
基于潜在语义分析的文本指纹提取方法
2018-06-14 07:38崔彤彤崔荣一
中文信息学报 2018年5期
崔彤彤,崔荣一
(延边大学 计算机科学与技术学院 智能信息处理研究室,吉林 延吉 133000)
0 引言
随着社会的不断进步、信息技术的飞速发展,网络空间的信息资源以惊人的速度不断增长,越来越庞大的数据量不仅给网络空间带来了压力,同时对网络资源的有效利用也带来了巨大的挑战。因此,对网络空间信息数据的压缩存储和有效组织管理显得尤为重要[1]。数字指纹作为新兴的数字版权保护技术,类似于人的指纹,具有唯一标识的特点。它可以将任何一个数据信息(文字、图像、语音、视频等等),用一串固定长度的随机数来表示,作为区别它和其他数据信息的数字指纹。该数字指纹在加密、信息压缩和处理中有着广泛的应用。文本数字指纹即是对一段文本数据的压缩,一般通过哈希函数来完成,只要哈希函数设计得好,任何两个数据信息的指纹都很难重复,因此不同文本的数字指纹是完全不同的。
在实际的数字指纹生成方案中,产生数字指纹的关键算法是伪随机数产生器算法(PRNG),常用的算法有Rabin算法、MD5算法和SHA-1算法[2],它们是将一个任意长的信息变成固定长度(128位或者160位等)的二进制随机数。其中MD5、SHA-1在大文件的指纹生成中具有较高的性能,而在小文件的指纹生成中,三者具有同样的性能。然而由于哈希函数具有较强的“雪崩效应”,因此它只能检测信息是否被篡改,而不能量化信息内容的修改程度。
Simhash算法[3]由Charikar于2002年提出,该算法实质上是对只负责将原始内容尽量均匀随机地映射为一个签名值的传统Hash算法的一种改进。与传统哈希函数不同的是,Simhash对于原始内容相近或相似的文本所生成的数字指纹也是相似的。其主要思想是使用传统哈希函数对提取的特征计算哈希值,然后通过加权、累加等步骤得到最终的二进制数字指纹,最后使用数字指纹间的差异来衡量原始文档内容的相似程度。Manku[4]将该算法用于海量网页的去重,它被认为是目前最好、最有效的相似网页去重算法之一,近年来Google公司也使用该算法对网络中的海量网页进行去重。此外,该算法也被广泛应用于文本和图像的快速去重[5-7]、反作弊[8]、检索[9-12]等领域。
以上数字指纹生成方法均是基于哈希函数产生的,而哈希函数产生的数字指纹位数固定且本身存在着随机性,因此其生成的数字指纹严重缺失原文的语义信息。为此,本文提出一种基于潜在语义分析的指纹提取方法,该方法根据文本主题映射和随机超平面原理对文本生成k位(主题数目)数字指纹,该k位的数字指纹用k维向量进行表示。指纹位数随文本主题个数的变化而变化,相较于固定长度的数字指纹能够更好地反应文本的语义,更好地表征原始数据。
1 潜在语义空间的构造
潜在语义分析[13-14](latent semantic analysis,LSA)又称潜在语义索引(latent semantic lndex, LSI),是一种信息检索技术,主要用于改善搜索引擎的查询性能。它主要基于以下假设: 在以词项作为特征的原始空间中,任何一个词项在文档中的出现都不是随机的,而是围绕一个或多个主题的词项集合。因此,我们潜意识里认为在以词项作为特征的原始空间中,词项与词项之间、词项与文档之间,以及文档与文档之间一定存在着一种潜在的语义结构。LSI就是根据词项在文档中的共现关系探查文档间的语义联系。
若n篇文档中出现m个词项,则文档集可表示为实数矩阵A∈Rm×n,称之为文本特征矩阵或词项-文档矩阵,其元素值(A)ij为词项ti在文档dj中所占的权重,表示该词项与该文档之间的相关程度。一般情况下,A是高维稀疏矩阵。奇异值分解(singular value decomposition, SVD)[14]是构造LSI空间的重要算法,它可以将文本特征矩阵A分解成三个矩阵的乘积,如式(1)所示。
(1)
其中Ur∈Rm×r,Σr∈Rr×r,Vr∈Rn×r,且r=rank(A)为矩阵A的秩。
在文本信息处理中,这三个矩阵有着非常清楚的物理意义。Ur的每一行对应特定的词项,列向量是相互正交的单位向量,构成表示文档的基向量,它们代表文档集中的不同“语义”维度,(Ur)is给出的是词项i和第s个“语义”维度之间关系的强弱程度。Vr的每一行对应文档集中的特定文档,列向量也是相互正交的单位向量,代表文档集中的不同“语义”维度,(Vr)js给出的是文档j和第s个“语义”维度之间关系的强弱程度。Σr是对角矩阵,其对角线上的元素为A的全体(共r个)非零奇异值,按行递增顺序从大到小排列,这些奇异值表示文档集包含的各“语义”维度的权重。
LSI是SVD在文本特征矩阵中应用的产物。从物理意义上讲,LSI是原始特征的线性组合,它通过奇异值分解,并只保留Σ矩阵中的前k个最大的奇异值来达到去噪和同义词归类的目的。从文本表示角度上看,这一处理结果构造了原始文档特征矩阵A的一个低秩逼近Ak,其中k为降秩后的秩,一般远小于原始特征矩阵的秩:k=rank(Ak)< (2) 其中矩阵Ak仍是一个m×n实数矩阵,但现已变成低维密集矩阵。Uk∈Rm×k的全体列向量所组成的k维线性空间构成文本的潜在语义表示空间(LSI空间),A中的任一文档可通过Uk映射到该空间而得到其LSI表示。由式(2)可得原始文档集的LSI映射表示R,推导过程如式(3)所示。 (3) 上述矩阵R即为原始高维稀疏矩阵A在LSI空间的低维密集表示。这一映射不仅起到了降维的作用,还保留了原始空间的语义信息。LSI能够较好地体现共现词所表达的潜在语义层面上文本间的相似性,对于合适的k值,可解决部分一义多词问题,进而提高检索效率。 本文提出的基于潜在语义分析的文本指纹提取方法主要包括文本预处理、向量空间表示、潜在语义空间构造及指纹生成四个部分,具体流程如图1所示。 图1 指纹提取流程 (1) 文本预处理 文本预处理主要包括分词、词性词频统计、去停用词等。中国科学院计算技术研究所研发的NLPIR系统分词精度可达98.45%,是当前主流的汉语词法分析器之一,主要功能包括中文分词、词性标注、命名体识别等,同时支持用户自定义词典。本文采用该分词系统对待处理的n篇文档进行快速分词和词性标注,并统计词频;然后利用词性去掉对文章贡献较少的停用词(助词、语气词等)和标点符号,保留重要词项,则被保留下来所有词项的集合T={t1,t2,…,tm}即为文档的特征集。 (2) 向量空间表示 采用向量空间模型(VSM)[15]对原始文本进行向量空间表示。将预处理得到特征集中的每一个词项作为向量空间中的一维,则每一篇文档都被一个m维的特征向量所表示。因此,n篇文档特征向量表示的集合即为文档集的向量空间表示。该向量空间是文档集的特征空间,描述词项和文档间的相关性,其相关程度可用词项在文档中所占的权重来衡量,典型方法是采用词频与逆文档频率之积,如式(4)所示。 (4) 其中tfij为词项ti在文档dj中出现的频次,idfi为文档集中出现词项ti的文档频次之倒数。上述wij即为式(1)中文本特征矩阵A的元素值(A)ij。根据不同的需求,权重可采用不同的形式。 (3) 潜在语义空间构造 随着文档数量的增多,其向量空间维度也越来越大且越来越稀疏。为节省存储空间、去除噪声、实现一义多词合并,本文利用SVD获取原始高维稀疏空间特征之间的潜在语义联系,并通过式(3)将原文本特征矩阵转换到LSI空间,得到与其相对应的低维LSI空间表示R,这样做不仅使维数降低许多,还保留了原始空间的语义信息。 (4) 指纹生成 根据随机超平面原理,将LSI空间的R矩阵转换为二进制数字指纹,转换原理及其合理性分析本文将在2.2节中进行阐述,转换规则如下: (5) 文本之间的相似程度可通过指纹间的汉明距离来度量。 本文提出的文本指纹提取方法是在潜在语义分析的基础上,根据随机超平面原理[3]对文本进行语义指纹提取。提取过程如下: (1) 根据式(3)将m×n维文本特征矩阵A转换到LSI空间R; 当采用余弦相似度度量文本间相似性时,如果向量u和的夹角为θ,则当θ=0时,两向量重合,方向完全相同;θ=π/2时,两向量正交;θ=π时,两向量方向完全相反。此时,用主题超平面去分割两个向量的夹角,则被分开的概率就为θ/π,因此向量u和指纹对应位不同的概率也为θ/π。所以我们可以用两向量指纹对应位不同的个数来衡量两个向量的差异程度。因此,提取文本指纹后,原始文本间的相似程度可以采用汉明距离来衡量。 对于给定文档集D={d1,d2, …,dn},其中dj=(w1j,w2j,…,wmj)T(j=1,2,…,n),wij表示第j篇文档的第i个特征(见式(4)),由此可构造文本特征矩阵A=[d1,d2, …,dn]∈Rm×n。完整的指纹提取算法和相似度计算算法描述如下: 算法1指纹生成算法 Input: Term_Document matricA=[d1,d2, …,dn] Output: Fingerprint {R1,R2, …,Rn} do SVD(A); fori←1 ton do forj←1 tom ifRij>0 thenRij=1 elseRij=0 return{R1, R2, …, Rn} 算法2指纹相似度算法 Input: Fingerprint matricR=[R1,R2, …,Rn] Output: Similar matricS fors←1 ton do fort←s+1ton doS(s,t)=(k-sum(RiRj))/k; returnS 其中sum(RiRj)的值为对二进制向量Ri和Rj进行异或运算后各位求和。 为验证本文提出数字指纹生成方法的准确性和有效性,利用本文提出的方法进行了文本间相似度实验和聚类实验,并将实验结果同Simhash算法和VSM方法进行了对比。该实验的实验设备及环境为: Intel Xeon CPU E3-1230 v3处理器,8GB内存,Windows 10,64位操作系统,Visual Studio 2013和Matlab R2015a。 实验数据选自知网上的计算机、医学、教育、历史、法律、政治等六个领域的学术文献,共1 000篇。对数据集中文档做相应预处理后所得到的不同词项数量为26 037个,最终指纹位数使用“SVD前k个特征值之和占特征值总和的80%以上”的原则,经计算得k=170,即文档最终指纹位数为170位,而Simhash算法生成指纹的位数固定为128位。 利用本文提出方法,对学术论文集中的论文文本提取语义指纹,然后根据指纹计算文本间的相似度,最终采用类内平均相似度和类间平均相似度两个评价指标来衡量本文方法的有效性。 假设现有一个含有m类文档的数据集A,A=(C1,C2, …,Cm)(m为数据集中文档的类别数),其中第i类文档中包含文档ni篇。则对数据集中文档进行相似度计算,第i类内n篇文档的类内平均相似度(Sim_W)即为类内所有文档间相似度的和与类内文档对个数的比值;第i类和第j类的类间平均相似度(Sim_B)即为类间文档相似度的和与类间文档对个数的比值。计算公式如式(6)~式(7)所示。 其中,S(s,t)与2.2节指纹相似度算法中指纹相似度矩阵S相对应,表示第i类内第s篇文档与第t篇文档之间的相似度。指纹相似度矩阵S按文献领域的不同进行顺序排列,第i类文档的起始位置为si,即S矩阵中第i类文档数据位于si~si+ni-1行区域内。 图2是三种方法类内平均相似度的对比情况,其中横轴表示六类文档,纵轴表示对应类别文档的类内平均相似度,取值范围为[0,1]。图中三条曲线,从上到下,五角星、圆形、星号分别对应Simhash方法、本文方法和VSM方法的类内平均相似度。不难看出,在多数类中,本文方法的类内平均相似度高于VSM方法,且低于Simhash方法。这是因为VSM方法和Simhash方法都仅仅是通过文档间所使用的词项来衡量其相似程度,所以对于词项重叠率较低的文档,VSM方法计算的相似度会偏低,虽然Simhash方法所得相似度高于本文算法,但并不代表该方法衡量的相似度准确,好的文档表示应具有较高的类内平均相似度和较低的类间平均相似度,还需要参照类间平均相似度对其进行评价。 图2 类内平均相似度曲线 图3是三种方法类间平均相似度的对比情况。与类内平均相似度结果一样,本文提出方法的类间平均相似度仍然处于VSM方法和Simhash方法之间。值得注意的是Simhash方法的类间平均相似度和类内平均相似度都在0.50以上,也就是说它认为文档集中的所有文档都很相似,这显然是不合理的。而本文方法所得的类间平均相似度在0.3~0.4之间,低于其类内平均相似度(0.4~0.7),由此看出本文方法能够更好地区分文档集中的不同类文档。 图3 类间平均相似度曲线 根据本文方法提取的语义指纹,对学术论文集中的论文文本进行聚类实验,采用查准率、查全率、F值对聚类效果进行评价。则对于任何人工标注簇pj和聚类簇Ci,相应的三种评价标准[16](查准率、查全率和F指标)计算公式如式(8)~式(10)所示: 通过式(10),对每一个人工标注簇pj,我们可定义其Fmax值,如式(11)所示: (11) 进一步,对所有簇的F值作加权平均,则可得到整个聚类结果的F值,如式(12)所示。 (12) 其中,式(11)为某个人工标注簇的F值,式(12)是通过评价全局所有的人工标注簇来评价整个聚类结果,最终结果成为Class_F值,它对聚类结果优劣的整体区分能力较强。 表1所示是本文方法、VSM方法和Simhash方法在学术论文集上的聚类结果。 表1 聚类实验结果对比 表中元素表示的是文本采用本文方法、VSM和Simhash表示时,使用K-means算法对文本聚类所得聚类结果的准确率和召回率的平均值、F值及Class_F值。表中可看出相较于其他两种表示方法,采用本文方法对文本表示时,其聚类结果的准确率、召回率、F值均有提高,尤其是F值和Class_F值提高幅度较大。主要是因为本文实验采用知网上的学术论文作为实验数据,其文本间所使用词项的重叠率较低,实验数据比较自然。因此,当采用VSM方法和Simhash方法表示文本时其召回率较低,同时导致F值和Class_F值也较低。 分别采用VSM方法、Simhash方法和本文方法对文本进行表示,并基于三种表示对文档进行了相似度实验和聚类实验。实验结果表明: 在文本间相似度实验中,本文方法具有较高的类内平均相似度和较低的类间平均相似度;在聚类实验中,采用本文方法对文本进行表示时所得聚类结果的准确率、召回率、F值以及Class_F值均优于其他两种方法。因此,本文提出的指纹提取方法能够更好地表征文本的潜在语义信息,进而证明了本文提出方法的准确性和有效性。 目前常见的数字指纹提取方法大多数都使用哈希函数来完成,由于其本身的随机性和雪崩效应,其多部分被用于内容相近或近似相同的去重、近似检测、检索等领域。为弥补数据潜在含义的缺失,本文针对中文文献提出了一种基于潜在语义分析的文本指纹提取方法,该方法通过潜在语义分析将原始的高维稀疏文本特征空间转换到低维密集的LSI空间,然后根据随机超平面原理对文本生成数字指纹。在此过程中,LSI所获取的每一个潜在语义主题特征都会决定一位数字指纹,使得最终生成的文本指纹携带原文语义信息,可以有效地对原文进行语义压缩表示。通过与Simhash方法和VSM方法的对比实验,验证了本文提出方法能够更加精确地表征原始文档。 本文所提出的指纹提取方法选取tf_idf作为词项权重值,所以其计算需要耗费大量时间,此时可采用并行环境来减少计算时间,提高其计算效率。另外,本文方法较适合于大量长文本,对短文本的指纹提取准确率往往得不到有效保证。若对短文本进行指纹提取,可利用其他模型提取文本特征,再对其生成数字指纹。 [1] 吴纯青, 任沛阁, 王小峰. 基于语义的网络大数据组织与搜索[J]. 计算机学报, 2015, 38(1): 1-17. [2] 刘文龙.数字指纹关键技术研究[D]. 北京: 北京邮电大学硕士学位论文, 2015. [3] Charikar M S. Similarity estimation techniques from rounding algorithms[C]//Proceeding of the 34th Annual ACM Symposium on Theory of Computing. Montreal, Canada: ACM, 2002: 380-388. [4] Manku G S,Jain A, Sarma A D. Detecting near duplicates for web Crawling[C]// Proceedings of International Conference on World Wide Web. Banff Canada: ACM, 2007: 141-150. [5] 李纲,毛进,陈璟浩.基于语义指纹的中文文本快速去重[J]. 现代图书情报技术, 2013, 29(9): 41-47. [6] 陈露,吴国仕,李晶.基于语义指纹和LCS的文本去重方法[J].软件,2014, 36(11): 25-30. [7] Yi Y. Research on large scale documents deduplication technique based on Simhash algorithm[C]//Proceedings of International Conference on Information Sciences, Machinery, Materials and Energy.Chongqing, China: Atlantis Press, 2015: 1226-1229. [8] 徐济惠.基于Simhash算法的海量文档反作弊技术研究[J]. 计算机技术与发展, 2014, 24(9): 103-107. [9] 白如江,王晓笛,王效岳.基于数字指纹的文献相似度检测研究[J]. 图书情报工作,2013,57(15): 88-95. [10] 罗文俊,孙志蔚.基于Simhash的密文同义词检索方法[J]. 武汉大学学报(理学版),2014,60(5): 459-465. [11] 罗新高.基于Simhash的海量视频检索研究[D]. 湘潭: 湘潭大学硕士学位论文, 2015. [12] 杨旸,杨书略,柯闽.加密云数据下基于Simhash的模糊排序搜索方案[J].计算机学报,2017,40(2): 431-444. [13] 刘云峰,齐欢.潜在语义分析权重计算的改进[J].中文信息学报,2006,19(6): 64-69. [14] 卢健. 潜在语义分析在文本信息检索中的应用研究[D]. 武汉: 华中科技大学硕士学位论文, 2005. [15] Salton G, Wong A, Yang C S. A vector space model for automatic indexing[J]. Communications of the ACM, 1975, 18(11): 613-620. [16] 周昭涛. 文本聚类分析效果评价及文本表示研究[D]. 北京: 中国科学院计算技术研究所硕士学位论文, 2005.2 文本指纹提取方法
2.1 指纹提取基本过程

2.2 指纹提取方法

3 实验结果与分析
3.1 文本间相似度实验
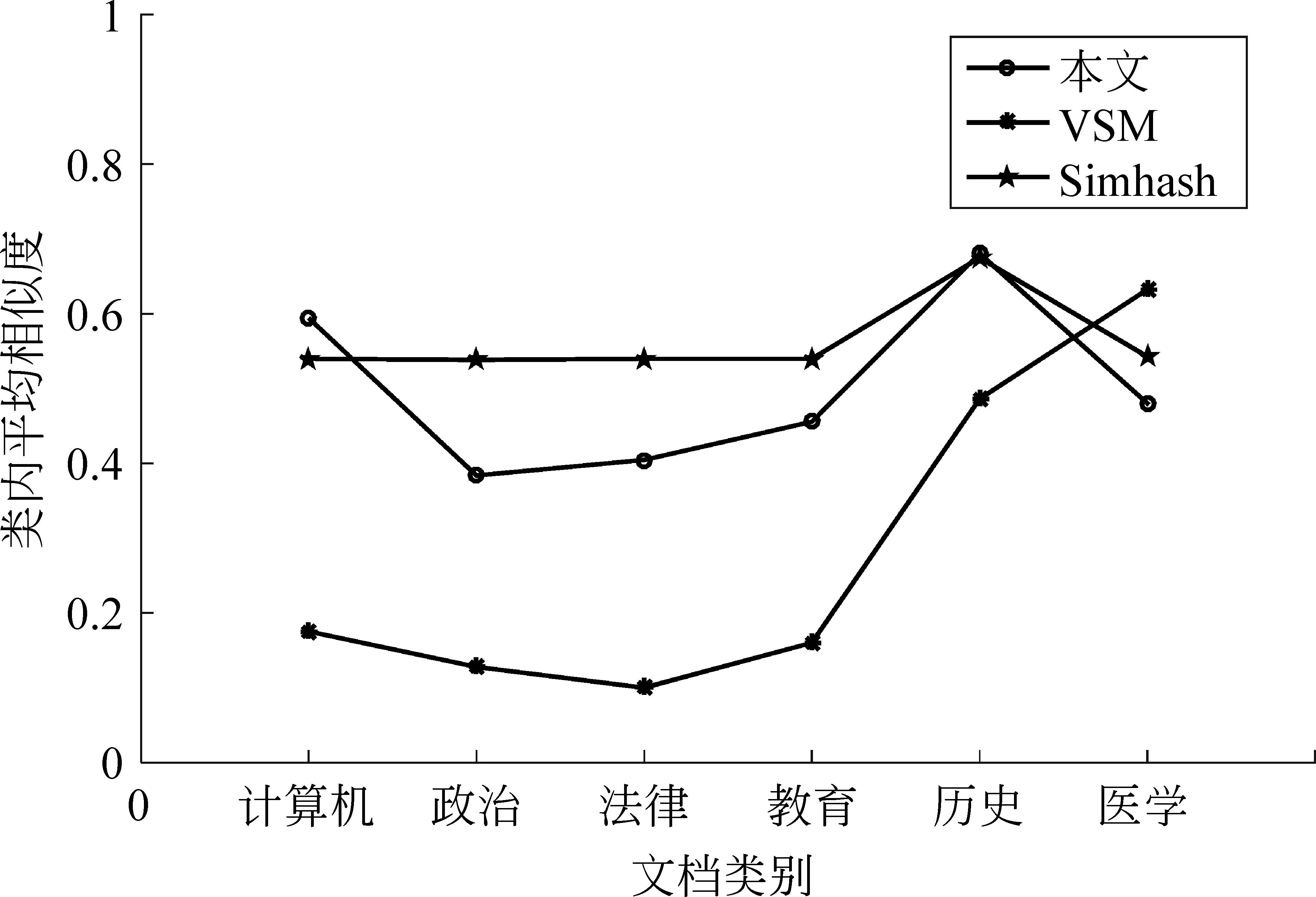

3.2 文本聚类实验
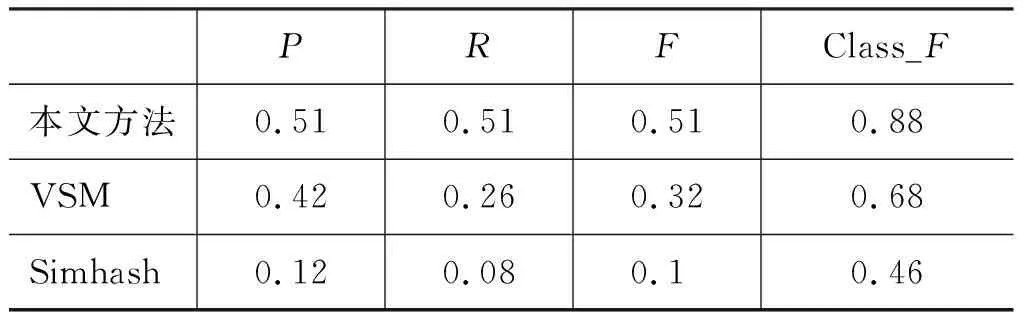
4 结论
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
小哥白尼(趣味科学)(2021年11期)2021-02-28
小天使·一年级语数英综合(2020年10期)2020-12-16
哲学评论(2018年1期)2018-09-14
大学教育(2017年5期)2017-05-10
电脑爱好者(2017年7期)2017-05-06
儿童时代·快乐苗苗(2016年2期)2016-10-22
西南交通大学学报(社会科学版)(2015年4期)2016-03-29
