
基于Web Service多源异构系统增量同步的实现
2018-05-22 07:35庞秋奔
计算机应用与软件 2018年5期
庞秋奔 李 银
1 (广西医科大学第一附属医院 广西 南宁 530021)2 (中国移动通信集团广西有限公司 广西 南宁 530000)
0 引 言
在互联网+、云平台背景下,各企业单位利用信息技术进行内部系统的系统连接,实现信息共享,重建流程,在一定的意义上形成规模更大的信息实体。内部的集成平台、数据中心也日益凸显重要,而在建设系统集成过程中,如何交换同步数据,各分系统形成统一一致的标准化字典数据,无疑是系统集成的热点。在面对异构、同步数据量大的背景下,如何提高数据同步的效率是在多源异构系统之间建立一致标准化字典数据的关键问题。
对数据集成而言,就是满足在不同应用需求时,采用不同的方法。对交换数据量低、实时性要求高,用消息交互的应用集成方式,JMS的消息中间件,比如Active MQ、Open JMS;对交换数据量大、实时性要求低,用数据库数据集成方式,如数据库集成工具Oracle Golden Gate。在异构环境下,数据库之间的数据同步,采用的方法主要有:消息队列的中间件模型[1]、建立中心数据库[2]、使用XML和Web Services实现分布式数据库同步[3]等。当前,XML的跨平台、可格式化、良好交互性与Web Services的平台独立性(实现允许服务提供者和服务调用者在Internet上进行数据交互)使得利用XML和Web Services来进行数据传输和共享成为了研究的热点。但在面临多个复杂系统的数据交互同步,多个系统Web Services的调用与管理复杂性倍增的问题上,集成平台在解决数据交互上有着自身的优势,为多个复杂异构系统的集成提供强大的支持。能梳理复杂的数据交互接口,提高数据交换效率,形成标准化,易控易管理的接口平台。
已有的同步技术研究主要面向在采用如Oracle、 SQL Server、My SQL等主流关系型数据库之间实现增量同步,缺少对分别采用面向对象与关系型数据库的异构系统之间实现增量同步的研究。本文针对此问题进行研究,在增量数据交换数据量不大,实时性要求不高的应用需求前提下,使用集成平台集成多个异构系统的架构。研究对比增量数据捕获方法,设计一种结合采用数据库日志分析法与Web Service技术,在采用了面向对象数据库、关系型数据库的异构系统之间实现增量同步,实现主库到各异构分库的增量数据同步,提高数据同步的效率。研究重点在于面向对象数据库大日志数据的解析,与如何通过集成平台在多源异构系统之间进行数据的增量同步,实现各异构分库与主库保持统一标准化数据字典的目的。
1 面向对象Caché数据库日志分析法捕获增量数据
增量数据主要是指对数据库增加、修改和删除操作的数据库记录。常用捕获增量数据[4]的主要方法有:API法: 在源系统植入获取增量数据的程序,产生增量数据文件,但对源程序改动太大。快照法:比较源数据的两个快照,当数据量特别大时,性能会成为问题。日志分析法:日志包含了全部成功提交的操作记录信息,通过对事务数据库日志进行分析来捕获变化数据,日志文件量大时,则要求有支持日志文件解析的工具包。触发器法:在要抽取的表上建立需要的触发器,每当源表中的数据发生变化,就被相应的触发器将变化的数据写入一个临时表,它会对业务系统的性能造成严重影响,因为每次数据库更新操作都会引起一次触发器执行。
经过综合分析, 日志分析法对业务系统的性能影响很小,且实时性较强。要求数据库系统必须具有日志管理系统,并且提供分析日志文件所需的命令或工具。本文研究是对异构系统采用面向对象数据库与关系型数据库之间实现增量同步的研究。面向对象数据库典型代表是Caché数据库, Caché 数据库使用有效的多维数据引擎,多维数据引擎能够对复杂的现实数据进行直观、有效的建模。Caché多维数组被称之为“Global”,Global是一种类似树的存储形式,定义形式为^Global (“节点1”,“节点2”,“节点3”)=“数据”。本节实现对面向对象Caché数据库日志进行分析捕获变化数据。
数据库日志可看作是逆数据操作列表,分析日志中的数据可获得数据库的变化数据。每个数据库系统的日志记录形式都不一样,但基本可以用一个七元组来简单描述[5]:〈LSN,TID,E,O,T,V,W〉。其中LSN 为日志记录的唯一标识,TID 标识事务,E 为操作的数据对象,O 表示数据库操作,T 为操作发生的时刻,V和W 分别表示操作数据的新值和旧值。对于面向对象Caché数据库,日志数据也带有七元组的元素,但也有所不同。以下是从Caché数据库日志内容中通过日志文件工具导出 Global: ^ABC数据变化的日志片断:
Address: 373980
Type: Set
Intransaction: No
Job ID: 0x003D0015
Process ID: 3997717(jid)
Remote systemID: 0
Time stamp: 63998,14405-03/21/2016 04:00:05
Collation sequence: 5
Prev address: 373928
Next address: 374032
Global: ^[“^^C:MyCachemgr”]ABC
New Value: 5
Old Value: 2
其中Address表示文件记录的位置,Type是命令的类型,In transaction 表示更新是否发生在事务中,Process ID是进程ID号,Remote system ID 表示远程系统ID号, 0表示本地进程, Time stamp 表示日志缓存时间, Global 表示更新的Global节点,可对应一个关系二维表记录, New Value 对Set命令赋予的新值, Old Value 对Set或Kill命令操作之前的值。每个数据变化日志导出大体是此类结构,数据变化为新增记录的,无Old Value行;对数据变化为修改、删除记录的,有Old Value行。其他行数据标签是一样的,值不同。
在Caché数据库中,每个表可对应一个Caché多维数组即Global。每条记录对应一个Global节点,对于数据库表记录的增、删、改都对应到Global。由以上分析可见Caché数据库的日志可导出为带标签的结构化模板格式,对于结构化模板的日志文件,利用数据库技术与正则表达式,通过匹配模板的方式来提取变化的数据。通过提取日志数据中对应的Global标签的内容来获取增、删、改操作后导致数据库表变化记录的主键值。特别地对数据的删除操作,考虑基础字典数据表的完整性,一般情况下数据库设计为每个基础表记录增加一个字段,记录是否结束,而不是物理删除数据。因此,对于修改和删除,都视为修改。对于可导出为结构化模板的日志文件,采用提取相关的日志文件,转化为数据库的行列后进行正则表达式分析匹配搜索变化的目标数据。
Caché数据库基础表数据的增、删、改日志内容都体现在Global标签内容,可归纳出特定的模式匹配串,通过在日志文件找到各记录Global节点对应的主键ID。新增、删除、修改数据的日志内容都带有Global主数据data节点的特征。例如表1是人员表SS_USER对应的Global结构设计,SS_USER表数据变化都带有^SSU(“SSUSR”,{ SSUSR_Rowid})的模式,因为SSUSR_Rowid是变化的,在日志文件中体现为各主键ID值。本文使用正则表达式进行匹配,即匹配出所有SSU("SSUSR", *)结构的串,再提取出*对应的数值,即对应于修改或删除记录的主键ID值。需要同步的表对应的Global与匹配模式串存放在一个设定好的同步配置表中(见表2)。
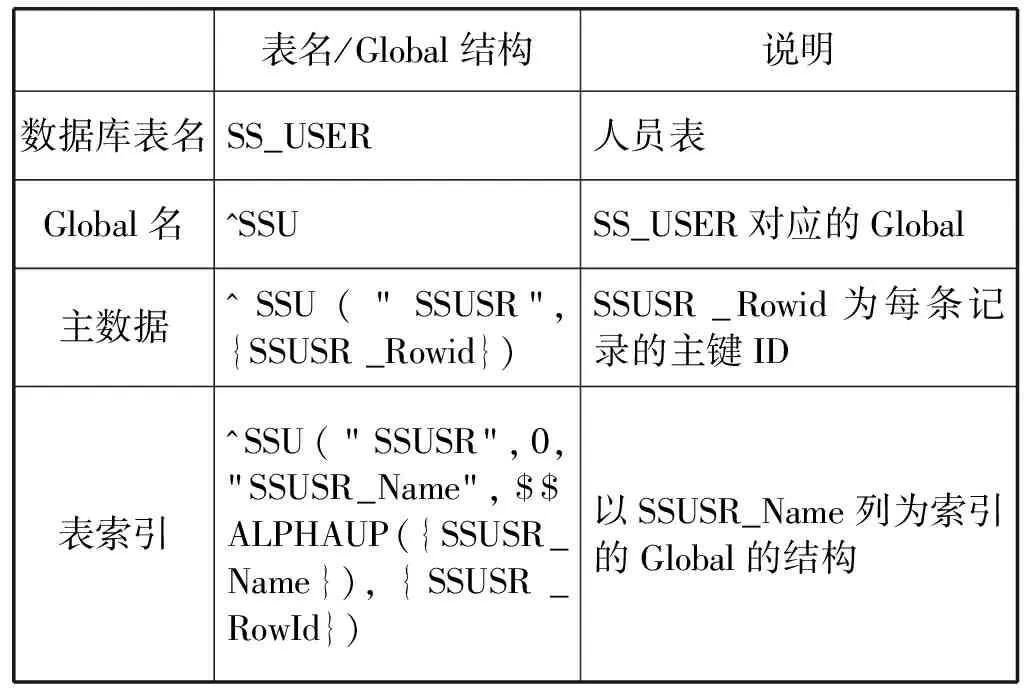
表1 人员表SS_USER对应多维数组Global

表2 同步配置表
结合本节分析,Caché数据库表增量数据捕获具体处理流程如图1、图2所示,主要分为3大模块内容[2,5]:下载日志;解析日志、捕获增量数据主键ID;检索源数据、转换输出。

图1 增量数据捕获处理流程 图2 日志解析处理流程
Caché数据库同步表记录增量变化捕获处理步骤如下:
步骤1获取指定日期内的数据库文件日志目录结构。使用数据库日志命令:DO^JRNDUMP获取相应日志文件目录结构。
步骤2对步骤1的日志文件目录,循环对每个日志文件,读取同步配置表,使用 SELECT^JRNDUMP命令搜索提取出含同步表的日志内容,分别保存为txt文件。
步骤3循环对步骤2的txt日志文件,使用Caché数据库与正则表达式进行索引查找。
步骤3.1以流方式读取步骤2得到的各行数据。
步骤3.2对步骤3.1的各行数据进行处理:
步骤3.2.1定位“Global”标签行;
步骤3.2.2转换为Caché 数据库临时表各行列,标签为一列,标签值为一列;
步骤3.2.3读取同步配置表对应的模式匹配串,对3.2.2各行标签值进行匹配,若匹配,取出模式串对应到*数值,则为增、删、改操作记录对应到源表有变动记录的主键ID值。
步骤4在定义好的两个继承XML.Adaptor适配器类中,一个类定义一个类型为list集合的属性,list集合成员为另个类的对象。循环地进行对象实例化与插入list集合:根据步骤3.2.3得到的各主键ID与需要同步的字段列,用各主键ID的Global data节点下对应的字段值相应地赋值给对象属性,并将实例化的对象插入有list集合属性的类对象。
步骤5使用XMLExportToStream方法将步骤4中定义有list集合属性的对象转换为XML流,最后输出所有变化数据的XML流。
2 结合数据库日志分析法+集成平台实现增量数据同步的设计
目前通常采用基于中间件模型和数据仓库等的方法来构造集成系统。本文的研究背景是内部各系统之间基础数据的增量同步、增量数据交换数据量不大,实时性要求不高。适合采用基于集成平台的,通过消息交互的应用集成方式。集成平台方式是面向对象的开放式集成技术, 集成平台与各个应用系统之间形成一种星形的拓扑结构, 各系统之间的消息交换通过各自的适配器由集成平台统一控制管理。系统中各子系统和用户的信息采用统一的标准, 规范和编码, 实现全系统信息共享。由于本文的研究对象是针对医疗行业,由于其行业的特殊性,医疗行业内的专业信息化系统多、流程多且动态变化、数据多且复杂的特点, 适合使用具有快速集成应用和开发符合程序的,基于ESB 消息总线的Ensemble平台。基于Ensemble集成平台的提供多种输入输出适配器,有效解决系统异构问题,数据交互过程提供可视化工具进行工作流定制与管理。
Ensemble集成平台[9-10]主要实现将一个系统的消息传递给另一个或者多个其他系统,消息是Ensemble内部协调业务步骤所需要传递的数据,消息根据方向分为请求消息和响应消息。每建立的一个Ensemble production包含三个组件:业务服务(BS)、业务流程(BP)、业务操作(BO)。BS从Ensemble外部接收消息,每一个BS连接一个接口;BP提供逻辑以及流程控制,对于HL7,成为“消息路由”或者“路由引擎”;BO向Ensemble外部发送消息,每一个操作连接一个接口。通过从BS到BP,再到BO实现消息的传递。
本文在Ensemble集成平台上用Web Service+XML方式实现增量数据在多源异构系统之间的增量同步[3,7-8,11],具体设计的处理过程见图3。
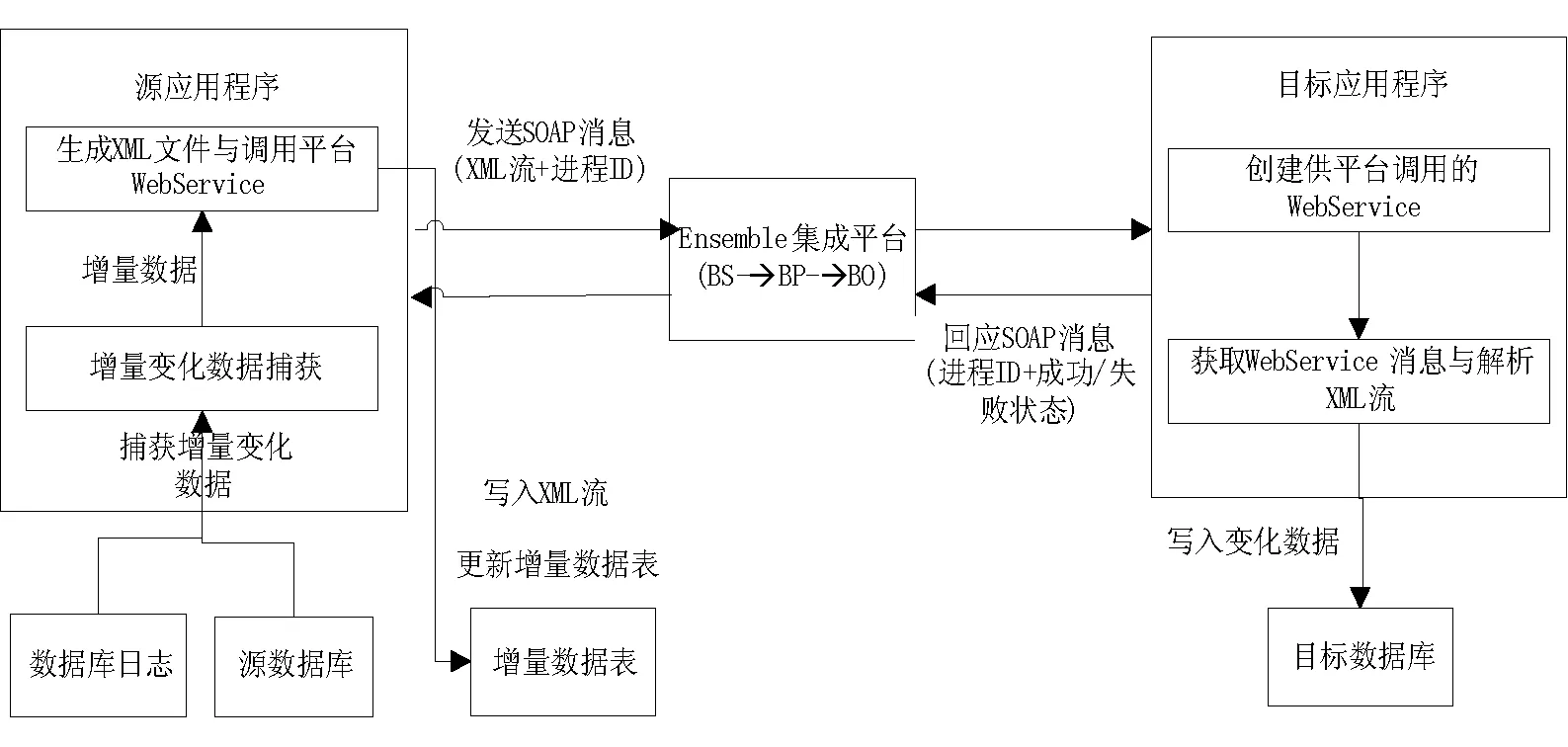
图3 增量数据同步更新处理流程
处理流程的过程说明如下:
(1) 源应用程序定期触发增量变化数据捕获程序模块(具体见第1节),把输出的增量变化数据XML流和随机生成的进程ID分别插入增量数据表和发送到集成平台。
(2) 集成平台通过BS、BP、BO处理后,发送到目标应用程序。
(3) 目标应用程序通过自身Web Service获取从集成平台传入的XML流,使用DataSet读取XML流,根据解析转换出来的各行记录,更新目标数据库对应的表数据。并向集成平台发送同步是否成功的响应消息。
(4) 集成平台向源应用程序转发响应消息。
(5) 源应用程序接收响应消息后,更新增量日志表,若响应消息成功,则删除增量日志表对应进程ID的行记录;若响应消息失败,则源应用程序重新发送,直到重复次数超过3次。若成功,转第7步,否则放弃。
(6) 源应用程序定期轮询增量数据表,若查询到有数据,跳转到第2步。
(7) 结束。
图4中的增量数据表设计为3列,第1列表自增列, 第2列为进程ID,第3列为第2节中每次生成的XML流字节。在Ensemble平台内BS、BP、BO消息处理过程[7,9]为:平台内定义好BS、BP、BO程序,BS内定义各函数,发布为集成平台的Web Service, 将请求消息发送给业务流程BP。BP内利用业务流程语言(BPL)工具定制好开始(start)、分流(switch)、调用(call)、等待(wait)、代码(code)、结束(end)业务流程,转换消息格式,根据BS传入的消息参数不同,在调用属性中设定调用的某个BO,BO中定义好要连接异构系统的Web Service接口程序。目标程序获得XML回应消息,发送XML回应消息。在需要连接多个目标应用程序情况下,在平台的BO中添加相应的目标应用程序,在BP中定义好调用的顺序即可。
图4中目标应用程序对Ensemble集成平台传入的XML流解析处理的具体过程为:首先目标应用程序调用自身Web Service接收平台传入的XML流;接着使用数据集DataSet对象的ReadXML方法将XML流加载到 DataSet,通过DataSet.Tables[“表名”]转换为数据表DataTable对象。用foreach循环DataTable每行数据,根据各行的主键ID,业务逻辑判断是插入还是更改,最后使用sqlcommand方法将数据更新到目标数据库相应的表。实现将增量数据也就是源系统变化数据同步更新到目标系统。
3 实验结果分析
本文实验构建在笔者所在信息中心的环境下,该环境通过Ensemble集成平台实现了各医疗子系统的集成。本实验根据第1、2节提出的数据库日志分析法+Ensemble集成平台实现增量数据同步的设计,实现主库到各异构分库增量数据的准同步。本实验的测试中,主库与集成平台的测试环境参数为: 操作系统Windows Server 2008 R2 Enterprise;硬件环境: Intel(R) Xeon(R) CPU X5650 @ 2.67 GHz 2个;内存 8 GB。分库的测试环境参数为: 操作系统Windows Server 2003 R2 Enterprise;硬件环境: Intel(R) Xeon(R) CPU E5649 @ 2.53 GHz 2个;内存8 GB。网络环境都是 100 Mbit/s校园网。
主库的编程语言采用集成平台自带的M开发语言, 源数据库为面向对象的Caché数据库。目标库的编程语言采用C#,数据库为oracle10i数据库。实验通过对源数据库某个表使用SQLdbx工具进行增、删、改操作,在目标数据库oracle10i目标表数据检查是否同步成功,并且在主库初始日志大小为111 MB的情况下, 测试了单个表,同步4个字段列,在数据记录行变化的情况下同步成功所用的不同时间,实验结果见图4。以1千条数据为例,下载的日志文件大小为3 763 KB, 增量数据XML文件大小为177 KB,同步时间为19 125 ms。
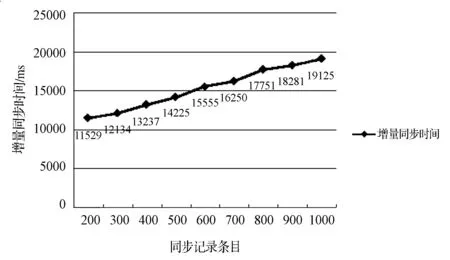
图4 增量同步时间
4 结 语
本文首先分析了面向对象Caché数据库日志文件的结构特点, 用Caché数据库开放的API下载变化数据日志。接着分析如何采用数据库日志法分析日志, 结合Caché数据库与正则表达式法捕获增量变化数据,通过Ensemble集成平台,使用Web Service+XML的方式推送到相应的目标系统。最后是目标系统对XML串的解析与处理。在多源异构系统之间完成增量同步,实现主库到各异构分库的增量数据同步的目的,使得各异构分库与主库保持统一标准化数据字典, 提高数据同步的效率。该方法应用到某医疗环境的信息系统中,实验结果表明本文采用的方法增量同步数据文件约在940 KB大小下,同步速度大约为5 300条记录/min,实现了多源异构系统的增量同步,在不含大对象情况下,增量同步获得较好效果。
参考文献
[1] 田淼.分布式异构数据库同步中间件的设计与实现[D].西安:西安电子科技大学,2012:17-34.
[2] 王玉标,饶锡如,何盼.异构环境下数据库增量同步更新机制[J]. 计算机工程与设计,2011, 32(3): 948-951.
[3] 任建辉,徐林,蔡航标.一种基于XML/Web Services 的分布式数据库同步技术的研究与实现[J].成都大学学报(自然科学版),2009,28(2):136-145.
[4] 邹先霞,贾维嘉,潘久辉. 基于数据库日志的变化数据捕获研究[J].小型微型计算机系统,2012,33(3): 534-535.
[5] 李立亚.一种基于记录标记的数据库同步算法[J]. 计算机与数字工程,2015,43(6):947-951.
[6] 周健. 数据同步技术在省级数据集中的应用[D].湖北:湖北大学,2012:9-12.
[7] 宫涛. 异构数据库准实时同步技术研究[D].湖北:华中科技大学,2010:20-22.
[8] 刘天平.信息交换平台数据同步模块的设计与实现[D].北京:北京交通大学,2011:38-48.
[9] 龙凤舞.基于Ensemble的医院信息集成平台的设计与实现[D]. 湖南:中南大学,2014:19-20, 24-26.
[10] 黄冉.基于Ensemble的医疗信息系统集成[D]. 浙江:浙江大学,2012: 33-42.
[11] 顾倩文,曾献辉. 多源异构环境下数据同步复制技术的研究[J].微型机与应用,2015,34(22):22-24.
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
北京航空航天大学学报(2022年5期)2022-06-06
小学教学研究(2022年5期)2022-04-28
当代陕西(2022年6期)2022-04-19
华人时刊(2021年13期)2021-11-27
当代水产(2021年8期)2021-11-04
心声歌刊(2020年4期)2020-09-07
电子制作(2019年14期)2019-08-20
商周刊(2019年1期)2019-01-31
妇女生活(2019年1期)2019-01-17
