
基于变更类型和相似性比较的代码重构模式识别
2018-05-23 11:46孙美荣杨春花
智能计算机与应用 2018年2期
孙美荣 杨春花

摘 要: 在现代软件开发和维护中重构是提高软件可维护性和软件质量的常用手段。而大量重构模式掺杂在日常的bug修复、功能增加等代码变更中,使得变更理解变得非常复杂。因此,提出一种对常见的抽取方法和抽取类重构模式的识别算法。研究基于工具ChangeDistiller和JDiff分别获取变更类型和抽取代码块,通过判断移动后的代码块与原文件变更代码的关系,识别采取的重构模式。该算法在4个开源项目中进行实验,其平均准确率在80%左右。
关键词: 重构模式;抽取方法;抽取类
Abstract:Refactoring is a common way of improving software maintainability and software quality in modern software development and maintenance. In daily revision refactoring patterns are usually mixed with code changes accomplishing other tasks such as bug fixing and feature addition which makes the change understanding very complicated. The paper proposes an identifying algorithm for refactoring patterns including the extract method and extract class. It is based on ChangeDistiller and JDiff that are used to get code changes types and extract code blocks respectively. Then the algorithm will identify the refactoring pattern according to the characteristics of the relationship between the changed codes and the original codes. The algorithm has been tested on 4 open source projects with an average 80% accuracy.
Key words: refactoring patterns;extract method;extract class
引言
重構[1]是现代软件开发和维护中用于提高软件可维护性和软件质量的常用手段。现代的软件开发一般基于版本管理系统设计实现,软件工程师为了维护系统或提高系统的性能每天会提交大量的代码。而大量重构模式掺杂在日常的bug修复、功能增加等代码变更中,使得代码评审者和软件工程师在理解代码时不得不对代码进行人工探查,以区分哪些变更的代码是重构,哪些不是。因此,为了使得变更的代码易于理解,将重构模式从代码变更中隔离出来是非常必要的。
重构[2]是一种基于规则、经过训练、有条不紊的程序整理方法,在整理过程中可以将不小心引入的错误降低。重构是处理代码坏味的一种常用手段。当前,在对重构方法的研究方面包括基于K-最近邻的C克隆代码重构方法[3]、使用抽象语法树和静态分析的克隆代码自重构方法[3]、基于抽象语法树和多态机制的复杂条件语句自动重构研究[4]、长方法坏味重构选择策略[5]等等。
重构模式的识别是在变更后的代码中寻找符合特定重构模式的代码修改,是重构的反过程。刘阳[6]等人提出了一种重构检测算法,是基于版本元素匹配原理,对函数抽取重构进行了识别,但是并没有涉及其它类型的重构模式。
通过对4个开源项目的变更代码进行探查,研究发现抽取方法、抽取类等是最为常见的重构模式。因此,本文对这2种重构模式进行了研究,提出了识别的算法。
1 抽取方法与抽取类的重构模式的识别
1.1 抽取方法与抽取类模式
图1是抽取方法(Extract Method)模式的示例。其中,V1是变更前的版本,V2是变更后的版本。对比两版本,V2中多了一个含参数的新增方法printDetails,且V1 中4~5行的内容抽取到V2的新增方法5~7行中,则在V2相对于V1删除代码的位置有对方法printDetails进行调用。
抽取方法的表现形式有3种,分别是:没有局部变量的代码块移动、有局部变量的代码块移动、对局部变量再赋值。图1中的抽取方法重构是有局部变量代码块移动模式。
抽取类(Extract Class)[7]重构模式,一般用于处理过长的类。一个类如果包含过多的功能及属性,会导致这个类过于臃肿。为了提高类的高内聚,低耦合,就会将一些不必要的或不常用的方法提炼到另一个类中,来为这个类服务。如图2 是一个抽取类模式的示例,用类图形式展示。类Person中过多的属性officeAreaCode和officeNumber以及功能代码getTelephoneNumber()被抽取到了一个新类TelephoneNumber中,且在移动代码的地方增加对新类的引用。
1.2 识别方法
1.2.1 抽取方法模式识别
根据上述抽取方法和抽取类模式的例子,不难发现,属于抽取方法和抽取类两种模式的代码变更具备如下3个特性:
(1)文件中有新增方法或提交的revision_id中含有新增类文件。
(2)抽取代码块移动到某个方法中。
(3)在删除代码的位置有对该方法的引用。
为了识别这3个特性,研究借用ChangeDistiller(https://bitbucket.org/sealuzh/tools-changedistiller/src/)工具获得一个文件变更前后所有的代码变更类型。这是Fluri[8]等人编写的一个Tree differ 算法,对变更前后抽象语法树进行对比,获取分类的变更。同时,也可以区别多种方法类型的变化或类等级上的变化。
但是ChangeDistiller只能获取原有方法中的新增语句,不能获取新增方法中的语句体。为此,研究又对ChangeDistiller进行了些许扩展,使其可以返回每个代码变更的代码行或代码行范围。例如,对于一个新增方法printDetails,ChangeDistiller返回的变更类型为ADDITIONAL_FUNCTIONALITY: printDetails()。扩展后,将返回该方法的行号范围5~10。
基于每个新增方法变更的行号范围,研究中借用文本比较工具JDiff(https://maven.apache.org/archives/maven-1,x/plugins/jdiff)来获取该方法的方法体。JDiff是一种面向行的文本比较(text diff)工具,用于显示同一文件2个版本之间的更改。
另外,对于新增方法中的代码块和删除的代码块之间的移动关系判断,进一步借助了Levevshtein(https://en.wikipedia.org/wiki/Levenshtein_distance)算法。Levevshtein是一种计算2个字符串间的差异程度的字符串度量(string metric)算法,即一个单词变成另一个单词要求的最少单个字符编辑数量(如:删除、插入和替换)。
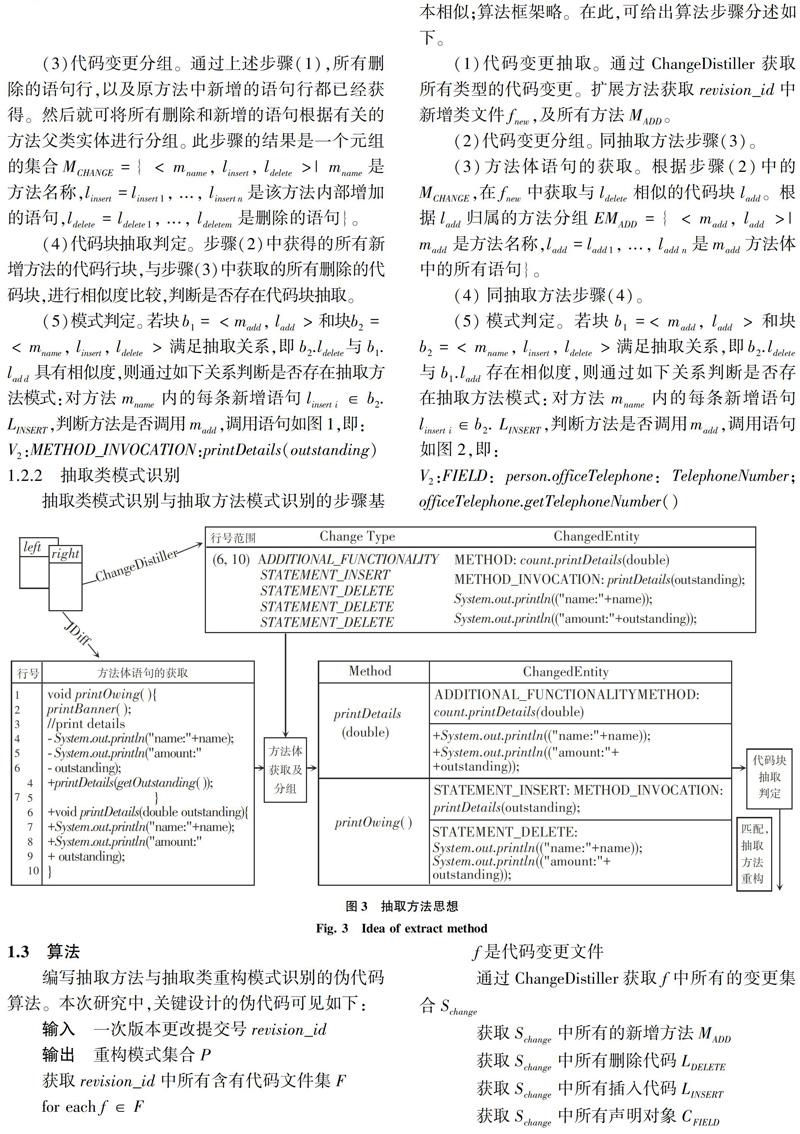
图3显示了该算法的框架,其中left,right分别表示变更前后的两文件,left是变更前版本,right表示变更后版本。研究可得算法设计流程如下:
(1)代码变更抽取。通过ChangeDistiller获取所有类型的代码变更,包括新增的方法、删除的语句、原方法中新增的语句等。一个代码变更由变更类型(ChangeType)、变更实体(ChangeEntiy)和变更双亲实体(ParentEntity)构成。根据研究中对ChangeDistiller的扩展,对每个新增方法madd,将对应一个行号范围(beginline endline)。
(2)方法体语句的获取。根据新增方法的行号范围通过JDiff获取代码块。此步骤的结果是一个元组的集合EMADD={
(3)代码变更分组。通过上述步骤(1),所有删除的语句行,以及原方法中新增的语句行都已经获得。然后就可将所有删除和新增的语句根据有关的方法父类实体进行分组。此步骤的结果是一个元组的集合MCHANGE={ < mname linsert ldelete >| mname是方法名称,linsert =linsert1 ... linsertn是该方法内部增加的語句,ldelete = ldelete1 ... ldeletem是删除的语句}。
(4)代码块抽取判定。步骤(2)中获得的所有新增方法的代码行块,与步骤(3)中获取的所有删除的代码块,进行相似度比较,判断是否存在代码块抽取。
(5)模式判定。若块b1=
V2:METHOD_INVOCATION:printDetails(outstanding
1.2.2 抽取类模式识别
抽取类模式识别与抽取方法模式识别的步骤基本相似;算法框架略。在此,可给出算法步骤分述如下。
(1)代码变更抽取。通过ChangeDistiller获取所有类型的代码变更。扩展方法获取revision_id中新增类文件fnew,及所有方法MADD。
(2)代码变更分组。 同抽取方法步骤(3)。
(3)方法体语句的获取。根据步骤(2)中的MCHANGE,在fnew中获取与ldelete相似的代码块ladd。根据ladd归属的方法分组EMADD={
(4)同抽取方法步骤(4)。
(5)模式判定。若块b1=
V2:FIELD: person.officeTelephone: TelephoneNumber;officeTelephone.getTelephoneNumber()
1.3 算法
编写抽取方法与抽取类重构模式识别的伪代码算法。本次研究中,关键设计的伪代码可见如下:
对给定某个程序的2个相邻版本
算法伪代码中第5行通过ChangeDistiller可知f是否为变更文件;第13行中的mname是根据Schange.cparententity获得;第28行中的新增文件fnew是根据本次提交的revision_id与上次revision_id-1进行比较获得;第29行根据类的反射机制获取fnew中的所有方法Madd;第47行返回所有成功识别的重构模式集合P。
2 实验验证
2.1 数据源
为了验证实验的可执行性,过程中通过minigit(https://github.com/3ofcoins/minigit/)工具获取了4个开源项目进行验证。分别为:jEdit、maven、goole_guice、eclipse,利用MySql根据各项目提交的日志筛选出将近10年的重构revision_id,然后对筛选出的重构revision_id进行人工检测,表1即为筛选出的抽取方法、抽取类两种重构模式的基本详细信息。具体内容详述如下。
(1)jEdit( http://sourceforge.net/project/jedit/)是一个跨平台的文本编辑器。数据获取时间段为:1998/09/27~2012/08/08,本次实验人工检测JEdit发生重构的revision_id数目为45个版本,含有的总文件数目548个。
(2)maven(http://maven.apache.org/dowload.cgi)是对象模型(POM),可以通过一小段描述信息来管理项目的构建、报告和文档的软件项目管理工具。数据获取时间段为:2003/09/02~2014/01/29,本次实验人工检测maven发生重构的revision_id数目为123个版本,含有的总文件数目为1 494个。
(3)goole_guice(https://github.com/apress/goo-gle guice),读作"juice")是超轻量级的,下一代的,为Java 5及后续版本设计的依赖注入容器。数据获取时间段为:2006/08/23~2013/12/12,本次实验人工检测goole_guice发生重构的revision_id数目为25个版本,含有的总文件数目为567个。
(4)eclipse(http://www.eclipse.org/downloads/eclipse-packages/)是一个开放源代码的、基于Java的可扩展开发平台。数据获取时间段为:2001/06/23~2013/10/16,本次实验人工检测eclipse发生重构的revision_id数目为20个版本,含有的总文件数目为175个。
2.2 结果及实验分析
图4、5是变更前后的两文件,图6是该算法对这一变更检测的详细信息输出。
图4、图5给出了ChangeDistiller获取的新增方法injectMirror,以及由JDiff结合Levenshtein获取的抽取代码块,ML(502~514)方法体行号范围。
该实验对4个Java开源项目中的数据进行验证,每个项目中有30~100个重构revison_id版本,对表1中的数据进行验证,因为每个revison_id版本中包含多个文件,所以重构检测不止对一个文件进行操作。通过实验后检测得到的实验結果,可见表2。
通过表2可以得出,该实验测定运行的抽取方法和抽取类的检测结果的平均准确率为80%,准确率在75%~82.5%之间略有波动。准确率没有达到100%的原因与相似度值选取有关。本文是借用Levenshtein算法比较两字符串的相似性,对于阈值的选取是关键原因。阈值选取过高,降低了准确率;阈值选取过小,则会大大降低查准率。因此,对代码相似度算法的选取也是后续研发的重要工作之一。
3 结束语
本文中,研究提出一种基于ChangeDistiller和文本差异工具识别变更代码中重构模式的算法,并通过4个开源试验成功识别了抽取方法和抽取类两种重构模式。未来工作可有针对性地围绕如下工作展开研究:
(1)获取更多的相关数据进行验证。
(2)对Extract Superclass、Move Method等模式进行研究。
参考文献
[1] MURPHYHILL E PARNIN C BLACK A P. How we refactor and how we know it[J]. IEEE 31st international conference on Software Engineering. Vancouver BC Canada:IEEE 2009:287-297.
[2] FOWLER M BECK K ROBERTS D et al. Refactoring improving the design of existing code[M]. Sebastopol CA:Addison-Wesley Professional 1999.
[3] 于冬琦 彭鑫 赵文耘. 使用抽象语法树和静态分析的克隆代码自动重构方法[J]. 小型微型计算机系统 2009 30(9):1752-1760.
[4] 刘伟 胡志刚 刘宏韬. 基于抽象语法树和多态机制的复杂条件语句自动重构研究[J]. 电子科技大学学报 2014 43(5):736-741.
[5] 马飞飞 吴海涛. 长方法坏味重构选择策略[J]. 计算机应用 2014,34(s1):284-286,293.
[6] 刘阳 刘秋荣 刘辉. 函数抽取重构的自动检测方法[J]. 计算机科学 2015 42(12):105-107.
[7] FOKAEFS M TSANTALIS N STROULIA E et al. Identification and application of Extract Class refactorings in object-oriented systems[J]. Journal of Systems & Software 2012 85(10):2241-2260.
[8] FLURI B GALL H C. Classifying change types for qualifying change couplings[C]//International Conference on Program Comprehension (2006). Athens Greece:IEEE 2006:35-45.
