
用于SAR图像海面溢油自动识别的Bagging-AdaBoost决策树分类器系统
2018-10-12 11:02丁新涛贺明霞
中国海洋大学学报(自然科学版) 2018年10期
丁新涛, 曾 侃, 贺明霞
(中国海洋大学海洋遥感研究所,山东 青岛 266003)
海上溢油是人类工业活动引发的严重海洋环境污染之一。上世纪90年代以来,国际上可用于海洋观测的业务化卫星大发展,为海上溢油事故监测提供了无可比拟的新技术支持。其中,星载合成孔径雷达(Synthetic Aperture Radar, SAR)具有高空间分辨率、全天时全天候工作等优点,且对海面油膜的探测灵敏度高,被公认为监测海面溢油的理想传感器。
SAR对海面的成像机制基于雷达波与海面毛细波或短重力波的相互作用,其简单模型是Bragg散射。海面油膜的存在,引起局部海表面张力的变大,导致海面粗糙度的变小,从而使Bragg后向散射系数变小。在SAR图像上,海面油膜相对于周围海面呈现为暗斑。但是,SAR图像中的暗斑不仅是海面溢油,众多大气和海洋现象都可能导致SAR图像中的暗斑,它们被称为疑似溢油(look-alikes)。因此,利用星载SAR图像监测海面溢油的关键技术之一是海面溢油和疑似溢油的自动识别技术[1-3]。
目前,用于海面油膜识别的分类方法主要有四种,分别是概率统计模型[4-11]、神经网络[12-18]、决策树[2,21-23]以及模糊逻辑[19-20,32]。这些方法的共同点是,通过各种方式试图建立一个高检测率的单分类器。实际上,获得一个高检测率及优秀泛化性能和稳定性能的强单分类器是相当困难的,因此,Schipire等于1990年代在计算机学习领域提出了将多个弱分类器组合为强分类器的算法[24],其中包括Boosting算法及其改进型AdaBoost算法[25-26]和Bagging算法[30-31]。这些算法在计算机领域已成为分类器性能增强的通用方法。2006年,Geraldo L B Ramalho等在模式识别国际会议上首次以神经网络作为Boosting算法的内核对SAR图像进行海面溢油检测[27],结果显示Boosting算法增强了神经网络的分类结果。2012年,Topouzelis等首次使用Bagging算法组合多个决策树分类器对溢油和疑似溢油SAR图像样本进行分类,结果显示Bagging算法增强了决策树单分类器的识别性能[28]。
本研究针对1 448个Envisat/ASAR暗目标样本,进一步验证AdaBoost算法和Bagging算法对单分类器在SAR图像海面溢油识别上的泛化性能和稳定性能的增强效果,选择决策树(Decision Tree,DT)作为单分类器内核。同时,在AdaBoost-DT分类器系统(DT-A)和Bagging-DT分类器系统(DT-B)的基础上,本研究提出使用Bagging算法组合多个AdaBoost-DT分类器系统(DT-A)构成Bagging-AdaBoost-决策树分类器系统(DT-AB),以期进一步增强自动识别分类器的检测率、泛化性能和稳定性能。
1 基本方法
1.1 决策树算法
决策树是一种树形结构的识别、分类算法。其基本思想是以不纯度为度量指标,构造一棵不纯度下降最快的树。不纯度是指某树节点上样本多类别的程度。以i(N)表示节点N的“不纯度”,当节点上的样本属于同一类时,i(N) =0;当节点上的样本类别齐全且数量相当,则i(N)很大。
决策树的构造是通过对样本集的学习,自顶向下建立决策规则(见图1)。树中每个节点代表某些样本的集合,每个分叉路径代表某一特征及其阈值对节点进行分裂生长。在每个非叶节点上,遍历所有特征参数,找到能使此节点的不纯度下降最大的特征参数及其阈值以进行分裂。以此类推,直到叶节点处不纯度为0止,此时每个叶节点中的样本都属于同一类别。
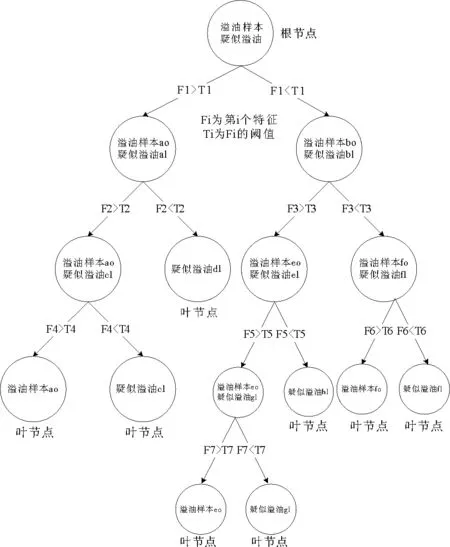
图1 决策树示意图Fig.1 The scheme of decision tree
常用的决策树算法有ID3,ID4,C4.5,C5.0,CART等,本研究选择opencv函数库中的CART树算法。CART树的不纯度指标为Gini(基尼)不纯度:
(1)
其中:i,j为类的编号;P(ωj)是节点N处属于ωj类的样本数占总样本数的频度。
在决策树构造过程中,如果树分支停止太晚,决策树的泛化性能将较差,被称为“过拟合”。相反,如果树分支停止太早,将导致分类性能较差,被称为“欠拟合”。为解决“过拟合”问题,有交叉验证、不纯度下降差门限、节点样本数门限以及剪枝等方法可供选择[22-23,31,66]。本研究同时使用opencv函数库中提供的交叉验证和剪枝方法。
1.2 AdaBoost算法
AdaBoost是Adaptive Boosting(自适应增强)算法的缩写,它是一种分类器的自适应增强算法。AdaBoost算法的基础是1990年Schapire构造的Boosting算法[40],经Freund和Schapire对Boosting算法的改进[41-42],解决了原Boosting算法中需要依靠弱学习器先验知识的限制,最终形成了AdaBoost算法。AdaBoost算法的基本思想是:针对同一个训练样本集,并选定某单分类器,例如决策树,通过调整样本权重,训练一系列不同的分类器,进而组合成一个分类器系统。调整样本权重的规则是提高分类错误样本的权重,降低分类正确样本的权重。其目的是训练下一个分类器时,更加关注上一个分类器错分的样本。如此迭代训练,构建一系列单分类器,直到足够小的分类错误率为止。AdaBoost算法目前已成为一族算法,具有多个变种,其中包括Discrete AdaBoost、Real AdaBoost、Logit Boost、Gentle AdBoost等。本研究表明,Gentle AdBoost算法对SAR溢油检测效果是较好的。本研究使用opencv函数库提供的Gentle AdaBoost算法。
Gentle AdaBoost的具体步骤如下:
第一步:定义权重分布空间。
Dm=(ωm,1,ωm,2,ωm,3,……ωm,i……,ωm,N)。
(2)
其中:m为迭代轮数,即单分类器的个数;i为训练样本编号,i=1,2,…N; 为m轮迭代时第i个样本的权重。
第二步:初始化权重空间。因为有N个训练样本,因此每个训练样本的初始权重为1/N。首先训练第一个单分类器,即迭代轮数为1,因此权重分布空间为:
(3)
第三步:进行多次迭代,训练系列单分类器。
(1)使用具有权重分布的训练样本集训练出第m个单分类器Gm(x)的回归函数fm(x),其中fm(x)值域为[-1,1],|fm(x)|反映了样本被分为某类的置信度,其符号为分类器输出的类别,即Gm(x)=sign(fm(x))。
(2)更新权重分布空间,从Dm更新至Dm+1:
ωm+1,i=ωm,iexp(-yifm(xi))。
(4)
其中:是第m个分类器对某样本xi的回归函数值。yi是xi样本的真实值。此公式表明,对于分类错误的样本,其权重被增加,且被错分样本的置信度越高其权重被增加越多。
规一化以使样本总权重为1,即:
(5)
第四步:组合各单分类器,形成一个强分类器系统,其回归函数由M个单分类器的回归函数之和求得。
(6)
其中,M是单分类器的系列总数。Gentle AdaBoost分类器系统的分类结果由下式描述:
(7)
1.3 Bagging算法
Bagging 算法的名称源自bootstrap aggregation(自助聚集),是一种组合系列同类型分类器构成一个强分类器系统的自助聚集算法。其基本思想是从个数为N的训练样本集中随机且有放回的抽取个数为n(n(N)的训练样本以形成一系列独立的自助数据集[30]。每个独立自助数据集训练一个选定类型的的分类器,例如决策树。这一系列独立决策树分类器的分类结果的平均值被取为Bagging决策树分类器系统的最终分类结果。选定的分类器被称为Bagging分类器系统中的分量分类器。
研究表明[44,50-51,54-58],当自助数据集的样本数n与训练样本集的样本数N相等时,由于其随机且有放回的样本抽取方式,某些样本可能被多次抽取,某些样本可能从不被抽取,而每个自助数据集中无重复的有效样本的概率为训练样本集总数N的63.2%,许多研究均采用这种抽取方式。另一些研究者使用了不同的抽取方式,包括按比例抽样[59]、无放回抽样[60-62,65]、交叉验证抽样[61-62]、先验概率抽样[63]、EBBag抽样[64-65]、under-sampling和over-sampling抽样[64]等。对于SAR图像海面溢油自动识别系统,SAR观测到的海面油膜和疑似油膜的样本数是不平衡的,即油膜样本往往远少于疑似油膜样本。我们希望保持各自助数据集中两种样本数比例为训练样本集中的原比例,因此本研究使用按比例,无放回抽样。
Bagging算法的关键问题是训练多少个分量分类器是最佳的。许多研究表明[48,50-53],并非分量分类器越多,Bagging系统的性能越好。许多研究者通过测试实验来确定Bagging系统中分量分类器的个数[29,44-49]。本研究表明,分量分类器过少, Bagging分类器系统的性能欠佳;分量分类器过多,会导致计算量过大而Bagging分类器系统的性能并无提高。
Bagging算法不仅是一个强分类器系统,同时亦是一个稳定性系统[30]。这是因为Bagging分类器系统中的每个分量分类器都是使用不同的独立自助数据集训练而得,因而组合的Bagging分类器系统得以适应各种样本特征空间分布情况,并对不连续处作了平均化处理[30-31]。
2 数据与特征参数
本文使用的1 448个SAR图像海面暗目标样本集源自65幅Envisat/ASAR精处理和宽刈幅图像,其中包括10幅2011中国渤海蓬莱19-3油田溢油事故期间的数据。暗目标样本由Zeng[33]等研发的自适应阈值分割算法和软件提供。经人工经验判读,其中溢油样本564个,疑似溢油样本884个。
对每个暗目标样本提取68个特征,其中包括14个几何特征、15个灰度特征、39个纹理特征(包括24个灰度共生矩阵特征和15个灰度梯度共生矩阵特征)。表1给出68个特征名称、分类和特征计算公式的参考文献[34-39,43]。
3 实验与结果
本研究建立了四个分类器和分类器系统,分别是决策树(DT)、AdaBoost-决策树(DT-A)、Bagging-决策树(DT-B)和Bagging-AdaBoost-决策树(DT-AB),并通过实验测试它们的检测率、泛化性能和稳定性能,以验证DT-A、DT-B分类器系统对于DT单分类器在海面溢油自动识别上的增强效果,并证明本文提出的DT-AB分类器系统的优良性能和应用前景。
下面,首先介绍检测率、错检率和识别率的基本概念;其次通过测试实验确定DT-B和DT-AB分类器系统中分量分类器的个数。最后分别测试DT,DT-A,DT-B和DT-AB的性能并作比较分析。
3.1 检测率、错检率和识别率
检测率,错检率和识别率是模式识别的3个重要指标。识别率是描述整个样本集内所有类别样本正确分类的比值,检测率是描述特定样本正确分类的比值,而错检率是描述特定样本被错误分类的比值。在本研究中,关心的是海面溢油样本的正确识别以及海面疑似溢油的误判,并不关心海面疑似溢油的正确识别。因此,高检测率和低错检率是SAR海面溢油自动识别业务化系统所追求的。

表1 特征参数列表Table 1 Features list
检测率、错检率和识别率的计算公式及相关符号说明为下:

人工判定类别溢油(Y=Yy+Yn)疑似溢油(N=Ny+Nn)分类器判定类别溢油(y=Yy+Ny)YyNy疑似溢油(n=Yn+Nn)YnNn
检测率=Yy/(Yy+Yn);
错检率=Ny/(Yy+Ny);
识别率=(Yy+Nn)/(Yy+Ny+Yn+Nn);
其中,检测率是分类器正确判别的溢油样本数(Yy)与人工判别的溢油样本数(Y)的比值;错检率是分类器将人工判别为疑似溢油样本误判为溢油样本数(Ny)与分类器判别的溢油样本数(y)的比值;识别率是分类器正确判别的样本数(Yy+Nn)与测试样本集总数的比值。
3.2 Bagging分类器系统中分量分类器个数的选择
如前所述,在测试两个Bagging分类器系统(DT-B和DT-AB)的检测率、泛化性能和稳定性能之前,需要通过测试实验来确定分量分类器的个数。
测试实验流程如图2所示:

图2 Bagging系统中分量分类器个数选择实验流程图Fig.2 The flow chart of the experiment that was used to test how many numbers component classifiers should be select
首先在1 448个SAR海面暗目标样本集中按溢油/疑似溢油样本比例随机抽取70%的样本作为训练样本集,剩余样本作为测试样本集。然后从训练样本集中按同样比例随机抽取70%的样本作为独立的自助数据集,并训练出一个决策树(DT)分类器和以决策树为内核的AdaBoost(DT-A)分类器系统。这个过程循环1 000次,即用1 000个独立的自助数据集分别训练出1 000个DT和DT-AB。
从训练好的1 000个分类器中随机抽取M(M=1~300)个分类器组成Bagging系统,并对测试样本集进行测试,得到相应的检测率、错检率、识别率。将这个过程循环100次,得到 100个分量分类器为M的Bagging系统,同样对测试样本集进行测试,得到100个相应的检测率,错检率,识别率。这100个独立分类器系统相应的检测率、错检率和识别率的均值和标准差即为分量分类器为M的Bagging分类器系统(DT-B、DT-AB)的分类结果。
图3为DT-B在不同个数分量分类器下的检测率及标准差。可以看出,当分量分类器个数M达到10时,分类器系统的检测率均值达到最大。随着M的增加,检测率均值呈降低趋势,标准差呈变小趋势。当M=130时,标准差趋于稳定,因此选择DT-B分类器系统的分量分类器个数M=130。
图4为DT-AB在不同个数分量分类器下的检测率及标准差。可以看出,当分量分类器个数M到10时,分类器系统的检测率均值达到最大。随着M的增加,检测率均值呈降低趋势,当M=50时,DT-AB检测率均值趋于稳定,标准差均值仍呈变小趋势。综合考虑分类性能和计算效率两方面,选择DT-AB分类器系统的分量分类器个数M=150。
对比图3和4,可以看到,DT-AB分类器系统在检测率和标准差两方面均优于DT-B分类器系统。
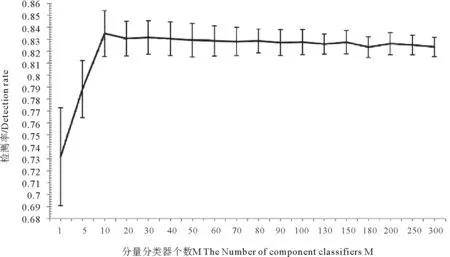
图3 DT-B在不同个数分量分类器下的检测率及标准差(检测率的标准差表示为竖线线段)Fig.3 The mean value and standard deviation of DT-B’s detection rate with different numbers of component classifiers(The standard deviations of detection rate are expressed as vertical bar lines)
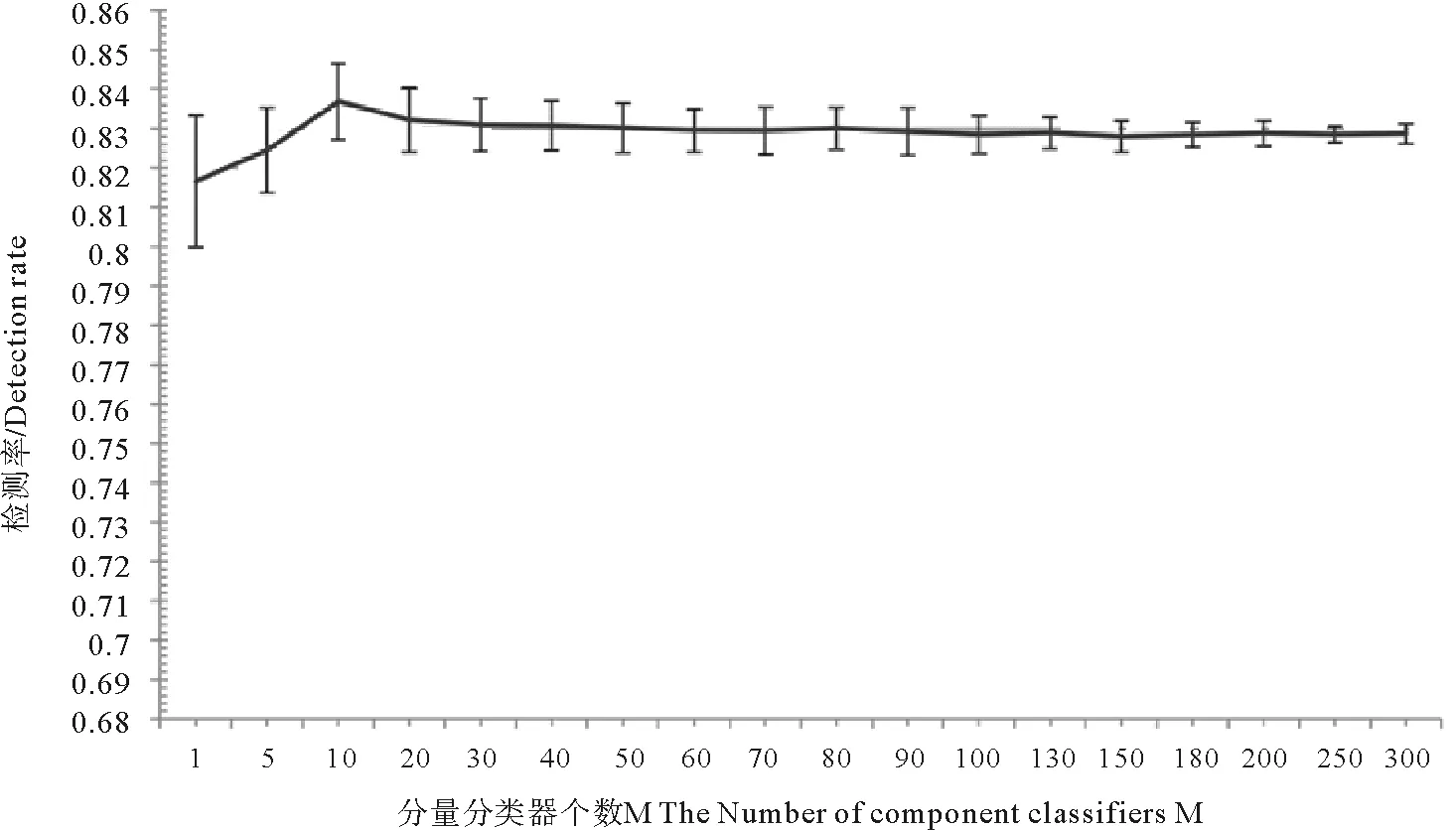
图4 DT-AB在不同个数分量分类器下的检测率及标准差(检测率的标准差表示为竖线线段)Fig.4 The mean value and standard deviation of DT-AB’s detection rate with different numbers of component classifiers(The standard deviations of detection rate are expressed as vertical bar lines)
3.3 泛化性能
泛化性能是描述分类器或分类器系统的普适性指标。常用的泛化性能测试方法有交叉验证法和自抽样法。本研究选择自抽样法(Booststrapping)对四种分类器或分类器系统(DT、DT-A、DT-B以及DT-AB)的泛化性能进行测试。自抽样法每次从样本集中抽取一部分样本训练分类器,而后对剩余样本进行测试。这样做N次,最后获取检测率、错检率和识别率的均值,作为泛化性能的衡量标准。
设计的实验流程如图5所示。
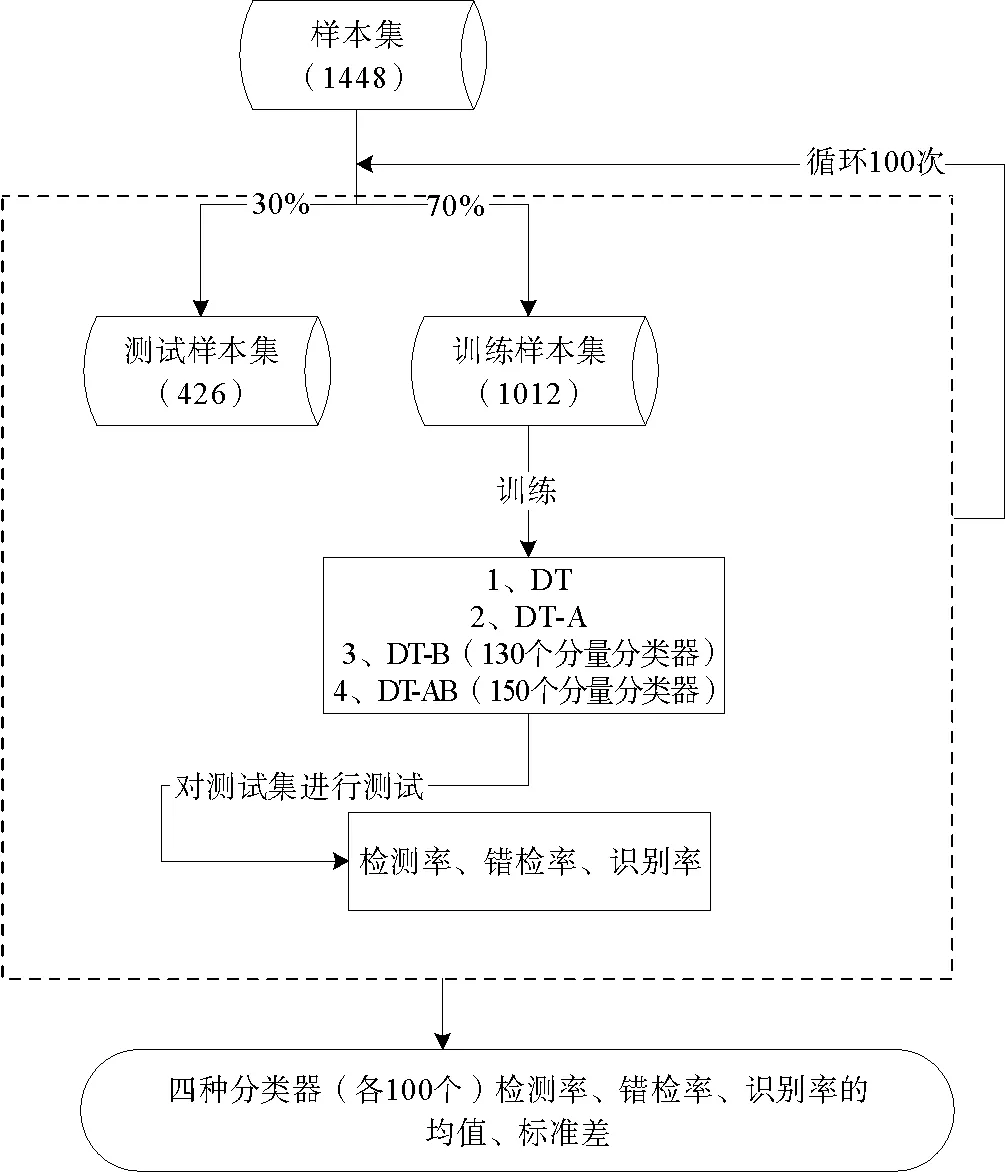
图5 泛化能力测试实验流程图
首先从样本集中按溢油/疑似溢油样本比例随机抽取70%的样本作为训练样本集,剩余30%样本作为测试样本集。用训练样本集训练出DT、DT-A、DT-B、DT-AB四种分类器或分类器系统。然后分别使用四种分类器或分类器系统对相应的测试集进行测试,得到各自的检测率、错检率、识别率。重复以上步骤100次,得到四种分类器或分类器系统各100个检测率、错检率、识别率,其中每次从样本集中随机抽取70%的样本作为训练样本集的过程即为自抽样法(Booststrapping)的概念。各100个检测率、错检率、识别率的均值和标准差即为评价DT、DT-A、DT-B和DT-AB泛化性能的指标。
实验结果如表2所示。可以看出,DT-A和DT-B的检测率、错检率和识别率均优于DT,这说明AdaBoost算法(DT-A)与Bagging算法(DT-B)确实提高了决策树单分类器的检测率和泛化性能,DT-A略优于DT-B。尤其,以DT-A分类器系统为分量分类器的Bagging系统DT-AB的检测率和识别率最高而错检率最低,说明其泛化性能最佳。
3.4 稳定性能
Breiman提出[30],如果一个分类器因训练集样本的较小改变而导致分类器性能的显著改变,则这种分类器被认为是“不稳定”(Unstable)的。
Bagging算法对分类器稳定性能的提高需通过实验进行测试。测试过程需满足训练集样本的较小改变这一条件。需要获得一系列由略有差别的训练集训练出的某种分类器或分类器系统,进而得到它们对相同测试集的检测率、错检率和识别率的均值、标准差。以标准差作为稳定性的评价指标,标准差越小,表明稳定性能越好。
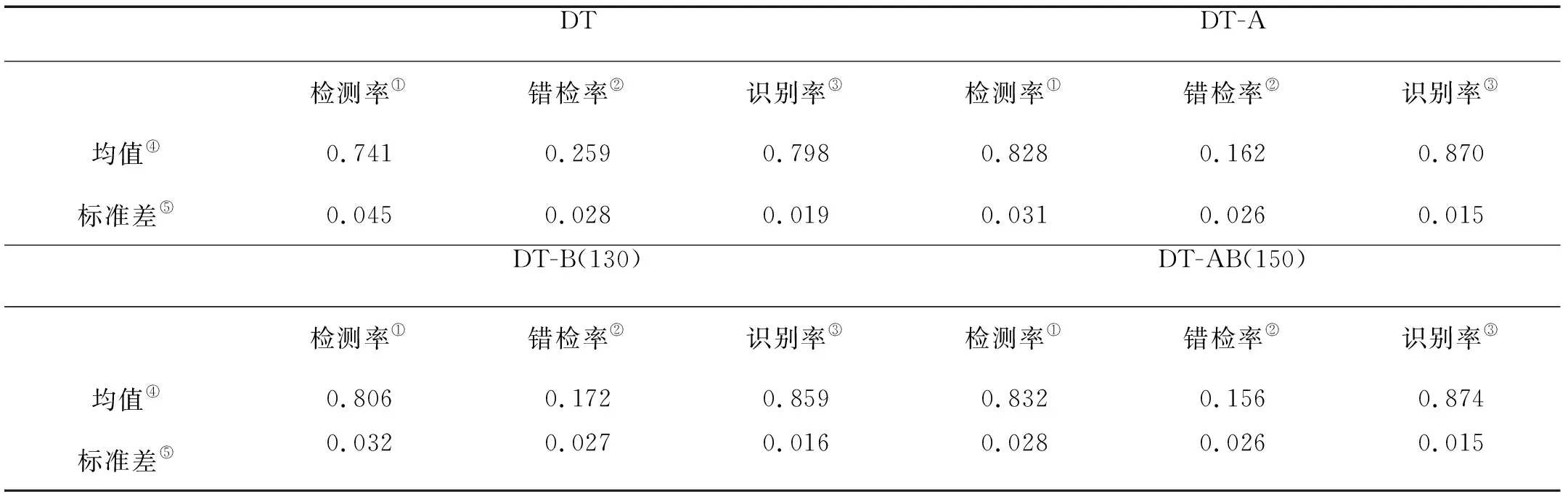
表2 泛化能力测试实验结果Table 2 The test result of generalization performance
Note:①Detection rate;②False discovery rate;③Recognition rate;④Average;⑤Standard deviation
设计的实验流程如图6所示。
首先从训练样本集中按溢油/疑似溢油样本比例随机抽取80%的样本组成微调训练集,并训练出DT、DT-A、DT-B(130个分量分类器)和DT-AB(150个分量分类器)四种分类器或分类器系统。然后分别使用DT、DT-A、DT-B和DT-AB对测试样本集进行测试,得到各自的检测率、错检率、识别率。重复以上步骤100次,得到四种分类器各100个检测率、错检率、识别率。最后,计算各100个检测率、错检率、识别率的均值和标准差,以标准差作为分类器稳定性能的指标。
实验结果如表3所示。可以看出,DT-A和DT-B的检测率、错检率和识别率的标准差均低于DT,这说明Bagging算法和AdaBoost算法不仅提高了决策树单分类器的检测率和泛化性能,同时提高了稳定性能,DT-B的标准差略低于DT-A的标准差。尤其,DT-AB分类器系统的标准差最小,说明DT-AB分类器系统不仅泛化性能最佳,其稳定性能亦最佳。
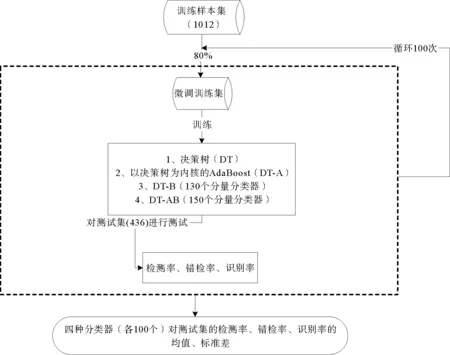
图6 稳定性能测试实验流程图Fig.6 The flow chart of the experiment that was used to test stability performance
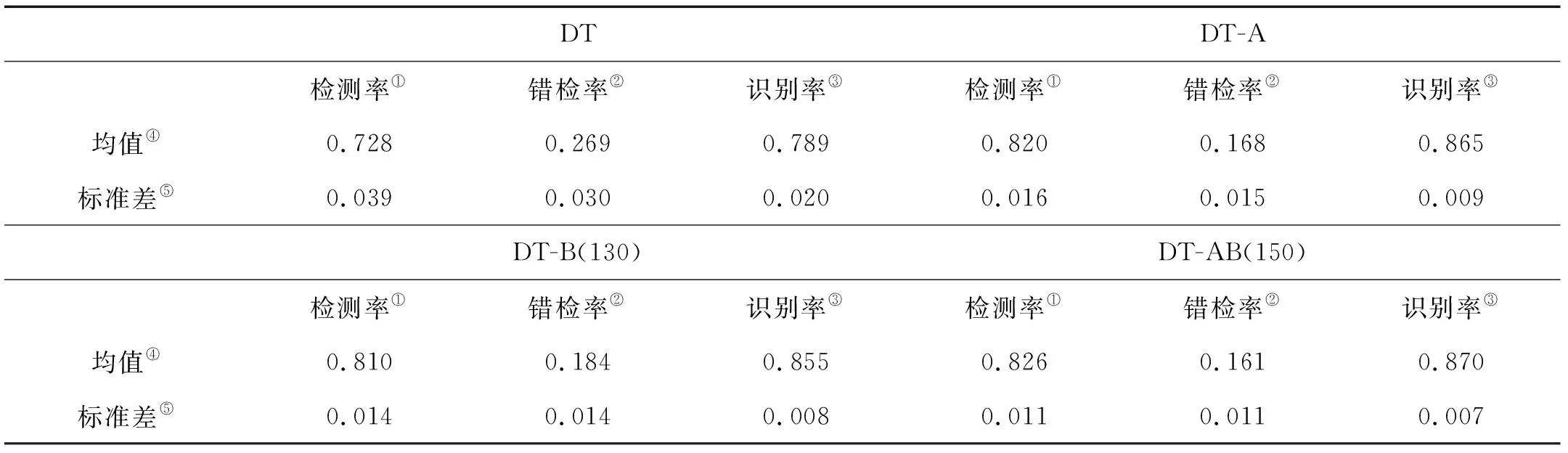
DTDT-A检测率①错检率②识别率③检测率①错检率②识别率③均值④0.728 0.269 0.789 0.820 0.168 0.865 标准差⑤0.039 0.030 0.020 0.016 0.015 0.009 DT-B(130)DT-AB(150) 检测率①错检率②识别率③检测率①错检率②识别率③均值④0.810 0.184 0.855 0.826 0.161 0.870 标准差⑤0.014 0.014 0.008 0.011 0.011 0.007
Note:①Detection rate;②False discovery rate;③Recognition rate;④Average;⑤Standard deviation
4 结论与讨论
近年一些重大的海上溢油事故引起广泛重视,从而利用卫星SAR图像自动监测海面溢油成为SAR数据海洋应用的热点之一。
目前应用于SAR海面溢油检测的分类器大多为单分类器,其检测率往往难以达到要求。本研究引入AdaBoost算法和Bagging算法,采用决策树(DT)单分类器为其内核,形成两种分类器系统DT-A和DT-B。进而提出以DT-A为内核的Bagging分类器系统DT-AB。对1 448个Envisat/ASAR(C-Band)海面溢油和疑似溢油样本集进行分类实验。结果表明:(1)AdaBoost算法和Bagging算法可以明显增强单分类器的分类性能、泛化性能和稳定性能。(2)本研究首次提出的DT-AB分类器系统的分类性能、泛化性能和稳定性能优于DT-A和DT-B。因此,DT-AB分类器系统用于卫星SAR海面溢油自动识别业务化应用方面具有前景。
本研究对不同时空覆盖的Envisat/ASAR(C-Band)样本集以及不同卫星不同波段的COSMO-SkyMed SAR(X-Band)样本集进行了同样的实验,结果与上述一致。
需要说明的是,上述用于实验的样本集中,海面溢油样本数与疑似溢油样本数的比例在1∶5左右。而实际应用中,一幅SAR图像中的海面溢油样本数与疑似溢油样本数的比例往往达到1∶100甚至更大。这种样本不平衡问题是模式识别中的难点之一。在项目研究方案中采用一个新的自适应阈值分割算法先行解决严重的不平衡问题。
今后,将针对样本集深入研究海面溢油和疑似溢油的特征参数。
致谢:感谢中海油项目“海上溢油卫星自动识别和预警业务化系统研发”对本研究的资助以及项目课题组师生对本研究的有益讨论和帮助。感谢ESA-MOST Dargon3 ID10580 Project提供Envisat/ASAR卫星图像。
猜你喜欢
化工管理(2022年13期)2022-12-02
舰船科学技术(2022年20期)2022-11-28
中国水运(2022年9期)2022-10-14
计算机技术与发展(2020年9期)2020-11-26
World Journal of Cardiology(2020年10期)2020-11-25
中国听力语言康复科学杂志(2019年3期)2019-06-24
听力学及言语疾病杂志(2019年3期)2019-05-24
专用汽车(2018年10期)2018-11-02
中国高新技术企业(2017年5期)2017-05-05
物联网技术(2016年11期)2017-01-12
