
基于卷积神经网络的恶意URL检测*
2018-09-03 09:53潘司晨
通信技术 2018年8期
潘司晨,薛 质,施 勇
(上海交通大学 电子信息与电气工程学院,上海 200240)
0 引 言
在互联网时代,企业与用户面临着各种安全威胁,如恶意链接、恶意软件和注入攻击等。
在恶意URL识别方面,最初的检测方式是黑白名单和规则匹配。由于规则是基于当时的安全知识,因此可能无法有效拦截新型的攻击方式。
随着计算机性能的提升和人工智能的发展,安全领域开始使用机器学习的方法来加强检测和防御技术。机器学习可以从URL的域名、长度、参数和敏感字符等方面分析,挖掘数据中蕴含的信息,发现潜在的规律,通过合适的算法构建模型,从而对新型攻击方式实现有效拦截。对于传统机器学习方法,如支持向量机、决策树等,特征提取非常重要,最终模型效果的好坏与选用的特征有很大关系。但是,特征提取和试验需要耗费大量精力和时间[1-2]。
而深度学习可以直接使用原始数据,不需要预先提取特征,因此可以节省不少提取特征的时间。通过多层神经网络,模仿人脑的机制来解释和处理数据。深度学习可以从低层特征不断学习进化为高层特征,从而对结果进行预测。
本文主要研究了卷积神经网络(CNN)在恶意URL检测上的应用和效果。第1章介绍实验的整个实现流程,包括数据及预处理、训练词嵌入模型、神经网络模型构建、优化等。第2章分析CNN模型的最终效果,并与基于逻辑回归算法的模型结果进行对比。第3章分析结果的意义。
1 结构模型与实现
通过搭建和训练卷积神经网络模型,对URL的恶意性进行判别。模型基于TensorFlow[3-4]库实现。完整的处理流程如图1所示。

图1 模型总体流程
整个处理流程可分为数据集预处理、训练词嵌入模型、URL编码映射、模型训练、验证模型和调整模型等步骤。
1. 1 数据集处理
本实验所用的数据集为恶意URL研究时的常用数据集[5],共有约45万条URL,训练集和测试集的数目比约为12∶1。以下是两条数据样例,其中第一条URL被标注为"bad",第二条URL被标注为"good":
http∶//goodlandurbanfarms.com/wolomasx/wtyhyyq/hykoopp/qrrttrr/
http∶//www.metrolyrics.com/arashi-lyrics.html
读取数据后,在将数据传入CNN模型前,需要对其进行一系列转换。对于标签y,本人采用one-hot编码的方式,用大小为1×2的数组表示各个标签。原先的正样本"good"被转换成[0,1],负样本"bad"被转换成[1,0]。
对于URL集合,为使URL能被之后的神经网络模型所理解,需要将每条原始的URL字符串映射成二维实数矩阵。通过字符级别的词嵌入编码方法[6-7],将URL中的每个字符映射成尺寸大小为1×embedding_len的实数数组。经过多次试验,选取参数embedding_len=64。数据集中,共有大小写英文字母、数字、'.'、'/'、'?'、'_'等特殊符号共94个字符。此外,由于各条URL的长度不同,需要将所有URL的长度统一变为sequence_length以便处理。观察数据集后发现,99%的URL长度不超过200,因此选取sequence_length=200。对于长度超过200的URL,只截取其前200个字符;而对于长度小于200的URL,则在原始URL的末尾填充若干个空格(' '),使其长度达到200。通过上述方法,每条原始URL字符串被映射成了200×64的二维矩阵,作为神经网络模型输入层的输入。
1.2 字符表 征
为了将每条原始的URL字符串映射成二维矩阵,本人使用了字符级别的词嵌入编码方法。之所以不采用one-hot编码,是因为其存在一些缺陷。
如果使用one-hot编码,则每条URL将被映射成200×94的二维矩阵,且CNN神经网络输入层的神经元个数需要调整为94个。因此,与词嵌入编码相比,one-hot编码需要耗费更多的空间和计算资源。此外,one-hot编码会把每个词孤立起来,使得算法对相关词的泛化能力不强。本文在CNN模型不变的情况下,对URL分别进行了字符级别的词嵌入编码和one-hot编码,并在第2章比较了两者的结果。
1.3 神经网络模型
CNN网络的结构如图2所示,模型中各部分的功能描述、形状大小等如表1所示。

图2 CNN网络 结构

表1 模型各部分 概况
该模型借鉴了CNN经典网络模型GoogLeNet中Inception模块的思想[8]。当为卷积神经网络设计某一层时,需要考虑层的类别(如卷积层或池化层)、卷积核或池化核的尺寸大小和步长等。以卷积核尺寸为例,往往需要尝试多个不同的尺寸大小,比较模型训练的结果,才能确定合适的尺寸大小。而在Inception模块中,设计者可以同时使用多个不同尺寸大小的卷积核,并把它们的输出结果相连接。即Inception模块的特点是,当设计者不确定该使用何种尺寸的卷积核时,可以选择使用多个卷积核,使神经网络模型自身去学习相关参数获得想要用到的卷积核大小。这虽然会使网络架构更加复杂,但可以改善最终的效果。
本实验中,CNN模型的起始输入是经过字符级别的词嵌入编码后的二维矩阵,尺寸为200×64。Inception层由3个卷积层和3个最大池化层并联而成,各自的尺寸大小和步长如表1所示,padding类型均为"valid"。以Conv1和Maxpool1为例。Conv1由128个尺寸为3×64×1的卷积核组成,经过激活函数ReLU和最大池化后,数据维度变为1×1×128。将3个池化层的输出数据连接在一起后,Inception层的输出维度为1×1×384。之后是三层神经元个数分别为128、64和2的全连接层。假设第三层全连接层的输出是[a,b],通过softmax函数后,输出变为,记为[y1, y2],显然y1+y2=1。设置阈值thre,当y1>thre时,则判定原始URL为恶意URL,否则则视为正常URL。本实验取thre=0.5。
为防止过拟合,模型中对每层的输出采用dropout随机失活[9]。另外,为了加快模型的训练速度,在Inception层之后对数据实施了批量归一化(Batch Normalization)[10]。批量归一化的步骤如下:设Inception层的输出为z→,通过式(1)、式(2)和式(3)计算出各z(i)的均值、方差和归一化后的结果:
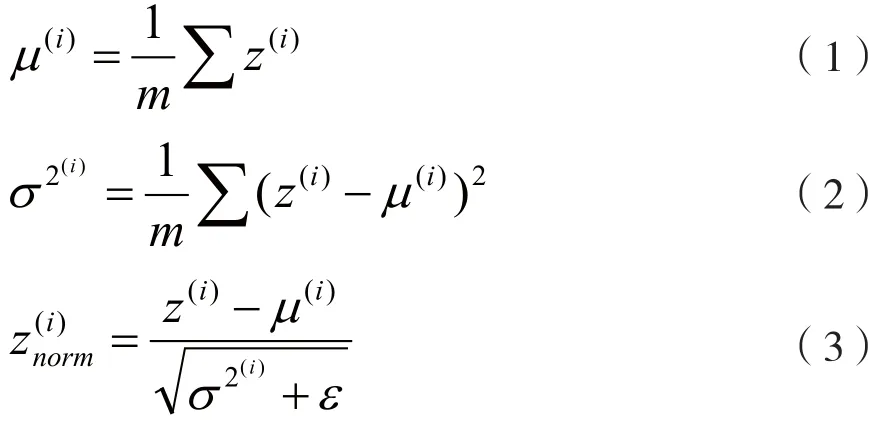
式中,m代表样本的个数。本实验在调整模型更新权重和偏差参数时,采用小批量的Adam优化算法[11],每次迭代使用的batch大小为64。为了防止式(3)的分母为0,可令ε=0.001,有:

损失函数为:

本实验数据集的样本数目约为45万条。在更新权重和偏差参数时,如果每次都使用所有训练集样本来计算损失函数,则计算量和训练时间非常大。因此,本文采用小批量优化算法。每次更新参数时,仅基于当前被选择的m个样本,可以大大加快每次训练的速度,也可以节省内存空间。常用的优化算法有Momentum算法、Adagrad算法和RMSprop算法等,这里采用Adam算法作为本实验的优化算法。Adam算法(Adaptive Moment Estimation)[11]适用于许多深度学习网络结构,本质上是将动量算法和RMSprop算法相结合,能计算每个参数的自适应学习率。
2 结果分析
2.1 CNN模型测试结果
本实验将数据集分 为训练集、交叉验证集和测试集三个部分。使用章节1所述的模型和参数,训练23 000次后,在测试集上测试,测试集共有33 339个样本,包含25 378个正样本和7 961个负样本。测试结果和相关名词的含义如表2所示。与诸如个性化商品推荐等机器学习应用不同,应用于安全领域的模型如果分类错误,可能会造成很大影响,特别是当恶意样本被误判为正样本时。因此,测试结果计算的是负样本的查准率、查全率和Fβ值,且设置Fβ中的β=1.5,表示查全率比查准率有更大的影响[12]。

表2 CNN测试结果
2.2 其他模型的测试结果
在对字符串进行编码映射时,除了使用字符级别的词嵌入编码外,还对字符进行了one-hot编码,并比较了两者间最终结果的差异。此外,将结果与使用逻辑回归算法进行恶意URL检测[5]的结果进行了对比。需要说明的是,这三个模型使用相同的训练集、交叉验证集和测试集。
2.2.1 逻辑回归法
通过逻辑回归算法对恶意URL进行判别。特征提取采用词频与逆向文件频率模型(TF-IDF)[13]实现。
TF-IDF常用于文本处理领域。假设数据集由m个文本Ai组成,每个文本由ni个单词组成。假设单词c在文本Ai出现的次数为nic,数据集中共有mc个文本包含单词c,则单词c的。它在文本Ai中的词频。因此,它在文本Ai中的TF-IDF可由式(6)得到:

由式(6)可知,TF-IDF表示各个字词对于数据集的重要程度。如果单词c在某个文本中的词频较高,且在其他文本中的出现次数较少,则可以认为它具备一定的类别区分能力,适合用来分类。
以'-''.'等字符作为分隔符,对各URL进行切分,调用python库sklearn中的相关函数,生成TF-IDF矩阵后,通过逻辑回归算法进行训练,流程图如图3所示。

图3 逻辑回归法流程
最 终在测试集上的结果,如表3所示。

表3 逻辑回归算法测试结 果
2.2.2 one-hot编码
在第1.2节曾提到,one-hot编码会降低算法的泛化能力。为了验证这一点,在CNN模型和参数不变的情况下,对URL进行one-hot编码。数据集中共有大小写英文字母、数字、'.''/''?''_'等特殊符号共94个字符,因此把每个字符映射成大小为1×94的数组。对于各字符,把数组相应位置的值设为1,其余均设为0。最终在测试集上的结果如表4所示。

表4 one-hot编码测试结果
2.3 结果比较
比较上述三个模型的结果可知,词嵌入编码CNN模型和one-hot编码CNN模型的查全率和F值均比通过逻辑回归算法的结果好,且省去了特征提取的步骤。因此,深度学习在安全领域的某些方面具有应用价值。此外,词嵌入编码的最终效果优于one-hot编码的效果,证明了one-hot编码存在泛化能力不强的缺陷。
3 结 语
本文研究了卷积神经网络在恶意URL检测上的应用和效果,设计和训练了一个CNN模型对恶意URL进行检测,并与传统逻辑回归算法的结果进行了对比。在正确率、查全率、F值等指标上,CNN模型的效果均好于后者,且省去了特征提取的步骤。因此,深度学习在安全领域的某些方面具有应用价值。随着计算机处理速度的提高和硬件条件的改善,训练更加复杂的神经网络模型也将成为可能。
猜你喜欢
小学生学习指导(中年级)(2021年12期)2021-12-30
北京航空航天大学学报(2021年9期)2021-11-02
汉字汉语研究(2020年2期)2020-08-13
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
电子制作(2019年13期)2020-01-14
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
电子制作(2019年11期)2019-07-04
