
基于公共块“补偿-对称”模型的微博文本相似度计算*
2018-09-03 09:53王维建
通信技术 2018年8期
王维建
(上海新华控制技术(集团)有限公司,上海 200240)
0 引 言
随着互联网的快速发展,我国的网民数量快速增加。据CNNIC发布的《第39次中国互联网络发展状况统计报告》显示[1],截至2016年12月,我国网民规模达7.31亿,互联网的普及率达到53.2%。微博作为分享简短实时信息的广播式的社交网络平台,吸引了庞大的用户群。《报告》显示,截止至2017年3月31日,微博月活跃用户已达3.4亿。作为新兴的媒介,微博依靠其庞大的用户群数量和迅速的消息传播能力,使得一些微博热点事件能在极短时间内广泛传播并形成网络舆情。有些网络水军也利用这个特点来控制舆论、传播谣言等,使得微博给不法分子留下了可趁之机。计算微博文本相似度,有助于比较微博之间的关系,对于识别网络水军、寻找舆论操控者以及打击传播违法虚假信息的行为都有重大意义。同样,计算微博文本相似度的工作为微博传播路径构建、微博热点话题检测和微博舆情检测等奠定基础。
微博,即微型博客,源自英文单词microblog。作为Web 2.0的产物,微博属于博客的一种形式,但单篇的文本内容通常限制在140个字以内。这一特点使得微博的信息碎片化,文本本身普遍短小、简洁,与传统意义上的文章有较大的差别,使得传统的用于长文本相似度计算的方法不太适用于微博研究。同时,微博中经常包括各种以“@”开头的用户ID名称和各类表情的使用等,大大增大了微博文本处理的难度。因此,如何利用微博短文本的特点设计高效的微博文本相似度计算算法成为一个难点。
1 研究现状
本文提出一种基于公共块的“对称-补偿”微博文本相似度计算模型,根据微博文本各个词之间的相似度、公共块中词项的数量、词语在微博中出现的顺序及微博标签等属性来计算微博间的相似度,并设置一个合理的阈值,当相似度大于该阈值时认为两条微博是“相似的”。
国内外研究者已经开展了大量的文本相似度计算工作,提出过多种类型的算法。张焕炯、王国胜等[2]提出基于汉明距离的文本相似度计算,王振振、何明等[3]提出基于LDA主题模型的文本相似度计算方法,郭庆琳、李艳梅等人[4]提出利用TF-IDF算法提取特征词并用向量空间余弦值来衡量文本相似度的算法。但是,这些算法不是专门针对微博短文本,在用于短小简洁的微博文本相似度计算时效果难免会下降。对于短文本相似度计算,重庆理工大学黄贤英等人[5]提出基于公共词块的英文短文本相似度计算,将传统文本相似度计算与短文本的特点结合起来。
2 基于公共块的“补偿-对称”微博文本相似度计算模型
微博本身具有简洁性和随意性,使得微博文本并不像传统文本一样具有较为固定的结构与语法,甚至还可能夹杂一些表情、用户ID或者网络流行用语。微博文本中还可能含有标签话题,即以“#”开头和结尾的、高度概括表达该条微博文本内容主题的文字,一般不超过10个字。基于公共块的“补偿-对称”博文本相似度计算模型将紧密结合并利用微博的特点进行相似度计算,计算框图如图1所示。
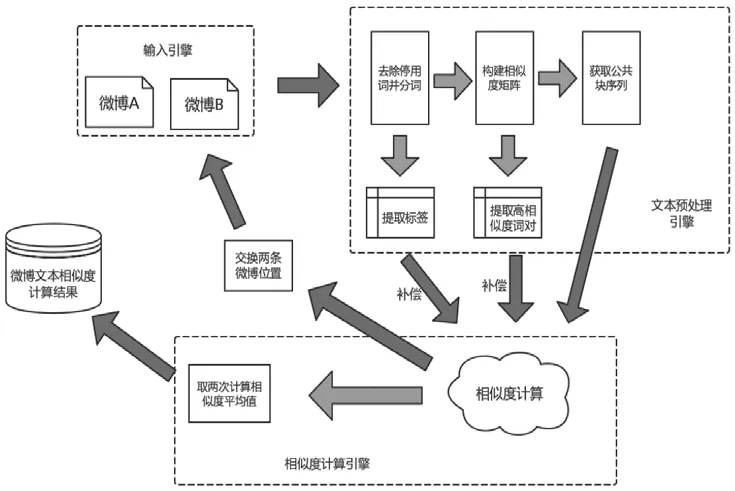
图1 计算流程
2.1 微博文本预处理
微博文本的随意性,使得它并不像普通传统性文本有清晰的结构、明晰的格式以及合乎逻辑的语法。微博中常常有一些对计算微博文本相似度的干扰项,如表示各种表情的编码、以“@”开头来引用某一用户ID或者含有系统自带的“转发微博”“秒拍视频”等词项。正文部分各类标点符号如“,”“?”等,或者是一些常用的停用词如“哦”“啊”“的”词,也不利于正确计算微博之间的相似度。所以,对微博文本先进行预处理显得十分必要。
预处理流程如下:
步骤 1:去除微博文本中形如“http∶//”“https∶//”的网址。
步骤2:去除以“#”开头的微博标签,并提取储存用于之后的处理。
步骤3:去除以“@”开头的微博用户ID。
步骤4:去除停用词,停用词集合A={哦,啊,吗,阿,哎,哎呀,哎哟,唉,吧,……}共598个词元素(限于篇幅仅列出部分词元素)。
步骤5:去除标点符号,标点符号集合B={“,”“。”“!”“?”“:”“、”……}共58个(限于篇幅仅列出部分标点符号)。
整个计算模型的最小子结构是依赖于词语与词语之间的相似度。所以,经过预处理后的微博文本,还需要对其进行分词处理,从而进行后续计算相似度的工作。
2.2 词语相似度计算
本文提出利用Google开发的一款开源词向量计算工具word2vec计算并构建两条微博文本的词语相似度矩阵[6],核心是神经网络机器学习算法。采用CBOW(Continuous Bag-of-Words)和Skip-Gram两种模型,将词语映像到同一坐标系,得出数值向量。CBOW的目标是根据上下文预测当前词语的概率,且上下文所有的词对当前词出现概率的影响权重一样,因此叫Continuous Bag-of-Words模型。例如,在袋子中取词,取出数量足够的词即可,至于取出的先后顺序无关紧要。Skip-gram刚好相反,它是根据当前词语来预测上下文的概率。word2vec可以在百万数量级的词典和上亿的数据集上进行高效训练,且该工具得到的训练结果——词向量可以很好地度量词与词之间的相似性。
通过爬取大量微博文本,将其进行分词后作为word2vec神经网络的训练集。word2vec神经网络训练过程,每个词的向量维度被设置为400。词向量训练时上下文扫描窗口的大小被设定为5,而最低频率设定为5,即如果一个词语在所有文档中出现的次数小于5则被丢弃。在大量数据训练后,可以获得一个相比其他模型更加适用于微博这个特定类型文本的计算词语相似度的模型,对一些网络用语、流行话语、特定的人名或者英文单词等都更加有针对性。对两条微博,从两个词对集合中分别选择一个词组成一组词对,计算词对的相似性。利用word2vec计算每组词对的词语相似度可以构建一个矩阵,矩阵元素是对应两个词的相似度。
2.3 基于公共块的“补偿-对称”模型
本文提出基于公共块“对称-补偿”模型算法进行微博文本相似度的计算,具体步骤如下:
步骤1:在得到微博文本词语相似度矩阵后,遍历该矩阵每一行,找到该行中相似度最大值(≥0.3),并把该值对应的词对写入词对集合。
步骤2:将第一条微博记为微博A,第二条微博记为微博B。
步骤3:将词对集合中的每对单词属于微博A的词项写入词集1,属于微博B的词项写入词集2。
步骤4:将步骤2中的两个词集根据在对应的微博文本中出现的顺序进行排序,得到排序后的词集1记做D_WordList1,排序后的词集2记做D_WordList2。
步骤5:从D_WordList1中选择前两个词语,如果它们在词对集合中对应的词语在D_WordList2中不是连续递增,则将这两个词从D_WordList1中删除,并且作为两个公共块写入公共块集合,重复该操作;如果它们对应的词语在D_WordList2中是连续的,则继续遍历到D_WordList1下一个元素进行顺序判断,直到D_WordList1变为空集。
步骤6:计算公共块在微博A、微博B中的顺序向量。为方便计算,直接定义公共块集合顺序向量在微博A中的顺序向量为r1=(1,2,…,i),而相应地通过在公共块序列中的词对可以找到每个公共块在微博B中出现的顺序,确定微博B的顺序向量。
步骤7:采用公共块序列计算文本相似度基于以下三条规则。(1)文本的公共块数量越多,文本之间的相似度越高;(2)文本公共块所包含的词项个数越多,文本间的相似度越高;(3)两篇文本中公共块的先后顺序越符合,文本间的相似度越高。
具体的计算公式如式(1)~式(3)所示:
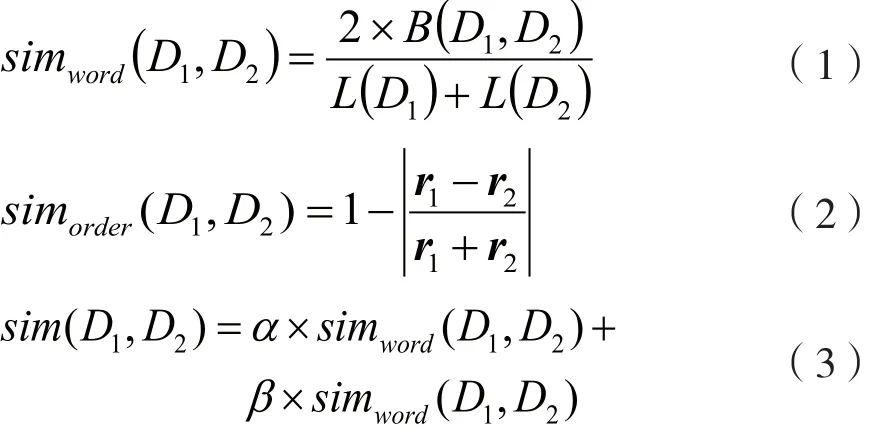
其中simword由公共块包含词项数量决定,simorder由公共块在两篇文本中的出现顺序决定,B(D1,D2)指所有公共块包含的词项总数,L(D1)和L(D2)指两篇微博文本中分别包含的词项个数,r1和r2分别指公共块在微博D1和微博D2中的顺序向量,根据公共块在两条微博中出现的顺序,可以计算出两条微博对应的顺序向量。α和β为实际实验中人为调整的两个系数参数,本文设α=0.7,β=0.3。
步骤8:补偿。在构建词语间的相似度矩阵中可以明显发现,有些词语的相似度非常高,这是微博文本相似度高的指示标志。同样,利用微博文本特有的以“#”开头和结尾的话题功能,当两条微博相同话题数量越大,可以认为两条微博“相似”的可能性越大。因此,计算过程中记录相似度大于0.8的词对数目并记为Count1,可以得到补偿性指标。

同时,记录两条微博的相同话题标签数量,并记为Count2,以得到补偿性指标:
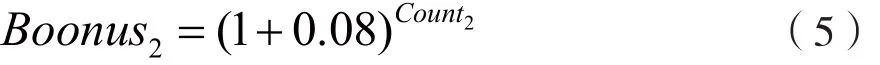
通过补偿,将上述计算的sim(D1,D2)进行修正,得到新的sim(D1,D2):
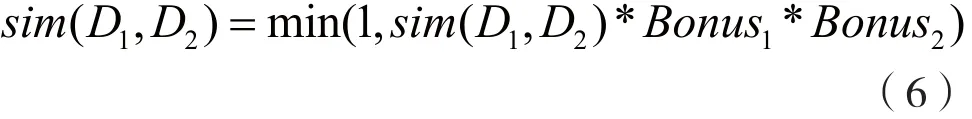
步骤9:对称。从上述步骤中可以看出,在顺序向量的选取中,为了方便计算,将微博A的顺序向量直接定义为r1=(1,2,…,i),再以该向量为参照结合公共块序列和词项的排序结果得出微博B的顺序向量。显然,这样的计算不具有对称性,即把第一条微博作为微博A而把第二条微博作为微博B计算得出的结果,不同于把第二条微博作为微博A而把第一条微博作为微博B计算得出的结果。因此,对称算法将第一条微博作为微博B,第一条微博作为微博A,并重复上述的步骤3到步骤7,分别记两次计算得出的相似度结果为sim1(D1,D2)和sim2(D1,D2),则最终两条微博之间的相似度为:
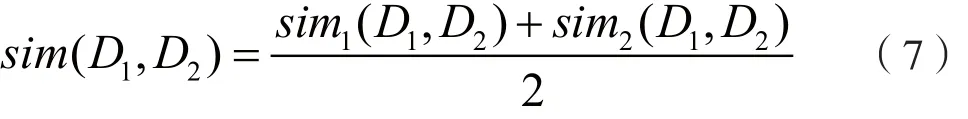
3 实验结果
3.1 实验举例分析
以从新浪微博上随机选取的两条微博为例子来分析算法流程。两条微博内容如下:
①震惊!詹老汉生涯首次被驱逐出场!!还是在球队大比分领先的情况下!#詹姆斯被驱逐#转发微博【可爱】【可爱】【可爱】
②#詹姆斯被驱逐#职业生涯首次,詹姆斯对裁判判罚不满,连吃到两个T直接被驱逐出场!@NBA篮球协会【花心】
经过去除标点符号、停用词以及表情之类的工作之后进行分词,得到对应的两条文本为:
①震惊 詹 老汉 生涯 首次 驱逐 出场 还是在 球队 大比分 领先 的 情况 下
② 职业生涯 首次 詹姆斯 对 裁判 判罚 不满连 吃 到 两个 t 直接 被 驱逐 出场
可以看出,经过文本预处理后,微博中对相似度计算无关紧要的东西已经被去除,且以词语的形式来表达这条微博的内容,以进行关于相似度计算的工作,然后通过word2vec计算构建相似度矩阵。限于篇幅,这里给出矩阵的部分结果如表1所示。

表1 微博词语相似度计算矩阵部分结果
在得到的完整相似度矩阵中,若以第一条微博为微博A,第二条微博为微博B,则可以得到词对集合为{<驱逐,首次>,<大比分,出场>,<首次,判罚>,<老汉,驱逐>,<领先,詹姆斯>,<生涯,驱逐>,<情况,驱逐>,<球队,驱逐>,<出场,首次>,<詹,裁判>,<震惊,裁判>},由词对集合生成词集并排序可以得到D_WordList1{震惊,詹,老汉,生涯,首次,驱逐,出场,球队,大比分,领先,情况}和D_WordList2{首次,首次,詹姆斯,裁判,裁判,判罚,驱逐,驱逐,驱逐,驱逐,出场},然后遍历D_WordList1,寻找其在WordList2中对应的词语,得到公共块序列{[(震惊,裁判),(詹,裁判),(老汉,驱逐),(生涯,驱逐)],[(首次,判罚)],[(驱逐,首次),(出场,首次),(球队,驱逐)],[(大比分,出场)],[(领先,詹姆斯),(情况,驱逐)]}。
由以上分析知,两微博公共块数量为5。所以,微博A的顺序向量为r1=(1,2,3,4,5)。对于第一个公共块的第一个元素(震惊,裁判),可以从D_WordList2中知道“裁判”出现在第4个位置,故顺序向量r2第一个元素为4,经过类似计算可以得出微博B的顺序向量为r2=(4,6,1,11,3)。
在两条微博构建的相似度矩阵中,矩阵元素大于0.8的词对数目共有6对,而相同的话题标签有一个,所以可以计算得到Bonus1=1.18,Bonus2=(1+0.08),则:

同样地,交换两条微博位置,即以第二条微博为微博A,第一条微博为微博B,经过相同步骤后可以计算得到sim2(D1,D2)=0.669,因此得到该两条微博的相似度最终结果为:

3.2 实验数据
采用真实的新浪微博数据进行测试,且微博的话题标定利用新浪微博中的“热门话题”功能,其在每一个热门话题中的微博都围绕同一个主题,且内容也较为相似。而不同的热门话题中的微博由于主题不同内容不同,所以相似度较低。因此,论文将属于同一热门话题下的微博标定为“相似的”,而属于不同热门话题的微博标定为“不相似的”,作为算法的测试集。
3.3 实验评价指标
实验分别选用80组人工标定为“相似的”的微博与80组人工标定为“不相似的”的微博来测试算法有效性。将数据测试结果分为如表2所示的4种情况。

表2 分类实验评价表
由表2可以计算出准确率和召回率:

准确率越高,说明被预测为“相似的”的微博中确实为“相似的”的微博所占比例越高;召回率越高,说明实际为“相似的”的微博被正确预测为“相似的”的比例越高。因此,可以用准确率和召回率来评价算法模型的有效性。
3.4 实验结果与比较分析
由于LDA模型、TF-IDF算法等并不太适用微博这种简短而又随意的文本相似度计算,因此将采用黄贤英等人提出的传统的基于公共块的短文本相似度计算方法和本文提出的“补偿-对称”模型算法分别进行实验,并比较两者的实验结果。
经过计算,两种方法得到的计算结果在各个相似度区间的数据组数,如表3所示。

表3 两种方法的计算结果
对于传统的公共块算法,结果如图2所示。
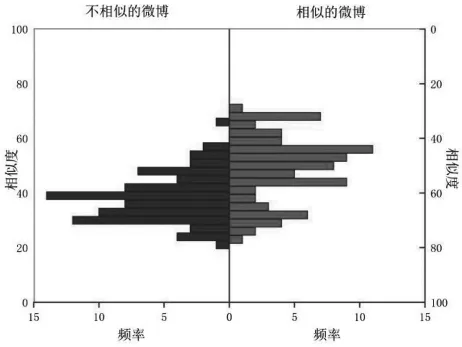
图2 基于传统公共块算法的微博相似度频率
图2 左边是被标定为“不相似的”的微博的各个相似度的频率,图2右边是被标定为“相似的”的微博的各个相似度的频率。同样,对于“补偿-对称”模型,其实验结果如图3所示。

图3 基于“补偿-对称”模型的微博相似度频率
可以明显看出,传统的公共块模型算法中,在相似度为0.3~0.5中,“相似的”微博与“不相似的”微博有较多重叠,使得算法在该区间内的区分性不高。而“补偿-对称”算法尽管在该区间内同样有重叠,但可以看到其重叠数量相对较少,区分性有提升。
图4、图5给出不同的判断阈值应用两种模型的准确率和召回率。

图4 两种方法在不同阈值下的准确率曲线

图5 两种方法在不同阈值下的召回率曲线
可以看出,在准确率方面,随着阈值的增加,两种方法的准确率都在不断提高。在阈值小于0.4的情况下,传统公共块模型算法计算得到的准确率略微高于“补偿-对称”模型;而在阈值大于0.4时,“补偿-对称”模型准确率则明显更高。在召回率方面,随着阈值的增加,两种方法的召回率都在不断下降。但是,在各个阈值情况下,“补偿-对称”模型的召回率都要明显高于传统公共块模型至少10%。可见,无论在准确率还是召回率方面,本文提出的算法模型识别效果都要好于传统的公共块模型。
将上述准确率和召回率的曲线绘制在同一张图中,如图6所示。对于“补偿-对称”模型,当把阈值设置在较低的位置如0.34时,虽然可以获得高达95%的召回率,但是实验的准确率却不到65%;当把阈值设置在较高的位置如0.48时,可以发现其准确率达到了95%的水平,但是召回率显著下降,仅有60%左右。因此,为了达到较好的效果,即准确率和召回率都保持在较高的水平,选择两条召回率曲线与准确率曲线的交点对应的横坐标0.42作为阈值。在该阈值下,召回率与准确率都达到了80%以上,整体效果良好。这为应用“补偿-对称”模型提供了参考:设置阈值在0.42左右,可以使召回率和准确率都保持在较高水平。

图6 两种方法的准确率与召回率曲线
同理,取传统公共块模型算法的召回率和准确率曲线的交点横坐标作为其阈值。显然,在专门针对短文本的两种算法中,传统公共块模型与“补偿-对称”模型在选择上述阈值的情况下都可以达到比较良好的效果。但是,本文提出的“补偿-对称”模型的召回率与准确率比传统模型高了8%,说明该模型相比传统公共块模型有更好的分类效果。
从以上实验结果可以看出,“补偿-对称”模型进一步将相似度极高的词项和微博标签话题考虑在内,对相似度进行补偿,并且弥补了公共块算法本身存在的不对称性而可能造成的相似度计算偏差较大的缺点,使得实验得到的结果要优于传统的公共块模型算法。
4 结 语
提出的基于公共块“补偿-对称”模型的文本相似度计算方法不仅考虑了文本的公共块数量、文本公共块所包含的词项个数以及两篇文本中公共块的先后顺序,还考虑相似度极高的词项和微博标签话题,对相似度进行补偿,进一步弥补了公共块算法本身存在的不对称性,提高了相似度计算的精度,可为微博溯源、舆情检测、网络水军识别、打击违法犯罪等提供技术支持。阈值选择对于准确率与召回率的影响较大,下一步工作将探讨如何根据实际需要设定阈值,从而使算法能够更好地达到预期效果。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
作文大王·低年级(2022年3期)2022-03-19
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
临床骨科杂志(2020年1期)2020-12-12
制造技术与机床(2019年9期)2019-09-10
小学生作文·小学低年级适用(2018年12期)2018-04-11
高中生学习·高三版(2016年9期)2016-05-14
校园英语·下旬(2016年2期)2016-03-18
新高考·高二数学(2015年11期)2015-12-23
探测与控制学报(2015年4期)2015-12-15
