
基于Python的数据信息爬虫技术
2018-06-19 03:19西安工业大学魏程程
电子世界 2018年11期
西安工业大学 魏程程
1.引言
随着互联网时代的迅速发展,Web已成为大量信息的载体,如何能从中有效地提取并利用这些信息成为一个巨大的挑战。用户通过访问Web检索信息的工具一般都是传统的搜索引擎,而其具有一定的局限性,比如说,不同领域、不同背景的用户往往具有不同的检索目的和需求,而传统的搜索引擎所返回的结果往往包含大量用户不关心的网页。为了解决这类问题,爬虫技术应运而生。
利用c++和java进行爬虫的程序代码,c++代码复杂性高,而且可读性、可理解性较低,不易上手,一般比较适合资深程序员编写,来加深对c++语言的理解,不合适初学者学习。Java的可读性适中,但是代码冗余较多,同样一个爬虫,java的代码量可能是Python的两倍。Python作为一种语法简洁、面向对象的解释性语言,其便捷性、容易上手性受到众多程序员的青睐,本文主要介绍如何利用python进行网站数据的抓取工作,即网络爬虫技术。
2.网络爬虫技术
网络爬虫[1],也叫网络蜘蛛(Web Spider),如果把互联网比喻成一个蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,沿着网络抓取自己的猎物(数据)。爬虫指的是:向网站发起请求,获取资源后分析并提取有用数据的程序;从技术层面来说就是通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频)爬到本地,进而提取自己需要的数据,存放起来使用。简单的爬虫架构如图1所示。

图1 爬虫架构图
爬虫调度器是用来启动、执行、停止爬虫,或者监视爬虫中的运行情况;在爬虫程序中有三个核心模块:URL管理器,是用来管理待爬取URL数据和已爬取URL数据;网页下载器,是将URL管理器里提供的一个URL对应的网页下载下来,存储为一个字符串,这个字符串会传送给网页解析器进行解析;网页解析器,一方面会解析出有价值的数据,另一方面,由于每一个页面都有很多指向其它页面的网页,这些URL被解析出来之后,可以补充进URL管理器。这三部分就组成了一个简单的爬虫架构,这个架构就能将互联网中所有的网页抓取下来。
网络爬虫的基本工作流程如下:
● 首先选取一部分URL作为种子URL;
● 将这些种子URL加入待抓取集合;
● 从待抓取的URL集合中取出待抓取的URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取的URL集合;
● 分析已抓取URL集合中的URL,分析其中的其他URL,并且将URL放入待抓取URL集合,从而进入下一个循环;
● 解析下载下来的网页,将需要的数据解析出来;
● 数据持久化,保存至数据库中。
2.1 URL管理器
URL管理器管理待抓取的URL集合和已抓取的URL集合,防止重复抓取和循环抓取,如图2所示。

图2 URL管理器图解
URL管理器的实现方式有内存、关系数据库和缓存数据库三种,内存适合个人或小型企业,如果想要永久存储或是内存不够用,小型企业或个人可以选择关系数据库,缓存数据库由于其高性能,被大型互联网公司青睐。
2.2 网页下载器
网页下载器作为爬虫的核心组件之一,是将Web上URL对应的网页下载到本地的工具。常用的Python网页下载器有urllib2基础模块和requests第三方插件两种。urllib2支持功能有:支持直接url下载;支持向网页直接输入的数据;支持需要登陆网页的cookie处理;需要代理访问的代理处理。
urllib2有三种下载方法:
1)直接下载法,这是最简洁的方法:urllib2.urlopen(url)。
2)添加data和http,这里data即指用户需要输入的数据,http-header主要是为了提交http的头信息。将url、data、header三个参数传递给urllib2的Request类,生成一个request对象,接着再使用urllib2中的urlopen方法,以request作为参数发送网页请求。
3)添加特殊情境的处理器
有些网页需要登录才能访问,需要添加cookie进行处理,这里使用HTTPCookieProcessor。
需代理才能访问的使用:ProxyHandler
使用https加密协议的网页:HTTPSHandler
有的url相互自动的跳转关系:HTTPRedirectHandler
将这些handler传送给urllib2的build_opener(handler)方法来创建opener对象,在传送给install_opener(opener),之后urllib2就具有了这些场景的处理能力。
2.3 网页解析器
网页解析器,简单的说就是用来解析html网页的工具,准确的说:它是一个HTML网页信息提取工具,就是从html网页中解析提取出“我们需要的有价值的数据”或者“新的URL链接”的工具。
常见的python网页解析工具有:
1)正则表达式:将整个网页文档当作字符串,然后使用模糊匹配的方式,来提取出有价值的数据和新的url。其优点是看起来比较直观,但如果文档比较复杂,这种解析方式会显得很麻烦;
2)html.parser:此为python自带的解析器;
3)lxml:第三方插件解析器,可解析html和xml网页;
4)Beautiful Soup:强大的第三方插件解析器,可使用html.parser和lxml解析器。
以上这四种网页解析器,是两种不同类型的解析器,其中re正则表达式即为字符串式的模糊匹配模式;BeautifulSoup、html.parser与lxml为“结构化解析”模式,他们都以DOM树结构为标准,进行标签结构信息的提取。而所谓结构化解析,就是网页解析器它会将下载的整个HTML文档当成一个Doucment对象,然后在利用其上下结构的标签形式,对这个对象进行上下级的标签进行遍历和信息提取操作。
下来我们重点学习一下BeautifulSoup,它是一个可以从HTML或XML文件中提取数据的Python第三方库,它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。Beautiful Soup会帮你节省数小时甚至数天的工作时间,其使用方法如下:
第一步:创建BeautifulSoup对象(即DOM对象)。
第二步:搜索节点(find_all,find)。
搜索节点方法:
soup.find_all() --- 查找所有符合查询条件的标签节点,并返回一个列表。
soup.find() --- 查找符合符合查询条件的第一个标签节点。
实例:查找所有标签符合标签名为a,链接符合 /view/123.html的节点。
实现方法1:
>>>> soup.find_all(‘a’, href = ‘/view/123.html’)
实现方法2:
>>>> soup.find_all(‘a’, href = re.compile(r’/view/d+.html’))
第三步:访问节点信息。
比如我们得到节点:I love Python
1)获取节点名称
>>>> node.name
2)获取查找到的a节点的href属性
>>>> node[‘href’]
或者
>>>> node.get(‘href’)
3)获取查找到的a节点的字符串内容
>>>> node.get_text()
3.爬虫的抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
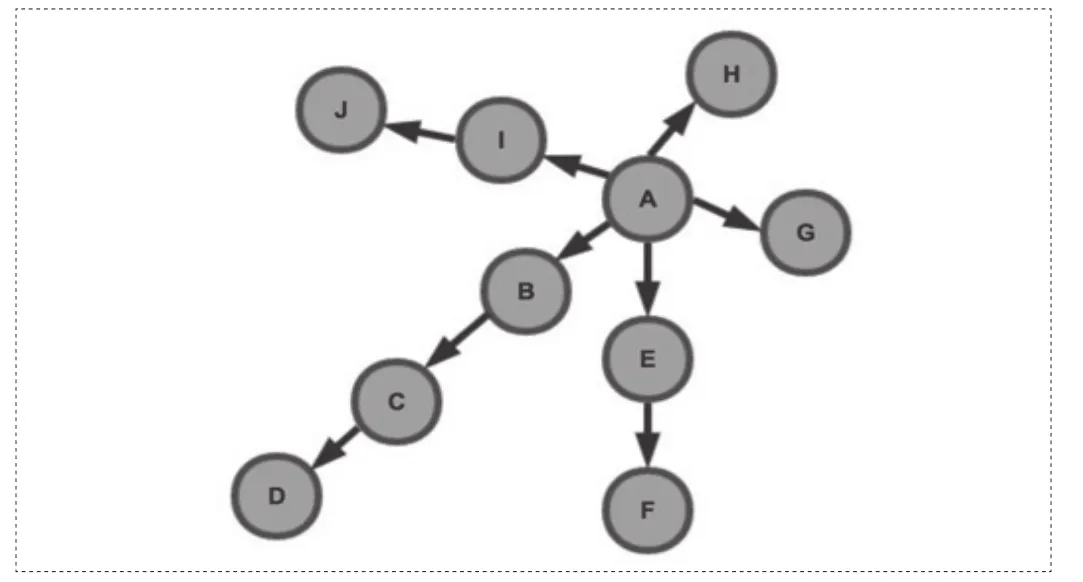
图3 抓取顺序图
1)深度优先策略(DFS)
深度优先策略是指爬虫从某个URL开始,一个链接一个链接的爬取下去,直到处理完了某个链接所在的所有线路,才切换到其它的线路。此时抓取顺序为:A -> B -> C -> D -> E -> F -> G -> H -> I-> J(参考图3)。
2)广度优先策略(BFS)
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。此时抓取顺序为:A -> B -> E -> G-> H -> I -> C -> F -> J -> D(参考图3)。
4.小结
本文介绍了基于Python的数据信息爬虫技术的工作流程,以及爬虫技术中的三大核心模块的使用方法,为日后的研究工作奠定理论基础,对开发设计网络爬虫实例具有一定的指导意义。
[1]Wesley J. Chun. Python核心编程[M].宋吉广译.北京:人民邮电出版社,2008.
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
电脑爱好者(2020年10期)2020-07-28
数码世界(2018年2期)2018-12-21
电子制作(2018年10期)2018-08-04
电子测试(2018年1期)2018-04-18
电子制作(2017年2期)2017-05-17
电子制作(2017年9期)2017-04-17
电子测试(2015年18期)2016-01-14
电子设计工程(2015年12期)2015-02-27
