
HDFS动态副本因子的优化研究
2018-07-25 12:05梁胜昔
计算机技术与发展 2018年7期
宗 平,梁胜昔
(1.南京邮电大学 海外教育学院,江苏 南京 210023;2.南京邮电大学 计算机学院,江苏 南京 210023)
0 引 言
在云计算环境下的数据存储过程中,数据副本对于提高系统可用性和可靠性,以及降低并发访问的响应时间发挥着重要作用。针对云计算环境下默认副本因子机制存在的不足,很多学者提出了对副本因子的改进措施,主要集中在对默认副本因子的动态调整上。
文献[1]利用马尔可夫模型获取文件访问热度并修正预测偏差以对默认副本因子进行更加准确的调整。文献[2]通过数据中心选举和动态副本管理策略,同时结合近期最少使用算法LRU,做到了副本数量优化和系统性能的均衡。文献[3]通过建立概率优化模型,根据约束不等式来计算优化后的副本数量,同时在远端节点选择中引入节点评价系数以优化副本的放置。文献[4]提出的动态副本创建算法(DRCA)将副本调整划分为复制、保持和删除三个阶段,结合文件访问频率算法进行文件访问热度的预测,并综合考虑了其他多种因素对副本数量进行动态调整,从而有效降低了文件访问的时间消耗。文献[5]结合文件block的访问频率,提出了一种基于访问频率的副本算法,通过计算文件block的本地和全局支持率,同时考虑了block访问频率,以优化副本数量,从而达到降低存储空间消耗的目的。事实上,目前云环境下的副本因子策略主要分为静态副本因子策略和动态副本因子策略两大类[6],默认的副本因子一般采用静态副本策略,由于静态副本策略在云环境下存在诸多不足,目前研究热点主要集中在如何通过动态地调整副本数量,在提高性能和可靠性的同时,有效降低副本维护的代价。
1 Hadoop默认副本策略及其存在的问题
开源云计算框架Apache Hadoop[7]的出现,为人类在大数据时代更加科学高效地存储及处理海量数据提供了有力支持,作为Google云计算模型基于Java的开源实现,逐渐成为企业将应用迁移到云中的一个有效方案。在实现海量数据的存储时,Hadoop主要借助开源的分布式文件系统(Hadoop distributed file system,HDFS)来实现文件的高效和可靠性存储,然而HDFS默认的副本机制却成为制约其性能和可靠性提高的一项重要因素[8-11]。
1.1 Hadoop分布式文件系统
HDFS[12-14]主要基于廉价的分布式机器集群,为整个系统提供高可靠、高性能、可扩展和容错性强的分布式存储服务。HDFS采取典型的Master/Slave架构,主要由NameNode、DataNode、SecondaryNameNode三个组件组成,如图1所示。
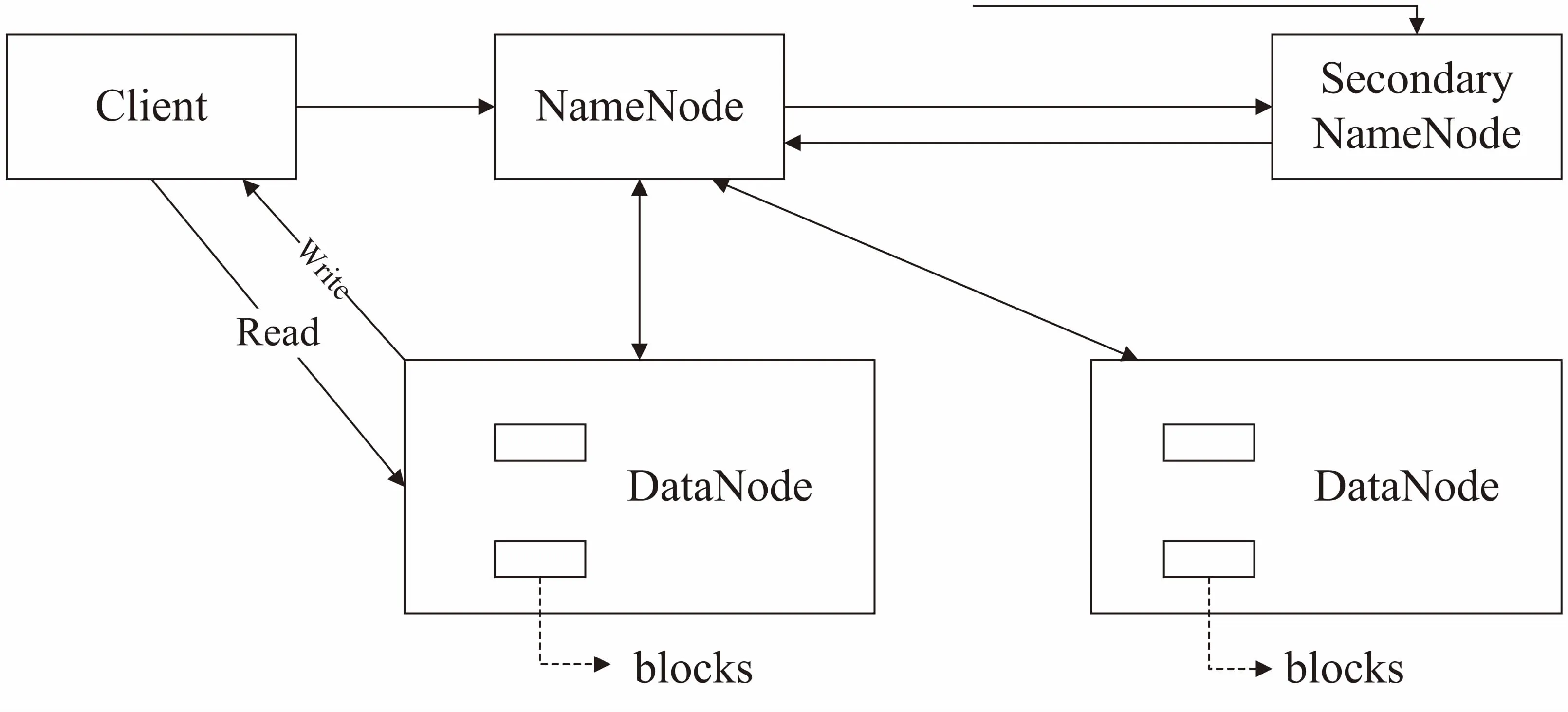
图1 HDFS主要结构示意图
其中NameNode是Master节点,负责存储整个集群的元数据信息,对集群中众多的DataNode节点进行统一管理和维护,同时控制DataNode从节点进行相应的I/O操作;NameNode节点在整个集群中起到了重要的管理和控制角色,为防止发生单点故障,系统中设计了SecondaryNameNode节点以实现对NameNode的备份。DataNode主要负责存储具体的文件数据,并负责接受文件的读/写请求。由于分布式集群中的机器为廉价机器,存在很大的宕机可能性,HDFS通过多副本备份机制来提高系统的可靠性和稳定性,同时这些分布在集群中的多副本还可以提高MapReduce的计算性能。
1.2 默认的副本管理机制
目前主流的副本因子管理策略主要分为两种:静态策略和动态策略。静态副本管理策略通过预先配置的副本因子,是一种较为简单的副本因子实现机制,但缺乏灵活性,无法适应系统环境的变化。过低的副本因子对系统的可靠性和性能会造成影响,过高的副本因子则会极大增加存储空间的消耗,尤其在大数据时代,用户数据量可以达到PB、EB级甚至更高,如果一味通过增加副本因子来提高系统性能和可靠性,无疑会对存储空间利用提出巨大挑战,因此副本因子管理机制需要做到系统性能及可靠性和存储代价的均衡与折中。目前Hadoop系统默认采用静态副本机制,存在较大的优化空间。
动态副本因子策略能更好地适应用户访问频率、存储空间、系统带宽、系统响应时间和网络拓扑等的变化,在运行时刻动态地调整副本因子,根据评价指标对副本数量进行适应性的增加、减少或者保持。动态副本因子往往能够更好地满足云计算中多用户和异构存储环境下的数据访问需求,具有更大的灵活性和针对性,同时能做到性能、可靠性与存储代价等的有效折中。
1.3 存在的问题分析
HDFS默认采用3副本的静态副本机制,不能较好地适应系统的动态变化,包括用户访问频率、异构节点性能和结构等的差异,尤其在云计算中多用户环境下,不同用户对不同文件的访问频率存在较大差异,即文件的访问热度差异较大。如果对访问热度存在较大差异性的不同文件采取统一的副本因子机制,热度偏高的文件因为副本因子过小而不能很好地应对较高频率的访问需求,热度偏低的文件因保留过多的副本数而造成存储空间的浪费。因此动态副本机制是解决多用户环境下,文件访问热度不均对文件访问响应时间以及网络负载造成影响的一种有效方案。但在采取动态副本因子策略的同时,也需要对待调整副本因子的文件进行有效筛选,如果对所有文件采取统一的副本因子动态调整策略会带来较大的时间和空间上的消耗,同时副本调整策略还需要能够有效应对文件访问的突发性需求[15],能够在文件热度突增的情况下保持较高的数据访问性能。
2 改进的动态副本因子调整策略
针对HDFS默认静态副本策略在文件访问热度分布不均的情况下所存在的不足,以及现有的动态副本策略在进行副本因子调整时存在的统一决策和调整的问题,提出了一种改进的动态副本因子调整策略。该策略在根据文件的访问热度进行副本因子调整的同时,还考虑了不同文件热度的优先级,并且根据两种不同长度的时间区间进行副本因子的调整决策,从而可以很好地适应文件访问热度突增的情况。
2.1 相关符号及定义
假设集群中存在的文件数目为n,文件集合记为F={f1,f2,…,fn}。对于文件fk∈F(k∈[1,n]),fk被切分成nk个block分别存储在不同的DataNode节点上,fk被切分成的block集合记为Bk={b1,b2,…,bnk},每个block的大小是bsj(其中j∈[1,nk]),fk的副本数目记为brk。
(1)文件fk在tnow时刻的访问热度FHk。
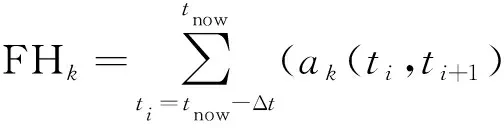
(1)
其中,ak(ti,ti+1)是文件fk在时间区间(ti,ti+1)内的文件访问次数;函数decay(ti,tnow)是文件访问次数对文件热度影响的衰减函数,在时间区间(ti,tnow)内,decay(ti,tnow)定义为:
decay(ti,tnow)=e-(tnow-ti)m,m∈{1,2,3…}
(2)
根据数据访问的时间局部性原理,当前被频繁访问的文件在未来的一定时间范围内存在较高的被再次访问的概率,因此可以根据当前时间之前一段时间区间内的用户文件访问次数对其未来访问热度进行预测。文件fk在tnow时刻的文件热度FHk的大小依赖于tnow之前的Δt时间区间内的文件访问次数,距离当前时间tnow距离越远的文件访问频率,对当前时刻文件热度计算的影响则越小,即这种影响会呈衰减趋势。
(2)文件fk的副本决策因子RDk。
(3)
每个文件对应的副本决策因子RDk用于决策文件副本因子是否需要进行相应的调整。
(3)集群副本决策因子RDcluster。
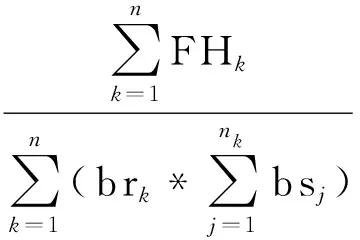
(4)
FHk由距离当前时间Δt时间区间内的访问频率决定,而RDcluster作为系统的副本因子调整阈值,用于对后面副本因子的调整进行决策。
(4)高热度文件。
对于任意的文件fk∈F,如果RDk>a*RDcluster(其中a根据集群整体的性能进行调整,a∈[1,2]),则认为fk属于高热度文件。
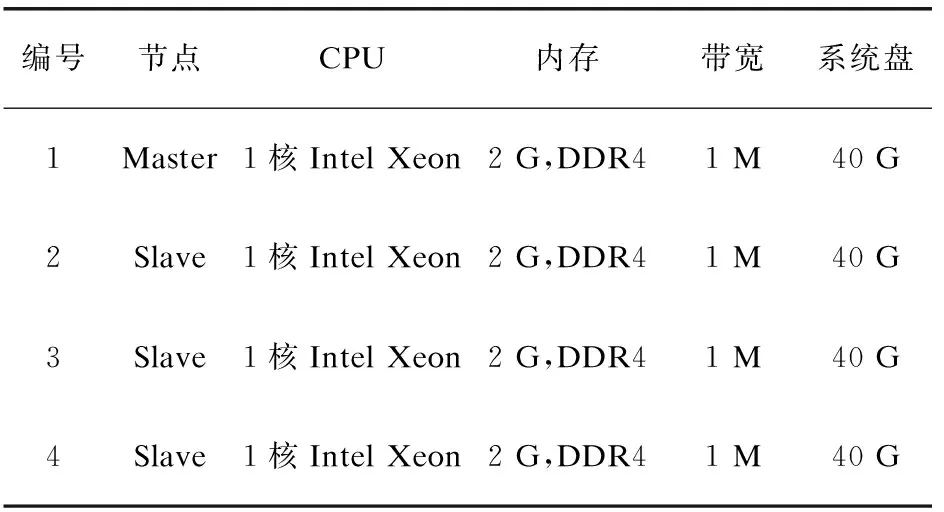
(5)低热度文件。
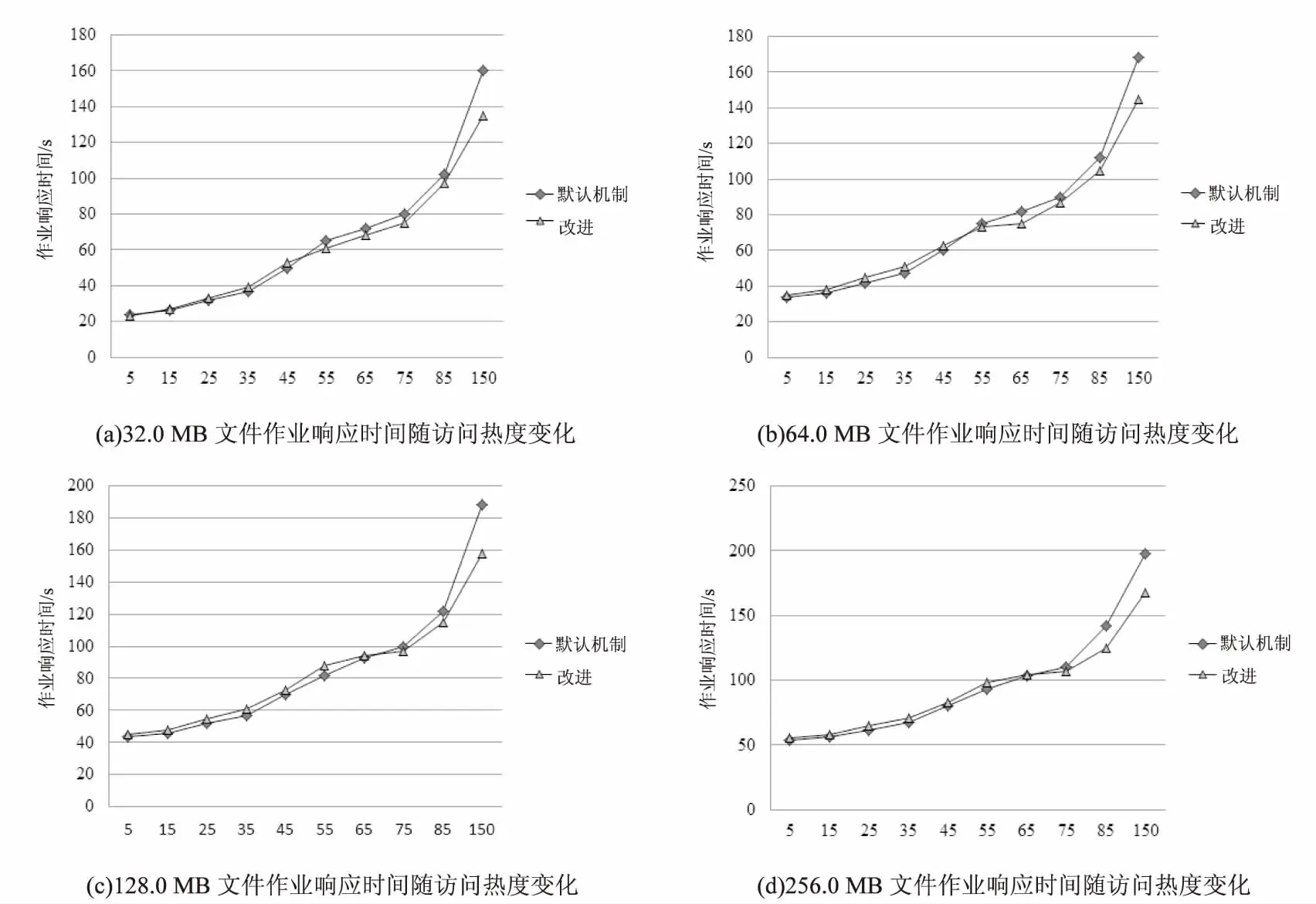
对于任意的文件fk∈F,如果RDk (6)高热度文件fk副本因子动态调整值DVk。 对于上述定义的高热度文件,在决策时间区间Δt内,文件fk的副本因子动态调整值取决于其副本决策因子的相对大小,需要针对默认的静态副本因子λ=3进行动态调整: (5) 其中,RDk为文件fk在距离当前时间Δt的决策时间区间内的副本决策因子;RDmax、RDmin则分别为Δt决策时间区间内副本决策因子的最大值和最小值;λ为HDFS默认的静态副本因子。 改进的动态副本因子调整算法首先根据文件访问热度和副本决策因子值,获取待调整副本因子文件集合,然后针对不同的文件采取不同的副本因子调整策略。 2.2.1 待调整副本因子文件筛选算法描述 算法输入:集群中文件集合F={f1,f2,…,fn},以及两个决策区间Δt1和Δt2。 2.2.2 文件副本因子调整算法描述 2.2.3 改进算法分析 改进算法在实现副本因子调整的过程中,充分考虑了文件访问热度对副本因子调整的影响,具体改进策略有: (1)考虑到文件访问过程中的时间局部性原理,当前访问热度高的文件在未来一段时间内存在较大的被访问概率,因此根据一定时间区间内的文件访问次数对文件访问热度进行定量描述,以此来预测文件在未来的访问概率,从而据此进行副本因子的动态调整。 (2)针对高热度文件访问热度和副本决策因子的计算,设置了两个不同长度的时间区间,其中短区间用于对突发性的文件访问需求进行副本因子调整,避免了长区间对文件副本因子调整所带来的偏差。 (3)在进行文件副本因子调整的过程中,针对不同访问频率所产生的高热度文件和低热度文件,采取了不同的调整措施。对于低热度文件,在对可靠性和性能及存储代价的权衡下,进行相应的副本因子减小;而对于高热度文件,依据不同的访问热度大小,采取不同的副本因子增加措施。 为验证动态副本因子调整算法对系统性能的改进,搭建Hadoop的分布式实验环境进行仿真实验验证,对比分析默认副本机制和动态副本因子调整算法对作业平均响应时间的影响。 基于Hadoop的Master/Slave架构,借助阿里云云服务器ECS搭建分布式的仿真实验环境,该分布式实验平台包含3个Slave节点以及一个Master节点,节点的主要配置如表1所示。 表1 仿真实验节点的主要配置 为模拟用户对集群中不同文件访问热度的差异,设置集群中文件每分钟的访问次数分别为5、15、25、35、45、55、65、75、85、100共10组,以此来反映用户对文件访问热度的变化。此次实验对于高热度文件和低热度文件的判定,设置参数(a=1.2,b=0.8,γ=0.8),调整决策时间区间为Δt1=45 s,Δt2=5 s,设置4组大小不同的文件(32.0 M、64.0 M、128.0 M、256.0 M),比较不同访问热度下系统作业的平均响应时间,得出的作业响应时间随文件访问热度变化的曲线如图2所示。 由图2可知,当文件访问热度较低,文件的热度对副本因子动态调整影响较小,甚至不会触发副本因子的动态增加或减少,而同时由于算法在动态计算过程中本身需要耗费一定的资源和时间,因此会出现改进的副本因子调整机制比默认静态副本机制平均作业响应时间长的情况,即此时动态副本因子调整算法还不能有效发挥其性能提升作用。随着文件访问热度的不断增加,动态副本因子调整算法开始体现出一定的性能优势。 观察图2可以得知当文件每分钟的访问频率达到50~60时,此时由于触发了副本因子的动态增加,因此对于高热度文件会存在多个副本同时对外提供访问服务,有效降低了高热度并发访问下的文件访问竞争,缩短了作业的响应时间。针对高热度文件能够及时动态地增加副本因子,以应对持续或突发性的高热度访问需求,因此可以有效缩短系统作业平均响应时间,实现云环境下多用户文件访问的服务响应性能提升。 图2 作业响应时间随访问热度的变化曲线 提出的动态副本因子调整策略主要针对云环境下静态副本机制存在的局限性,结合云环境下多用户文件访问的热度差异和不同决策时间区间内的访问热度值,对副本因子进行动态调整,在提升文件访问性能的同时降低存储空间的消耗。接下来的工作可以进一步优化副本因子调整算法,以更好地适应复杂云环境下文件突发性的访问需求。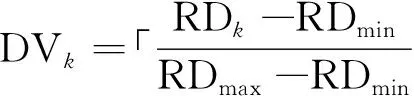
2.2 改进的动态副本因子调整算法
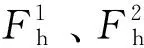
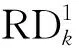
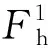
3 实 验
3.1 实验环境与设置
3.2 实验结果与分析
4 结束语
猜你喜欢
卫星应用(2022年7期)2022-09-05
卫星应用(2022年3期)2022-05-23
卫星应用(2022年1期)2022-03-09
今日农业(2021年14期)2021-11-25
意林(2020年10期)2020-06-01
火力与指挥控制(2019年10期)2019-11-19
环球慈善(2019年6期)2019-09-25
网络安全和信息化(2019年8期)2019-08-28
计算机系统应用(2019年2期)2019-04-10
证券市场红周刊(2018年5期)2018-05-14
