
基于自适应池化的神经网络的服装图像识别
2018-10-16 03:12屈瑾瑾许川佩朱爱军
计算机应用 2018年8期
胡 聪,屈瑾瑾,许川佩,朱爱军
(桂林电子科技大学 电子工程与自动化学院,广西 桂林 541004)(*通信作者电子邮箱ice_qu @189.cn)
0 引言
据中国产业信息网统计,2011—2016年我国网络购物用户数量持续增长,2016年网购用户总规模达4.48亿人,占比达60%。从销售额来看,2016年,我国服装网购市场交易规模达9343亿元,同比增长25%;服装网购渗透率达到36.9%。在线下零售市场环境回暖的情况下,2017年上半年服装网络销售仍保持强劲增长势头。目前服装网购以关键词文本的检索方式为主,只有在用户对要检索的服装标签非常明确的情况下,才有比较高的准确率。淘宝、京东等网购平台依赖其强大的图像及标签数据库,能在基于图像的检索时有一定的准确率,但也经常出现检索错误、分类不准确的情况[1],因此自主研制出一套具有较高识别率的服装图像识别系统显得尤为必要。

在卷积神经网络进行服装图像识别过程中,超参数的选取是影响识别率的一个关键因素:优良的超参数能够快速找到全局最优点,加快网络的收敛速度,达到较好的识别结果;反之,则有可能陷入局部最优,模型无法收敛。为了快速选取优良的超参数,吴桂芳等[16]在进行冷轧带钢表面缺陷识别问题时用到了小样本调优的算法;Jin等[17]研究了小样本情况下水下图像的识别。本文在模型超参数以及池化算法的纠正误差项方面使用了小样本调优的办法,除此之外为了进一步提高服装图像的识别率在图像预处理上增加了水平翻转、颜色光照变化的数据扩充方法。
1 网络模型分析
1.1 AlexNet网络结构
AlexNet在LeNet的基础上把CNN的基本原理应用到比较深的网络中,其主要技术特点如下:
1)激活函数选用ReLu(Rectified Linear Unit),相较之前的激活函数tanh(Hyperbolic Tangent)和sigmoid,ReLu运算复杂度降低,收敛速度更快,且对于随着网络的加深而出现的梯度消失现象具有抑制作用。图1为各激活函数图像。
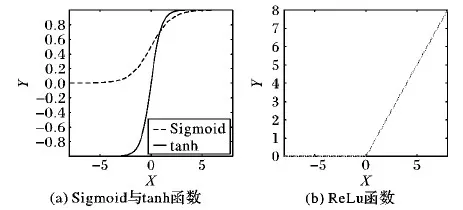
图1 激活函数
2)在第六层和第七层全连接层后分别使用了Dropout层,它按照一定的Dropout率随机忽略一部分神经元,即从原始网络得到一个更“瘦”的网络。该技术强迫一个神经单元和随机挑选出来的其他神经元共同工作,减弱了神经元节点间的联合适应性,增强了泛化能力,在很大程度上防止了模型的过拟合。图2为使用Dropout层前后对比图。

图2 Dropout使用效果图
3)在网络的第一层和第二层池化后分别增加了LRN(Local Response Normalization)层,LRN层主要是借鉴生物神经学的“侧抑制”机制对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
为了让该网络模型更好地适用于服装图像识别,在原有网络架构的基础上进行了如下改进:
1)由于本文所选的服装图像数据库中大部分图像尺寸为300×300,随机从原图像上截取227×227大小的区域,在图像预处理上首先进行了水平翻转,使得模型可以识别不同角度的实体,扩充了图像数据量,并在一定程度上防止了模型的过拟合;其次对原始图像进行亮度和对比度的调整,使训练所得的模型尽可能小地受到无关因素的影响,增强了模型的鲁棒性[18]。
2)图像池化关乎特征提取的质量,而提取的图像特征对识别率有重大的影响,原AlexNet的池化层均采用了最大池化,其计算公式如下:
(1)
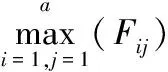
由于最大值池化仅仅是对池化域内的元素取最大值,因此并不总是提取有用信息,如图3在2×2的池化域内α2为最大值,在α1、α3未知的情况下,用最大值代替该池化域的特征会对图像造成一定程度的弱化,影响后续的分类任务。

图3 最大池化域示意图
针对服装图像,由于其花纹样式多样、图像背景丰富多变,再加上褶皱、纹理、质地、模特姿态的多变性,使得经典的池化方法难以提取有效的特征值。为了最大限度地提高服装图像的识别率,本文对原AlexNet网络的池化层作了改进,依据插值优化方法构建数学模型,在原最大值池化的基础上用适当的特定函数值作为池化结果,其算法如下:
(2)
其中,λ为池化因子,本质上是利用λ的取值来调节池化结果。λ取值利用池化域内的元素值,根据最大值池化的模型进行构建。λ的计算公式如下:
(3)
其中:c为池化域内除最大值之外的元素平均值;vmax为池化域内的最大值;δ为纠正误差项,取值范围为(0,1),该项取值需要根据识别对象动态进行调整,本文采用第2章提出小样本调优的方式选取δ值,具体实现过程在第2章中将会详细描述。θ为特征系数,计算公式如下:
(4)
其中:nepoch为网络训练的轮数,训练集全部在网络中训练完成,测试集测试一遍为一个epoch,在训练阶段,在nepoch确定的情况下,特征系数θ根据池化域尺寸取值,进而确定池化因子λ,从而求得自适应池化的结果。在当nepoch取值大到一定的程度,可以发现θ趋于0,则λ=6,池化的结果将通过池化域内的最大值和纠正误差项的取值选取最优值。在测试阶段,取nepoch=1,当nepoch值确定之后,根据式(4)可得θ=a,池化因子将通过池化域尺寸以及池化域内的元素值而确定。
自适应池化根据池化域内的元素值、池化尺寸以及训练的轮数进行调整,避免了经典的最大值池化造成的特征信息损伤的情况,使提取的特征值能够最大限度地反映原始输入图像。
1.2 自适应池化的实现
深度卷积神经网络的卷积和池化过程都是通过在原始图像或者特征图上进行从左到右、从上到下的滑窗过程实现的,因此可以利用卷积实现自适应池化。如图4(a)所示,输入的特征图尺寸为4×4,卷积核大小为2×2,以步长为1进行卷积后的特征图尺寸为3×3,以步长为2进行池化后得到的特征图尺寸为2×2。由该过程可知,卷积结果相对于池化结果从第2行第2列开始的偶数坐标的值是重叠计算的,如图4(b)将卷积结果从第2行第2列开始的偶数坐标值进行删除操作即可得到池化结果。
如图4(a)所示的特征图尺寸为4×4,现有四个2×2大小的卷积核分别为:
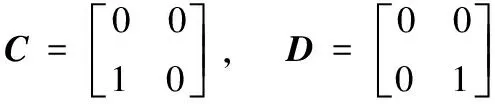
对特征图进行卷积,得到4个大小为3×3的特征图,将其连接为4×3×3的多维矩阵,定义为T1,对该空间矩阵求取对应位置的最大值即可得到1×3×3的矩阵T2,对T2进行如上所述的删除操作即可得到最大池化的结果。

图4 卷积池化的实现
自适应池化是在卷积的基础上实现的,在得到T1后,在4个二维矩阵上进行对应位置的求和运算得到T3,再计算T3-T2,求剩余元素个数的平均值,即可得到式(3)中的c的取值,根据式(4)以及c值即可求出池化因子λ值,由此可得自适应池化的结果。由自适应池化算法及实现过程可知,自适应池化是依据卷积与原经典池化的方式实现的,并未引入另外需要训练的变量,不会影响神经网络的反向传播算法更新参数过程。引入自适应池化层后所构建的网络结构如图5所示。

图5 加入自适应池化后的网络结构
由图5可知,将原AlexNet网络架构的第一、二、五层卷积后的最大值池化用自适应池化取代。对于卷积后的特征图不再是简单地对池化域内的元素求取最大值,而是根据特征图上池化域元素、池化域大小、训练轮数自适应地调整,选取更加有效的特征值,使其更好地反映原始输入。
2 数据集与实验设备
2.1 服装图像数据集
服装图像数据库采用香港中文大学2016年公开的DeepFashion 大规模服装图像数据集,该数据集主要来自购物网站和搜索引擎,论坛、博客以及用户生成图像对其进行了扩充。经过图像测试、清洗等操作,删除了重复、低分辨率以及图片内容与服装无关的图像,最终确定了80 000幅图片。它包括有不同角度不同场景的买家秀、卖家秀图像, 50个细分类别,1 000个属性特征,300 000个交叉/跨域图像对,丰富的服饰标志(每幅服装图像具有4~8个标志点),这是迄今为止最大和最全面的服装数据库。 现存的一些其他数据集致力于服装细分、解析[19-23]和时尚造型[24-25]等任务,而DeepFashion专注于服装识别和检索。
通过DeepFashion数据库开发的四个基准包括:Attribute Prediction、Consumer-to-shop Clothes Retrieval、In-shop Clothes Retrieval和 Landmark Detection。本文采用Category and Attribute Prediction Benchmark数据集,它包含289 222张服装图像,每张图像都有一个类别标注,共50个细分类,1 000个属性标注,其中上装20种,下装16种,套装14种。部分服装图像数据集如图6所示,其中前面的数字为类别码,后者为类别名。服装图像数据集的类别名以及各类别数目如表1所示。
图6 部分服装图像数据集
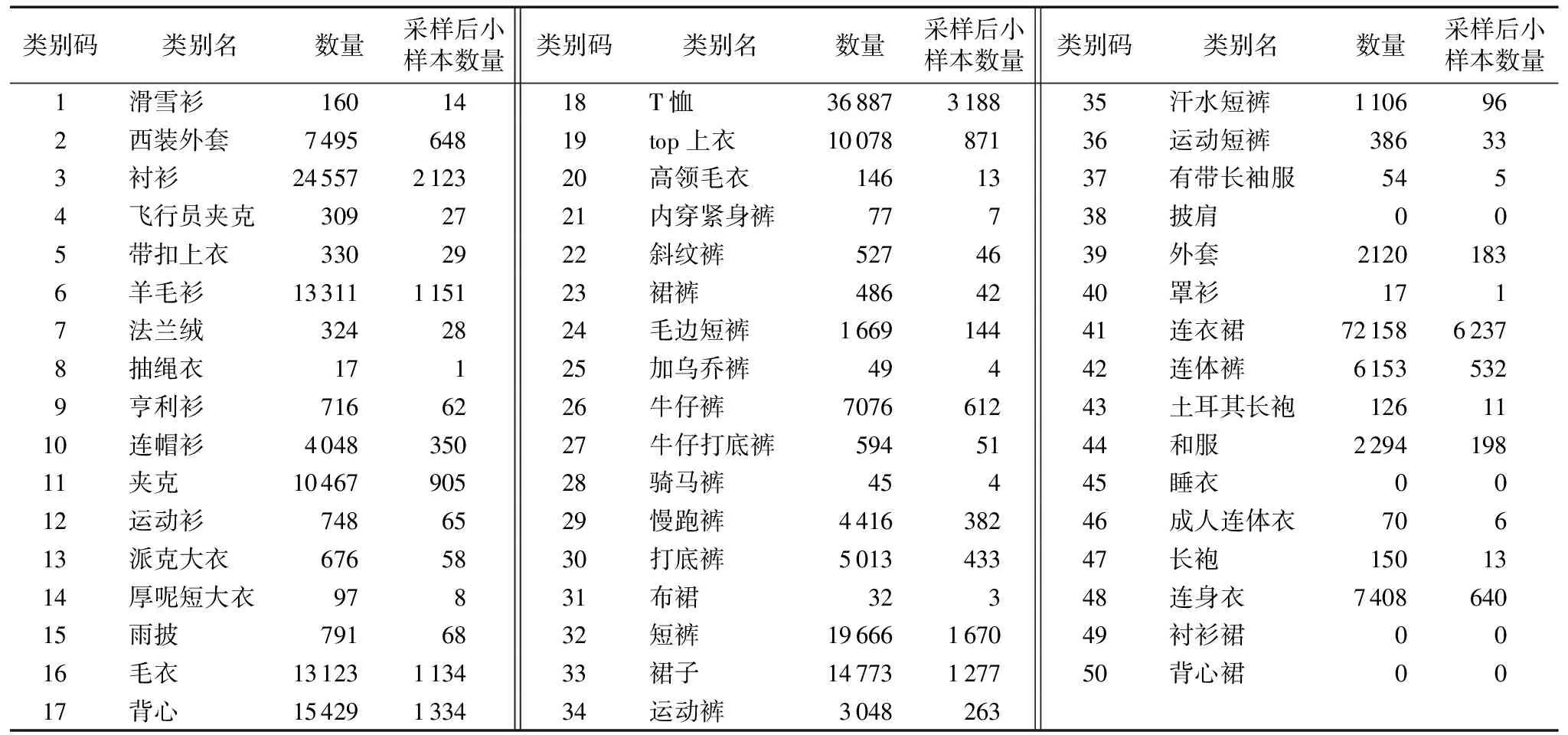
类别码类别名数量采样后小样本数量类别码类别名数量采样后小样本数量类别码类别名数量采样后小样本数量1滑雪衫1601418T恤36887318835汗水短裤1106962西装外套749564819top上衣1007887136运动短裤386333衬衫24557212320高领毛衣1461337有带长袖服5454飞行员夹克3092721内穿紧身裤77738披肩005带扣上衣3302922斜纹裤5274639外套21201836羊毛衫13311115123裙裤4864240罩衫1717法兰绒3242824毛边短裤166914441连衣裙7215862378抽绳衣17125加乌乔裤49442连体裤61535329亨利衫7166226牛仔裤707661243土耳其长袍1261110连帽衫404835027牛仔打底裤5945144和服229419811夹克1046790528骑马裤45445睡衣0012运动衫7486529慢跑裤441638246成人连体衣70613派克大衣6765830打底裤501343347长袍1501314厚呢短大衣97831布裙32348连身衣740864015雨披7916832短裤19666167049衬衫裙0016毛衣13123113433裙子14773127750背心裙0017背心15429133434运动裤3048263
2.2 小样本数据集的制作
卷积神经网络超参数的选取是影响其识别率的一个关键因素。为了选取合适的超参数,大多数研究者在全部数据集上依靠经验测试,根据识别结果确定超参数取值,该调参方式在数据量巨大、网络模型复杂的情况下费时费力,效率极低。本文所选用的数据库有289 222幅图片,数据量巨大,所选用的基础架构AlexNet网络模型有三层全连接层,需要迭代的参数量巨大,在第1章自适应池化算法式(3)中的纠正误差项δ对池化的结果影响重大,关乎到池化层特征值提取的质量。因此为了优化该调参过程以及快速选取自适应池化纠正误差项的最佳值,制作了小样本数据集,在很大程度上节约了时间成本,提高了调参选值效率。小样本数据集实验流程如图7所示。
1)小样本数据集的制作。
根据抽样的基本原理以及抽样的基本要求,由原始样本库具有特征鲜明的不同类型出发,采用概率抽样方法中的分层抽样(类型抽样)方法进行小样本的抽取任务。分层抽样在当一个总体内部类型明显时,能够提高样本的代表性,从而提高样本推断总体的精确性,特别适用既要对总体参数进行推断,又要对各子层参数进行推断的情形,具体实施步骤可分为:
a)根据总体的差异将总体分为互不交叉的层(类型)。
b)按比例k=n/N在每层当中抽取样本,k为每种类型抽取的样本数目,n为样本容量,N为总体数目。
c)合成样本。

(5)
在小样本的抽取上既要考虑总体的类别数,又要考虑每种类别占总体的比例大小,而概率抽样方法中的分层抽样能够很好地兼顾此两点。因此按照该抽取规则,小样本数据集在一定程度上可以代表原始数据集,通过小样本数据集训练所得的最优超参数在一定程度上能够适应原始数据集。按照上述抽取规则小样本数据集分布情况如表1“采样后小样本数量”所示。
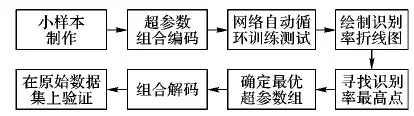
图7 小样本数据集实验流程
2)超参数组合与统一编码。
假设影响神经网络的超参数有p1,p2, …,pn,每个超参数的可取值的个数分别为c1,c2, …,cn,则可得所有的组合数M=c1×c2×…×cn,编码方式为先确定前面组合的取值,后面的参数以由后到前的顺序遍历所有值,相应的组合编号为1,2,…,M。
3)卷积神经网络自动循环训练模型并测试模型。
基于小样本数据集在所有已编码的超参数组合上进行卷积神经网络的循环训练并测试,记录每组超参数下模型训练和测试的结果,绘制图形找到识别率的最高点,经过解码确定最优的超参数组合,并在原始数据集上进行验证。
2.3 实验的硬件设施以及软件环境
处理器选用Intel Core i5-7500 CPU 3.40 GHz,显卡NVIDIA GeForce GTX1070,显存容量为8 GB,Ubuntu16.04的操作系统,Tensorflow1.3.0开源框架,Pycharm2017.2编译器,Python2.7解释器。
3 实验结果与分析
3.1 实验过程
待比较模型分别为池化层采用最大池化的模型A和池化层采用自适应池化的模型B。在原始数据集上采用十折交叉验证的方式,具体实验过程如下:
1)随机将原始数据集S分成互不相交的同样大小的10个子集,记为S1,S2,…S10。
2)对于每个模型分别用Si(i=1,2,…,10)作验证集,其余9个作训练集,共10个训练验证集组合,每次实验选取其中一组进行训练验证,记录一次识别率。依次遍历所有组合,记录10个识别率,计算这10个识别率的平均值作为模型的最终识别结果。
经过模型对比后,选定性能较优的模型,针对该模型在小样本数据集上采用小样本调优的方式,为模型选定最优超参数组合以及选定最佳自适应池化的纠正误差项。将通过小样本选取的最优超参数组合与随机选择的超参数组合在原始数据集上进行验证,以验证小样本的实用性、高效性。
3.2 实验结果与分析
3.2.1 模型对比结果与分析
模型A和模型B十折交叉验证的识别率如表2,模型对比如图8。在实验过程中,含有自适应池化模型在式(3)中的纠正误差项取值为0,实验过程中,如最后一层自适应池化域的边长为3,则可知a=3,根据池化算法推算池化因子取值,进而确定池化结果。通过比较实验数据发现,含有自适应池化的模型的平均识别率更高,为83.13%,含有最大值池化的模型的平均识别率为81.11%,自适应池化方式是对最大值池化的一种改进,在提取图像特征方面性能更优。具体实例如图9所示,其中图(a)正确的标签是10,类别名连帽衫,在未采用自适应池化模型时,模型给出的识别结果为标签17,类别名为背心;图(b)正确的标签是34,类别名为运动裤,在未采用自适应池化方法时,模型给出的识别结果为标签30,类别名为打底裤;图(c)正确的标签为48,类别名为连身衣,在未采用自适应池化方法时,模型给出的识别结果为标签41,类别名为连衣裙。在将池化模型改成自适应池化后均能正确识别。这主要是因为与最大值池化相比,自适应池化对褶皱、纹理等形变鲁棒性好,能够提取更加有效的特征值,最大限度地反映原始输入,从而取得更高的分类准确率。

表2 模型十折交叉验证结果

图8 模型A和B的识别率对比
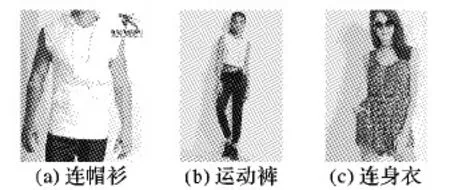
图9 具体实例
3.2.2 超参数选取结果与分析
通过分析发现,影响识别率以及训练效率的超参数主要有学习率η、每个批次训练图片数目batchsize、训练轮数epoch、每次入队图片数capacity和自适应池化公式(3)的纠正误差项δ。根据理论以及经验值,η选值为0.000 1、0.001和0.005共三组,batchsize选值为64和128共两组,epoch选值为20和30共两组,capacity选值为600和1 024共两组,δ选值为0、0.2、0.4、0.6和0.8共五组,超参数顺序为(η,batchsize,Epoch,capacity,δ),超参数的组合数为3×2×2×2×5=120,按照2.2节的编码方式为超参数组合编码1,2,…120,将这120个组合分别在小样本数据集上进行训练,测试结果如图10。
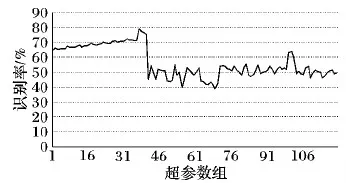
图10 小样本调参结果
由图10可知,在小样本数据集上编码为37的超参数组合识别率最高为78.98%,经过组合解码可得该超参数组为(0.000 1,128,30,1 024,0.2)。可以认为η=0.000 1,batchsize=128,epoch=30,capacity=1 024,δ=0.2为该数据集的优良超参数组。将该超参数组与随机组合的超参数在原始图像数据集上进行验证,结果如表3所示。

表3 原始数据集验证结果
从表3可以得出,通过小样本调优法选定的超参数组合为第1组,其识别率为86.98%。其余9组是随机选择的超参数,在随机选择的组合中识别率最高的为第2组,识别结果为76.31%,比第一组低了10.67个百分点;识别结果最低的为第8组,识别率为53.30%,比第一组低了33.68个百分点;同时对9组随机选择的超参数求取其平均识别率,结果为61.52%,比第一组低了25.46个百分点。
在2.3节所述的实验条件下,各类服装的识别结果如表4所示,其中识别率1为含有自适应池化层的网络模型,超参数选用上述通过小样本确定的经验值范围内的最优超参数组合,训练大约65 h后所得的各类服装的识别结果;识别率2为含有自适应池化模型,超参数选择表4中序号为2的超参数组合,训练大约45 h后所得的各类服装的识别结果;识别率3为含有最大值池化的网络模型,超参数选取通过小样本确定的经验值范围内的最优超参数组合,训练大约65 h后所得各类服装图像的识别结果。
通过对识别率1与2的分析,充分说明了利用小样本调优法选定的超参数组在经验值范围内最优,并且能够适用原始数据集。由此可知,该超参数组合能够反映服装图像的属性特征,利用该组超参数确定的网络模型对服装图像能够取得较高的识别率。通过对识别率1与3的分析,说明含有自适应池化模型的识别效果更优,在相同实验条件下,对各类服装的褶皱、纹理等形变具有高度不变性,分类准确率更高。
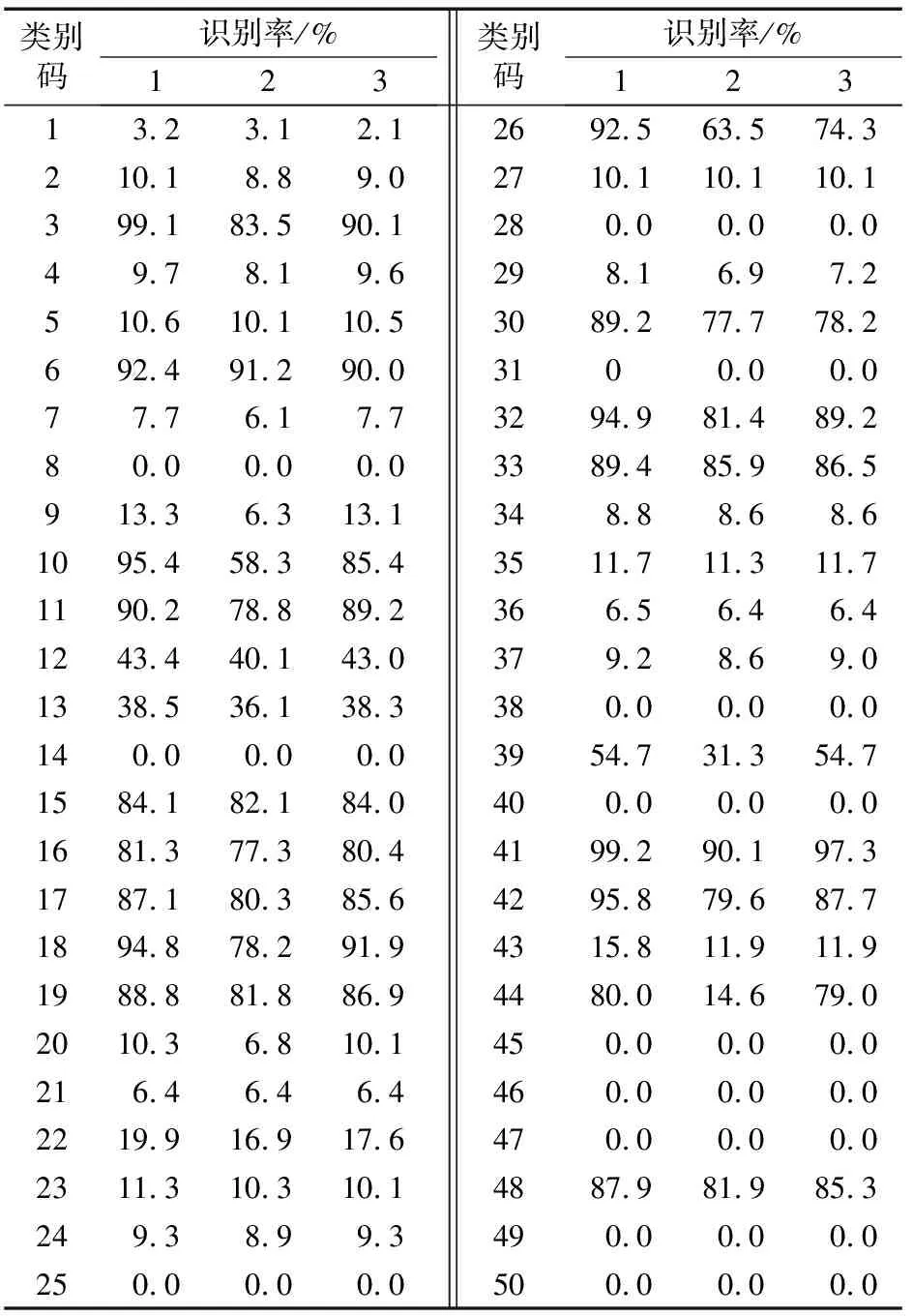
表4 各类服装的识别结果
4 结语
本文主要将深度神经网络应用到服装图像的识别中,提出自适应池化替代其传统的最大值池化,并采用十折交叉验证的方式对模型进行了测试;同时在网络模型超参数与自适应算法中纠正误差项的选取上提出了小样本调优法。实验表明,自适应池化模型相对最大值池化模型能明显提高服装图像的识别率,小样本调优法能快速地在经验值范围内寻求网络模型的最优超参数组合及最佳纠正误差项,最终确定的网络模型不仅对服装图像有较高识别率,而且泛化能力强,经过实验得出该模型在mnist数据集上可以达到约98.4%的正确率。在接下来的研究中,我们将考虑使用更加复杂的模型,并结合人脸识别算法,在网上购物平台大量的服装项目中识别视屏场景中的服装,构建一套完善且具有广泛应用的服装图像识别系统。
猜你喜欢
计算机应用(2022年9期)2022-09-25
软件导刊(2022年3期)2022-03-25
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
计算机技术与发展(2019年1期)2019-01-21
智能计算机与应用(2018年2期)2018-05-23
北京航空航天大学学报(2018年1期)2018-04-20
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
