
相同敏感值数据集的隐私保护泛化算法
2018-05-10 02:17郑明辉吕含笑段洋洋
郑州大学学报(理学版) 2018年2期
郑明辉, 吕含笑, 段洋洋
(湖北民族学院 信息工程学院 湖北 恩施 445000)
0 引言
随着网络信息与技术的高速发展,社会和网络中的信息逐渐朝着信息共享与资源互利的趋势发展.数据挖掘在近几年的大数据背景下不断升温,各机构尽最大可能收集用户的信息,并从中挖掘关键内容,这导致了用户隐私信息的泄露[1],尤其是家庭住址、医疗信息、工作情况等重要信息.因此,亟待数据发布前的保护,以避免链接攻击导致个人隐私泄露.文献 [2]提出k-匿名模型,通过对数据集中的属性进行隐匿的泛化操作,使相互可区别的元组匿名成k个不可区分的元组,以此达到攻击者无法使用多表链接出个体隐私的目的.该模型易于理解且实用性强,因此在应用中不断被优化.已有的研究成果主要包括:使敏感值多样化分布在等价类的l-多样性模型[3]与t-closeness模型[4];根据敏感度划分等价类的(p,a)-sensitivek-匿名模型[5];避免偏度攻击的(n,t)-proximity模型[6];避免同质性攻击[7]的(C,L)-多样性模型[8];避免相似性攻击的(l,e)-diversity模型[9]等.目前还出现了抗背景知识攻击、语义攻击等的k-匿名模型研究,并开始在位置服务领域、社交网络领域、智慧医疗、电力系统等方面对k-匿名模型进行应用[10].另外,如何度量算法的有效性也是数据隐私保护的主要研究内容.文献[11]将匿名转化率作为信息损失的度量,以此计算数据质量.文献[12]提出了一种度量轨迹数据隐私风险的模型,通过计算敏感状态先验概率与后验概率之间的差值,评估轨迹还原造成的隐私泄露程度.
通过分析发现,以上研究并非建立在2个数据表的实际链接之上,而是将其中一个链接数据表抽象为攻击者,其原因在于微数据表中的敏感属性值不完全相同,链接攻击可被简化为已知某些个体存在于微数据表中的攻击者意图获取这些个体敏感信息的过程.因此,传统k-匿名技术研究的重点是对含不同敏感属性值的数据进行隐私保护.事实上,同质性攻击是一种因敏感值相同而出现的攻击方式[13-14],k-匿名方案对该攻击的防御常常依靠其他敏感值嵌入其中以干扰攻击者,并没有从根本上解决针对相同敏感值数据的攻击问题.文献[15]指出k-匿名技术在对相同敏感值数据集进行泛化时易出现过度保护或欠缺保护.为弥补该缺陷,文献[16]提出了一种基于二元递归决策划分的泛化算法(以下简称“决策泛化算法”),用于对相同疾病的数据集进行泛化保护,提高了泛化后数据的安全性,但其关注的隐私泄露风险较单一.本文在完善泄露风险计算的基础上,提出了2种具有不同等价类划分标准的新泛化算法,构造出具有最小隐私泄露风险,数据可用性较强,且具有有效迭代停止标准的算法;并根据泛化后数据集的等价类数量、隐私泄露风险等内容评价各泛化算法的优势,从而选取最优的泛化算法作为相同敏感值数据表的泛化保护方法.
1 相同敏感值条件下的隐私泄露风险
本节将以医疗数据为应用场景,给出相同敏感值条件下的数据隐私泄露定义和隐私泄露风险的计算方法.
1.1 传统的隐私泄露
k-匿名技术关注的数据隐私泄露有身份泄露和属性泄露两种.目前,k-匿名技术基本上能抵御身份泄露,但是敏感属性值的多样性使得属性泄露不易被解决.因此,仍会出现隐私保护不到位的情况.另外同质性攻击、相似性攻击等都是因敏感值相同、敏感度相似而发生的攻击形式,在多样化敏感值数据表中可利用敏感值的不同分布来抵御这种攻击,在相同敏感值条件下尚不能有效地解决该问题.
1.2 敏感值条件对隐私泄露的影响
1) 实例多属性泄露
同质性攻击的原理是攻击者已知某个体恰好存在于敏感值相同的等价类中,则攻击者可直接获知该个体的敏感值信息.而在相同敏感值数据表中,无法以目标个体存在于该表中为前提进行属性值匹配链接,对攻击者而言只能依靠多表链接进行攻击.
实际上,攻击者的目的不仅局限在获取个体的敏感信息.以患者疾病数据为例描述以下攻击场景:表1为患者的联系方式数据,表2为患者的疾病微数据(为便于对比不同/相同敏感值,微数据表中同时出现相同疾病(S-disease)和不同疾病(Dif-disease)),关注表2中相同疾病的情况.若攻击者将2个数据表进行链接,不仅能确定Brown、Smith、Stone、Green和Miller同患一种疾病,并且能获知他们各自的电话信息.为区别“属性泄露”,本文对相同敏感值数据集在链接攻击中产生的额外属性泄露定义为“实例多属性泄露”.

表1 患者的联系方式数据

表2 患者的疾病微数据
定义1在含相同敏感值的微数据表和对应的去识别化的信息表中,链接出一个元组并获取该元组在信息表中的其他属性信息,称为“实例多属性泄露”.
2) 实例完全泄露
将表2的准标识符属性泛化至满足3-匿名标准,表3为满足3-匿名的疾病微数据,其包含两个等价类,ID为1、2、3的元组为等价类1,ID为4、5、6的元组为等价类2.
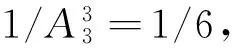
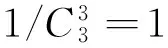

表3 满足3-匿名的疾病微数据
定义2微数据集泛化后,每个等价类的所有元组在信息表中被攻击者同时识别出隐私信息,称为“实例完全泄露”.
从表4可以看出,相同疾病敏感值数据集在链接攻击中的泄露风险值大于不同敏感值的数据集.因此,对相同敏感值数据集进行发布前的隐私保护非常重要.

表4 不同场景的隐私泄露风险值
1.3 相同敏感值条件下泄露风险的计算
1) 实例多属性泄露风险的计算
在相同敏感值的微数据表和对应的信息表中,第i个等价类中每条元组产生的多属性泄露风险为
ri=ni/Ni,
(1)
式中:ni为泛化后疾病微数据表中第i个等价类中元组的个数;Ni为泛化后患者信息表中第i个等价类中元组的个数.
实例多属性泄露并不意味着攻击者将微数据表中第i个等价类中的所有元组以概率ri识别出来,而是信息表中某个体被察觉到存在于疾病微数据表中的概率.即从信息表的第i个等价类中任意选取ni条元组,其中至少有一人的敏感信息被泄露,概率为ri.当两组等价类出现r1=r2这种特殊情况时,这两组等价类的隐私泄露程度是否一样还需要更多的参数来说明.
2) 实例完全泄露风险的计算
由于实例多属性泄露风险只能对一条元组的泄露情况进行描述,无法从微数据表被隐匿泛化后的整体角度描述隐私泄露的情况.尤其当r1=r2时,这2个等价类中所有元组的实例完全泄露风险却常常不同.在这种特殊情况下,如何判断微数据表的泛化效果,就需要实例完全泄露风险来衡量.
在泛化后的相同敏感值微数据表中,第i个等价类中所有元组同时泄露的风险为
(2)
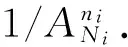
在上述有关患者数据集的攻击场景中,攻击者的目的在于只需要知道某个联系方式的所属者患有某疾病,不需要清楚地识别患者的身份.所以在相同疾病的情况下,尽可能让攻击者获取到患者的疾病信息与联系方式的概率更小才更加安全.由于相同敏感值条件下的实例完全泄露风险明显大于以往研究关注的不同敏感值数据集,故针对相同敏感值数据集进行隐私保护以降低实例完全泄露风险的研究意义重大.
2 降低隐私泄露风险的泛化算法设计
为了避免含相同敏感值的数据在发布后受到链接攻击产生的隐私泄露过多,需要在数据发布前对其进行泛化保护.泛化是一种将数据分类后对其进行隐匿或抑制的操作,使其与同一等价类的数据具有不可区分性.泛化后的数据虽然不能完全抵御链接攻击、背景知识攻击导致的泄露,但却可以减少相应攻击下的隐私泄露.
本文提出2种泛化算法,将实例多属性泄露风险作为算法中等价类的划分标准,以降低实例多属性泄露风险和实例完全泄露风险为目标对数据集进行泛化.一方面完善决策泛化算法中的停止标准,另一方面通过采取不同的等价类划分标准,从数据集被泛化后的结果,分析划分标准对算法达到的不同隐私保护效果.
2.1 参数符号及其含义
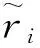
2.2 算法1
需要患者疾病微数据表D,患者联系方式信息表C,且已知D集合中的患者一定在C集合中,2个集合有d个公共准标识符属性.
步骤1: 按照升序或降序的排序方法,把d中的每个属性值进行排列.并在每一个属性j中,在相邻的值之间进行一次试验划分;
步骤5: 对D集合已经划分出来的2个集合再进行步骤2~4的重复,直到一个待划分的集合当前的实例完全泄露风险大于或等于划分后的实例完全泄露风险,停止对该集合的划分.同理,其余待划分集合以此作为停止循环划分的标准.
2.3 算法2
在对集合进行等价类划分的过程中,可以采用不同的标准进行.因此,本方案提出第2种划分标准,将2种划分标准与决策泛化算法的划分标准通过实验进行对比,从而选取最优化的算法作为相同敏感值数据集的泛化方法.
算法2与算法1的区别体现在步骤2中,在计算D中每次划分得到的2个等价类实例多属性泄露风险ri1与ri2后,选择max{ri1,ri2},然后再选择min{max{rii,ri2}}.最小的max{ri1,ri2}值所对应的属性中的值,在此处进行D集合的“最佳试验划分”.后续过程以此类推,其他步骤同算法1.
3 实验仿真
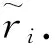
3.1 实验结果分析
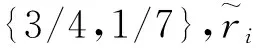
从等价类的数量来看,等价类越多则数据集的元组泛化程度越低,即数据质量的损失越少.算法1的等价类略多于算法2,在数据可用性方面表现较好.从实例多属性泄露风险的角度来看,算法1的风险值上下波动明显,下限虽然小,但是上限值却很大,数据集在泛化后的平均泄露风险也会较大;算法2的风险下限虽略大于算法1,但是最大风险值只有1/2,能良好控制整个数据集的泄露风险.从实例完全泄露风险角度来看,算法2的风险值上下限均明显小于算法1.

表5 3种算法的实验结果
3.2 本方案与决策泛化算法的结果对比
本文对决策泛化算法进行了模拟(由于原算法中没有明确指出迭代的停止标准,故按本方案的停止标准进行实验).从实验结果来看,3个算法的等价类数量都比较接近,算法1从等价类数量上更优化;实例多属性泄露风险的下限值是接近的,但从避免攻击者成功窃取隐私信息的角度来看,希望该风险的上限更小,因此算法2优于其他两种算法;算法2在实例完全泄露风险上的表现也比较突出,所以算法2的结果总体上更有说服力.另外,3种算法使同一数据集的元组均满足2-匿名标准,产生该结果的原因还有待具体分析.
同决策泛化算法相比,本文的2个算法在计算复杂度方面只改变了划分等价类时的泄露风险计算方式,算法其他部分的复杂度相同,泄露风险计算方式的不同并未改变算法的复杂度;算法停止条件的约束会减少决策泛化算法实际划分的次数.因此,本文的泛化算法复杂度不大于原算法.
4 结论
仿真结果表明,算法2的数据可用性较高、实例多属性泄露风险上限最小且实例完全泄露风险最小,为最优算法.在实验结果中发现,这3种算法对数据集泛化后,其等价类中包含的元组数量符合2-匿名标准,表明对于相同敏感值的数据隐私保护也可以满足k-匿名要求,但其原因还需进一步的研究.当遇到数据量过大时,等价类划分标准存在计算困难的问题,如何解决该问题也是未来需要继续研究的.另外,如果能有更全面的关于算法安全性和有效性的评估模型对本文进行评估则会更加完善,后续拟从信息熵的角度继续深入研究泛化后数据集防御链接攻击的表现以及计算数据表的数据质量损失.
参考文献:
[1] 冯登国, 张敏, 李昊. 大数据安全与隐私保护[J]. 计算机学报, 2014, 37(1):246-258.
[2] SWEENEY L.k-Anonymity: a model for protecting privacy[J]. International journal of uncertainty, fuzziness and knowledge-based systems, 2002, 10(5):557-570.
[3] MACHANAVAJJHALA A, GEHRKE J, KIFER D, et al.l-Diversity: privacy beyondk-anonymity[C]//Proceedings of the 22nd International Conference on Data Engineering. Atlanta, 2006:24.
[4] LI N, LI T, VENKATASUBRAMANIAN S.t-Closeness: privacy beyondk-anonymity andl-diversity[C]//Proceedings of the 23rd International Conference on Data Engineering. Istanbul, 2007:106-115.
[5] WANG Q, ZENG Z P. (p,a)-Sensitivek-anonymity:privacy protection model[J]. Application research of computers, 2009, 26(6):2176-2177.
[6] PRAKASH M, SINGARAVEL G. A new model for privacy preserving sensitive data mining[C]// Third International Conference on Computing Communication and Networking Technologies. Coimbatore, 2012:1-8.
[7] LEFEVRE K, DEWITT D J, RAMAKRISHNAN R. Incognito:efficient full-domaink-anonymity[C]//Proceedings of the ACM SIGMOD International Conference on Management of Data. Baltimore, 2005:49-60.
[8] YI T, SHI M Y, SHANG W Q, et al. Graded medical data publishing based on clustering[C]//Proceedings of the 12th International Conference on Fuzzy Systems and Knowledge Discovery. Zhangjiajie, 2015:1647-1652.
[9] WANG H Y, HAN J M, WANG J Y, et al. (l,e)-Diversity:a privacy preserving model to resist semantic similarity attack[J]. Journal of computers, 2014, 9(1):59-64.
[10] 许长清, 赵华东, 宋晓辉. 基于大数据的电力用户群体识别与分析方法研究[J]. 郑州大学学报(理学版), 2016, 48(3):113-117.
[11] 王伟, 郭献彬. 一种增强的匿名化隐私保护模型[J]. 信息通信, 2016(1):1-4.
[12] 彭瑞卿,刘行军,用户的行动轨迹还原与隐私风险度量[J].武汉大学学报(理学版),2017,63(2):142-150.
[13] 杨晓春, 刘向宇, 王斌,等. 支持多约束的k-匿名化方法[J]. 软件学报, 2006, 17(5):1222-1231.
[14] 韩建民, 岑婷婷, 虞慧群. 数据表k-匿名化的微聚集算法研究[J]. 电子学报, 2008, 36(10):2021-2029.
[15] LIU X P, LI X B, MOTIWALLA L, et al. Sharing patient disease data with privacy preservation[C]//Proceedings of the AIS SIGSEC Workshop on Information Security and Privacy. Fort Worth, 2015:1-13.
[16] LIU X, LI X B, MOTIWALLA L, et al. Preserving patient privacy when sharing same-disease data[J]. Journal of data and information quality, 2016, 7 (4):17.
猜你喜欢
新高考·高三数学(2022年3期)2022-04-28
西南大学学报(自然科学版)(2022年4期)2022-04-15
电脑报(2021年14期)2021-06-28
计算机与生活(2020年8期)2020-08-12
党员生活·下(2020年3期)2020-04-20
党员生活·下(2020年2期)2020-04-20
党员生活(2020年2期)2020-04-17
软件学报(2019年11期)2019-12-11
计算机与生活(2019年5期)2019-07-18
中文信息(2017年12期)2018-01-27
