
一种支持数据质量评价的方法与应用研究
2018-05-22 07:19宋俊典刘丰源
计算机应用与软件 2018年5期
宋俊典 刘丰源
(上海计算机软件技术开发中心 上海 201112)
0 引 言
当前各行业企业越来越多依赖于数据进行决策和运转,数据的信息提取能力和处理能力急需提升。然而许多数据已经超出了传统技术能管控的范畴,存在大规模的低质量数据混在其中,进而影响了整体数据的清洁度。由于数据质量问题导致的计算偏差和决策失误屡见不鲜,数据质量的低下造成严重经济损失,并影响着各行业的发展。数据本身和数据质量都是一个多维度而模糊的概念,数据质量的评估难以用单一的指标来准确判断,而且随着业务流程的不同,数据质量的评价维度也是多种多样。如何处理数据质量评价维度的模糊性,使得数据质量的评价具有可靠性和准确性,在数据质量的评估工作中一直是研究的重点和难点。本文面向数据质量评估提出了一种基于多维度的模糊综合评价法,具有全面、可靠、准确等优点,为辅助企业进行数据质量的提升和改进提供了一套行之有效的方法。
1 数据质量评价概述
数据质量评估是指针对数据的好坏优劣进行评判的方法或模型[1],国内外学者对此开展了大量的研究。Meyen[2]等最早定义数据质量评估是一种面向数据环境的属性,旨在提高数据准确性的有效手段。Richard[3]在随后一年首创数据质量评估先例,将质量评估定义、质量量化和质量分析以及提升纳入质量评估体系中。Eppler[4]等基于之前的质量分析框架融合了新的原色,提出纳入质量提升方案作为评估体系的内容之一。IMF 紧接着发布了更适用于定性度量的DQAF即《数据质量评估框架》[5],该框架成为后来的三大框架之一。相同时期Yang等[6]和Leo等[7](2002)都分别在质量评估方法上有所突破,分别提出了AIMQ方法和主客观融合评估方法,大大改进了数据质量的评估方法的单一问题,其中AIMQ方法同样成为了三大数据质量评估框架之一,广为沿用。 Carlo[8]等在2008年扩展了原有的质量评估方法,提出一套更为全面、灵活的评估框架,被命名为CDQ,同属三大框架之一。
而国内的学者在数据质量评估方法的研究和应用方面起步较晚,但是近年也做出了大量的研究和实践。其中王淑贞[9]面向ERP系统,分析了数据精确度缺陷的根源和弊端,提出了面向准确性属性的优化手段。王欣[10]对Benford分布律不能用于有界数据集准确性评估的局限性,提出了修正Benford分布律基础上的准确性评估方法。然而上述方法都是将数据质量等同于数据准确性,存在一定的偏差,近年来越来越多的学者开始考虑多维评估问题,规避原始的单维度评估可能导致的不客观性。吴骋[11]等关注数据质量评估工作的多维性,提出了量化的评估方法并应用在医疗领域。丁小欧[12]等归纳了一套数据质量评估指标,并深入研究了多维关系评估策略。刘伟涛[13]等结合互联网数据,建立了面向WEB数据的评估模型和标准。
综上所述,国外研究人员倾向于宏观框架的构建,研究主体在于评估方法的组合和复用,而国内学者更倾向于应用在具体的场景中,构建不同的特色的质量指标评估体系并更关注准确性这个单一维度,但近年来国内学者也开始关注多维数据质量评估问题。然而结合国内外针对数据质量评价方法的研究现状可以看出,国外的质量评估框架仅能对质量评估工作起到一定的指导作用,鲜有结合计算机系统落地实施的工具产生,而国内的指标体系并不完全,即便是考虑到了多维质量评估维度,仍然局限在准确性、完整性、规范性等少数维度,缺少与国际主流框架的结合,尚不够全面,进而导致质量评估的结果会有一定偏差。基于以上问题,本文的研究试图解决以下 3 个方面的问题: ① 综合现有研究成果和国际主流评估框架,制定8大维度的多层级数据质量评估指标体系; ② 融合德尔菲法和层次分析法进行权重的计算,使权重集更为客观准确,并融合模糊综合评价法进行多维度模糊综合评价法的构建; ③ 在实践层面给出具体算例分析并结合计算机系统实现和验证,并将方法成功应用在一个项目实例中。
2 基于多维度模糊综合评价方法
2.1 关键技术
1) 德尔菲法(Delphi) 德尔菲法[13]是实现专家决策的重要手段,通过采用背对背的通信方式屏蔽专家之间的沟通渠道,再通过反复轮询使结果趋同。德尔菲法具有鲜明的特点:综合考虑到参与决策者的专业知识,是吸收融合知识进行预测的专业方法;只允许背靠背通信方式,即只允许参与决策者与调研人员单方面沟通,禁止专家之间的直接交流,可以有效避免主观意识对结果的影响;反复迭代单次统计结果,直到结果逐渐趋于统一,可以通过统计次数的递增降低决策的失误率。
正是由于德尔菲法充分利用了决策者的资源,并具有一定的匿名性和独立性,使得每次调研和决策结果都是真实可信的,且具有一定的可靠性,同时该方法又利用反复迭代的思想得到趋同的最终结果,使得反馈结果具有一致性和可信性。
2) 层次分析法(AHP) 层次分析法AHP[14]的提出是面向复杂关系的梳理和转化,该方法通过层次分析结构模型实现各层级的比较,实现彼此重要程度的比对,建立判端矩阵并计算权重分配。层次分析法优点明确,通过将原始的定性问题转化为定量处理,可以实现更好的效果。相比于其他定量方法,层次分析法更加注重模拟人脑思考的过程,关注于定性的分析和判断。同时层次分析法具有简单可实行的特点,通过把问题分层量化,实现了数学计算的简化,有助于快速辅助决策。因此层次分析法常常应用于解决定性问题和简化指标计算。
3) 模糊综合评价法(FCEM) 模糊综合评价法[15]是实现模糊概念转化与评价的方法,基础是模糊数学。模糊数学是用来描述、研究和处理事物所具有的模糊特征的数学,可以有效地解决表述对象的不确定性和模糊性,并且提供了相关处理不精确问题的工具。模糊综合评价法的核心是隶属度函数,可以把定性的问题转化为定量的问题来处理,是实现模糊转化的核心手段,最终可以实现将多维评价属性转化为定量的计算,得到科学的评价等级的目的。
模糊综合评价法具有通用的流程可以参考,首先是构建符合特定业务场景的评估指标体系,且需要具有一定的客观性,指标体系可分为多层级指标,用于后续模糊转化以及权重制定;其次是进行权重向量的制定,权重的确定可根据需要变更权重确定方法,但需要遵循客观准确的原则;接着是构建评价矩阵,在这个环节里需要对隶属度函数进行确定并应用隶属度函数进行模糊转化和模糊计算;最后是矩阵和权重的合成,可以更好地综合模糊概念的定性和定量特征,保证最终结果的准确可靠。
模糊综合评价法在难以定量计算的评价问题上具有非常优秀的实用性,通过模糊概念的定量转化,可以结合计算机实现精准的评价。
2.2 多维模糊评价法概述
本方法计算流程如图1所示。

图1 方法流程图
1) 确定评价指标集:依据业务场景制定可以评价数据质量的评判对象因素构成集合。假设存在二级指标,则U(u1,u2,…,un)表示一级指标,Uk(uk1,uk2,…,uks)为二级指标,k=1,2,…,n。
2) 建立权重集,依照指标体系中各指标重要性比对结果制定相应的权重矩阵,本方法中一级指标的权重集A(a1,a2,…,an)可采用德尔菲法计算;二级指标采用层次分析法计算Ak(ak1,ak2,…,aks),通过对各因素相互比较形成判断矩阵来确定的各因素的权重。
3) 确定评语集v(v1,v2,…,vm),比如4类评语等级{优,良,中,差}。
4) 确定隶属度函数,即依据数据对于指标体系的贴合程度确定U对v的隶属度rij,构造各评价指标的评价矩阵Rk=(rij)s×m。
5) 模糊变换及模糊综合评价模型:
(1) 通过将uki的评价矩阵Rk与权重进行矩阵合成,得到一级指标uk对于评语集v的隶属向量Bk=AkRk=[bk1,bk2,…,bkm]。
(2) 再对R进行模糊变换得到目标指标U对评语集v的隶属向量B1×m=AR=[a1,a2,…,an][B1,B2,…,Bn]。
(3) 最后计算出隶属向量。
6) 根据最大隶属度原则,得到数据质量评价等级。
2.3 数据质量评估指标体系
数据质量评估系统除了需要满足一般的系统管理、权限管理等基础功能外[16],重要的需求点在于质量评估指标体系如何制定以及如何将指标落实到系统中。结合当前研究成果和实现数据质量评估检查所需要的实际指标,制订如下两层指标体系,作为系统指标体系。
本指标体系分为8类一级指标和20类二级指标。各级指标如下所述:
1) 可靠性:包含原始数据、定期更新的权威数据、不定期更新的文献数据或专著中的数据、基于文献统计数据、无根据的假设数据等5类二级指标。其中原始数据是现场调查的一线数据;定时更新的权威数据和不定期更新的文献专著数据主要指爬虫获取的互联网数据。
2) 准确性:包含数值准确性、值域准确性和平衡规则检查3类二级指标。其中数值准确性指指标数值与阈值上下限的比较;值域准确性指检查特定字段的取值是否在预定的取值范围之内;平衡规则检查指多个指标间的约束关系检查。
3) 完整性:包含数据量充足性、关键属性空置率和外键引用检查3类二级指标。其中数据量充足性指检查样本数据是否充足;关键属性空置率指实体关键属性中空置部分的占比;外键引用检查是指检查是否满足引用完整性的规则。
4) 一致性:包含数据一致性、格式一致性和变更一致性3类二级指标。数据一致性指采集点、取数时间点、接口数据获取是否失真;格式一致性指创建数据默认值与数据录入的校验规则是否不当;变更一致性指与基础数据可库一致性。
5) 及时性:包含数据更新及时率1个二级指标,指数据来源的范围、数据量以及更新的时间。
6) 规范性:包含数据命名标准规范率检查1个二级指标,该指标指根据数据的标准字典进行评判是否符合标准化的定义。
7) 唯一性:包含数值重复率和业务主键唯一性2个二级指标。数值重复率指检查数据记录与其所表示的真实实体或事件是否一一对应;业务主键唯一性指对具有业务唯一意义的字段进行唯一性检查。
8) 有效性:包含实体主键取值有效性(业务主键唯一性占比)和属性有效性2个二级指标。实体主键取值有效性指逻辑主键是表的唯一标识,主键上数据有效性;属性有效性指实体属性的取值在语法和语义上均应符合业务逻辑。
2.4 确定隶属度函数
隶属度是多维度模糊评判法的核心,因此在确定数据质量评估指标体系后需要依据其进行隶属度函数的确定,具体方法如下所示:
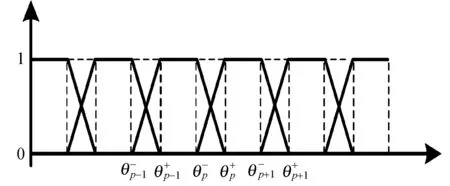
给定监测对象Uk关于指标uks的一个质量评价值xks表示最底层质量指标的分值,其属于模糊类p(p=1…m)的隶属度计算如下,
1)p=1(偏大型,优级)

2) 1 3)p=m(偏小型,差级) 图2 基本模糊等级的隶属度函数 2.5 确定权重系数 而对于权重的计算,本方法采用一二级指标分开计算的策略,一级指标较为简单,因此采用德尔菲法进行专家打分评定,考虑到细粒度指标较复杂,选择采用层次分析法处理,并构建指标间对比矩阵如表1所示。 表1 指标间对比矩阵(9级标度) 按照二级数据质量评价指标构造比较矩阵,以dij表示评价指标aki与akj的重要程度。 Dk=[dij]s×s 本文提出的基于多维度的模糊综合评价法应用在上海市某大型证券公司与上海软件中心合作的数据治理项目中,以该证券公司部分数据为例进行验证。本项目指标体系参照表1,本项目中评估结果采用优、良、中、差四级评语集,基于本方法进行模糊计算并得到数据等级评估结果。基于算理的整体计算分析过程如下: 1) 根据评价指标构建评估对象集U={u1,u2,u3,u4,u5,u6,u7,u8},其下指标集为u1={u11,u12,u13,u14,u15},u2={u21,u22,u23},u3={u31,u32,u33},u4={u41,u42,u43},u5={u51},u6={u61},u7={u71,u72},u8={u81,u82}。 2) 建立评语集v,v={v1=优,v2=良,v3=中,v4=差}。 3) 计算二级指标权重Ak,得到权重A1={a11,a12,a13,a14,a15},A2={a21,a22,a23},A3={a31,a32,a33},A4={a41,a42,a43},A5={a51},A6={a61},A7={a71,a72},A8={a81,a82}。 4) 构造评价矩阵Rk,本项目中x≥96为优,82≤x≤89为良,68≤x≤75为中,x≤61为差,其余分值则根据隶属度函数计算求得: 5) 对二级评价矩阵进行模糊变换,即求模糊综合评价Bk。本文模糊算子M(,⊕)为加权平均型,因此模糊子集Bk=AkRk=[bk1,bk2,bk3,bk4],一级指标评判矩阵R=[B1,B2,…,Bn]n×4。 6) 数据质量评价向量B,B1×4=AR=[a1,a2,…,an][B1,B2,…,Bn]。 7) 在各隶属度中选择最大的作为该对象隶属度,构造结果矩阵。 8) 评价结果分析,通过系统实现本次数据质量的评估,评估结果如图3所示。 图3 数据质量评估结果 为了验证本研究提出的基于多维度模糊综合评价法的准确性,本文采用市面上某主流质量评估工具对同数据的评估结果做比对,该评估结果如表2所示。 表2 某工具评估结果 经过比对可见本文提出的基于多维度模糊综合评价方法得出的结果,与市面上某工具的评估结果相比,在同样的评估数据源中进行同等权重配置,在最终得到的结果上本文方法发现的问题率偏高1%~2%,综合得分偏差较小,因此本文方法具备一定的有效性和准确性,并可成功应用在实际的数据治理项目中,为数据治理中的数据质量管理工作做出了一定程度的改进和优化。 本文提出了一种基于多维度的模糊综合评价方法,将传统的数据质量评估指标体系扩展到了8个维度,20个二级指标,优化了权重的制定方法,提高了本方法的准确性。同时采用基于隶属度函数的模糊综合评价法进行数据质量模糊概念的转化,使定性转变为定量,最终得到科学有效的数据等级。本研究方法在实际项目中的真实数据进行实验,并与当前市面上主流的质量评估软件的评估结果进行比对验证,结果表明本方法与主流质量评估方法一致性达到90%以上,具有良好的可信性。同时本文也存在一些局限:一是本文权重的制定需要融合德尔菲法和层次分析法,此两种方法需要大量的调研工作,且对于参与调研者的要求较高,需要被调研者熟知待检测数据方能产生较为可靠的权重集;二是本文所制定的数据质量评估体系是较为全面的,但是实际评估工作过程中,需要根据数据实际情况和具体业务流程有所选择。 参考文献 [1] 李庭辉. 基于匹配性的GDP数据质量评估研究[D]. 湖南大学, 2012. [2] Meyen D, Willshire M J. A Data Quality Engineering Framework[C]// Conference on Information Quality. DBLP, 1997:95-116. [3] Wang R Y. A product perspective on total data quality management[J]. Communications of the Acm, 1998, 41(2):58-65. [4] Eppler M J, Wittig D. Conceptualizing Information Quality: A Review of Information Quality Frameworks from the Last Ten Years[C]// Fifth Conference on Information Quality (IQ 2000). 2000:83-96. [5] Kahn B K, Strong D M, Wang R Y. Information quality benchmarks: product and service performance[J]. Communication of the ACM,2002, 45(4): 184-192. [6] Yang W L, Strong D M, Kahn B K, et al. AIMQ: a methodology for information quality assessment[J]. Information & Management, 2002, 40(2):133-146. [7] Pipino L L, Lee Y W, Wang R Y. Data quality assessment[J]. Communications of the Acm, 2002, 45(4ve):211-218. [8] Batini C, Cabitza F, Cappiello C, et al. A Comprehensive Data Quality Methodology for Web and Structured Data[J]. International Journal of Innovative Computing & Applications, 2007, 1(3):448-456. [9] 王淑贞.数据准确性在企业信息化中的应用研究[J].中国管理信息化,2014,17(16):41. [10] 王欣. 修正Benford分布律及其在数据准确性评估中的应用[D].天津财经大学,2016. [11] 吴骋,秦婴逸,肖翔,等.病案首页数据质量的量化评估方法研究及应用[J].中国病案,2016,17(03):10-13. [12] 丁小欧,王宏志,张笑影,等.数据质量多种性质的关联关系研究[J].软件学报,2016,27(07):1626-1644. [13] 刘伟涛, 顾鸿, 李春洪. 基于德尔菲法的专家评估方法[J]. 计算机工程, 2011(s1):189-191. [14] 单美静. 基于AHP法的移动支付安全风险评估[J]. 计算机科学, 2015,42(11A):368-371. [15] 王珏,乔建忠,林树宽,等.基于综合隶属度函数的模糊支持向量回归机[J].小型微型计算机系统,2016,37(3):551-554. [16] 赵星,李石君,余伟,等.大数据环境下Web数据源质量评估方法研究[J].计算机工程,2017,43(2):48-56.






3 案例应用





4 结 语
猜你喜欢
第一财经(2022年6期)2022-06-15
心理学报(2022年5期)2022-05-16
中国典型病例大全(2022年12期)2022-05-13
建材发展导向(2021年10期)2021-07-16
新世纪智能(语文备考)(2021年11期)2021-03-08
当代陕西(2020年17期)2020-10-28
军事运筹与系统工程(2019年1期)2019-11-16
建材发展导向(2019年11期)2019-08-24
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
