检索、分析和获取。为了实现这一目的,英文关键词考虑到Aggregation、LinkData、Semantic、KnowledgeDiscovery、Bibliometric等。英文文献检索采用的检索式为“TS=(“aggregation”) and TS= (“ information” or“ resource” or“data”) and TS= (“library”or“ontology”or“semantic*”or“knowledge organiz*”or“knowledge discover*”or“ co-occur*” or“ co-word*” or“ cite*” or“ citing”or“bibliometrics”or“informetrics”or“scientometrics”or“information retrieval”or“topmodel”or“LDA”) and文献类型:(Article)”,共获得核心合集相关文献767篇。本研究对数据的清洗亦不同于以往数据结果的处理,保留了全部检索结果。按照共词分析的要求,按照纯文本(TXT)格式输出检索结果数据。
3.2 共词频次统计分析
Web of Science平台收录的论文中除了由作者提供检索词外,还有汤森路透(Thomson Reuters)对作者的研究成果进行关键词著录,这两类关键词的标注均能揭示文章研究的关键词,重点突出研究对象、研究方法、研究结果和研究领域。通过对关键词的分析可以发现研究的主要结构布局和最重要的主题方向。运用共词分析工具对上述294篇论文进行共词分析(见表 2)。

表2 频次大于5的英文关键词分布
3.3 构建关键词共词图谱
在绘制共词关系时,未严格按照对频次大于某一特定值的关键词进行共词分析,而是对所有符合条件的关键词进行共词分析(见图2)。

图2 相关外文文献关键词共现图谱
共现关键词的网络结构图谱从结构上看,96个关键词分成了3个较为分明的版块,分别是:主要集中区域,这一区域的研究成果多,共现关系复杂;较少关注区域,这个区域有2个独立的孤立化呈现区域;独立出现的关键词。这3个版块代表的研究领域不同,对于实际研究具有很好地指导作用。
3.4 共现关键词图谱分析
(1)研究成果集中的领域。现有研究成果较多的主要集中在如图2椭圆标注的领域,这个领域的研究中涉及的关键词有:“aggregation”(聚合)、“theory”(理论)、“web”(网络)、“data”(数据)、“knowledge”(知识)、“ontology”(本体)、“information retrieve”(信息检索)、“semantic”(语义)、“rank aggregation”(等级聚合)、“meta search”(元数据搜索)等。通过分析这些关键词,发现目前国外对于资源聚合研究较多的集中在“资源聚合的理论”、“网络资源聚合”、“数据聚合”、“知识聚合”、“知识发现”,资源聚合的方法主要有本体资源聚合方法、语义资源聚合”、“数字资源的等级聚合”,还有对资源聚合的“信息检索”、“元数据检索”等领域。在这些领域国外的研究成果较多,研究也相对成熟。数字资源聚合研究在国外注重理论和实践两个方面的研究,并取得了一定的成果,在实践中也有了相关的应用。
(2)研究成果分散的领域。通过英文关键词共现图谱可知,国外相关研究除了集中在上述研究领域外,在以下领域也开展了研究,研究成果相对于集中研究区域较少,分别是:“link data”(关联数据)、“acut coronari syndrome”(急性冠状动脉综合征)、“heart disea”(心脏病)、“antiplateletag”(抗血小板)、“myocardi revasular(心 肌 救 护)、“arrhythmiacardiac”(心律失常)、“drug therap”(药物治疗)、“anticoagul”(抗凝)、“coronary angiographi”(冠状动脉造影)、“antiplateletag”(抗血小板聚集)、“coronari arterirevascular interventst”(科伦纳动脉介入术的ST)等,这一区域的研究集中在医学领域,目前在国外的相关研究中,医学领域研究成果已集中了一定的规模,并与资源聚合形成了关联关系。另外一个领域是蛋白的空间聚合。在国外相关研究中,资源研究的领域已有进一步拓宽。
(3)未揭示出的研究领域。虽然通过表2揭示出了共现关键词的主要部分,但是由于受到词频数的限制,一些关键的共现关系并未揭示出来。这一研究领域主要的关键词有:“digital library”(数字图书馆)、“cloud computer”(云计算)、“wireless sensor network”(无线传感器网络)、“textmin”(文本挖掘)、“map” (知识图谱)、“web server”(网络服务)、“semantic similar”(语义相似)、“datamining”(数据挖掘)、“cluster”(聚合)、“focus retrieve”(聚焦检索)、“retrieve”(检索)、“perform”(表现)、“relative database”(检索数据库)、“search”(检索)、“evaluation”(评价)、“operation”(操作)、“hierarch structure”(等级结构)、“micro aggregation”(微聚合)、“language”(语种聚合)、“SmartWeb”(智能网)、“Retrieve”(检索)等。其中,“wirelesssensornetwork”(无线传感器网络)和中文文献中的研究相一致,但是研究成果同样较少。
(4)孤立化呈现的关键词。由于制作图谱的过程中,并没有去掉共现频次较少的关键词,所以在图谱显示中出现了孤立化的关键词,这些领域主要涉及到“algebramultigrid”(代数多重网格)。在未来数字资源聚合的研究中有可能采用代数多重网格方法对资源进行聚合。
3.5 国外研究的主要内容
(1)资源聚合的理论研究。P.Kokkinos等[22]认为信息聚合是一种减少网格中信息的交换,便于资源管理和决策应用。当资源可被公共获取时,可通过遍历各个节点摘取详细和敏感信息保存为私有信息。为了解决网格聚合的相关问题,设计了通用的信息聚合框架,提出了单点聚合和域聚合的关于静态和动态信息资源的网格规则的主导技术,并讨论了资源优化和选择功能。聚合框架的测量是既通过对执行决策的效率和又通过减少它带来的信息数量,并全面权衡。通过仿真证明合适的聚合框架可以显著地减少信息和网格中信息交换。Vodel等[23]指出网络产生大量的异构数据在动态变化的多通道无线传感器中传输,特别是在无线低功耗的应用领域,能源效率和通信任务的优先级是关键。通过研究优化各自的硬件组成以及在物理层协议,MAC或网络层处理这些问题。解决的关键是尽量减少数据传输量,同时又不降低信息质量,在数据融合领域提供了一个有效的数据处理技术。根据研究结果和相应的分析,提出了切实可行的数据聚合技术。
(2) 资源聚合的方法研究。VíctorFernáandez等[24]指出大数据狄拉克(DIRAC)是一种用大数据解决分布式基础设施的远程代理控制接入点。用户可以获得分散不同区域的大数据资源,通过运用狄拉克实现负载平衡。结果显示了大数据狄拉克具有管理储存在本地的Hadoop簇的系统文件的能力。大数据狄拉克可被用于收集可行性统计数据和执行的监控,从远程上传文件到Hadoop系统,结果存储在机器中。大数据狄拉克可以有效地聚合资源。Kyungyong Lee等[25]提出了广域资源发现的匹配树方法。这种方法是建立在对等框架基础之上,以提供可扩展和容错资源发现。匹配树方法利用一个自组织树实施分布查询处理和结果聚合。匹配树本身相关的资源发现系统基于结构化的P2P,支持复杂的查询(如匹配正则表达式),以及相关的非结构化P2P发现系统保证查询的完整性。Hanane Zitouni等[26]提出了关于角色学习方法。该方法结合了协同过滤和电子学习的特点。一方面,当没有明确的角色偏好基础数据时,利用社区角色兴趣聚合做一个初步的推荐。另一方面,借助于已有的基础,通过元数据的描述对新学习资源进行推荐,其方法是通过计算的新资源的元数据和原有资源的元数据相似度来判断角色感兴趣的新资源,并进行推荐。
(3)资源聚合的效果研究。L.Canósa等[27]开发了一个柔性化的决策支持系统帮助管理者对用户不同需求的决策定制功能。这一数据决策系统模仿专家使用平均顺序权重方法,按照不同权重实现不同选择标准的聚合操作,展示了一种基于按侯选项排序分析效率的聚合模型。P.Kokkinos等[28]提出了一种通过任务调度实现相关信息资源聚合方法。通过这种方法,可以统一表示一组资源的信息,同时减少在网格网络中传输的信息量。描述了属于同一层次的网格域的一系列信息资源聚合的技术。这些信息包括存放在中央处理器的存储容量、队列的任务数,以及其他资源的相关参数。聚合方法的质量会影响调度程序决策的效率。当任务执行时使用完整的资源信息,当任务延迟时,使用聚合方案。仿真实验表明,所提出的聚合方案大大地减少了信息传输。
(4)资源聚合的过程研究。Gang Li等[29]针对无形网络中有的大量有价值的信息资源存在却难以使用的现状,提出了一种称为收割消息的系统,这是能够使看不见的网络变得可见,尤其是对于大量更新频繁、时间敏感的实时信息。收割的方法是利用信息提取、文本分类、全文索引、RSS技术等聚合无形的网络信息资源。分析了四种类型的无形网无形的原因,同时总结了无形网的特点。在此基础上,建立了信息收割的结构体系。用校园招聘信息与通用搜索引擎测试相比验证系统。随着Web 2.0的兴起,用户生成的元数据或所谓的大众分类便于万维网管理数字内容。Ching-Chieh Kiu等[30]提出的分类和分众分类算法有利于提高知识分类和导航。
(5)资源聚合成本的研究。Anass Nagih等[31]提出在资源消耗限制条件下寻找指定节点之间最小成本的路径。用动态规划算法求解其计算时间,计算时间随资源数量的增加而增加。为此提出了一个启发式解决方案,通过聚集资源的目标以减少状态空间。Joel Cummings[32]通过EBSCO学术搜索对得到的菲沙河谷大学学院获取全文内容的两类全文列表比较研究。因为在菲沙河谷大学学院的工作人员和图书馆用户依赖于这个数据库的一部分馆藏期刊,所以这项研究是比较全文内容的准确性。检查馆际互借工作人员经常使用学术搜索全文杂志列表是否可在学院的电子表格中获取。从而发现从馆际互借成本角度考虑,需要一个精确的图书馆电子期刊补充列表。
4 国内外数字资源聚合研究述评
从国内外相关研究成果的总体情况来看,与数字资源聚合直接相关的研究比较少。国外相关的研究最早起源于Bordogna G[33]提出一种软化的硬布尔方案的信息检索方法。在这种方法中,信息检索是其中潜在的解决方案,即满足条件的多准则决策活动,存档的文件等都要求通过表达式检索。每一个潜在的解决方案满足由运营商汇总的信息需求汇总查询具有整体的决策功能评估。语言量词和连接器处理原发和可选的标准定义,并介绍了为查询语言指定的单个查询聚集标准要求。这些标准使得用户可以用简单的和自我解释的方式来表达疑问。国内研究起源于何超和张玉峰[34]针对馆藏数字资源深度开发与利用所存在的数字资源孤岛问题和数字资源超载问题,构建了基于本体的馆藏数字资源语义聚合与可视化模型。该模型利用本体提供的语义知识进行深层次的馆藏数字资源语义聚合,解决数字资源孤岛问题和数字资源超载问题;利用本体软件提供的可视化插件将非空间数据转换为视觉形式进行聚合结果展示,揭示馆藏数字资源内部存在的错综复杂关联和深层次内涵,加深馆藏数字资源聚合结果的认知和理解。从国内外的相关研究可以总结为以下几个方面。
4.1 理论研究与应用研究
国内外对于数字资源聚合研究的理论已向数据收集、信息整合、资源聚合和知识发现理论研究拓展。国外的相关研究主要集中在本体、语义数据、网络、关联数据、等级聚合、元数据检索、聚合模型、聚合安全、等级结构、决策支持、语义网、不同语种间聚合、聚合结果、知识发现、数据聚合、信息检索、模糊语言模型、聚合实验、实证研究和各类系统,这些领域涉及到了数字资源聚合的各个方面,有理论、方法、应用等。国内的研究主要集中在信息聚合、图书馆、网络信息资源、高校图书馆、馆藏资源、RSS、数字图书馆、信息资源、语义网、本体、可视化、数字资源聚合、信息可视化、数据聚合、深度聚合、关联数据、知识发现等。从国内外研究关注点来看各有不同,国外研究关注的范围比较宽,国内研究关注的比较窄,但是都采用了关联数据、本体、语义网等作为主要技术。值得一提的是,无论国内还是国外都在关注无线传感器网络的资源聚合。[35-36]
4.2 研究领域与应用领域
国外涉及的领域主要有生物领域和医学领域,并且在这两个研究领域的成果相对较多,两个领域的各自成果之间的关键词共现与耦合关系也比较明显。国内的相关研究领域主要是集中在图书情报档案等文化服务领域,随着这一主体领域研究成果的不断丰富,理论体系不断完善,应用不断扩大,在海事部门、通讯部门、地理信息旅游业部门和报网行业引入了相关研究。[37]但是这几个领域的研究比较分散,他们没有与研究主体形成实质上的关联关系,而且各自小领域的研究成果也不是很多。这一现象说明国内对于资源聚合的研究已渗透到多个领域,比国外的领域要广泛,但是没有国外研究成果丰富。从这点可以看出数字资源聚合的研究领域可以不断拓展,特别是领域本体、关联数据和语义网技术在不同领域的应用为领域应用资源聚合奠定了技术基础。总体来看国外的相关研究应用比国内要成熟一些。
4.3 宏观研究与微观研究
从国内外相关研究总体涉及的关键词词频、研究领域范围的广度等可以发现,国内外研究的侧重点有所不同。国内研究注重于微观对象的特性研究,研究数字图书馆或高校图书馆馆藏资源聚合的比较多,对于网络资源聚合研究的比较少,这与目前国内数字资源提供和利用情况密切相关。国外研究涉及的面比较广泛,更接近于普适研究和宏观研究,这与国外开展相关研究较早有密切关系。而国内相关研究是从2011年国家社科基金重大项目立项前后才开始进行的。从总体上看,国外研究具有分散集中的特点,在某个主题研究的比较深入,对于不同研究主题关联关系的揭示较丰富,突出了数字资源聚合研究的深度延伸和广度拓展的趋向。国内研究集中的主题比较少,其他主题与集中主题的关联关系并不丰富和密切。但是研究的目的和所采用的方法具有共同点。
4.4 研究方向的发展趋势
综观国内外相关研究可以发现,国内外积累了许多经验,并取得了丰富的研究成果,但是研究理论体系尚不完善、理论和应用结合还不够深入。目前,相关研究更多的聚焦在聚合的途径和方法,对于聚合的结果处理以及可视化展示研究明显不足;对于相关研究的实践应用还停留在小范围内的应用,并没有形成大范围的推广;国内的数字资源来源渠道复杂,数据冗余量大,民族文献数字化识别处理的复杂性等要求加剧了相关研究的难度。为此,数字资源聚合应从以下几个方面进一步展开:① 理论研究,力求形成完整的理论体系;② 实证研究,进一步加强理论与实践的结合研究,理论与应用的结合研究;③ 深刻理解和有效把握影响资源聚合的相关因素,如:资源聚合阻力、聚合摩擦、聚合粘度、聚合强度、聚合深度和聚合噪声、聚合污染等。
[参考文献]
[1]邓君,陈丽君.国内外图书馆开源软件研究现状与展望[J].图书情报工作,2015(14):135-142.
[2]王飒,包丽颖.基于文献计量的共词分析方法及应用述评[J].情报科学,2015(4):150-154.
[3]王小华,等.基于共词分析的文本主题词聚类与主题发现 [J].情报科学,2011(11):1621-1624.
[4]黄祖良.构筑平台借外力借助外力保安全:江门海事局聚合社会资源解决海事监管难题[J].珠江水运,2009(11):56-57.
[5]高弋坤.联通移动互联应用产业峰会主打”开放牌”“Wo+开放体系”首次亮相谈聚合[J].通信世界,2011(44):4.
[6]宋关福.Service GIS引发地理信息服务共享与聚合革命[J].地理信息世界,2008(6):82-85.
[7]汤代禄,韩建俊.基于报业信息网格的新闻信息聚合与挖掘[J].中国传媒科技,2005(10):27-30.
[8]毕强,等.数字资源聚合的理论基础及其方法体系建构 [J].情报科学,2015(1):9-14,24.
[9]余厚强,邱均平.替代计量指标分层与聚合的理论研究[J].图书馆杂志,2014(10):13-19.
[10]郭少友,李庆赛.以UMLS语义命题为基础的医学信息资源聚合[J].图书情报工作,2014(3):99-105.
[11]邱均平,王菲菲.基于共现与耦合的馆藏文献资源深度聚合研究探析[J].中国图书馆学报,2013(3):25-33.
[12]毕强,等.基于语义的数字资源超网络聚合研究 [J].情报科学,2015(3):8-12.
[13]王丽伟,等.领域本体映射的语义互联方法研究——以药物本体为例[J].图书情报工作,2013(17):21-25,33.
[14]刘晓娟,等.语义网技术在图书馆数字资源深度聚合中的应用[J].图书馆杂志,2015(6):76-82.
[15]赵蓉英,柴雯.基于耦合关系的馆藏数字资源语义化深度聚合研究[J].情报资料工作,2015(2):52-55.
[16]李劲,等.基于语义的馆藏资源深度聚合方法研究[J].情报科学,2013(11):100-103.
[17]马鸿佳,等.数字资源聚合方法融合趋势研究[J].情报资料工作,2015(5):24-29.
[18]王伟,许鑫.融合关联数据和分众分类的徽州文化数字资源多维度聚合研究[J].图书情报工作,2015(14):31-36,58.
[19]陈晓美,等.社会网络分析法与分众分类法融合机理研究 [J].情报资料工作,2015(5):11-17.
[20]王菲菲,邱均平.信息计量视角下的数字文献资源语义化模型研究[J].情报资料工作,2015(4):62-69.
[21]王菲菲.发文与引文融合视角下的科学计量学领域核心作者影响力分析[J].科学学与科学技术管理,2014(12):45-55.
[22] Kokkinos P,Varvarigos E.Scheduling efficiency of resource information aggregation in grid networks[J].Future Generation Computer Systems,2012 (28) :9-23.
[23] VodelM,HardtW.Dataaggregation and data fusion techniques inWSN/SANET topologies-a critical discussion[C].IEEE Region 10 Conference(TENCON)-SustainableDevelopmentthrough Humanitarian Technology,2012:19-22.
[24] Víctor Fernández,et al.Federated big data for resource aggregation and load balancing with DIRAC[J].Procedia Computer Science,2015 (51):2769-2773.
[25] Kyungyong Lee,etal.Match tree:Flexible,scalable,and fault-tolerantwide-area resource discovery with distributed matchmaking and aggregation [J].Future Generation Computer Systems, 2013 (29):1596-1610.
[26] HananeZitouni,LlamiaBerkaniandOmarNouali.Recommendation of learning resourcesand usersusingan aggregation-based approach[C].2012 IEEE Second InternationalWorkshop on Advanced Information SystemsforEnterprises,2012:57-63.
[27] Canósa L,Liernb V.Softcomputing-based aggregation methods for human resourcemanagement[J].European JournalofOperationalResearch,2008 (189):669-681.
[28] KokkinosP,VarvarigosE.Resource information aggregation in hierarchicalgrid networks[C].9th IEE E/ACM InternationalSymposium on Cluster Computing and theGrid,IEEEComputerScience,2009:268-275.
[29] Gang Li,GuangzengKou.Aggregation ofinformation resourceson the invisibleweb[C].Second International Workshop on Knowledge Discovery and Data Mining,IEEEComputerSociety,2009:773-776.
[30] Ching-Chieh Kiu,Eric Tsui.Taxo folk:A hybrid taxonomy folksonomy structure for knowledge classi fication and navigation [J].Expert Systemswith Applications,2011 (38):6049-6058.
[31] AnassNagih,FrancζoisSoumis.Nodalaggregationof resourceconstraintsinashortestpath problem [J].European Journal of Operational Research,2006,172(2):500-514.
[32] Joel Cummings.Full-Text aggregation:An examinationmetadata accuracy and the implications for resourcesharing[J].SerialsReview,2003,29(1):11-15.
[33] Bordogna G,Pasi G.An ordinal information retrievalmodel[J].International JournalofUncertainty Fuzzinessand Knowledge-based Systems,2001,9(S):63-75.
[34]何超,张玉峰.基于Web链接挖掘的馆藏资源语义聚合与可视化展示研究[J].情报科学,2015(2):115-120.
[35]张强,等.基于分簇的无线传感器网络数据聚合方案研究[J].传感技术学报,2010(12):1778-1782.
[36]叶宁,王汝传.基于蚁群算法的无线传感器网络数据聚合路由算法[J].南京邮电大学学报(自然科学版),2008(2):63-68.
[37]刘菲,杨兴锋.南方报业的聚合战略[J].新闻与写作,2011(4):49-50.
猜你喜欢
军事文摘(2022年17期)2022-09-24
北京航空航天大学学报(2022年8期)2022-08-31
家庭影院技术(2021年8期)2021-11-02
开放教育研究(2020年2期)2020-03-31
计算机世界(2020年50期)2020-01-15
青年生活(2019年23期)2019-09-10
图书馆建设(2018年5期)2018-07-10
档案管理(2017年5期)2017-09-07
合作经济与科技(2017年9期)2017-05-12
中国修辞(2017年0期)2017-01-31
