
基于深度神经网络的低延迟声源分离方法
2018-06-25 07:34钟秀章
无线互联科技 2018年6期
钟秀章

摘要:文章提出了一种基于深度神经网络的低延迟(≦算法延迟20 ms)声源分离方法。方法利用了扩展的过去的上下文,输出软时频掩码用于分离音频信号,比基本的NMF有更好的分离性能。实验表明,基于DNN的方法比起基本的低延迟的NMF方法在不同帧长的处理帧和分析帧上,SDR+均至少提升1 dB,尤其是当处理帧较短时,效果尤为显著。
关键词:声源分离;深度神经网络;低延迟
聲源分离的目的是恢复由多个声源混合而成的混合音中的单个声音。这种技术最常见的用途有语音识别,语音去噪和助听器。所有这些应用都可以采用在线的方式处理声源分离,其中助听器对处理延迟的要求最高,因为当延迟超过20 ms时,听者的不适感显著提高。另外听者能够感受到最低延迟为3 ms。考虑到这样的应用,开发出一种能够处理帧长非常短的声源分离方法就变得很有必要。
有两种流行的声源分离方法:(l)基于组合模型的方法[1],如非负矩阵分解(Nonnegative Matrix Factor, NMF)或某种等价的概率潜在成分分析(Probabilistic LatentComponent Analysis,PLCA)。(2)基于深层神经网络的方法。基于组合模型的方法基于固有结构,将复杂的声学混合信号线性分解成更简单的子单元或组件。另一方面,深神经网络本质上是非线性模型,能够学习复杂的非线性输入和输出之间的映射,输入和输出的关系被嵌入在隐藏层中的权重中。深度神经网络( Deep Neural Networks,DNN)技术在声源分离问题中的应用越来越广泛,比起基于组合模型的方法表现出更好的性能。
对于低延迟的声源分离,文献[2]提出了一种监督的、基于字典的方法。该方法对更前面的上下文数据进行因式分解生成短帧掩码,来预测单通道语音分离中相对困难的场景里用到的分离滤波器的权重。类似的方法可用于基于DNN分离的方法中,可以为非线性的数据建模提供更大的可能。
本文方法主要应用在对低延迟有比较高要求的场景,例如助听器。我们使用来自声音混合信号的频谱特征向量作为DNN的输入,再预测出时频掩码。我们发现把过去时间的上下文加入到DNN的输入中,可以提高短帧低延时处理的性能。我们研究了这种加入时间上下文的时长对分离性能的影响,并将结果与基本的NMF进行了比较。
本文的结构如下:第2节介绍了提出的方法。第3节介绍实验使用的样本数据,用于评估的指标,还有实验设置和结果。第4部分对论文进行总结。
1 基于神经网络的声源分离
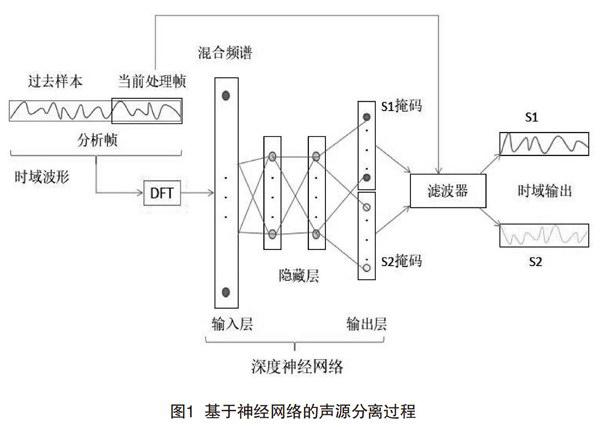
在一般的基于频谱的使用DNN进行声源分离的方法中,混合声音信号的频谱特征作为DNN的输入向量,然后在输出端预测时频掩码。这些掩码滤波器被应用到混合声音频谱的中,以获得重构的单一源谱。在本文的方法中,我们把输入的时域信号进行分块处理。为了确保低延迟,运算在被称为处理帧的短块上进行。延迟取决于该帧的长度,因为在应用离散傅里叶变换( Discrete Fourier Transform,DFT)获得频谱特征之前,必须先缓冲所有的样本。我们建议使用更长的过去时间上下文来生成与当前处理帧相对应的网络输入。这种扩展的时间上下文被称为分析帧。因此,由分析帧导出的频谱特征,作为DNN输入用于预测处理帧的声源分离的掩码,这个过程如图l所示。
1.1输入特征
当前分析帧的频谱特征,是通过短时傅里叶变换(Short-Time Fourier Transform,STFT)产生的。本文使用的窗长等于处理帧的帧长,重叠率为50%。分析帧比处理帧长,它可以生成一组特征向量,再串联成更长的分析特征向量提供给每个处理帧,下面现在详细阐述时频掩码的生成过程。
1.2时频掩码
本文提出的有监督的语音分离方法,目的是为了估计一个合适的时频掩码,可以提高分离出来的语音信号的分离度和清晰度。本文方法中使用的掩码是一个软时频掩码,定义为:
t是某处理帧的索引,/是离散傅里叶变换的索引。Sl和S2是对应语音信号的STFT特征向量。掩码的值的范围是[0,1],保证了数值的稳定性,为神经网络的反向梯度训练提供一个的目标输出。
训练时,对于每个处理帧,通过等式l得到了DNN目标输出。DNN网络的权值是通过相应的分析帧的特征和相应的处理帧的目标输出进行调整的。其目的是从训练数据中获取相关特征,以生成合适的掩码输出。为了使系统的算法延迟较低,处理帧和相应的掩码需要相应地保持得比较短,因为在所有需要的样本被缓冲完之前,不能计算DFT。
1.3源重构
通过掩码M(t,f),可以从混合谱Y(t,f)中分离出己分离信号的STFT复数谱:S,S,等式为:
这里,*表示元素相乘。通过离散傅立叶逆变换(InverseDiscrete Fourier Transform,IDFT)和叠加处理,在线从复数谱中重构出时域源信号的估计。同时,混合信号的频谱的相位也被用于源重构。
2估计
本节阐述评估中使用的指标、数据集、实验设置以及最终得到的结果。我们用有10 000个基原子的NMF作为基线。大的字典有更好的分离性能,因为它们能更好对混合信号进行建模。NMF配置使用的是文献[2]中具有最好性能的NMF配置,从而为基于DNN的系统提出一个很好的基线。
2.1训练数据
本文使用CMU北极数据集‘31来评估基于DNN的语音分离方法。数据集里5对说话人中有3名男性和2名女性。说话人分别为:US-awb,US-clb,US-jmk,US-ksp和US-slt。总共有两对男男混合,两对男女混合,一对女女混合。为了生成每个说话人的训练数据,从数据库的语音集A中随机选出32条语音。给每一对说话人总共生成所有可能的排列共1 024条混合信号作为训练集。测试集是来源于CMU北极数据集B,以确保训练,验证和测试集不相交。每个说话人有10条语音,考虑所有可能的排列,则每对说话人有100条语音。在出现两语音长度不一样时,较短的语音进行补零。所有的语音都为16 kHz的采样率。用于训练DNN的训练集也被用于生成基本的NMF的字典。
2.2評估指标
使用BSS-EVAL评估工具包评估分离性能。它包括3种指标:SIR (Source to Interference Ratio)、SAR (Source toArtifacts Ratio)、SDR( Source to Distortion Ratio)。其中SDR衡量整体的分离性能。在评估时,原时域混合信号以及相对应的时域分离信号被用来计算这些指标。
2.3 DNN的结构和训练
使用Keras深度学习框架来训练DNN。分别为五对说话人训练单独的DNN。DNN有3个隐藏层,每层有250个神经元。隐藏层和输出层的激活函数都是Sigmoid函数,损失函数是均方误差(Mean Square Error,MSE),优化方法为Adam。学习率η=0.001,decay分别为β1=0.9,β2=0.999,这3个参数也是Adam优化中的缺省参数。为了防止过拟合,使用了dropout正则化,批规范化。批规范化,除了保证更快的收敛性外,也能在验证集上取得更好的性能。需要注意的是批规范化使用在隐藏层之间且在隐藏层的Sigmoid激活函数之后。另外,DNN训练时还使用了early stop,若20 epochs后,验证集的损失没有降低就停止训练。
2.4测试条件
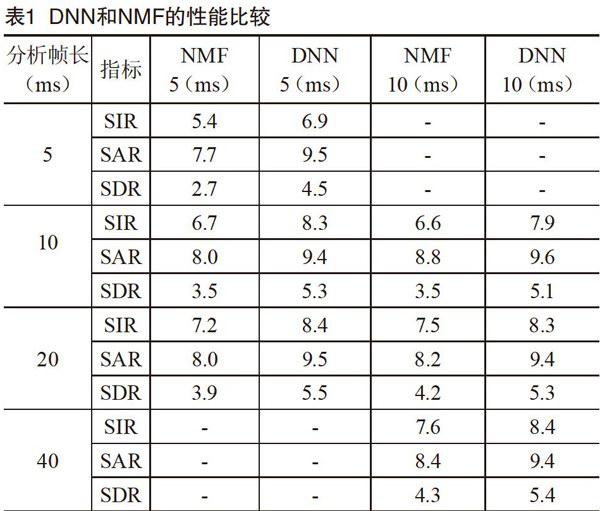
对每对说话人,都用2.2节的评估指标来评估NMF和DNNs。处理帧长分别为5,10和20 ms(见表1)。当涉及低延迟的应用如助听器时,较长的处理帧长度就不合适了。此外,每种长度的处理帧,都结合过去的上下文进行研究。具体而言,分别利用5,10,20,40,80,和160 ms的分析帧的长度进行研究。
2.5结果
计算了5对说话人的分离性能指标,并取平均得出最终结果。不同的分析帧长度的DNN的分离性能如图2所示。据观察,结合过去时间上下文使得处理帧为5 ms和10 ms的性能得到提升,尤其是5 ms。随着上下文时间的变长,性能开始下降,当分析帧是处理帧2-4倍时,性能提升最大。当处理帧长度为20 ms时,性能没有提升。同时,不管处理帧,分析帧的帧长是多少,DNN的分离性能都比NMF好。DNN和NMF的性能比较如表1所示。5 ms和10 ms的处理帧对应5,10,20,和40 ms的分析帧。可以看出,基于DNN方法的性能一直优于其对应NMF。在SDR上,5 ms的处理帧的至少有1.5 dB的提升,10 ms的处理帧至少有l dB的提升。
3结语
本文提出了一种低延迟的基于DNN的单通道盲源分离方法,比起具有最好性能的低延迟基本NMF,它提供了一个更好的分离性能。实验证明结合过去的上下文可以提高分离性能,尤其是处理帧的长度较短时如5ms,性能提升尤为显著,这一观察结果与报告的结果一致。
应该指出的是,分析帧长度增加时,DNN的输入特征向量的维数也增加了。这种情况下,使用的DNN结构可能是次优的,通过增加隐藏层神经元数目或隐藏层层数可能有助于提高分离性能。此外,增加训练数据量也将有助于提高分离性能。本研究利用传统的前馈DNN结构。若使用能对时间依赖性进行建模的网络结构,如长短时记忆(Long ShortTerm Memory, LSTM)有望进一步提高分离性能。
[参考文献]
[IlVIRTANEN T, GEMMEKE J F. RAJ B. et aI.Compositional models for audio processing: Uncovering the structure of sound
mixtures[J] .IEEE Signal Processing Magazine. 2015 ( 2) : 125-144.
[2lBARKER T. VIRTANEN T. PONTOPPIDAN N H.Lowlatency sound-source-separation using non-negative matrix factorisation with
coupled analysis and synthesis dictionaries[Cl.Brisbane: IEEE International Conference on Acoustics, Speech and Signal Processing
(ICASSP) . 2015.
[3lKOMINEK J A. BLACK W.The CMU arctic speech database[J].Processing of Isca Speech Synthesis Workshop, 2004 ( 4) : 223-224.
