
一种基于位置语义和概率的人群分类方法
2018-06-28 09:27邱运芬张晖李波杨春明赵旭剑
数据采集与处理 2018年3期
邱运芬 张晖 李波,2 杨春明 赵旭剑
(1.西南科技大学计算机科学与技术学院,绵阳, 621010;2.中国科学技术大学计算机科学与技术学院,合肥, 230027)
引 言
现代城市由各种各样的功能区域组成,人们每天在这些功能区域中进行不同的社会活动,如购物、上下班、生活和旅游等。同时,随着定位服务的兴起,基于位置服务的应用软件迅猛发展,可以通过位置服务APP获取民众在这些功能区域中活动产生的GPS坐标,如社交软件微信、导航软件高德地图等。深入挖掘移动用户GPS坐标的功能特征,计算其在该功能特征区域出现的概率大小,可以研究移动用户的兴趣爱好,为判断用户类型奠定坚实的基础。例如,若用户A经常出现的GPS坐标的功能特征为餐厅,可猜测A用户对于饮食文化有一定程度的研究,对于研究用户的兴趣爱好具有重大意义。目前,基于GPS坐标的人群分类研究大部分基于出现在相同或地理位置相近的用户通常为同类用户的假设。这种方法具有一定局限性,得到的同类用户基本上都在相同或相近的区域内活动。若用户B经常出入地方的GPS坐标与用户A经常出入的GPS坐标距离相差较大,该方法会认为A与B不是同类用户。但考虑现实情况, 若A与B产生的GPS坐标具有相同的功能特征(如餐厅),他们即为同类用户。故部分学者提出了基于功能特征的人群分类方法,但这部分研究仅局限于探究用户是否拥有相同的功能特征,却忽略了用户访问不同功能特征的不确定性。针对以上问题,本文从功能特征和访问功能特征的不确定性两个方面考虑,从具象GPS坐标引申出抽象位置语义的概念,以更高维度解析用户访问GPS坐标的目的性与意义,并计算用户访问不同位置语义的概率大小,将用户对不同位置语义的访问倾向作为特征进行人群分类,最终得到人群分类结果。
1 相关工作
随着定位技术的高速发展,基于位置服务的应用软件越来越多,更容易获取用户位置数据,因此越来越多的学者投身到基于位置数据的人群分类研究中。到目前为止,按照人群分类特征选取的不同,可分为两大类:基于GPS坐标和基于功能特征。前者认为GPS坐标作为移动用户最重要的特征,是辅助人群分类的重要属性,频繁出现在相同或相近地理位置的用户可视为同类人群,因此部分学者采用频繁模式[1-4]挖掘用户频繁出现的位置坐标法,将其作为用户分类特征。宋衡等[5]采用主成分分析法(Principal component analysis,PCA)提取不同用户经常出现的位置坐标,将其作为分类特征,首先收集3个年级在校学生的位置数据集,利用PCA抽取用户特征,从而对学生进行年级分类。在此基础上,张成等[6]提出了一种基于PCA的单变量贡献度方法,其核心思想为利用最大似然估计算法提取用户分类特征,从而对人群进行分类管理。但是如前文所述,基于GPS坐标的人群分类算法局限于具象的GPS坐标的地域相近性,忽略了用户访问该地理位置的潜在意义。
近年来,很多研究者致力于研究用户访问地理位置的潜在意义,即地理位置隐含功能特征的提取,如发现地区功能特征(Discovering regions of different functions,DRoF)的框架,用于提取地理位置隐含的功能特征[7]。输入移动用户产生的位置数据和先验兴趣点,框架由此计算出移动用户地理位置的功能特征,但该方法的缺陷是需要提前收集用户兴趣点的先验知识,会耗费一定的人力物力。Yuan等[8]先按城市主干道(如高速公路)对地理位置进行区域划分,然后按照时间顺序连接GPS坐标点为用户移动轨迹,在此基础上挖掘功能特征。该方法区域划分粒度不好掌握,如按照高速公路划分区域,会导致功能区域的范围较大。文献 [9]从用户的行为出发,认为用户行为与功能特征密切相关,利用移动用户在该区域内的手机行为(电话、 各类APP使用情况等)推断功能特征。
随着功能特征提取方法的逐渐完善,基于功能特征的各类研究也逐渐成为热门,其中基于功能特征的人群分类也得到部分学者的青睐。Lee等[10]提出了多项传播率(Multiple propagation rate,MPR)算法,该方法抽取用户频繁出现的K个地理位置,并利用用户手机APP的使用情况构建地理位置分类层次图,从中获取K个地理位置代表的功能特征,将这两者作为用户特征进行用户相似性计算。该方法只选取用户的K个频繁点,忽略了总体功能特征访问次数大的地理位置,会造成一定的误差,其次手动构建地理位置分类层次图工作量较大。Xiao[11,12]考虑用户在功能特征间移动的先后顺序,抽取用户移动轨迹,采用最大序列算法计算移动用户移动轨迹的相似度,但在构建用户移动轨迹时并没有考虑用户在不同功能特征地区的出现概率,因此构建的移动轨迹含有不能体现用户生活习惯的点。
针对人群分类的现有问题,本文提出了一种基于位置语义和概率的人群分类方法:首先利用贝叶斯思想,位置语义的分布满足多项分布,迭代求出位置词汇下隐藏的位置语义分布;然后在得到位置语义分配的情况下,选出权重最高的前20个位置词汇,借助百度地图查看位置语义指代的具体含义,如生活区等;最后将用户在位置语义空间下的访问概率向量作为聚类特征向量,找到同类用户,并根据位置语义指代的具体含义确定人群类型。
2 人群分类方法
定义1位置词汇( Location word, LW),用户的GPS坐标,由经纬度唯一标示,具有唯一性,表示为p={pL,pR}(pL表示经度,pR表示纬度)。
定义2位置语义(Location semantic, LS), 位置词汇指代的功能特征,表示为z,z∈{z1,z2,…,zT}。其中,zi表示具体的位置语义,T为位置语义总数。
基于以上两个定义,本文提出的人群分类方法主要分为两部分:位置语义发现和访问概率向量聚类,图1给出了其流程图。如图1(a)所示,输入4个用户的位置数据集,输出位置词汇指代的位置语义。User 1和User 2虽然分别出现在不同的地理位置(茗缘茶楼和尚雅咖啡),但却同时拥有为餐饮区的位置语义;同理,User 3和User 4同时拥有为住宅区的位置语义。经过第1步后,计算用户在位置语义空间的访问概率向量(见图(b))。从图1可知,User 1和User 2对住宅区和教学区这两种位置语义的访问概率偏大,而User 3和User 4对餐饮区这一位置语义的访问概率偏大。最后将访问概率向量作为聚类特征计算用户相似度,得到同类用户。
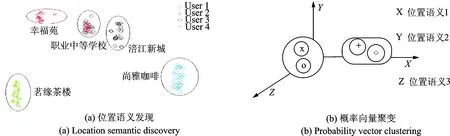
图1 算法流程图Fig.1 Algorithm flowchart
2.1 位置语义发现

位置语义发现主要分为3步:
(1)位置语义抽取满足多项分布,由λ的概率密度可知用户在位置语义空间出现的概率θm满足
(1)
式中:Γ(x)为gamma函数。
(2)设定变量ε,基于ε和θm的取值,提取每个位置词汇的位置语义。ε的取值满足
(2)
式中:ptarg表示目标位置词汇,p表示当前位置词汇,dis(p,ptarg)表示p与ptarg的物理距离,distance表示距离阈值。依次遍历每个用户文档,ε初始值为1。当ptarg与p的物理距离大于distance时,设置ε=1,同时利用θm为p重新分配一个位置语义,并设置ptarg=p;反之,则设置ε=0,同时认为ptarg与p具有相同的位置语义。这样操作的意义是,既能保证相近的位置词汇必定属于同一位置语义,又能让距离较远的位置词汇有机率获得相同的位置语义,符合现实情境。按照经验,用户在某个位置语义内的活动范围一般较集中,同时为避免距离阈值设值太大造成误差过大,本实验中的distance取值为50。
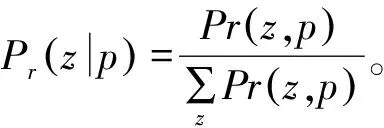
(3)
(3)由式(3)为位置词汇执行分配操作,统计位置词汇在位置语义下的出现次数,使用狄利克雷期望公式[16]更新θm,并重复此步骤,以达到用户访问概率向量收敛,即
(4)
以此得到每个位置词汇的位置语义和每个用户在位置语义空间下的访问概率向量。
2.2 访问概率向量聚类
由定义2可知,位置语义暗示着用户出现在该区域的目的性,表示位置词汇隐含的功能特征,同时,访问概率向量表示移动用户在位置语义空间的出现概率,暗含用户在该区域出现的不确定性。因此,将位置语义和访问概率向量共同作为用户相似性计算标准,既考虑了用户出现在地理位置的深层含义,不再局限于坐标位置的地理限制,也考虑了用户访问不同位置语义的不确定性。如某用户包含一系列位置语义z={z1,z2,z3,z4},分别代表教学区、住宅区、餐饮区和娱乐区,与该位置语义空间对应的访问概率向量为θ={0.4,0.5,0.05,0.05}。综合两者来看,该用户在日常生活中,有访问过4种类型的位置语义,但在教学区和住宅区出现的概率最大,在餐饮区和娱乐区访问概率较小,从而可作出较为合理的推测:该用户可能为学生或教职员工。因此,若要寻找该用户的同类用户,也应包含相同的位置语义,且具有相似的访问概率向量。因此,将用户m在特定位置语义空间的访问概率向量作为人群聚类的特征向量,即有
θm={Pr(z1),Pr(z2),…,Pr(zT)}
(5)
式中:Pr(zi)表示用户在位置语义zi出现的概率,且Pr(z1)+Pr(z2)+…+Pr(zT)=1。使用通用聚类算法对访问概率向量聚类得到的结果即为人群分类结果。
3 位置语义发现和人群分类实验
3.1 实验数据及数据预处理
本文历时两个月(2015-08-13至2015-10-10),收集了某地区的移动用户通过使用位置服务类App所产生的位置数据。收集的数据属性包括经度、纬度和 App名称等信息,其中经度和纬度共同组成位置词汇,APP用于后期用户类型标识,具体说明如表1所示。

表1 数据格式说明
在进行实验之前,需要先对数据进行预处理,避免误差数据影响实验结果。数据筛选包括两类:(1)异常点去除:只保留某地区范围内的位置词汇,过滤掉其他范围的位置词汇,以免造成数据混淆和增大位置语义标识的难度;(2)数据选取:随机抽取1 000个用户,以保证数据选取的随机性。约33万条位置记录进行后期实验,保证数据量充足和实验结果的准确性。
3.2 评价指标
现有的人群分类方法,用户类型的判断大多采用人工标注,在准备实验数据时需耗费大量精力,且受人为因素影响较大。因此,本文从两个方面对实验结果进行评价:内部评价和外部评价。内部评价用于评估访问概率向量在各类聚类方法中的聚合度[17],外部评价则用于评估人群分类结果的正确性,两个评价方式的计算公式分别如式(6,7)所示。
(1) 内部评价指标:Dunn index
(6)
式中:分母表示取分类k中任意两个移动用户的相似度d′(k)的最大值;分子表示取类别i和j的相似度d(i,j)的最小值。D值越高,意味着同簇内用户相似度越高,簇间用户相似度越低,即达到最佳聚合结果,因此D值越高表示聚合度越高。但D值的大小并不能判定人群分类结果的正确性,因此,本文引入了外部评价指标用于评价人群分类正确性。
(2) 外部评价指标:APP类标签。通过对位置数据集和相关研究的深入分析,可知位置语义与产生位置词汇的APP之间存在着一定的关联关系[9]。用户处在不同的位置语义下,会有不同的手机行为,比如,如果用户处于餐饮区,用户则可能使用美团APP,便于搜索附近美食或参与团购。基于此认识,将采集到的位置数据中的APP名称属性作为标注用户类型的依据。采用F-measure指标评价人群分类结果的优劣,其计算公式为
(7)
式中P和R分别表示准确率和召回率。
位置数据集中共包含21种常用APP名称,将其分成5大类,具体如表2所示。由于APP名称出现的次数可近似表示用户访问位置语义的概率大小,因此可根据每个用户位置文档中每种类型APP名称出现的次数来决定用户所属类型,其计算公式为

C=max{Nt,Nf,Ne,Nj,Nc} (8)
式中:Nt,Nf,Nj,Ne和Nc分别表示表2中5种类型APP名称出现的次数,取其最大值作为用户类型标签。
3.3 语义数目选择
在位置语义的提取过程中,语义数T的选择对实验结果及性能影响甚大,因此需要通过实验预先确定其大小。采用困惑度[18]来确定T值,其计算公式为
(9)
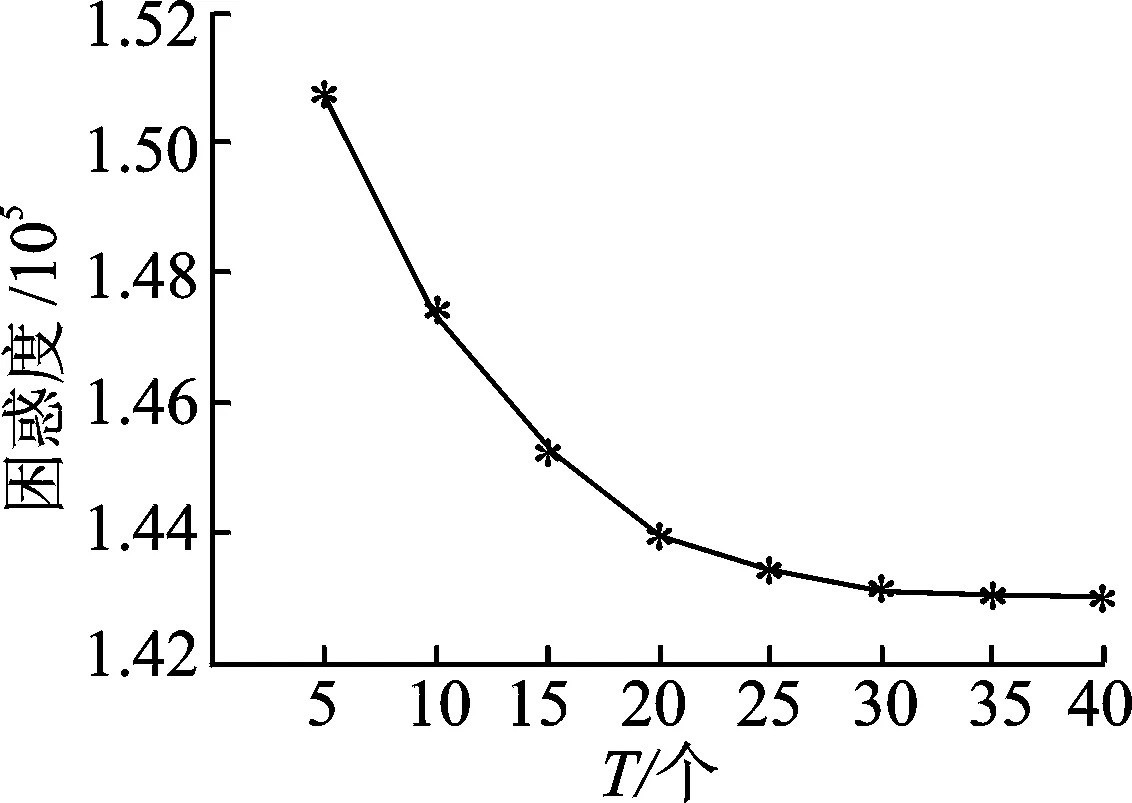
图2 位置语义发现方法的困惑度Fig.2 Perplexity of location semantics discovery method
式中:W表示测试集文档数目,Nw表示测试位置文档w的位置词汇总数;分母表示W个文档的位置词汇总数;Pr(Pω)表示pw的产生概率。实验中,先验分布λ=50/T为初始值,并且将语义数T分别设置每次新增5,采用Gibbs采样[19],分8次实验分别计算困惑度,取其合适的语义数作为后续实验前提,实验结果如图2所示。
从图2可以看出,困惑度随着语义数T的增大而逐渐降低,最后在[25,40]区间趋于稳定。当困惑度越低时,表示模型的泛化能力越强,但同时位置语义数目作为访问概率向量的维数,不宜取值过大,维数过大会影响计算效率。综上两点,位置语义数目取值为30较为合适。
3.4 实验结果与分析
3.4.1 位置语义实验结果
从每个位置语义下选择20个权重最大的位置词汇,借助百度地图,查看每个位置词汇的具体位置语义,得到位置语义的具体含义。表3展示了其中6个位置语义和其权重排名前5的位置词汇。当位置词汇在百度地图中展示为住宅区时,位置语义可解释为住宅区;当位置词汇在百度地图中展示为娱乐休闲场时,位置语义可解释为娱乐区,其他类型位置语义以此类推。从实验结果看出,不同的位置词汇可能拥有相同的位置语义,且本文提出的位置语义发现方法得到的实验结果能准确表达位置词汇所具有的功能特征。
3.4.2 人群分类结果
选择基于位置词汇的人群分类算法PCA[5],基于功能特征的人群分类算法MPR[10]与本文提出的方法进行对比实验。在MPR算法中,参考原文,取频繁出现的50个位置词汇及其位置语义作为分类特征。
为了更全面地比较3种特征选取方法的优劣,选取4种普遍的聚类算法,包括划分聚类K均值(K-means)、密度聚类(Density-based spatial clustering of applications with noise,DBSCAN)、层次聚类(Hierarchical clustering,HC)和吸引力传播聚类(Affinity propagation,AP)[20],尽可能忽略因聚类算法造成的误差,对比3种方法得到的人群分类结果。如3.2节所述,分别采用Dunn index和F-measure作为内部和外部评价指标,4种聚类方法得到的Dunn index值和F-measure值分别如图3和图4所示。

表3 位置语义下的位置词汇

图3 4种算法的Dunn index对比 图4 4种算法的F-measure
由图3可看出,本文提出用于人群分类的特征聚类后得到的聚合度最高,说明本文提出的访问概率向量更利于分类特征的聚合。但如上所述,Dunn index值只能说明本文提出的分类特征更利于聚合,却不能对人群分类结果进行评判。因此,需要用F-measure从另一个方面来评价人群分类结果的优劣。由图4可看出,本文方法得到的F-measure高于另外两种方法。
PCA方法仅能得到访问区域相近的同类人群,对拥有相同位置语义和不同位置词汇的用户不能判断为同类人群,因此分类效果不尽如人意。而MPR算法只抽取用户频繁出现的前50个位置词汇,得到其位置语义,综合考虑位置词汇和位置语义,将其作为用户特征计算相似性,但在本文中位置词汇是GPS坐标,粒度很小,且并没有作精度处理,因此用户频繁访问的GPS坐标完全相同的可能性很低。因此用户频繁出现的前50个位置词汇出现的次数都偏低,并不能完全体现出用户对该位置词汇的频繁访问。而本文的人群分类方法同时考虑位置语义和访问概率两方面,将具象的位置词汇抽象成更高维度的位置语义,挖掘位置词汇更深层的含义,加入用户访问位置词汇的意图,不再依赖于判断细粒度GPS坐标的相似性,提高了人群分类结果的召回率;同时将用户对位置语义空间的访问概率向量作为聚类特征,不再仅依赖于判断用户是否访问过相同的位置语义,并引入用户对位置语义访问概率的不确定性,从而提高了人群分类的准确率。
3.4.3 人群分类结果解释
图5和图6采用更直观的方式展示了基于位置语义与位置词汇进行人群分类的明显区别。由内部评价Dunn index可看出,DBSCAN的聚合度最高,所以选取LS-DBSCAN和PCA-DBSCAN作为对比。图5为采用LS-DBSCAN得到的同类用户,图6为采用PCA-DBSCAN得到的同类用户。从图中可看出,User 2和User 3属于物理意义上的相似用户,访问的位置词汇大多距离相近或相同;而User 1和User 2属于位置语义和访问概率相近的同类用户,更符合现实意义。由此可知,本文的人群分类方法具有更高的召回率和准确率。

图5 LS-商业型用户 图6 PCA-商业型用户
4 结束语
人们在各个功能区域中活动产生的GPS坐标是用户类型判断的重要依据,且用户在不同功能区域,会有不同的手机操作行为。深入挖掘移动用户GPS坐标的位置语义,研究用户访问不同位置语义的概率倾向,对于研究群体用户的兴趣爱好和用户类型具有重要意义。基于GPS坐标的人群分类方法按用户活动区域进行人群划分,得到的同类用户都出入在相同或相近的位置区域,为物理意义上的相似用户;而现有基于功能特征的人群分类局限于判断用户是否拥有相同的位置语义,忽略了用户对位置语义访问的不确定性,没有全面考虑用户在位置语义空间的出现概率。针对上述问题,本文提出了一种基于位置语义和概率的人群分类方法。该方法首先通过位置语义发现方法挖掘位置语义,实验结果表明,该方法得到的位置语义能较准确地说明位置词汇的功能特征;然后结合位置词汇的位置语义分配情况,计算用户在位置语义空间上的访问概率向量,考虑用户在不同位置语义上的访问倾向;其次将用户的访问概率向量作为聚类矩阵,采用聚类方法计算用户间相似度得到同类用户;最后根据位置语义的具体含义,标识用户类型。将位置语义与访问概率向量结合作为人群分类的特征与现有的方法相比具有更高的F-measure值。今后的研究工作将把时间属性加入到位置语义中,抽取位置语义随时间的变化轨迹,进一步挖掘用户在时间维度上的行为模式,并比较用户行为模式间的相似性。
参考文献:
[1] Xue Andyyuan, Zhang Rui, Zheng Yu, et al. Destination prediction sub-trajectory synthesis and privacy protection against such prediction [C] //Proceedings of the 29th IEEE International Conference on Data Engineering. Brisbane: IEEE, 2013:254-265.
[2] Zheng Kai, Zheng Yu, Yuan N J. Discovery of gathering patterns from trajectories [C] //Proceedings of the 29th International Conference on Data Engineering. Brisbane: IEEE, 2013:242-253.
[3] Tang Lu-an, Zheng Yu, Yuan Jing, et al. On discovery of traveling companions from streaming trajectories [C] //Proceedings of the 2012 IEEE 28th International Conference on Data Engineering. Washington: IEEE, 2012:186-197.
[4] Sheng Chang, Zheng Yu, Hsu Wynne, et al. Answering top-k similar region queries [C] //Proceedings of the 15th International Conference on Database Systems for Advanced Applications. Japan: Springer, 2010:186-201.
[5] 宋衡. 基于位置数据的人类行为识别和相似性研究[D]. 上海: 上海交通大学, 2014.
Song Heng. Human behavior recognition and similarity analysis based on location data[D].Shanghai: Shanghai Jiaotong University,2014.
[6] 张成, 刘亚东, 谢彦红,等. 基于PCA与MLE方法的人群分类新方法研究[J].沈阳化工大学学报(自然科学版), 2015, 29(2):168-171.
Zhang Cheng,Liu Yadong,Xie Yanhong,et al. A new method of population classification based on PCA and MLE[J].Journal of Shengyang University of Chemical Technology(Natural Science Edition), 2015, 29(2):168-171.
[7] Yuan Jing, Zheng Yu, Xie Xing. Discovering regions of different functions in a city using human mobility and POIs [C] // Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2012:186-194.
[8] Yuan Nicholas Jing, Zheng Yu, Xie Xing, et al. Discovering urban functional zones using latent activity trajectories [J].IEEE Transactions on Knowledge and Data Engineering,2015,27(3):712-725.
[9] Toole J L, Ulm M, Gonzalez M C, et al. Inferring land use from mobile phone activity [C] //Proceedings of the ACM SIGKDD International Workshop on Urban Computing. New York: ACM, 2012:1-8.
[10] Lee M J, Chung C W. A user similarity calculation based on the location for social network services [C] //Proceeding of the 16th International Conference on Database Systems Advanced Applications. Hong Kong: Springer, 2011, 4(1):38-52.
[11] Xiao Xiang Ye, Zheng Yu, Luo Qiong, et al. Finding similar users using category-based location history [C] //Proceedings of the 18th SIGSPATIAL International Symposium on Advances in Geographic Information Systems. New York: ACM, 2010:442-445.
[12] Xiao Xiangye, Zheng Yu, Luo Qiong, et al. Inferring social ties between users with human location history [J]. Journal of Ambient Intelligence and Humanized Computing,2012, 5(1):3-19.
[13] 蒋铭初,潘志松,尤俊.基于PLSA主题模型的多标记文本分类 [J].数据采集与处理,2016,31(3):541-547.
Jiang Mingchu, Pan Zhisong,You Jun. Multi-label text categorization algorithm based on topic model PLSA[J]. Journal of Data Acquisition and Processing,2016,31(3):541-547.
[14] Li Chengtao, Zhang Jianwen, Sun Jiantao, et al. Sentiment topic model with decomposed prior [C] // Proceedings of the 2013 SIAM International Conference on Data Mining. Austin: SIAM, 2013: 767-776.
[15] Lin Chenghua, He Yulan, Richard Everson, et al. Weakly supervised joint sentiment-topic detection from text [J]. IEEE Transactions on Knowledge and Data Engineering, 2012, 24(6):1134-1145.
[16] Chen Zhiyuan, Liu Bing. Mining topics in documents: Standing on the shoulders of big data [C] //Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York:ACM, 2014: 1116-1125.
[17] Xu Dongkuan, Tian Yingjie. A comprehensive survey of clustering algorithms [J].Annals of Data Science,2015, 2(2):165-193.
[18] Yang Guangbing, Wen Dunwei, Kinshuk, et al. A novel contextual topic model for multi-document summarization[J]. Expert Systems with Applications, 2015,42(3):1340-1352.
[19] 张俊鹏,贺建峰.基于LDA主题模型的功能性miRNA-mRNA调控模块识别[J].数据采集与处理,2015,30(1):155-163.
Zhang Junpeng,He Jianfeng. Identifying of funtional minRNA-mRNA regulator modules based on LDA topic model[J]. Journal of Data Acquisition and Processing, 2015,30(1):155-163.
[20] Brendan J F, Delbert D. Clustering by passing messages between data points[J]. Science, 2007,315(5814):972-976.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
开放教育研究(2020年2期)2020-03-31
铁道通信信号(2019年6期)2019-10-08
雷达学报(2017年6期)2017-03-26
现代语文(2016年21期)2016-05-25
高中生学习·高三版(2016年9期)2016-05-14
互联网天地(2016年1期)2016-05-04
新高考·高二数学(2015年11期)2015-12-23
电子设计工程(2015年6期)2015-02-27
