
濒危语言与汉语平行语料库动态构建技术研究
2018-09-26 07:07于重重张青川尹蔚彬孙沁瑶
计算机应用与软件 2018年9期
于重重 曹 帅 张青川 尹蔚彬 孙沁瑶 刘 畅
1(北京工商大学计算机与信息工程学院 北京 100048)2(中国社会科学院民族学与人类学研究所 北京 100081)
0 引 言
濒危语言,顾名思义,就是有濒临消失的危险的语言[1]。濒危语言是不可再生的非物质文化资源,抢救和保存濒危语言资料的核心任务是对这些正在流失、不可复得的语言资料及其蕴含的文化信息进行全方位的语言记录、语料处理和语言信息保存。作为低资源语言[2-4],濒危语言很多没有文字,以口语的形式存在,长篇自然话语的记录极为有限,能找到的录音人有限,不足以反映一种语言的基本面貌。同时,自然口语的人工标注、转录、对应通用语言的翻译工作量巨大。从机器翻译的角度上去分析,建立比较好的语言模型,离不开丰富语料库的支持[5]。因此,如何建立濒危语言的跨语言平行语料库是研究人员们面临的又一重要课题。吕苏语作为一种濒危语言,目前只有雅砻和尼亚格楚江沿岸的大约7 000人使用[6]。本文以吕苏语作为研究对象,为了建立吕苏语与汉语的跨语言平行语料库,首先使用jieba分词对吕苏语语料进行分词处理;然后基于TF-IDF技术来提取吕苏语语料的关键词,再以提取的关键词作为桥梁,在新浪博客静态网页下爬虫获取大量的汉语扩展文本;最后通过基于最小哈希的Jaccard相似度来计算并比较吕苏语语料与汉语扩展文本之间的相似度,将相似度较高的汉语扩展文本作为吕苏语的汉语扩展语料,实现吕苏语与汉语双语平行语料库的动态构建技术,为机器翻译奠定良好的基础。
1 语料扩展方案
吕苏语属于汉藏语系,是藏语的一个分支。目前只有族群内部的口语交流,没有文字传播。因此,为了保存吕苏语,必须要借助懂得汉语与吕苏语两种语言的母语人进行汉语的转译。通过机器翻译建立吕苏语与汉语之间的语言模型将会大大减少母语人的人工转译工作。要实现这一目标,首先需要构建吕苏语与汉语双语平行语料库。
本文针对吕苏语口语的汉语标注语料进行扩展。包含15个吕苏语的故事文本,总计25 746个单词,6 257个句子。目前的语料对于训练一个精确度较高的语言模型来说,是远远不够的。所以将吕苏语作为原始语料来获取与之相对应的汉语跨语言平行语料,简称汉语扩展语料,这一过程将有效扩展吕苏语语料库,为吕苏语语言模型的建立做充分的准备。
如图1所示,吕苏语的汉语扩展语料获取可分为四个步骤。

图1 吕苏语-汉语扩展语料获取步骤
其次,提取吕苏语语料的关键词。本文以提取出来的吕苏语核心词表作为用户自定义词典,先用jieba算法对吕苏语语料进行分词处理,然后用TF-IDF算法来实现每篇吕苏语语料的关键词抽取。平均每篇文档提取10个关键词,则提取的关键词总数为150个。结果表明,提取的关键词中包含一定数量的虚词,为了解决这一问题,每篇文档提取20个关键词,然后去掉其中的虚词,余下150词。这样不但保证了关键词的数量,而且确保了关键词的质量。
然后,爬虫获取大量汉语扩展文本。以提取的150个吕苏语关键词汇作为汉语语料爬虫的种子词汇,通过静态网页爬虫的方式从新浪博客上爬取N篇汉语扩展文本,N的计算公式如下:
(1)
式中:n是平均每篇吕苏语故事提取的关键词数,m是每篇吕苏语故事对应的k个关键词组合下爬取的汉语扩展文本篇数,l是吕苏语故事总数。本文中n和m均取10,l取15。
最后,比较每篇吕苏语语料与其相对应的汉语扩展语料的相似度。分别将吕苏语语料与爬取的汉语扩展语料进行基于最小哈希的Jaccard相似度计算,得到与每篇吕苏语语料相对应的汉语扩展语料的相似度值。如果吕苏语语料所对应的前五个相似度的值均在0.7~1.0之间,则将由此得到的前五篇汉语扩展语料作为最终吕苏语的汉语双语平行语料;如果吕苏语语料所对应的前五个相似度的最低值在0.5~0.7之间,则返回到爬虫环节,继续获取语料;如果吕苏语语料所对应的前五个相似度的最低值在0~0.5之间,则返回到关键词获取环节。
2 关键技术
本文中用到的主要方法有:在提取吕苏语语料的关键词时用到了基于jieba算法的中文文本分词技术、TF-IDF关键词抽取算法;在比较吕苏语语料与汉语扩展语料的相似度时用到了基于最小哈希签名的Jaccard相似度改进算法。
2.1 基于jieba的语料分词
目前,针对汉语分词的方法包括三种[7-9]:基于知识理解的分词方法、基于字典及词库匹配的分词方法和基于词频度统计的分词方法。本文使用的jieba分词[10]是一种基于词频度统计的全切分分词方法。jieba分词采用了动态规划查找最大概率路径,找出基于词频的最大切分组合,对于未登录词,采用了基于汉字成词能力的隐马尔可夫模型,使用了维特比算法。
如图2所示,基于jieba方法的吕苏语语料的分词过程主要包括三个方面:首先对吕苏语语料进行预处理,然后基于自定义词典的词图扫描方式以及动态规划算法建立模型,找到基于词频的最大切分组合,最后将分词结果输出。
177 3D 打印辅助微创接骨板内固定术(MIPO)改善胫骨旋转不良的前瞻性随机对照研究 张 磊,房 雷,陈 晓,史 萌,周 琳,徐盛明,苏佳灿

图2 基于jieba方法的吕苏语语料的分词过程
2.2 基于TF-IDF的语料关键词提取
基于TF-IDF的关键词抽取算法[11,12]是一种主流的关键词推荐方法。它利用候选关键词的统计性质对其进行排序,然后选取若干个排序最靠前的候选词作为关键词。
本文中对吕苏语语料及其汉语扩展语料进行关键词提取时不仅考虑到了汉语的语言特性,而且考虑到吕苏语的语言特性:在汉语特性中,如果以“的”、“了”、“是”等这些词为关键词获取扩展语料,无疑是对结果毫无帮助,因此需要将这些停止词进行过滤;在吕苏语语特性中,像“拉菇萨”、“千子山”、“什巴”等这些少见的词如果在某篇文章中多次出现,就可将其作为反映某篇吕苏语语料主题的关键词。与此同时,在提取关键词时用自定义词典代替jieba分词算法中的固有词典,有效地保留了吕苏语语料中的特有关键词。
基于TF-IDF的吕苏语语料的关键词提取步骤如图3所示。
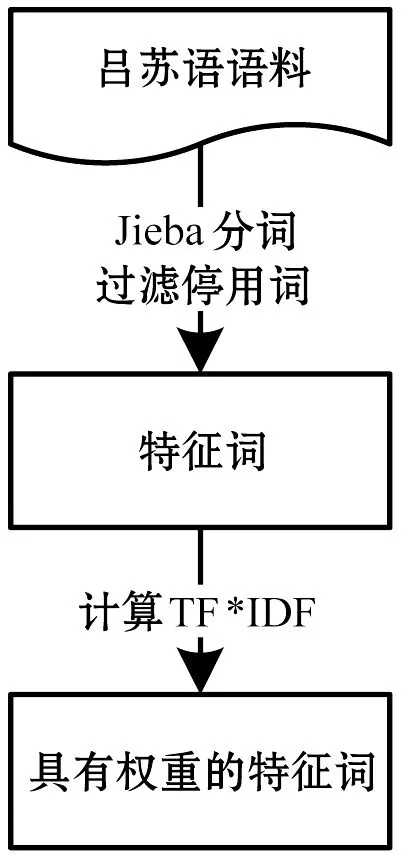
图3 基于TF-IDF的吕苏语语料关键词提取过程
本文中对于每一篇吕苏语语料,选择其中具有代表性的20个特征词作为关键词的候选词汇,然后去掉其中无意义的虚词,剩余的候选词汇作为吕苏语语料的关键词。
2.3 基于最小哈希的Jaccard相似度计算
为了识别字面上相似的文档,最有效的方法是将文档表示成短字符串集合,然后进行相似度比较。传统意义上最常用的方法是Broder提出的Shingling算法[13]。Shingling算法的原理是假定一篇文档就是一个字符串,则文档的k-shingle定义为其中任意长度为k的子串,于是每篇文档可以表示成文档中出现一次或者多次的k-shingle集合。一般来讲,对于少量语料相似度的计算,采用基于Shingling的Jaccard算法相对来说比较简单,容易实现;如果要比较相似度的语料数量较大,则会产生大量的shingling集合,导致计算的速度降低。
Jaccard相似度计算方法用来测量多个集合在共同属性上的重叠度[14]。假设给定两个集合A和B,则A、B的Jaccard相似度记为sim(A,B)。sim(A,B)计算过程如式2所示:
(2)
本文中待处理的吕苏语语料和汉语扩展语料的数量较多,故不将子字符串直接用成shingle,而是采用基于最小哈希的Jaccard相似度算法来计算吕苏语语料与汉语扩展语料之间的相似度值。基于最小哈希的Jaccard相似度算法原理是:通过某个哈希函数将长度为k的子字符串映射为桶编号,然后将映射之后的桶编号看成最终的shingle集合来进行Jaccard相似度计算。采用基于最小哈希的Jaccard算法不仅使数据得到了压缩,而且大幅度提升了程序运行的速度。具体计算过程如图4所示。

图4 基于最小哈希的Jaccard相似度计算流程
本文中基于最小哈希的Jaccard相似度计算过程如下:
1) 将吕苏语语料和汉语扩展语料中的每个故事表示成一个以k个字符为单位的k-shingle集合。假如某句子内容是“我的名字叫次仁翁嘉”,如果k设为2,那么该句子对应的k-shingle集合就是‘我的’,‘名字’,…,‘次仁’,‘翁嘉’等两个字组合的集合。
2) 统计吕苏语语料和汉语扩展语料中每个故事对应的k-shingle集合中的元素,形成特征矩阵Ma×b。Ma×b矩阵的列对应每个吕苏语及汉语扩展故事中的k-shingle集合,行对应所有吕苏语语料及汉语扩展语料中的元素。如果行r对应的元素属于列c对应的集合,那么矩阵第r行第c列的元素为1,否则为0。
3) 构建签名矩阵。首先定义哈希函数,然后建立基于特征矩阵Ma×b的签名矩阵。签名矩阵的列数与Ma×b的列数,其行数为哈希函数的个数n。令SIG(i,c)为签名矩阵中第i个哈希函数在第c列上的元素。SIG(i,c)的计算过程如图5所示。

SIG(i,c):签名矩阵中第i个哈希函数在c第列上的元素输入: • 哈希函数的个数 • 特征矩阵的维数初始化:将所有的i和c初始化为∞输出:哈希签名矩阵SIG(i,c)函数:1. Loop for i=1,2,…,n2. 计算行r对应的hi(r)3. End Loop for n4. Loop for c=1,2,…,b5. IfM(r,c)=16. SIG(i,c)=min(SIG(i,c),hi(r));i=1,…,n7. End Loop for b
图5SIG(i,c)算法流程
4) 使用Jaccard相似度计算公式来计算最小哈希下每篇吕苏语语料与其对应的汉语扩展语料之间的相似度值。事实上,两个集合经过最小哈希签名计算之后得到的两个最小哈希值相等的概率等于这两个集合的Jaccard相似度[15]。因此,本文中最终获得的相似度值直接作为吕苏语语料与其对应的汉语扩展语料之间的相似度值。
3 实验与分析
3.1 实验数据
本文使用的吕苏语语料来源于吕苏语口语的汉语标注语料,其中包含15个吕苏语的故事文本,总计25 746个单词、6 257个句子。通过对吕苏语语料进行jieba分词、TF-IDF关键词提取以及静态网页爬虫初步获取吕苏语的汉语扩展语料308篇。
吕苏语语料与初步获取的汉语扩展语料数量比为1∶20,词语数量比为2∶3。可以发现,初步获取的汉语扩展语料在数量上对吕苏语语料起到了很好的扩展作用。为了获取与吕苏语语料内容更加相似的汉语扩展语料,本文中设置了基于最小哈希的Jaccard相似度计算实验。该实验以15篇吕苏语语料和初步获取的308篇汉语扩展语料做为基本研究对象,通过计算吕苏语语料与初步获取的汉语扩展语料之间的相似度值,多次提取关键词以及爬虫获取数据,将相似度值为0.7及以上的前五篇汉语扩展语料作为最终吕苏语的汉语平行语料。
3.2 实验结果
本文中的所有算法均采用python编程在PC机下实现。为了确定该方法对濒危语言的语料扩展是否准确有效,在实验之前使用了大量的跨语言平行语料作为测试用例,编制了专门的测试程序,纠正了测试结果。测试环境为:计算机CPU为2.50 GHz,内存8.00 GB;操作平台是Windows 10;编程环境是Python2.7。
通过实验,获取吕苏语的汉语扩展语料共计75篇,其中包含的句子总数为4 231句,句子的平均长度为30词。为了验证相似性,本文对吕苏语语料及其汉语扩展语料分别进行了核心词以及文本之间的相似度计算实验。部分实验结果如表1所示。

表1 实验结果比较
结果表明,通过jieba分词、TF-IDF关键词提取、静态网页爬虫以及基于最小哈希的Jaccard相似度计算四个过程获取的汉语扩展语料在字面上与吕苏语语料之间存在较高的相似度。与此同时,通过阅读吕苏语语料及其汉语扩展语料发现二者语义都涉及到类似的生活场景。
4 结 语
本文以吕苏语作为研究对象,应用了基于jieba算法的中文语料分词技术、TF-IDF的关键词提取技术、静态网页爬虫技术以及基于最小哈希的Jaccard相似度算法获取了吕苏语的汉语扩展语料。该扩展语料不仅使得吕苏语语料库在数量上得到了很好的扩展,而且吕苏语的汉语扩展语料与吕苏语语料在内容上具有较高的相似度,为下一步吕苏语语言模型的建立奠定了良好的基础。
通过对吕苏语的汉语扩展语料的获取,实现了濒危语言与汉语双语平行语料库的动态构建技术。此技术不仅为自动语音识别技术提供了良好的保障,而且对濒危语言非物质文化遗产的保存起到了至关重要的作用。在未来的研究当中,一方面会将语义作为文本相似性比较中的影响因素之一,目的是获取语义相似度较高的扩展语料;另一方面改进相似度的计算方法,实现多个文本之间字面上、语义上相似度的全面比较。
猜你喜欢
大数据(2021年6期)2021-11-22
厦门大学学报(自然科学版)(2021年4期)2021-06-22
电脑爱好者(2021年8期)2021-04-21
校园英语·月末(2021年13期)2021-03-15
电脑爱好者(2020年20期)2020-10-22
电脑知识与技术(2019年23期)2019-11-03
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
电脑爱好者(2015年13期)2015-09-10
外语教学理论与实践(2014年2期)2014-06-21
