
Spark GraphX上的SPARQL查询处理算法*
2018-09-12 02:21邹兆年
计算机与生活 2018年9期
邱 慧,邹兆年
哈尔滨工业大学 计算机科学与技术学院,哈尔滨 150001
1 引言
资源描述框架(resource description framework,RDF)[1]是W3C提出的一种知识表示模型,用于描述和表达网络资源的内容和对应的结构,是一种用来描述元数据的数据。图1(a)是一个简单的包含16个元组的RDF三元组,三元组包括主体、谓词和客体。从图的视角来看,RDF也是一个天然的图模型。其中,三元组的主体和客体被当作图的顶点,而谓词被当作边。图1(b)是图1(a)三元组对应的RDF图模型表示。对于RDF数据,W3C提出了一种形式化的查询语言SPARQL(simple protocol and RDF query language)[2]作为检索和查询的标准语言。SPARQL查询也可以被看作是一个查询图。因此利用SPARQL在大规模的RDF数据中检索信息可以看作是大型图的子图匹配问题。例如,图2(a)是一个简单的SPARQL查询语言,图2(b)是其所对应的查询图。查询对应的意思是找出所有类型为出版物并且作者是助理教授2的图书。近年来,随着人们对语义网和知识库日益增长的兴趣和关注,RDF数据集的规模在不断增大,现有的RDF数据集的规模已经超出了单机处理能力的限制。因此,利用分布式系统来储存查询RDF数据成为了一个热门的研究课题。
现阶段,由于分布式平台例如Hadoop、Spark等强大的存储和并行计算能力,学术界提出了大量基于分布式计算平台的RDF检索方案,例如文献[3-8]等。Hadoop是Apache基金会开发的开源分布式存储计算框架,其核心是HDFS和MapReduce。HDFS为海量数据提供了存储功能,而MapReduce则提供了强大的分布式计算能力。除了其强大的存储性能和并行计算能力,Hadoop另一个显著的特点是其具有良好的可扩展性,可以扩展至几千甚至上万个节点。因此,对于数据量持续增长的问题具有很强的适用性。Hadoop的出现为海量数据的存储和查询提供了一种可行的方案。但是,基于Hadoop的检索方案有一个共同的缺点:由于内存空间的限制,数据计算过程中产生的大量中间结果会被写回到磁盘,从而会产生大量的I/O操作,严重影响查询性能。
Apache Spark[9]是一个针对大规模数据处理而设计的通用内存计算框架,在它的基础上有一系列的扩展,例如 SparkSQL、Spark Streaming、MLlib和GraphX[10]。Spark使用一个新的数据结构——弹性分布式数据集(resilient distributed datasets,RDD)来将计算结果存储在内存中,从而减少I/O次数,有效克服了基于Hadoop的SPARQL查询方式的缺点。GraphX是一个基于Spark的分布式并行图计算引擎,由于利用SPARQL检索RDF数据可以被看作一个大图上的子图匹配问题,因此GraphX可以很方便地被用来处理大型RDF数据集上的SPARQL查询。

Fig.1 RDF triples and graph model图1 RDF三元组及图模型
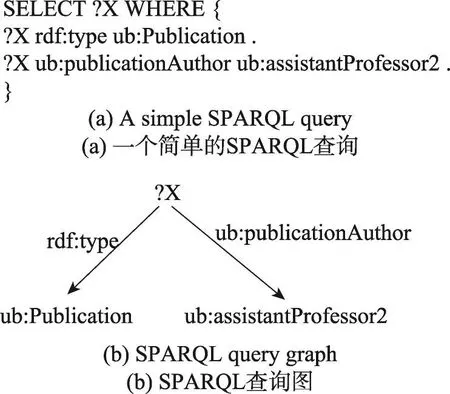
Fig.2 SPARQL query and SPARQL graph图2 SPARQL查询及其查询图
本文研究的主要内容是在Spark GraphX(为了方便,后文简称为GraphX)上处理SPARQL查询。据所知,目前只有两种基于GraphX的SPARQL查询处理方案,S2X[3]和Spar(k)ql[4]。S2X的主要缺点是在第一轮迭代中执行查询中所有的三元组模式,从而产生大量不必要的中间结果,大量消息需要在不同节点之间传输,严重影响查询效率。而Spar(k)ql的主要缺点是每次只能处理SPARQL查询中的一个三元组模式,从而没有完全发挥GraphX分布式图计算的威力。
本文提出了一种新的基于GraphX的SPARQL查询处理方案SQX。本文的主要工作如下:
(1)以属性图模式存储RDF数据,原始RDF图中的部分边被转化为数据属性存储在顶点内部,从而有效减少了RDF属性图中顶点和边的数量。同时对于部分三元组模式的匹配可以在节点内部完成,有效降低了数据的传输代价。
(2)SQX对于给定的SPARQL查询生成相应的查询计划,查询计划包括查询树、非树边和约束条件。查询计划首先对查询树进行匹配,然后利用非树边和约束条件进行筛选得到最终的结果。
(3)在查询树的匹配阶段,SQX采用自底向上分层匹配的策略。相邻顶点层之间的查询边将在一个超级步中被匹配,充分利用了GraphX的并行计算能力。
(4)做了大量的实验来验证SQX的查询性能。实验表明,SQX可以有效处理各种形状的SPARQL查询,并且具有良好的可扩展性。
2 相关工作
近年来,学术界在分布式平台上针对RDF存储查询方面做了大量的研究工作。其中一种方式是将集中式的RDF查询系统部署到分布式集群的所有节点上,在它们之间建立一个消息传递层,例如文献[5,11-13]。它们的不同之处在于划分策略,一些方法通过划分RDF数据集,将数据存储到不同的节点上,在每一个节点上做查询,最终得到的结果为在每一个节点上得到结果的连接,例如文献[13]。这种方法的缺点在于在数据划分阶段会产生大量的信息冗余。另外一些方法采用不同的划分策略,它通过划分查询而不是划分数据集来实现分布式查询处理。通过划分查询而不是数据集可以有效减少中间结果的传输,通过对局部结果的连接操作得到最终的结果。这种方式的缺点在于每一台机器需要存储所有的数据集,例如DREAM(distributed RDF engine with adaptive query planner and minimal communication)[5]。
另一种类型的存储查询方案是基于分布式云平台的RDF数据管理系统。最常用的分布式云计算平台是Hadoop,学术界在此之上做了大量的工作,例如文献[6-7,14-16]。基于Pig的PigSparql[7],将数据存储在HDFS(hadoop distributed file system)中,使用Pig作为一个中间层,而不是直接使用MapReduce进行计算。基于Schätzle等人提出的Sempala[6],通过将SPARQL查询分解成一系列Parquet上的SQL子查询,对这些子查询得到的结果进行连接形成最终结果。基于Hadoop方式的主要缺点是中间结果必须回写到磁盘,从而产生大量的I/O代价,降低查询性能。为了解决这个问题,近年来,基于Spark的RDF存储查询成为一个热门的研究学术课题,产生了大量的研究成果,例如文献[2,4,8,17]。Spark是一个通用内存分布式计算平台,计算的中间结果被保存在内存中,从而可以有效降低I/O代价。S2RDF[8]是一个基于Spark的分布式RDF数据管理系统,使用了Spark的关系数据库接口SparkSQL,通过垂直划分的方式将结果存储在Spark中。在查询阶段,将每一个三元组模式对应一个数据表,对结果进行连接得到最终结果。由于RDF可以被表示为图模式,因此也可以使用分布式图并行计算框架来实现SPARQL查询。第一个工作是Goodman等人基于GraphLab实现的[18]。Spar(k)ql[4]的原理类似于文献[18],基于GraphX实现。这两种方式的缺点在于在每一个超级步中只能处理一个三元组模式。另外一个工作是S2X[3],这种方式的优点是将图并行和数据并行结合到一系统中,但是缺点是会在第一轮迭代中产生大量的中间结果。
3 问题定义
定义1(RDF三元组)RDF三元组是一系列形如(s,p,o)的数据组合。其中s代表主体(subject),p代表属性(property),o代表客体(object)。三元组的取值区间可以表示为(U⋃B)×(U⋃B)×(U⋃B⋃L),其中U代表URI,B代表空值,L代表文本信息。
例如,对于三元组(苹果,种类,水果),苹果代表主体,种类代表属性,水果代表客体。三元组表示的意思是苹果的种类是水果。
定义2(RDF图模型)RDF图模型可以用一个四元组(V,E,LV,LE)来表示。其中,V代表RDF数据图中的顶点集,每个点代表RDF三元组中的主体或者客体;E是RDF图模型中的所有边的集合,每条边代表RDF三元组中的属性;LV是图中所有的顶点标签的集合;LE是图中所有边标签的集合。通常,任意两个顶点之间不存在双向边。
图1(b)给出了一个对应图1(a)中RDF三元组的图表示。其中方框中的元素代表URI或者空值,双引号中的元素代表文本属性。
定义3(三元组模式)当一个三元组中的元素被变量取代时,该三元组被称作一个三元组模式。一个三元组被称作是三元组模式的匹配当且仅当对应位置元素相互匹配。其中,变量可以匹配上所有元素,常量只能匹配上同标签元素。
定义4(SPARQL查询)一个SPARQL查询是一系列三元组模式的集合。SPARQL查询图是SPARQL查询的图模型表示。本文关注的主要是以select开头的选择性查询。
定义5(SPARQL查询匹配)给定一个RDF图G和一个SPARQL查询图Q,M是G的子图,M是Q的一个匹配当且仅当存在函数f:V(Q)→V(M)使得:
(1)对Q中的任意顶点v,如果v是一个变量,f(v)可以匹配任意值。如果v是一个常量,那么f(v)和v具有相同的URI或者文本属性。
(2)对于Q中的任意边(u,v),(f(u),f(v))是M中的边,且边上的标签一致。
对于图2(b)中的查询图和图1(b)中的RDF图,(ub:publication4,rdf:type,ub:Publication),(ub:publication4,ub:publication Author,ub:assistant Professor2)组成Q的一个匹配。
本文解决的问题可以形式化地表述为如下形式:给定一个RDF图G和一个SPARQL查询图Q,找出Q在G中的所有匹配。
4 SPARQL查询处理
本文提出了一种新的基于GraphX的SPARQL查询处理方式,利用GraphX的并行计算的威力来加速SPARQL查询。4.1节详细介绍了SQX用到的数据模型;4.2节介绍了如何根据给定的SPARQL查询图生成相应的查询计划;4.3节介绍了查询处理算法的具体细节。
4.1 数据模型
在本文方法中,RDF数据以属性图(property graph)的形式存储在GraphX中。在RDF数据中,存在两种类型的属性,分别为数据属性和对象属性。其中数据属性指的是连接实体和文本的属性,而对象属性代表连接两个实体的属性。例如在图1(b),谓词“ub:name”是一个数据属性而谓词“ub:publication Author”是一个对象属性。在本文的模型中,将数据属性存储到节点的内部,而对象属性被保留为边。通过将数据属性存储到节点的内部,可以有效减少图中顶点和边的数量,从而有效减少图的大小。对于每一个顶点,对应的顶点数据格式为(顶点ID,URI,数据属性集)。特殊的,将对象属性“rdf:type”当作数据属性存储在节点内部,这是SPARQL查询中最常见的属性,并且通常不会将该属性作为查询结果。通过将“rdf:type”存储在节点的内部,可以有效减少属性图中边的数量并且可以快速定位到相应类型的节点[18]。
图3是图1(b)中RDF图的一个属性图表示,其中对象属性被当作一条边,而数据属性被存储在节点的内部。
4.2 查询计划生成
给定一个SPARQL查询Q,首先为Q生成一个相应的查询计划。查询计划代表查询图中三元组模式的匹配顺序。例如,对于图4(a)中给出的查询图,图4(b)给出了对应的查询计划。查询计划由以下三部分组成:
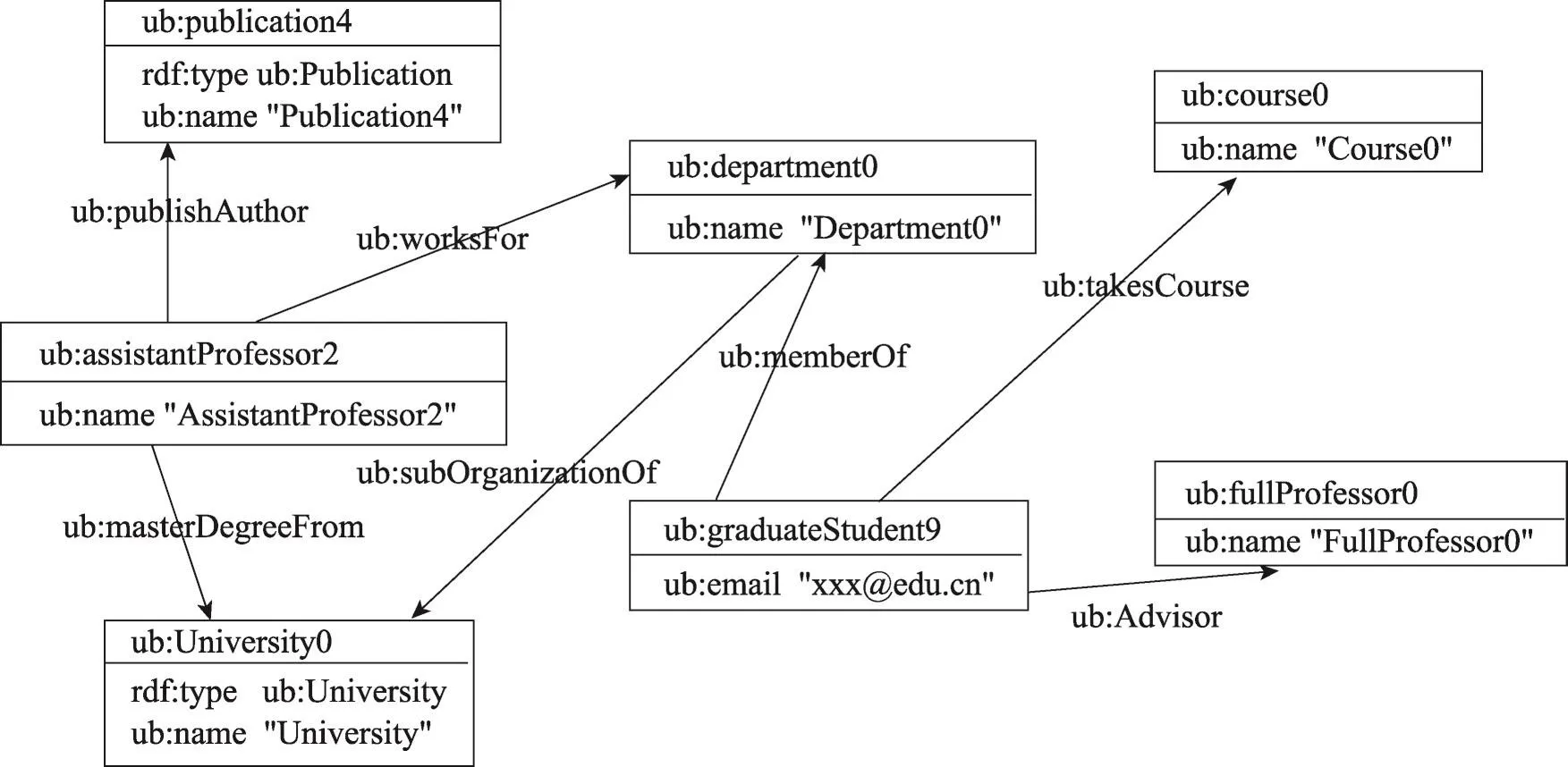
Fig.3 RDF property graph图3 RDF属性图
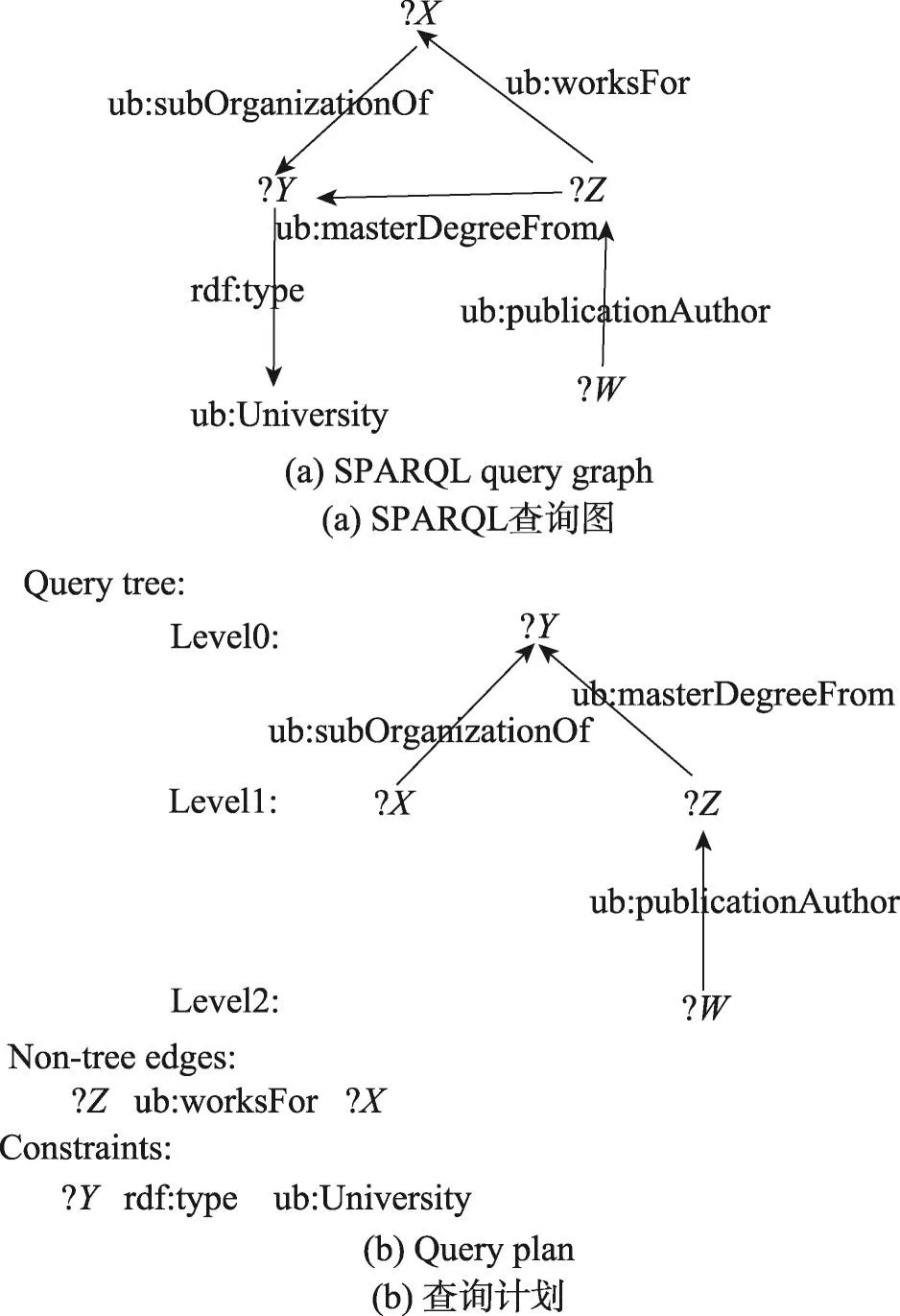
Fig.4 SPARQL query plan generation图4 查询计划生成
(1)查询树。查询树是从给定的查询图中提取出的树结构。在这个例子中,三元组模式(?X,ub:publicationAuthor,?Y),(?Z,ub:master Degree From,?Y),(?W,ub:publication Author,?Z)构成了相应的查询树。树中的节点被分配到不同的层中,根节点所在的层为第0层,其他每一个节点的层数为该节点到根节点的距离。例如?Y的层数为0,?X的层数为1。相邻顶点层之间的三元组模式将在一个超级步中被处理。
(2)非树边。非树边指那些在查询图中而不在查询树中的边,用于迭代完成之后的结果过滤。在这个例子中,非树边为(?X,ub:works For,?Z)。
(3)约束条件。约束条件指的是查询图中的数据属性。用于从非树边过滤完成后的结果中筛选出最终的结果,最终结果必须满足所有约束条件。在这个例子中,三元组模式(?Y,rdf:type,ub:University)是一个约束条件,?Y匹配上的节点中满足类型是大学的顶点才有可能成为最终的结果。
SPARQL查询处理具体步骤的形式化表述如下:给定一个SPARQL查询图,生成相应的查询计划,根据生成的查询计划首先匹配查询树,在得到的匹配结果中,利用非树边和约束条件进行结果过滤。
算法1给出了查询计划的具体生成过程。给定一个SPARQL查询,算法主要运行以下两个步骤:
步骤1(约束提取)首先提取数据属性并将它们转换成约束(第1行)。特殊的,如果给出的SPARQL查询中所有的三元组模式都是数据属性,那么将没有必要进行迭代,算法将不会发送任何消息,最终的结果将从所有满足约束条件的顶点中得到(第6行)。
步骤2(查询树构建)提取完数据属性之后,根据剩下的三元组模式构建查询树。一个查询图可能对应多棵生成树,需要从这些树中挑选最优的一棵。直观的,这棵查询树需要拥有最低的查询代价。因此提出了一种基于代价的查询树构建方案,为每一条边分配一个权值,然后找到该查询图的最小生成树MST(第3行)。边上的权值是对应的谓词在RDF数据库中出现的频率。这样做的原因在于出现频率低的边将发送更少的消息,通过使用最小生成树可以有效降低传输代价。不被最小生成树所包含的边被加入到非树边集合中。在得到最小生成树之后,为了使每一个超级步中的数据传输相对均衡,采用使层与层之间权值边权值方差最小的方案来挑选根节点。根节点的层数为零,其他节点的层数为该节点到根节点的距离。相邻层之间的所有三元组模式将在一个超级步中完成。采用一个自底向上的匹配方式来完成匹配过程,因此定义查询树中边的方向为从子节点指向其父节点。
为了方便后续查询,对每一个三元组模式构建一个匹配模式(第10行)。匹配模式包含三部分:三元组模式、源顶点和所有发送消息到该顶点的顶点集合。源顶点的作用是指明三元组模式中消息传递的方向,消息从源顶点发送到三元组模式的另外一个顶点。而所有发送消息到该顶点的顶点集合用于计算最终结果是否涉及查询图中的所有顶点,集合元素少于查询图中顶点个数的结果将被过滤。匹配模式自顶向下构建,相邻层之间的匹配模式将在一个超级步中被处理。
算法1查询计划生成
输入:谓词权值集合W,SPARQL查询Q。
输出:查询计划QP,迭代集合IL,非树边NonTreeEdges,约束条件Constraints。
1.将SPARQL查询划分为约束条件Constraints和对象属性OP
2.IfOP不为空Then
3.找到使相邻层之间边权值方差最小的最小生成树MST
4.非树边NonTreeEdges←OPMST中的三元组模式
5.Else
6.returnConstraints
7.End if
8.IL←∅
9.ForMST中的每一个三元组模式do
10.自顶向下构建匹配模式
11.将相邻层之间的匹配模式加入同一轮迭代iteration中
12.IL←IL⋃iteration
13.End for
14.returnQP(IL,NonTreeEdges,Constraints)
4.3 查询处理
查询处理主要分为两部分,查询树匹配和结果过滤。在查询树匹配阶段,采用自底向上分层匹配的方式。在执行匹配之前,首先需要将迭代进行反序。针对图4(b)中给出的查询树,在第一个超级步中首先匹配第一层和第二层之间的三元组模式(?W,ub:publication Author,?Z),完成之后匹配第0层和第一层之间三元组模式(?Z,ub:master Degree From,?Y),(?X,ub:subOrganizationOf,?Y),最终所有节点的匹配结果都将被发送到根节点。将每一轮的匹配结果以消息的形式从源顶点发送到相应的目的顶点。对于查询树中的每一个三元组模式,如果该三元组模式对应的边的方向和SPARQL查询图中边的方向一致,那么对RDF属性图中匹配上的三元组,消息从主体发送到客体。反之,消息从客体发送到主体。在本文的方法中,不考虑谓词为变量的情况。消息的格式包括三部分:目的顶点、谓词和匹配结果表。匹配结果表的表头为当前已经匹配完成的顶点,对应的值为相应的匹配结果。当匹配完一个三元组模式之后,在相应的表中添加一列,并添加相应的匹配结果。
以图4(b)中的查询和图3中的RDF属性图为例。考虑查询图中第0层和第一层之间的三元组模式(?Z,ub:master Degree From,?Y),属性图中所有谓词为“ub:master Degree From”的边消息从主体发送到客体。消息的头顶点为?Y,谓词为“ub:master Degree-From”,由于?Z有一棵子树,因此最终的?Y收到的消息结果是?Z顶点中存储的匹配结果和这一轮中匹配上的结果的连接。
在一个超级步完成之后,RDF属性图中的顶点可能会收集到从它邻居顶点发送来的多条信息。需要将这些消息进行合并,从而得到相应的中间结果存储在目的顶点中。通过例子的方式来说明本文的合并过程。考虑图5中一个顶点收到的3个消息M1、M2和M3。它们有着共同的目的顶点?X,消息的合并涉及到两个操作,union和join。第一阶段,因为消息M1和M2有相同的谓词P1,所以通过union操作将它们合并成一个表M12。第二阶段,因为消息M12和消息M3谓词不同,所以通过join操作将它们合并,移除谓词之后得到最终的合并结果,同时更新顶点的中间结果。具体的过程如图5所示。通过定义消息的合并顺序,算法可以在一个超级步中处理多个三元组模式并保证在合并消息的过程中不丢失结果。
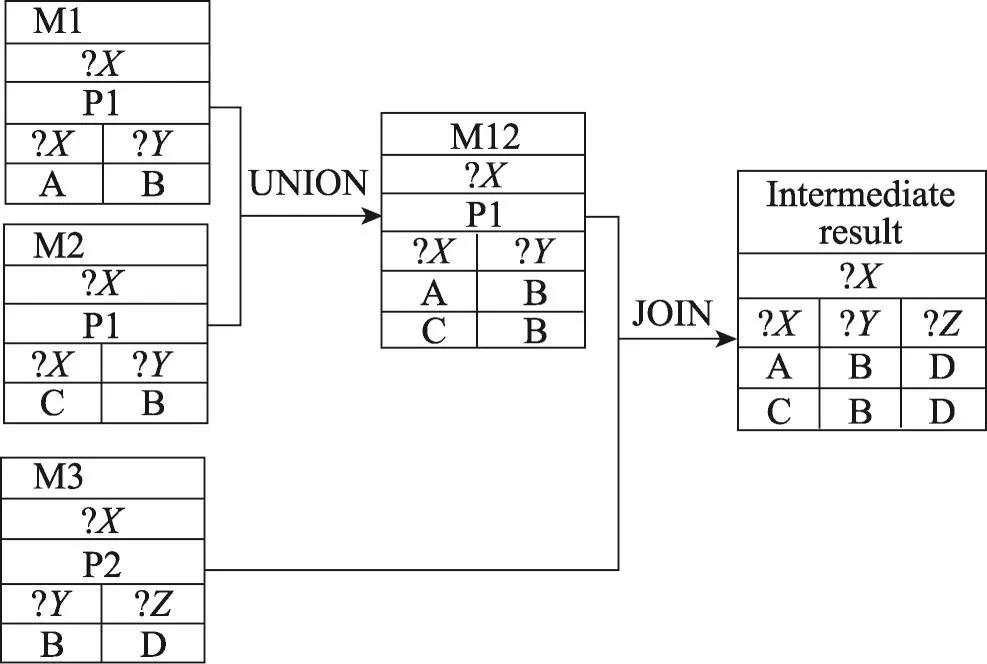
Fig.5 Illustration of message merging图5 消息合并方案
查询树的匹配过程基于GraphX的Pregel模式实现,Pregel是一个图并行计算接口,主要包括3个函数:msgCombiner、vertex Program 和 sendMsg。如果RDF属性图中的顶点是激活的,那么它将执行这一轮的超级步中所有这3个函数。在一轮超级步中,所有谓词和三元组模式中谓词相同的边将在sendMsg阶段将消息发送到它的对应的邻居节点,在msg-Combiner阶段,到达同一个顶点的具有相同谓词的消息将通过union操作被合并。最后,在vertexProgram阶段,具有不同谓词的消息通过join操作被合并,并且将合并后的结果作为中间结果存储到对应的数据顶点中。特殊的,如果想要查找数据属性,例如对于SPARQL查询(?X,ub:name,?Y),在查询计划的构建过程中,将它作为一条边而不是约束条件。然而在RDF属性图中,对应的属性被存储在了节点内部,因此不能通过迭代的方式得到相应的结果。为了解决这种情况,在一个超级步开始之前,检查每个三元组模式对应的谓词是否是一个数据属性谓词,如果是,那么在顶点的内部将数据属性合并到顶点的中间结果表中,同时在这一轮迭代中不发送任何消息到它的邻居顶点。
给定一个查询计划和属性图,算法2给出了具体的匹配过程。
算法2查询树匹配
输入:属性图G,迭代集合IL。
输出:包含结果的属性图G。
1.reverseIL/*反转迭代,自底向上匹配*/
2.Foriteration∈ILdo
3.Fortriplepattern∈iterationdo
4.If谓词在顶点内部出现then
5. 将数据属性合并到顶点的中间结果
6.Else if方向和SPARQL中一致then
7. 消息从主体发送到客体
8.Else
9. 消息从客体发送到主体
10. End if
11.End for
12.For∀v∈V&&vis active do
13. 合并到达v的谓词相同的消息
14.End for
15.For∀v∈V&&vis active do
16.合并到达v的所有消息并更新中间结果
17.End for
18.End for
在找到所有的查询树的匹配之后,还需要通过非树边和约束条件来对结果进行过滤。对于查询树匹配上的每一个匹配结果M,任意一个属于非树边集合中的三元组模式(u,p,v),检查(f(u),f(v))是否是M中的一条边,并且边上的标签为p。如果存在一条非树边使得M不满足条件,那么该匹配结果不可能是最终的结果,该结果可以被去除。完成非树边过滤之后,检查剩余的匹配是否满足所有的约束条件,满足所有约束条件的结果将被作为最终的匹配结果。通过这种“查询树匹配”+“结果过滤”的匹配方式,可以有效减少迭代轮数,大大提高查询性能。
5 实验与结果
在本章中,在数据集LUBM[19]上做了大量的实验来验证本文方法的查询性能。
5.1 实验设置
本文将在一个包含6个节点的集群上测试SQX的查询性能。集群包含5个worker节点和1个master节点。每个节点包含一个1.90 GHz 6核Intel Xeon E5-2609v3 CPU,480 GB固态硬盘和12 GB内存,运行系统为CentOS7。在Spark1.6.1上实现本文的算法,并使用Standalone模式,RDF数据被存储在HDFS中。将SQX和现有的两种基于Spark GraphX的SPARQL查询算法S2X[3]和Spar(k)ql[4]进行比较,实验的数据集为Lehigh University Benchmark(LUBM)。LUBM是一个公开的关于大学的数据集,通过改变相应的参数可以产生不同大小的数据集。实验使用的数据集对应的参数、文件个数和三元组数量如表1所示。
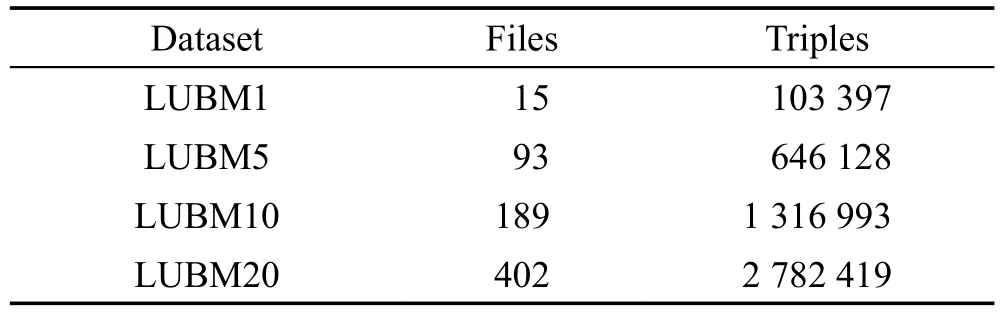
Table 1 Basic information of LUBM dataset表1LUBM数据集基本信息
5.2 查询评估
在本节中,使用所有的6个节点,在LUBM20上比较SQX、S2X以及Spar(k)ql的查询性能。使用LUBM提供的Benchmark中的查询,将查询分为简单查询和复杂查询。简单查询通常为星形查询,复杂查询为链状查询和包含环的查询。
图6(a)显示了针对简单查询 Q1、Q3、Q5、Q6、Q10的3种算法的查询性能。所有的这些查询都不包含环结构。可以看出,SQX的查询性能比S2X快很多,因为减少了大量的中间结果,从而有效提高了查询性能。SQX和Spar(k)ql查询时间基本一致,因为这些查询都只包含一个对象属性,两种方法都可以在一个超级步中完成,所以在查询时间上SQX优势并不明显。
图6(b)显示了针对 3个复杂查询 Q2、Q7、Q9 SQX和S2X两种方法的查询性能。其中,Q2和Q9为环状查询,Q7为链状查询。没有将Spar(k)ql列入比较是因为Spar(k)ql不能在可接受的时间(8 h)内完成查询。实验结果表明,对于复杂查询本文的方法查询速度比S2X更快。
5.3 可扩展性评估
在这一节,使用3个查询Q1、Q2、Q7来验证SQX的可扩展性。通过改变数据集的大小来验证方法在不同大小数据集上的查询性能。使用LUBM1、LUBM5、LUBM10和LUBM20数据集,实验结果如图7所示。从实验结果可以明显看出,随着数据集的增大,查询响应时间呈线性递增,并且对于不同查询的增长速度不一样。查询2的查询时间比查询1和7的查询时间增长得更为剧烈,原因在于查询2为带环查询,并且包含3个三元组模式,产生的中间结果更多。

Fig.6 Query processing time of different queries图6 不同查询的处理时间

Fig.7 Query processing time of different data set sizes图7 不同数据集大小查询处理时间
通过改变集群节点个数,来验证集群大小对查询的影响,对应的查询处理时间如图8所示。可以看到,随着节点数的增加,对于全部的3个查询,查询响应时间先减少后增加,原因在于随着节点数的增加,集群计算能力增加,但是当节点增加到一定数量时,消息传递的代价增大,相应的查询处理时间将变长。
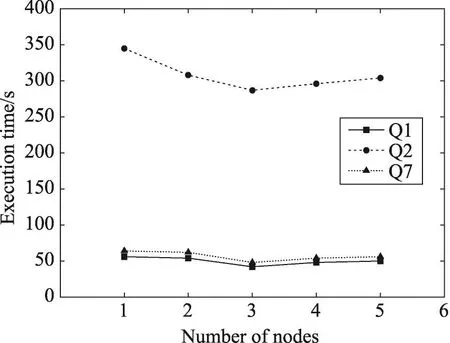
Fig.8 Query processing time of different number of cluster nodes图8 不同节点数查询处理时间
6 总结
本文提出了一种新的基于Spark GraphX的分布式RDF数据查询方法SQX。从图的视角来评估SPARQL查询,RDF数据被视为一个属性图并且中间结果和最终的结果存储在属性图节点的内部。提出了一个新的查询计划生成方案,将SPARQL查询分解为查询树匹配和结果过滤两个阶段。同其他基于GraphX的方法相比,SQX可以在一个超级步中处理多个三元组模式,充分利用了GraphX的并行计算能力。实验结果表明,本文的方法具有良好的查询效率和可扩展性。
猜你喜欢
计算机与生活(2022年3期)2022-03-13
中等数学(2021年9期)2021-11-22
中等数学(2021年8期)2021-11-22
计算机应用与软件(2021年4期)2021-04-15
——论胡好对逻辑谓词的误读
现代哲学(2020年5期)2020-11-30
西夏研究(2020年2期)2020-06-01
现代哲学(2019年4期)2019-12-14
五邑大学学报(自然科学版)(2019年3期)2019-09-06
计算机技术与发展(2018年12期)2018-12-20
中学生数理化·高一版(2009年6期)2009-08-31
