
基于老年人口数量的社会保障和就业支出的预测
2018-05-14 08:55谢珍珠杨润高
财讯 2018年6期
谢珍珠 杨润高


本文首先利用ARIMA模型对1990-2015年中国老年人口数量的时间序列数据进行分析,预测中国老年人口数量的发展趋势,然后建立我国老年人口数量与我国社会保障支出的模型,通过ARIMA模型预测的老年人口数量,预测我国财政在未来社会保障上面的支出。
中国老年人口 ARIMA
社会保障支出 协整 预测
联合国在1956年确定的《人口老龄化及其社会经济后果》
中的规定,当一个国家或地区65岁及以上老年人口占总人口比例超过7%,说明这个国家或者地区进入老龄化。根据国家统计局发布的数据,2016年我国60岁及以上人口为23086万人,占总人口的16.7%,65岁及以是人口为15003万人,占总人口的10.8%,远超过7%,说明我国已经进入老龄化国家。通过对近30年中国老年人口数量的分析,并对未来几年我国老年人口数量进行预测,老年人口数量影响到社会保障和就业支出,并提出相应的建议。
在人口方面预测的综述
人口数量进行预测的方法有很多,有Leslie矩阵方程法(黄健元,2010),有年龄移算法(蒋远营,2012),灰色预测模型(张荣艳等,2013),有Logistic模型法(阎慧臻,2008),有神经网络预测(毕小龙等,2004),还有VAR模型(吕盛鸽等,2012),等等。而本文采用ARIMA模型,该模型同时考虑了时间序列的偏自会归和自回归特性,在预测时间序列方面,是一种很好的方法。
已有很多学者运用ARIMA模型进行人口序列的预测与研究,有的学者预测中国人口自然增长率(李频等,2017),有的学者预测我国总人口(张讳等,2017),有的从人口出生率、死亡率和老年人所占比重方面进行分析(黄兰,2015),有的学者对吉林失地人口进行分析(孙少岩等,2014)[],也有学者对我国某一个省份的老年人口进行预测(杜鑫,2016)。
但是运用ARIMA模型对我国老年人口总数进行分析与预测的文章并不多,并且只是对人口数量简单的预测,而本文在对老年人口数量预测的基础上,进一步研究老年人口数量和社会保障和就业支出的关系,进一步达到对社会保障和就业支出的预测,对我国财政支出具有重大的参考价值。
ARIMA(p,d,q)模型的建立与分析
(1) ARIMA (p,d,q)模型的基本原理
ARIMA(p,d,q)模型的形式是:▽dxt=Θ(B)/Φ(B)εt
其中▽d=(1-B)d,Θ(B)=1-θ1B-......-θqBq是平稳可逆ARMA(p,q)的移动平滑系数多项式,Φ(B)=1-ψ1B-......-ψpBp是平稳可逆ARMA(p,q)的自回归系数多项式,{εt)是白噪声序列。
当时间序列数据足平稳状态时,ARIMA(p,d,q)模型变为回归移动平均模型即ARMA(p,q)模型。当q=0,ARMA(p,q)模型变为平稳可逆p阶自回归模型AR(p),当p=0,ARMA(p,q)模型变为平稳可逆q阶移动平均模型MA (q)。
实际问题中大多数的时间序列数据是不平稳的,所以需要对不平稳的时间序列数据进行差分处理,即确定ARIMA(p,d,q)模型中d的大小,然后确定p和q的大小。
(2)数据的来源和平稳性分析
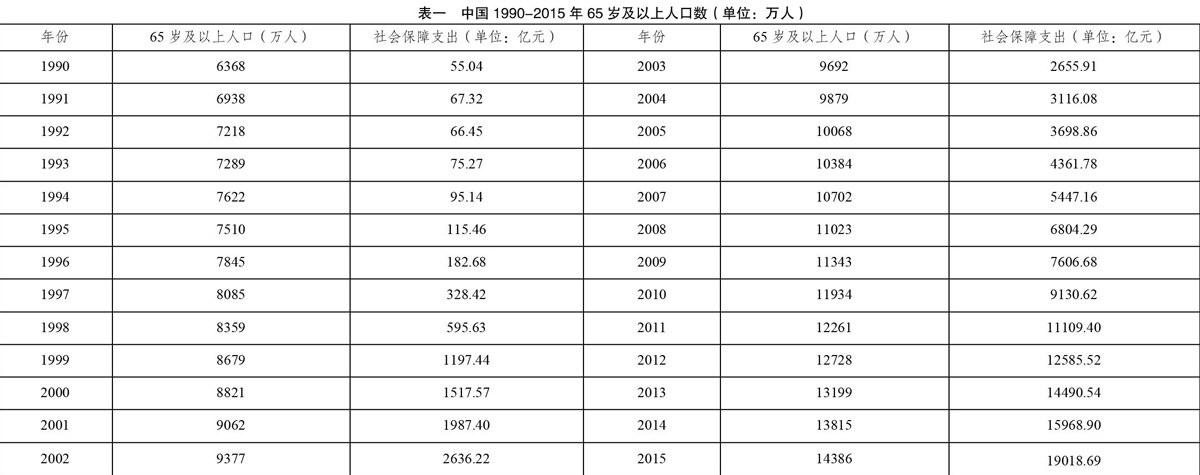
本文选取1990-2015年中国老年人口数量的数据,如表一,数据来自国家统计局官网。首先利用eviews8.0做出人口数量的时序图,得图一。从图一可以看出中国老年人口的序列X具有向上的趋势,不平稳。对这26年的中国老年人口进行单位根检验,得到ADF统计值为1.61,均大于给定的显著性水平为1%、5%和10%的临界值,不能拒绝原假设,即原序列存在单位根,不平稳。
对数据进行一阶差分处理,然后对一阶差分后的数据做单位根检验,得到ADF的统计值为-6.07,均小于在显著性水平为1%、5%和10%的临界值,故拒绝原假设,中国老年人几经一阶差分后足平稳的。绘制一阶差分序列的白相关和偏自相关图,得到一阶差分序列的自相关和偏自相关很快落人随机区问内,序列趋势已基本消除。所以ARIMA(p,d,q)模型中d为1,接下来就是确定p和q的值。
(3)模型的识别和估计
由上面的一阶差分序列的自相关和偏自相关图可知一阶差分序列的自相关系数1阶截尾,因此q=1,偏相关系数1阶截尾,因此P=1,因此可选择MA(1)、AR (1)、ARMA(1,1)模型拟合。又因为d=1,所以原始序列可选择ARIMA(0,1,1)、ARIMA(1,1,0)和ARIMA(1,1,1)。分别对这三个模型进行估计,得到ARIMA(1,1,1)模型拟合最好,但因为常数项不显著,故剔除,并且根据AIC和SC准则,剔除常数项之后的ARIMA(1,1,1)模型AIC和SC值最小,故最终模型为剔除常数项之后的ARIMA(1,1,1)模型。
(4)模型的检验
估计完模型之后,需要对模型的残差序列进行白噪声检验。得到剔除常数项之后的ARIMA(1,1,1)模型的殘差序列白相关和偏自相关的图,经过检验残差序列的自相关系数均落入随机区问内,且自相关系数的绝对值都比较小,故残差序列是纯随机的;另外Q统计量的P值大多数大于0.05,故可以近似的认为模型的残差序列为白噪声序列。
(5)模型的预测
利用剔除常数项之后的ARIMA(1,1,1)模型对2016-2020年中国老年人口数据进行预测,得到预测的65岁及以上人口在2016年为15190.02万人,在2017年为15846.34,在2018年为16543.19万人,在2019年为17283.07万人,在2020年为18068.64万人。
老年人口数与社会保障支出和就业模型估计
(1)数据的选取
根据表一,得到1990-2015我国社会保障支出的曲线图,如图二。从图二可知,1990-2000年我国社会保障支出增幅较小,而从2000年之后社会保障支出大致呈线性增加的趋势,故选取2000年之后的数据。
(2)数据的平稳性分析
对2000年之后的老年人口和社会保障支出的数据进行平稳性检验,为方便起见,把社会保障和就业支出变量命名为Y,把老年人口数量变量命名为X。经检验可知X序列和Y序列都是二阶单整序列,因此X和Y序列可能存在协整关系,作两变量之间的回归,然后进行协整性检验。
(3)模型的建立与检验
以社会保障支出为被解释变量,老年人几数量为解释变量,建立回归模型。回归方程如(1)所示:
Y=-27695.67+3.163674X
(1)
方程的调整之后的R2为0.981689,P值为0.0000,DW值为0.565737,在樣本容量n=16,k=1,显著性水平为5%的条件下,DW值小于dl值1.106,故模型存在序列相关。对模型进行修正,修正之后模型为(2):
Y=-32411.40+3.545799X+0.669718AR (1)
(2)
模型的调整之后R2为0.992351,P值为较小,DW值为2.446720,调整之后n=15,在5%的显著性水平下,du为1.361, 4-du为2.639,故调整之后的模型已不存在序列相关。
对模型进行残差平稳性检验,模型残差的ADF值为-5.658947,小于显著性水平为1%临界值-2.740613,故残差序列是平稳的,则中国老年人口数量和社会保障支出之间协整关系成立。
(4)模型的预测
利用已经预测的2016-2010年的老年人口数据,带人修正后的模型,对我国社会保障支出进行预测,得到预测的我国社会保障和就业支出在2016年为21453.71亿元,在2017年为23779.45亿元,在2018年为26249.38亿元,在2019年为28872.21亿元,在2020年为31657.25亿元。
结论
本文通过建立ARIMA模型对我国老年人口数量进行预测,然后建立老年人口数量和社会保障支出的协整模型,达到对2016-2020年社会保障支出进行预测。由模型(2)知,从长期来看,我国老年人口数量每增加一个单位,社会保障支出增加3.545799个单位,预测的老年人口数量呈逐年增加的趋势,故导致社会保障支出逐渐增加,到2020年,将达到31657.25亿元,对我国政府决策提供参考。
[1]黄健元.基于Leslie方程预测的江苏省人口老龄化特征分析[J].南京师大学报(社会科学版),2010( 03)
[2]蒋远营.基于年龄移算法的人口预测[J].统计与决策,2012(13).
[3]张荣艳,马艳琴,郝淑双.残差灰色预测模型在我国老龄人口预测中的应用[J].数学的实践与认识,2013(08).
[4]阎慧臻.Logistic模型在人口预测中的应用[J].大连工业大学学报,2008(12).
[5]毕小龙,魏巍.基于神经网络的我国人口老龄化趋势预测[J].武汉理工大学学报·信息与管理工程版,2004(06).
[6]昌盛鸽,宣丹萍.北京市人口老龄化系数预测[J].统计研究,2012( 03).
[7]李频胡明形.基于ARIMA模型的中国人口自然增长率预测[J].市场研究,2017(05).
[8]张祎朱家明.基于ARIMA和二次指数平滑模型的人口组合预测[J].牡丹江师范学院学报(自然科学版),2017(01)
[9]黄兰.我国人口老龄化问题的分析与预测[J].成都纺织高等专科学校学报,2015 (4).
[10]孙少岩,逯家英,王化波.基于ARIMA模型对吉林省失地人口的研究[J].人口学刊,2014(04).
[11]杜鑫.基于ARIMA模型的陕西省老年人口数量的分析[J].社会视点,2016(24).
[12]王燕.应用时间序列分析[M].中国人民大学出版社,2012.
[13]国家统计局.[Z].(1990-2015).
猜你喜欢
上海师范大学学报·自然科学版(2022年3期)2022-07-11
小康(2022年13期)2022-05-12
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
上海师范大学学报·自然科学版(2018年3期)2018-05-14
价值工程(2018年3期)2018-01-23
电子技术与软件工程(2017年19期)2017-11-09
计算机应用(2016年10期)2017-05-12
科技与创新(2015年19期)2015-10-14
科技经济市场(2014年2期)2014-06-20
东北大学学报(社会科学版)(2004年3期)2004-06-29
