
交互式多用户Skyline查询处理算法*
2018-08-15 08:24邵路伊秦小麟王潇逸郭成盖邓丹萍
计算机与生活 2018年8期
邵路伊,秦小麟,王潇逸,郭成盖,邓丹萍
南京航空航天大学 计算机科学与技术学院,南京 210016
1 引言
随着数据库技术的发展,数据库中存储的数据量急剧增加,如何从海量数据中找到人们最感兴趣的信息,为人们做出有效的决策,成为一个重要的研究课题。因此,Skyline查询在2001年作为一种新的数据库操作符被提出来[1],从此得到了数据库领域众多研究者的大量关注。Skyline查询在很多应用中都有着非常重要的作用,例如多目标决策、数据挖掘及可视化,以及用户偏好查询等[2]。数据库领域最初的Skyline查询是由单用户发起的,例如,一个用户发出查询“查找一家价格便宜同时距离海边近的酒店”。然而,在数据管理领域,随着计算环境的不断变化、信息技术的发展和应用新需求的出现,越来越多的数据库应用会涉及到由多个用户共同完成一个查询,例如:
查询1一群游客共同商定一个旅游城市,每位游客针对城市的气候、地理位置、景点以及消费水平等提出不同要求的查询。
查询2一个家庭共同选择一个宽带方案,每位家庭成员针对方案的带宽、价格、合约期限等提出不同要求的查询。
查询3一组同事共同预定一家聚餐餐厅,每位同事针对餐厅的口味、环境、服务以及人均价格等提出不同要求的查询。
上述查询事例可以抽象为:对于某数据集,多个用户发起不同维度组合上的子空间Skyline查询,系统对同时存在的子结果集进行整合,最终返回一个结果集。此类查询可概括为MUSQ(multi-user Skyline query)问题,即多用户Skyline查询问题。在此类查询中,发起查询操作的主体由单用户转变为多用户,并且多数情况下,用户只对数据集的某几个维度感兴趣,并非全部维度。由于用户之间关注的维度不同,在某些数据集上可能会发生查询条件冲突的现象。
研究者对子空间Skyline查询算法已经有了较为深入的研究,包括对某一特定子空间的查询[3]和对全部子空间[4-5]的查询。目前已有的算法均是在单用户场景下设计的,可以得到符合单个用户需求的子Skyline结果集,但是在涉及多用户参与的Skyline查询中无法对同时得到的多个子Skyline结果集进行有效整合。
同时,传统的Skyline算法缺乏交互性。对于用户提出的查询要求,已有的算法通过单次Skyline计算得到查询结果并返回给用户。然而,在实际应用场景中,由于用户的数量增加,且不同用户关注的数据维度不同,用户之间的查询条件存在差异性,单次Skyline计算得到的结果可能无法令所有用户满意。此时,用户与查询结果之间需要交互,用户与用户之间更需要交互,用户根据系统返回结果和其他用户的选择结果来调整自己的需求,使得结果更快地趋向于统一。通过交互,可以使系统返回更符合用户需求的候选集,令用户更好地做出决策。
此外,出于经验、社会地位等因素的考虑,不同用户在决策过程中的地位不同,当某个用户给出的意见更具有专业性,其查询需求则更具有决定性作用。例如,在餐厅选择的例子中,用户A在外就餐的次数多,对餐厅的选择相比其他用户更有经验,因此他的查询意见在最终决定中应赋予更大的权重。而传统的Skyline算法对用户本身的权重没有考虑。在此基础上,本文提出一种基于权重的交互式多用户Skyline查询(weight-based interactive multi-user Skyline query,MUSW)算法,有效处理多用户Skyline查询问题。
本文主要贡献如下:
(1)深入多用户Skyline查询问题,分析传统算法在多用户参与下的不足,提出基于用户权重的MUSW算法,考虑用户在查询选择过程中的权重比例,有效解决了多用户Skyline查询结果的整合问题。
(2)定义了一种满意度度量方法,对子空间Skyline查询后得到的结果进行满意度计算,再利用top-k选取k个满意度高的结果,可以有效控制输出结果的个数。
(3)设计了一套交互查询的机制,通过用户与返回结果以及用户与用户之间的交互,使得结果更符合用户的要求。
本文组织结构如下:第2章介绍Skyline查询的基础知识及相关工作,并分析现有方法在解决多用户Skyline查询时的不足;第3章提出MUSW算法,并对算法进行详尽的解析;第4章对MUSW算法进行实验评估,验证其可行性并检验其性能;最后对本文工作进行总结。
2 基础知识
2.1 Skyline查询概述
首先,介绍Skyline查询中的相关概念。
定义1(支配[1])给定一个d维数据集S,D为d个维度的集合。对于S上的两个数据点p和q,p支配q当且仅当p在任一维度上的取值都不比q差,且至少在一个维度上比q好,记为p≼q。
值得注意的是,不同维度的评判标准不同,由数据集本身的属性定义。
定义2(全空间Skyline)给定一个d维数据集S,以及维度组合U,如果U=D,则称U上所有不被任何其他点支配的数据点的集合为全空间Skyline结果集,记为skyD(S)。
表1为餐厅数据集示例,该数据集有5个数据点,4个维度,其中前3个维度的取值越大越优,第4个维度则相反。根据定义2,当一个用户发出查询“查找口味佳、环境好、服务水平高并且人均价格低的餐厅”,则为全空间Skyline查询,其查询结果为skyD(S)={O1,O2,O3,O4,O5}。
定义3(子空间Skyline)给定一个d维数据集S,以及维度组合U,如果U⊆D,则称U上所有不被任何其他点支配的数据点的集合为子空间Skyline结果集,记为skyU(S)。
同样以表1的数据集为例,此时有3位用户A、B、C分别根据自己感兴趣的数据维度提出了不同的查询。
用户A:查询口味佳且服务好的餐厅。
用户B:查询人均价格低且口味佳的餐厅。
用户C:查询环境评分高的餐厅。
以上3个查询均为子空间Skyline查询,将得到3个维度组合下的子空间Skyline查询结果,分别为skyA(S)={O1,O3}、skyB(S)={O4,O5}、skyC(S)={O2,O5}。
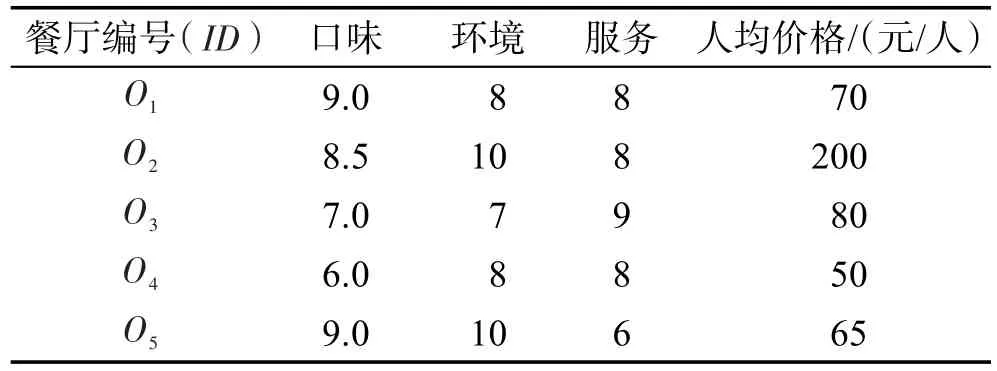
Table 1 Restaurant information data set表1 餐厅数据集示例
2.2 相关工作
传统Skyline查询的研究主要分为全空间Skyline查询和子空间Skyline查询。全空间Skyline查询算法主要包括 BNL(block-nested-loops)算法[1]、SFS(sort first skyline)算法[6]、D&C(divide and conquer)算法[1],以及基于R树索引提出的NN(nearest neighbor)算法[7]和BBS(branch and bound skyline)算法[8],其中BBS算法具有很强的剪枝能力。全空间Skyline的查询结果会随着数据量和数据维度的增加而剧增,意义不大,因此Pei等人[5,9]提出了子空间Skyline查询的概念。研究者对子空间Skyline查询的研究主要包括:Xia等人[10]提出了一种数据结构CSC(compressed SkyCube),对Skyline进行压缩分组,并基于CSC结构给出一个Skyline结果集计算方法QueryCSC;Huang等人[11]提出了SkyCube立方体的概念,他们将Skyline计算的所有子空间建立成一个SkyCube结构,并在此基础上提出了IMASCIR(incremental maintenance algorithm of SkyCube)算法;Tao等人[3,12]首次研究任意单个子空间上的Skyline查询,并给出一种计算任意子空间上Skyline对象的算法SUBSKY。以上传统的Skyline查询算法均针对单用户进行研究,未考虑多用户参与下查询要求的差异性,也没有对各子结果集的整理和融合进行进一步的研究。
考虑到传统Skyline查询在解决问题上的缺陷,研究者对Skyline查询的变种进行研究,其中包括多用户Skyline查询和交互Skyline查询。对多用户Skyline查询的研究如下:对于在分类属性上定义的目标选项和用户偏好,Benouaret等人[13]利用匹配度来计算支配关系,并提出了collective Skyline的概念,将Skyline中数据点的支配要求放松,对一半以上的用户成立即可,从而减少了Skyline结果集的规模;Bikakis等人[14]也利用匹配度,并给出了一种双重基于Pareto的策略,依次在单用户下和所有用户下对目标进行偏序排序;Ali等人[15]基于评价函数提出一种针对组用户查询的策略,致力于找到对一个子用户组而言评价函数最高的结果,且要求子用户组中用户的数量尽可能大;Sato等人[16]给出了一种解决空间数据集上多查询点问题的AMUSE算法,先找到一个子查询组的最优点,再通过k-NN查询找到更优的数据点。这些解决多用户参与的算法中,均没有对用户的重要程度进行划分,同时也没有考虑查询过程中的交互问题。同时,也有研究者对交互式的Skyline查询进行研究。Lee等人[17]提出了一种交互引导框架,针对用户提出的查询,系统分析现有的Skyline结果,推出一些能更新支配关系的重要问题反馈给用户,从而减小Skyline结果集的规模;Chester等人[18]通过增量式地修改Skyline查询要求,动态地调整Skyline的结果,以获得更符合用户真实需求的结果集。但以上的交互查询仅考虑单用户与系统之间的交互性,没有考虑多用户之间的交互对Skyline查询的影响。
综上,现有算法在解决多用户Skyline查询上的研究还很不成熟,在涉及多用户的Skyline查询过程中无法有效整合子Skyline结果集。此外现有的Skyline查询缺乏用户之间的交互性,无法最大程度上满足所有用户的需求。为解决以上问题,本文提出了MUSW算法。
3 基于权重的交互式多用户Skyline查询
3.1 算法的基本思路
为解决多用户Skyline查询问题,本文提出了一种满意度度量方法,由用户权重决定每个数据点的满意度大小。首先给出满意度的定义。
定义4(满意度)对于d维数据集S中的一点oi,满意度W为用户群U对该数据点的总体满意程度,其计算公式为WOi=∑lj(j|oi∈SKYj),其中SKYj为用户uj的子空间Skyline结果集,lj为用户uj对应的权重大小。
由定义可知,满意度由用户的权值决定,当其中一个用户的权重增大,那该点的满意度也增加。本文利用满意度来衡量目标选项的优劣性,满意度越高的目标选择越有可能返回给用户选择。因此,算法的基本思路为,在迭代过程中通过交互来动态调整用户的权值,使权值的比例更符合用户在用户群中的地位体现,从而使得返回的结果集更趋向于用户群的需求。
在多用户Skyline查询问题中,对于初始数据集D={o1,o2,…,om},用户群U={u1,u2,…,un},提出基于各自偏好的查询Q={q1,q2,…,qn}。MUSW算法的解决方案为,通过子空间Skyline查询得到每个用户ui对应的SKYi(SKYi⊆D),接着进行多轮迭代交互,根据用户的权值计算每个数据点oi在第t轮迭代中的满意度,再将本轮的候选集结果返回给用户,系统通过用户的反馈对权重进行动态调整,从而在下轮迭代中对数据点的满意度进行更新,直至交互过程终止。在权重更新过程中,系统对用户投票结果进行分析。在目标决策中,一个专业的决策者会影响其他决策者的选择[19],因此当用户u1参照另一个用户u2的选择时,则说明用户u2更加专业,即u2在用户群中的地位更高。权重是用户地位的体现,因此u2的权重将增大。
以2.1节中表1的数据集为例,A、B、C用户分别提出查询条件,且用户设定返回结果集大小为3。首先,分别对A、B、C用户作子空间上的Skyline查询操作,得到skyA(S)={O1,O3}、skyB(S)={O4,O5}、skyC(S)={O2,O5}。首先考虑3位用户拥有平等的地位,即权值lA=lB=lC=1,根据定义4计算用户对目标Oi的满意度可得而因此将返回满意度W最高的3个目标{O5,O1,O2}作为结果。在后续投票过程中,用户A选择o1,用户B选择o5,而用户C参照A选择了o1。当系统对投票结果进行分析,发现C参照了A的选择,可知A的地位比C更高,因此A的权重将增大,而C的权重相应减小。根据权值变化函数(详见3.5节),系统预定义的常数A取0.5,则在第1轮交互过程中,权值变化值Δl(t)=0.5。因此A相应权值增加为1.5,C的权值减小为0.5,而B的权值保持为1。此时因此将返回{O1,O3,O5}作为结果。随着后续交互的进行,用户的权值越来越趋向于用户真实的需求,而目标选项的满意度由用户的权值决定,那么返回的结果则越来越符合用户的要求。
3.2 MUSW算法
MUSW算法的输入为初始数据集合S、用户集合U和用户理想结果集大小k,输出为更大程度符合用户需求的Skyline结果集SKYk。MUSW算法将查询处理过程分为3个步骤:首先,针对多用户的不同需求,通过SUBSKY算法对原始数据集S进行子空间Skyline查询处理,得到各用户uj对应的子Skyline结果集SKYj组成的集合SUBSKYS;其次,对该结果建立一个基于Map的结果集索引;最后,实现交互流程,通过多轮迭代,最终返回大小为k的最终结果集给用户,对应算法1的第4~5行,具体的交互过程将在3.4节和3.5节中详细介绍。子空间Skyline查询的时间复杂度为O(nlbn),建立Map索引结构的时间复杂度为O(count(subskys)),交互过程的时间复杂度为O[t(count(subskys)+m)](详见算法2)。综上,算法1的时间复杂度为O[nlbn+t(count(subskys)+m)],其中n为数据点个数,count(subskys)为子空间候选集中的数据点个数,m为用户的数量,t为迭代的次数。
算法1MUSW算法
输入:原始数据集合S、用户集合U和用户理想结果集大小k。
输出:交互后大小为k的Skyline结果集SKYk。

3.3 建立基于Map的索引
MUSW算法的第一步是通过SUBSKY算法得到n个用户对应的n个子Skyline结果集集合SubSKYS,在后续的迭代过程中,系统会多次计算子Skyline结果集中数据点的满意度大小,需要对结果集进行多次遍历查询,因此需要对其建立索引减少遍历时间。本文采用基于Map的索引结构,将SKYj中的目标选项oi作为关键字建立索引,并以升序排列,每个关键字映射的内容为所有包含oi的子空间对应的用户群。
以表1中的数据为例,对A、B、C用户做子空间上的Skyline查询操作后得到skyA(S)={O1,O3}、skyB(S)={O4,O5}、skyC(S)={O2,O5},以上3个子结果集组成SubSKYS={O1,O2,O3,O4,O5},对其建立的索引如图1所示。
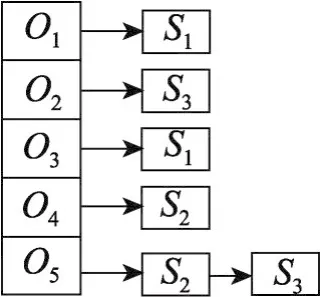
Fig.1 Map-based index graph图1 基于Map的索引图
3.4 用户交互过程
查询过程中,需求的改变会影响Skyline的结果集[19],特别对于多用户参与的查询,用户可以根据查询结果对自己的查询需求进行微调,交互的引入可使用户获得更准确的结果。因此,在得到子空间Skyline结果集的索引后,MUSW算法将通过用户与返回结果的交互,以及用户之间的交互,对用户的权重进行动态调整,使结果趋向于用户的需求,迭代交互过程是核心部分。
算法2用户交互算法Interact
输入:用户理想结果集大小k,子结果集索引IndexOf-SubSky。
输出:交互结果SKYk。

算法2的第1行分别对用户权重和迭代轮次等进行了初始化。其中,在交互之前用户的地位是平等的,因此系统将每个用户的权重初始值设为1。首先,系统通过用户的权重值和满意度计算公式得到子Skyline结果集中所有目标选项的满意度,然后选取满意度最高的k个结果返回,同时将结果显示在交互界面上供用户选择,对应算法2的第3~4行。此时,每个用户选择k个结果中最符合自己需求的1个目标选项返回给系统,系统记录下用户的选择以便之后的分析。根据用户的选择,系统将判断交互是否达到终止条件,一旦条件满足,将终止交互并将当前轮次产生的k个目标选项作为SKYk返回。终止的条件具体为:(1)所有用户均选择同一个目标,则返回以该目标为首的SKYk。(2)该轮迭代后,用户当前轮次的投票结果与上一轮的投票结果相同。若终止条件不满足,将对用户的投票结果进行分析,并根据分析结果相应地更新权重,具体算法见算法3。一轮交互结束后,用户的权重会根据本轮用户的投票选择做出动态调整。由此可知,算法2的时间复杂度为O[t(count(subskys)+m)],其中count(subskys)为子空间候选集索引的数据点个数,m为用户的数量,t为迭代的次数,值得注意的是,由于算法快速收敛,因此t一般很小。
3.5 分析更新算法
权重的变化是根据用户该轮投票结果来进行动态调整的。在目标决策中,一个专业的决策者会影响其他决策者的选择[19],即用户的投票结果会相互影响。而专业的用户,他在用户群里的权重比例更大。因此,算法3对所有用户做以下操作:当用户uj选择的是自身子结果集上SKYj的点,那么其权重值保持不变,对应算法3的第2~3行;当用户uj选择其他用户up的子结果集SKYp的点,那么用户uj的权重会减少Δl(t),用户up的权重值会相应增加Δl(t),保证了所有用户的权重值总和维持在n,对应算法3的第5~8行。其中,每轮交互迭代过程的权重的变化率Δl(t)是有关迭代轮次t的函数f(t)=A/t2,其中A为系统预定义的常数,用户可以根据需求进行调整。综上,哈希技术下Map索引的查询时间复杂度为O(1),因此算法3的时间复杂度为O(m),其中m为用户的数量。
定理1对于给定的数据集D和用户集U,权重更新算法快速收敛,因此MUSW算法的交互迭代过程具有收敛性。
证明在权重更新的过程中,用户权值组的各个元素随迭代轮次发生动态变化。第t轮的权值变化增量为f(t)=A/t2,对∀t0,在t0之后,权值增量总量为而由于权值不完全总在权值组的同一元素中,因此对∀t0,在t0之后,权值组任意元素的增量都将A/(t0-1)。同时,令g(t0)=A/(t0-1),则g′(t0)=-A/(t0-1)2,则在t0足够小时,g(t0)就能够快速收敛,并随着t0的增大快速收敛至0。因此f(t)将随着t0的增大快速收敛至0,即用户的权值组快速收敛至稳定。由定义4可知,满意度由用户的权重决定,则数据点的满意度W也趋向于不变,从而使得返回的结果趋向于不变,因此MUSW算法迭代过程收敛。 □
算法3分析更新算法Analyze
输入:投票结果SelectArray,用户权重LevelArray,迭代轮次t。
输出:更新后的用户权重LevelArray。

4 实验及分析
以下验证MUSW算法的有效性和交互性能,其中验证交互性能的必要性在于,在多用户参与的交互过程中,若系统无法在特定间隔内提供反馈信息将影响用户的交互体验。由于目前尚未有其他专门针对交互式多用户Skyline查询的算法可供比较,本实验中作为对比的Baseline算法为传统单用户下的Subsky算法[13-14]的两种扩展。首先通过Subsky算法获取多个子空间上的子Skyline结果集,然后对所有子结果集分别进行以下两种方式的整合:对所有子结果集做交集处理,对所有子结果集做并集处理,分别记为Baseline-intersection算法和Baseline-union算法。
MUSW算法的有效性将从两方面得到证明:首先,对算法的可行性进行验证,实验过程中,MUSW算法可以得到用户预定义大小的结果集,因此MUSW算法具备可行性;其次,对结果集大小这一指标进行衡量,并与Baseline-intersection算法、Baselineunion算法的执行结果进行对比。
算法的交互性能采用迭代轮次和系统自适应间隔两个指标(见表2)进行衡量。其中迭代轮次为系统与用户之间进行的交互次数,从系统返回候选集、用户投票、系统分析投票结果到更新用户权重值这整个过程为一个迭代轮次。系统自适应间隔,指用户通过交互进行投票后,系统通过分析更新用户权值从而调整目标选项的满意度到可支持下一轮交互的间隔。
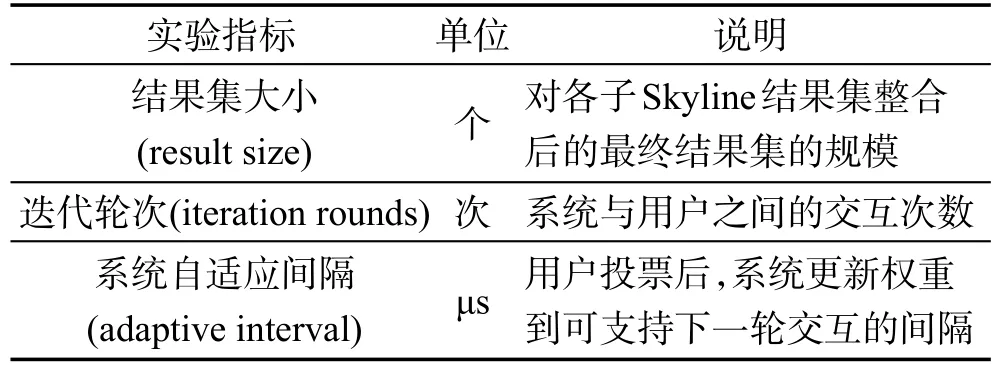
Table 2 Experimental indicators表2 实验指标
实验分别采用模拟数据集和真实数据集进行测试,如表3所示。其中,模拟数据集参照文献[1]中提到的数据生成器产生,默认属性值越小越优。模拟数据集根据数据点维度间关系分为3种[1]:(1)相关数据集,一个数据点在某个维度上相对较优,那么在其他维度上也较优;(2)独立数据集,数据集中所有维度上的数值都是独立分布的,即各维度直接没有相关关系;(3)反相关数据集,数据点在某个维度上较优,则在其他维度上相对较差。实验中,3种数据集的全空间维度均为6维。真实数据集参照文献[5]中的NBA球员技术统计数据集(www.nba.com)。由于实验需要多用户同时参与,在学校范围内选取了30名志愿者,在实验过程中作为用户提出不同的需求。为避免随机性对实验结果产生的影响,所有的结果均为10次实验运行结果的平均值。

Table 3 Experimental datasets表3 实验数据集
实验所用计算机的操作系统为Windows 10,CPU主频为3.3 GHz,内存为4 GB。所有算法均用C++语言实现,编译器为Visual Studio2010。
4.1 数据量对算法性能的影响
为分析数据量对MUSW算法性能的影响,本实验采用相关、独立和反相关3种人造数据集进行测试。数据点个数n从1×104到5×104变化。实验随机挑选10组测试用户组合,设定每组测试中参与的用户数为5,每个用户关注的最大维度为4,所求结果集大小、迭代轮次和系统自适应间隔为10组实验结果的平均值。
图2(a)、(b)、(c)分别展示了不同类型数据集下3种算法的结果集大小对比,从实验结果可以发现:Baseline算法得到的结果集大小随着数据集增大而增加,其中Baseline-union算法的结果集规模较其他两种算法很大,在图2(c)中尤为明显;Baseline-intersection算法在反相关数据集下的结果集规模比在相关数据集下小,这是因为前者各子Skyline结果集的数据点之间的共性小;而MUSW算法的结果集大小在不同的数据集下均稳定于较小的常量,保证了结果的有效性,该常量根据用户的需求由系统提前设定,故不受结果集基数大小以及数据集类型的影响。
考虑到Baseline算法均没有交互过程,因此对其不做交互性能的对比。图3为MUSW算法在相关、独立和反相关3种数据集下的迭代轮次结果。由于正相关数据集下各子空间Skyline结果集包含的数据点较少,且各子结果之间的交集较多,用户更容易达成共识,从而交互迭代的次数较其他两个数据集少。从实验结果看,迭代轮次整体上与数据量成正比,但变化幅度不大,且能有效控制在10次以内,这是因为MUSW算法中的权值变化函数具有收敛性,从而使得交互过程可收敛。
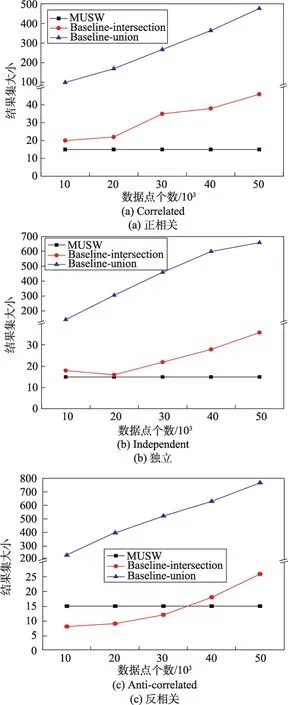
Fig.2 Effect of cardinality on result size图2 数据点基数对结果集大小的影响
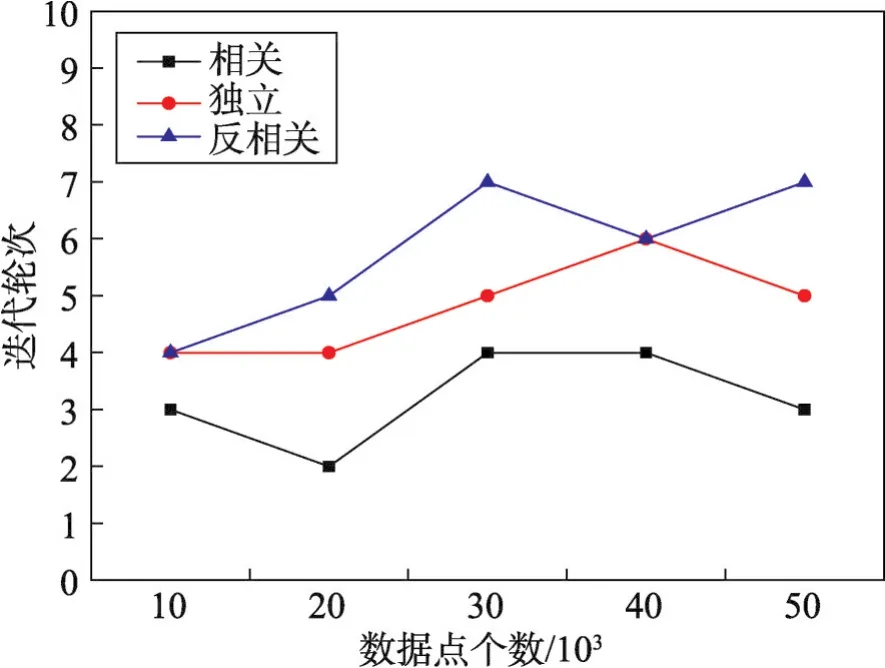
Fig.3 Effect of cardinality on iteration rounds图3 数据点基数对迭代轮次的影响
图4展示了3种数据集下系统自适应间隔的对比,该时间主要包括MUSW算法中的用户投票结果分析和满意度计算的运行时间。由于满意度计算与子Skyline结果的规模相关,从而随着数据集的增加,满意度计算消耗的时间缓慢递增。实验中系统交互间隔均在10 ms以内,算法中索引的建立使其可高效支持查询中用户权重的动态变化。

Fig.4 Effect of cardinality on adaptive interval图4 数据点基数对系统自适应间隔的影响
4.2 用户数量对算法性能的影响
本实验主要考察用户数量对MUSW算法性能的影响。由上节实验可知,正相关数据集下产生的子Skyline结果集的数据点较少,算法性能均较好,因此实验采用独立数据集和反相关数据集进行测试,数据点个数均为1×104。实验随机从30名志愿者中选取不同数量的用户组合,每组用户的数量从2到6变化,每个用户关注的维度最大为4,每组所求结果集大小、迭代轮次和系统自适应间隔为10次实验结果的平均值。
图5(a)、(b)分别为独立数据集和反相关数据集下结果集大小的测试结果,可以看出随着用户数量的增加,即子空间个数增长时,Baseline-union算法得到的结果集大小呈正比增长,而Baseline-intersection算法的结果集大小反而会减少。这是因为用户数量增加,即子空间个数增加,同时满足所有用户需求的交集变小。而MUSW算法优于以上两种算法,不受用户数量的影响,能稳定得到固定大小的候选集,有效地输出结果。
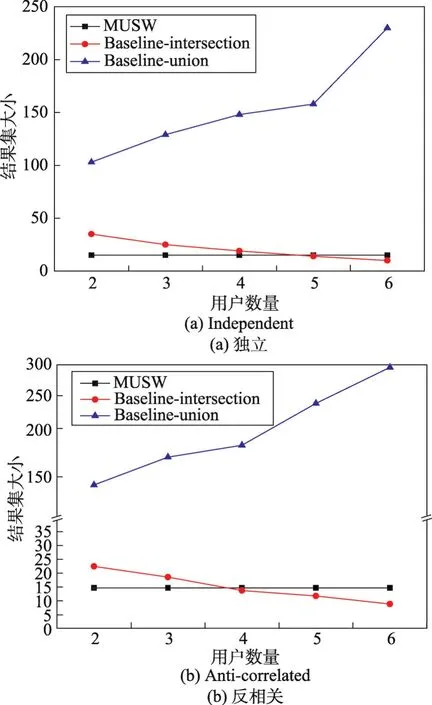
Fig.5 Effect of user number on result size图5 用户数量对结果集大小的影响
MUSW算法在独立和反相关数据集下的迭代轮次结果如图6所示,当参与的用户增多,多用户之间统一结果的难度增加,因此迭代轮次随之增加,但是均在10次以内,在用户可接受范围内。图7为系统自适应间隔的实验结果,当用户数量增加,子空间Skyline结果集个数增加,对目标选项满意度的计算耗时增加,因此系统自适应间隔与用户数量呈正比缓慢增长,且时间在10 ms以内,给用户提供良好的交互体验。
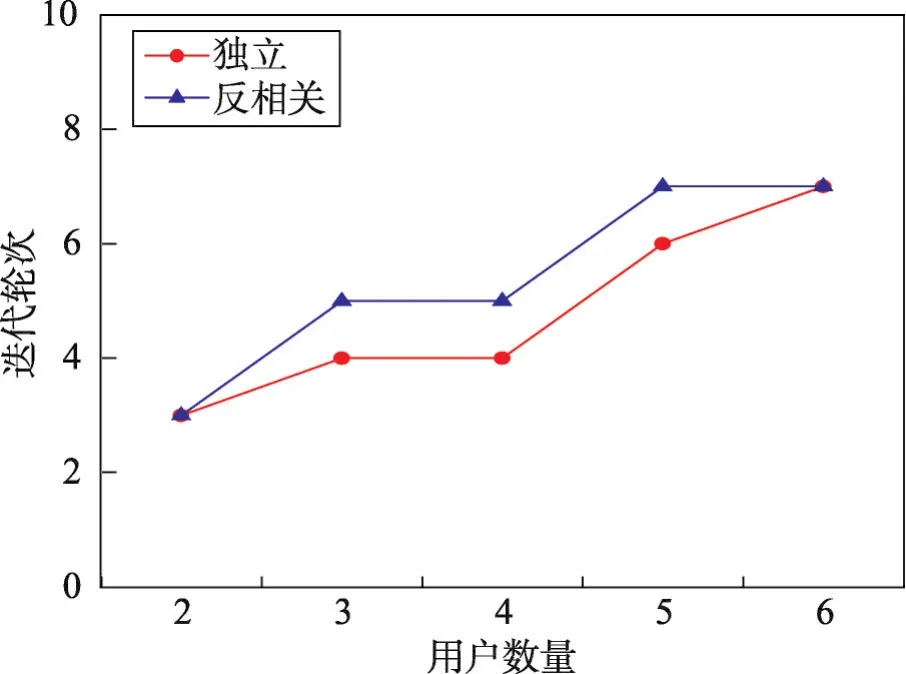
Fig.6 Effect of user number on iteration rounds图6 用户数量对迭代轮次的影响
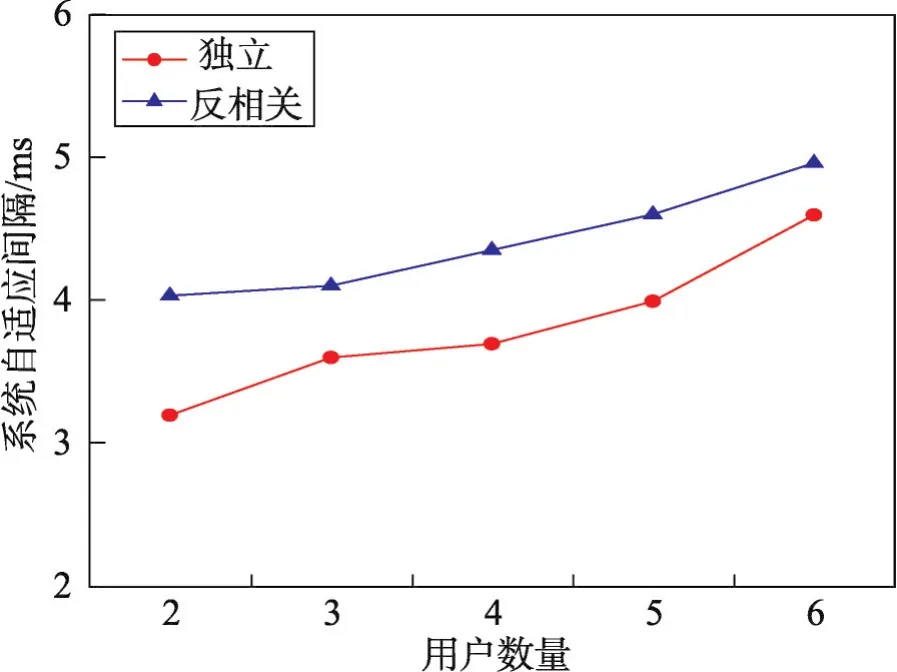
Fig.7 Effect of user number on adaptive interval图7 用户数量对系统自适应间隔的影响
4.3 真实数据集下的算法性能
本实验采用NBA球员技术统计数据集对算法的性能进行验证。该数据集共有17 265条数据,全空间维数为8维。为便于同人造数据下的实验比较,对原始数据进行预处理,将各维度数值映射到区间[1,100]之间,相应转换函数如下:

其中,p(ai)为数据在维度ai上的取值;maxai和minai分别为所有数据点在该维度上的最大值和最小值。
图8展示了真实数据集下用户数量对MUSW算法性能的影响。图8(a)、(b)分别为迭代次数和系统自适应间隔的实验结果,可以发现其结果与人造标准数据下的结果一致,验证了MUSW算法的收敛性,以及可高效地支持用户进行交互式查询。
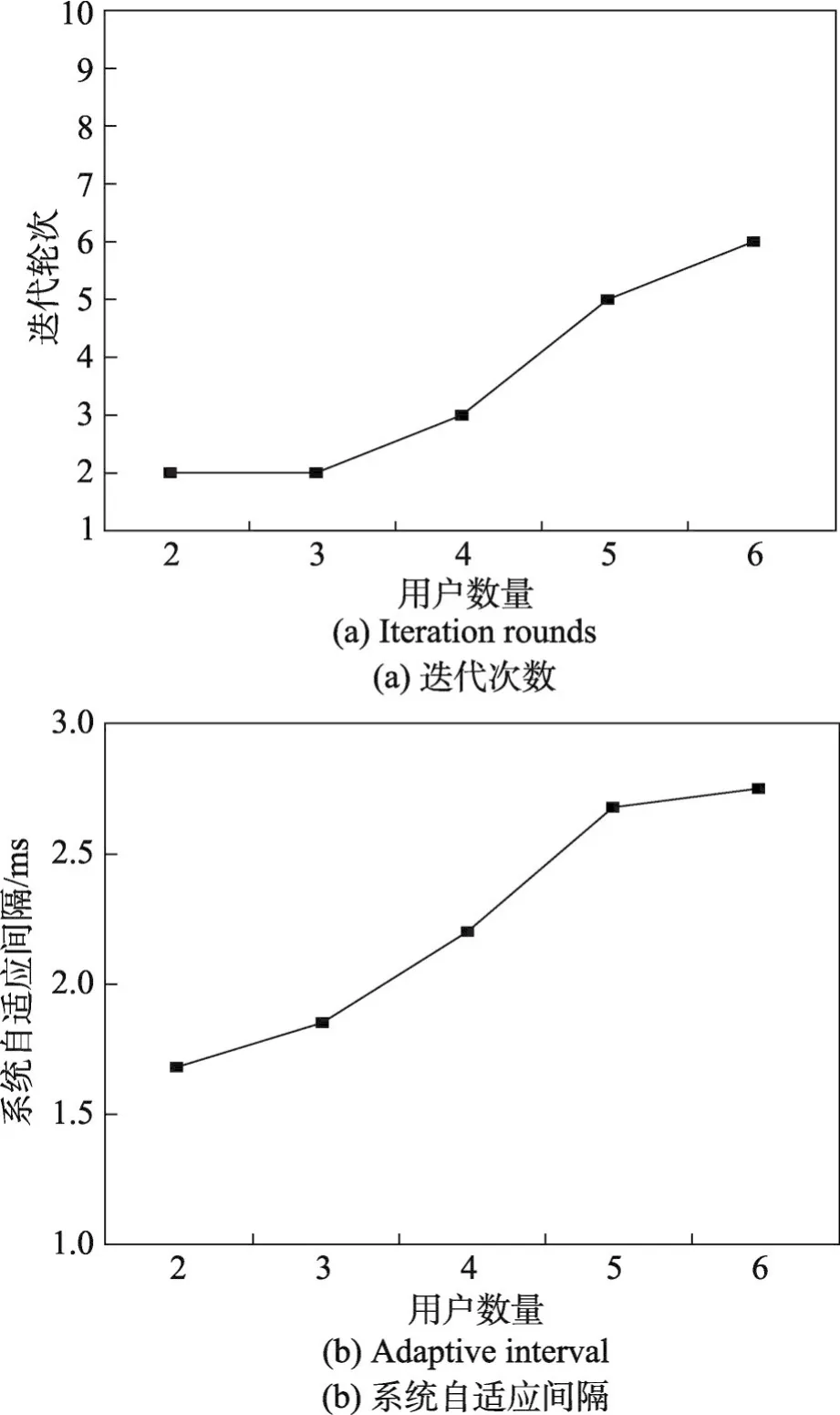
Fig.8 Effect of user number on algorithm performance under real data set图8 真实数据集下用户数量对算法性能的影响
5 结束语
本文针对多用户场景下的Skyline查询问题,进行深入分析和研究,提出了一种基于权重的交互式多用户Skyline查询算法MUSW。算法定义了一种满意度度量方法,由用户权重决定每个数据点的满意度大小。算法实施过程中,通过用户与结果以及用户之间的交互不断动态调整用户权重,当系统根据用户的反馈判断查询终止时,算法将返回满意度最大的K个点,从而使返回结果更符合用户的真实需求。实验证明MUSW算法可有效解决多用户Skyline查询问题,且具有良好的交互性能。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
心理学报(2022年5期)2022-05-16
邮电设计技术(2021年2期)2021-03-13
当代陕西(2020年17期)2020-10-28
计算机与数字工程(2019年11期)2019-11-29
南水北调与水利科技(2018年5期)2018-12-29
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
计算机测量与控制(2018年3期)2018-03-27
软件导刊(2017年12期)2018-01-09
