
软件定义网络中协同存储数据面快速转发
2018-10-16 02:56朱晓东王劲林王玲芳
计算机应用 2018年8期
朱晓东,王劲林,王玲芳
(1.中国科学院声学研究所 国家网络新媒体工程技术研究中心,北京 100190; 2.中国科学院大学 电子电气与通信工程学院,北京 100049)(*通信作者电子邮箱wangjl@dsp.ac.cn)
0 引言
诸多未来网络架构研究,如信息中心网络(Information-Centric Networking, ICN)[1]、移动性优先(Mobility First, MF)[2]、内容中心网络(Content-Centric Networking, CCN)[3]等均表明,网内节点具备存储能力可以为网络性能、带宽节省等带来显著提升。同时,软件定义网络(Software Defined Networking, SDN)[4]将传统网络的控制面与数据面进行了解耦和,从而提升了网络的可编程性及灵活性,使得网络服务可以得到更高效便捷的部署。其中,数据平面存在于交换机端,负责纯粹的数据转发行为;而控制平面则存在于逻辑上中心式的控制器中,通过Openflow[5]协议对数据平面进行管理。由于SDN的这些优势,目前,已有多种研究如文献[6-7]通过扩展SDN使得网络节点具备存储能力。而为了更高效利用网内节点的存储资源,需要将各个网内节点的存储资源协同起来利用,这就需要SDN的数据平面依据周边网络节点的存储状态对数据包进行快速的转发。而由于SDN设计中数据平面对于网络状态无感知,则只能把周边节点存储状态保存于控制面,那么数据面需要频繁地与控制面交互以获取周边节点存储状态并转发数据包,这会带来极大的通信开销以及转发延迟。由于网内存储状态的快速变化,若采用控制面预下发流表的形式也面临着表项过大、依据状态调整的延迟大等诸多问题,因此需要将部分存储状态保存在数据面以适应快速转发的需求。
针对数据面状态保存及快速转发的问题,文献[8]提出在数据面流匹配后添加专设的应用流表以及相关应用库来保存信息,以实现数据面对上层应用状态的感知,将更多操作下沉至数据面,减少与控制器交互;但该方案对数据面处理流程改动较大,且数据包匹配处理流程大幅增加,影响了数据面的转发能力。文献[9]提出利用控制面对全局状态进行维护,增加了专有状态协议与交换机进行交互,在有状态流的维护时,仅对于客户端以及主机端的交换机下发涉及状态的相关流表;但该方案不适用于协同存储所需的邻接节点间频繁交互、缓存状态频繁变化的场景。文献[6]提出由数据平面直接将所需状态保存于流表项中,但该方案仅支持将数据片段存储等较简单操作,且流表项消耗较大。文献[10]通过布隆过滤器(Bloom Filter, BF)实现数据面与控制面监控开销的有效性较低。文献[11]提出基于BF的多级流表结构用于数据面表项聚合,但为保证通用化的适配需增加中间适配层以适应多语义环境。文献[12]采用联合多维BF的方式实现流表的多属性查找。
针对SDN存储扩展后协同存储对于数据面状态保存及快速转发的需求,本文设计在交换机端对各端口存储两个BF用于维护该端口方向缓存数据的存在性状态,在兼顾较低错误率的基础上有效节省了交换机端的内存开销;并扩充操作指令可直接基于BF状态转发数据请求,从而支持在数据面基于缓存状态的快速转发。不同于已有数据面维护改动较大或BF设计复杂的实现方式,针对协同缓存对于目标端口存在性识别及方便更新并支持快速转发的具体需求,本文在较为轻量级的原则上设计了双BF维护并指令直接转发的方式,为数据面状态维护与快速转发的结合研究提供一种新的思路。
1 背景与系统
1.1 协议无感知转发
协议无感知转发(Protocol-Oblivious Forwarding, POF)[13]是对OpenFlow协议的扩展,通过{offset, length}匹配的方式实现对匹配域的索引,与OpenFlow设计相比,POF交换机对于网络协议无感知,可以无需升级即提供对各种协议以及新协议的支持。同时,POF定义了一组流指令集以实现更高的性能和更灵活的转发行为,研究人员亦可以针对新的需求设计新的指令。因此,本文选用POF这种SDN技术实现用于协同存储的数据面快速转发方法。
1.2 Bloom过滤器
BF用于判定某元素是否存在于给定的集合中,它由一个二进制向量和多个哈希函数组成。相比一般算法,BF具备快速及较低空间开销的优点,查找与插入元素等操作均可在常数时间内完成,且与树、链表、哈希表等数据结构相比,它在空间消耗上也具有明显优势。但BF存在假阳性判定的缺点,存在一定错误率将不存在于给定集合的元素判定为在该集合内。若存储元素数为n,假阳性概率为p,则可选定哈希函数个数为:
(1)
所需比特位个数m为:
(2)
1.3 协同存储系统模型
本文方法涉及的协同存储系统结构如图1所示:数据面为已具备存储功能扩展的POF交换机,可以把途经的网络数据缓存在交换机的存储设备内,使网络可以更快响应用户的数据请求;控制面为逻辑上中心式的控制器对管理域内的交换机进行统一管控。
在控制端,缓存管理模块对所管理域内节点的存储状态进行维护,其更新通过节点周期性地上报存储状态来实现;缓存策略模块提供缓存策略管理,以及相应流表的生成、下发与删除等。
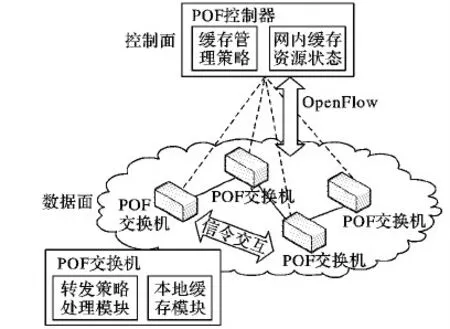
图1 协同存储系统结构
在数据平面交换机端,转发策略处理模块涉及转发策略所需相关信息的维护,如周边节点的存储容量、缓存数据索引等;并依照相应的转发策略,在交换机本地对于数据包快速转发。本地缓存模块可在本地保存及读取数据,提供对于数据的存取等功能。交换机的具体实现形式包括:1)以POF软交换机形式安装在服务器上,通过直接对本服务器文件系统进行操作的形式提供对数据的存取等操作;2)采用存储与转发分离架构,以自定义协议实现存储设备与交换机之间的交互与数据传输。交换机的本地缓存模块同时提供缓存数据分析接口,包括缓存容量查询、缓存数据名称查询、数据访问次数等;还提供可配置的本地缓存替换方式,如目前主流的最近最少使用(Least Recently Used,LRU)策略等。
为更有效、合理利用数据面内各个节点的存储资源,需要缓存管理策略来优化域内存储,使域内控制的交换机可以协同起来缓存网络数据,从而降低域内的缓存数据冗余、提高缓存命中率、使用户更快获取数据等。而缓存管理策略需要感知网络内已缓存资源的状态,并将数据请求依据网络内的缓存状态快速转发至相应的缓存节点。如节点A利用周边节点实现协同存储某内容c时,到后续内容c数据请求到达节点A,节点A需将该数据请求快速转发至协同存储的节点。而如前文所述,若缓存状态仅保存于控制面会带来诸多现实问题,因此有必要使数据面保存一定的缓存状态并支持快速转发。
2 本文方法
本文利用BF结构和POF灵活设计新指令的特性,构造满足上文中协同存储系统模型对于数据面状态维护及快速转发需求的方法。
2.1 缓存状态维护设计
将部分缓存状态保存在数据面的主要目的是支持数据面的快速转发,降低控制面与数据面过高的信令开销,降低控制面的压力;同时,由于交换机端通常资源有限,以及数据面通过控制面升级缓存状态所需的交互信令也不宜过大,还需要考虑缓存状态保存在数据面的空间开销问题。
交换机端所需用于快速转发的缓存状态为某数据是否存在于周边节点的缓存中,若采用流表存储并依据POF指令转发的方式,如果不能有效聚合数据名称,则会带来极大的流表资源开销。而如上文所述,BF适用于这一判定存在性的场景,且空间利用率高。可对交换机的每一个端口维护一个BF表用于判定该端口对应路径上缓存数据的存在性。同时,类比传统IP网络,上层应用可以承受一定程度的包丢失率。这样BF所存在的较低的假阳性问题带来的转发错误可能性,也可以为上层应用所承受,且可以进一步采用相关措施来降低假阳性概率。
本系统中可能出现的判断假阳性问题包括:1)由BF特性所带来的错误判定为真;2)由于交换机端缓存状态更新不及时导致的错误判定。后者可通过权衡错误代价与交互代价,由系统设计来调整缓存更新的速率与方式来解决。如在带宽允许的情况下,可通过提高节点间交互缓存数据的频率来降低错误率。而对于BF特性的问题,为进一步降低错误概率,对交换机的每一个交换端口同时设置一个BF表用于记录该端口数据不存在的情况。该添加操作由因假阳性导致所转发请求未能获取相应数据的反馈情况触发,也可采用周期性更新BF表的方式。为作区分,本文将周边缓存状态BF表记为BF1,将数据不存在状态BF表记为BF2。与使用计数BF并采用直接删除操作方式来处理反馈信息相比,本文方法的空间消耗更小,方便传输且传输方式更为灵活。同时,仅BF1匹配情况下才会再进行BF2判断,而且后续实验结果也表明这种两个BF表顺次匹配的设计未对转发效率造成影响。
本文通过修改POF软交换机代码的方式实现对BF表的构建。目前设置对周边一跳内节点的缓存状态进行维护,利用安装POF软交换机的主机的内存资源,在软交换机启动时,对每个交换端口维护两个BF表,且软交换机周期性发送通过缓存情况所生成的BF表以相互更新所维护的周边缓存状态。
对于各个交换端口所维护的BF表,需要根据多个BF表的结果汇总进行输出,而本文中首先是对多个BF表的查询结果进行聚合判断是否存有所校验的内容名称,其次才根据整体判定结果决定是否需要检索各个端口的具体状态查询结果。基于此,对每一交换端口采用两个二进制数组表征BF1与BF2表所维护的缓存状态,使用相同的哈希函数。将各端口两个二进制数组标识为BF1i和BF2i,其中i为端口号;哈希函数个数为k。优化的BF查询算法如下所示:
输入 各端口二进制数组BF1i、BF2i,内容名称name;
输出 存在内容名称端口数组。
步骤1 依据内容名称name哈希计算k个数据位置;
步骤2 依数据位置首先并行查询各端口BF1i,与运算获取二进制查询结果x1i;
步骤3 输出x1i,并继续查询BF2i操作获取查询结果x2i;
步骤4 {x11‖x12‖…‖x1i‖…}或运算汇总BF1i查询结果,若为0则跳出,若为1则继续步骤5;
步骤5 检索输出结果满足x1i=1且x2i=0的端口号,若端口数为0则跳出,若大于0则输出端口号列表由后续操作处理。
2.2 指令设计
为实现在数据面依据缓存状态快速转发的目标,在整体设计上需尽量简洁,因而不应对数据平面的流表匹配—执行指令这一处理流程作过多的调整。如前文所述,过于复杂的处理流程并不适合数据面快速转发的需求,因此,采用扩充POF指令的方式,即经流表匹配后执行扩充的POF指令,该指令直接利用交换机内所维护的缓存状态进行相关操作。
扩充POF指令所需要的功能包括对BF表的维护以及依据BF表状态进行转发。对于BF表的维护功能包括:BF表的整体升级更新、获取BF表、某一元素的插入、某一元素是否存在的判断等。最为核心的功能是依据BF表状态进行转发,即根据各端口所维护的BF表状态,将数据请求从相应的端口转发出去,这也是指令设计的重点。对各个端口BF表的查询可采用并行处理的方式以进一步降低顺次查询的时间开销,同时也对数据包转发的方式进行了优化。POF交换机中的转发指令会将数据内容以及metadata内容拷贝至转发缓存中再进行转发,但频繁的内存拷贝对于转发速度影响很大,而且若将查询结果再交由POF转发指令处理转发会带来更多的指令步骤。因此,直接在扩充POF指令中实现对数据包的转发,并采用直接将数据请求进行转发的操作以减小内存拷贝对转发速度的影响。
依据BF表状态进行转发这一指令功能的具体流程如图2所示:经指令type字段判断需将数据请求转发至所匹配端口,首先获取数据请求中的数据名称,然后并行查找各个端口的BF表。对于每个端口,首先查找BF1表,若无则输出结果至交换机metadata交由后续操作处理。若BF1判断为真则进一步匹配BF2,若存在则同样输出至交换机metadata。若BF2判断无则判定该端口方向存在该请求内容。并行处理后的汇总结果,可能包括多个端口号,即代表有多个端口方向存在该数据。此时,可按照具体场景需求,采用每个端口都群发或选择某端口单发的形式转发数据请求。同时,POF交换机的转发指令会将数据内容以及metadata内容拷贝至转发缓存中,再进行转发,而这里的转发流程不涉及对于数据请求的修改且转发无需metadata内容。为简化转发流程以进一步提升转发速率,将数据请求内容指针交由转发函数实现直接转发。

图2 数据请求转发功能指令流程
2.3 流程示例
如图3所示,以数据请求转发流程为例描述了本文方法在交换机端的执行方式。假定数据请求的数据为A,且数据A的名称存在于1端口对应BF1表中,同时BF2表中不存在数据A的名称,交换机内未缓存数据A;交换机内已缓存数据内容的查找亦通过交换机流表匹配的方式实现;假定BF表哈希函数个数k=3。
请求数据A的数据请求进入交换机后,经流表匹配判定为数据请求,跳转入缓存数据匹配流表。由于在交换机内未缓存数据A,无流表项与数据请求相匹配,即未能实现对相应内容名称的匹配并读取数据。缓存数据匹配流表对未匹配内容执行依周边节点缓存状态快速转发指令,即判定需要依据周边存储状态来转发数据请求,执行所扩充的POF指令。该指令依据数据A的名称哈希计算3个数据位置,各端口索引各自BF1i对应位置值,经与操作输出,则x11为1而其余端口输出为0。经或运算汇聚各端口x1i结果为1,判定继续检索各端口的最终输出结果。仅1端口对应满足x11=1且x21=0,即该指令查询BF表状态,1端口对应BF1表包含数据A名称且BF2不包含数据A名称,仅端口1方向存在相应数据内容。依据这一查询结果,将数据请求交由转发模块直接由1端口转发出去。

图3 依据周边缓存状态转发数据请求示例
3 性能分析
为验证将缓存状态保存在数据面对转发效率的提升,首先将本文方法与由控制器转发的方式进行对比;其次,为验证方法新指令未影响POF交换机的转发速率,与原有的转发指令进行对比验证;最后,对比了BF实现与流表实现的内存占用情况,以验证采用BF维护数据状态的方式有效节省了交换机端的空间开销。
3.1 实验设置
实验中使用三台服务器:一台作为控制器,一台安装本文方法扩展的POF软交换机,一台作为流量发生器。配置如下:2.10 GHz Intel E52620 CPU,64 GB DDR3内存,4个BCM5720 Gigabit网卡。如文献[14]所述,采用105个内容用于模拟一个应用场景是合适的,假定每个节点有高达0.1的存储比例,因而,BF表默认设置为:存储容量为10 000。目前IP应用通常可容忍约0.01的丢包率,类比于此,设置假阳性概率为0.01。发送数据采用80 KB大小的数据帧。控制器基于POX实现,并针对POF进行了相应的适配。
实验中,流量发生器向POF软交换机发送数据请求,周边节点缓存状态已预设在POF交换机内,设定仅有一个端口所维护缓存状态中包含数据请求的内容的名称。POF交换机将依据缓存状态转发数据请求。
3.2 与控制器转发对比实验
控制器转发方式即缓存状态仅保存在控制器中,交换机接收到数据请求后将其以packet-in消息形式发送到控制器,控制器依据所存储状态进行决策,并以packet-out消息形式下发由交换机转发数据请求。本实验通过与控制器转发方式对比验证将缓存状态保存在数据面进行转发的必要性。
如图4所示,控制器转发方式在输入速率为80 Kb/s时即达到瓶颈,其后随着输入速率的增大,输出速率基本保持恒定;而依据BF表转发方式在图中范围内可依数据包输入的速率转出数据。可见在较低的输入速率下,控制器转发方式已难以满足需求。这是因为交换机与控制器端的通信瓶颈、控制器端的处理开销以及交换机端对于packet-out处理的开销等诸多不利因素的影响。显然,控制器转发方式难以满足实际的需求。

图4 本文方法与控制器转发方式的对比
3.3 与直接无状态转发对比实验
为进一步验证所扩充的根据BF表状态转发数据请求的指令的转发效率,将该指令与POF原有的output转发指令以及基于计数BF实现转发数据请求的方式进行对比。基于计数BF方式即采用计数BF表以取代本文方案中的双BF表设计结构,并行查询后直接检索结果。如图5所示,当包输入速率较低时,基于双BF转发指令与output指令均可将输入报文以相应的速率从端口转发出去。当输入报文速率为105 Mb/s时,output指令转发速率达到最高值,之后随着输入速率的增加,转发效率逐渐降低;基于双BF转发指令在输入速率为111 Mb/s时转发速率达到最高值,之后随着输入速率的增加,转发效率下降,但仍略微高于output指令;而基于计数BF转发的方式在输入速率约在112 Mb/s时转发速率达到最高值,基于BF转发与基于计数BF转发方式曲线基本一致。
由实验结果可见,本文设计的基于双BF转发指令对于双BF查找操作在整个转发过程中开销较低,未对转发速率造成影响,因而能够以与output指令和基于计数BF转发方式基本一致的转发效率转发数据包;同时,由于对于转发流程的优化,将包内容直接转发,减少了内存拷贝,当输入速率较大时,基于双BF转发指令转发速率略高于output指令。在输入速率较大时,三种方式均出现转发速率降低的情况,这主要是受限于POF交换机整体设计以及服务器性能。
3.4 内存占用对比
BF表占用内存情况已在1.2节中描述。如2.1节中所述,若在POF交换机中采用流表项存储周边数据状态的方式,由3.3节结果可知,如不考虑匹配的额外开销问题,依据流表项匹配状态,并用原生output指令转发的方式可以达到与本文方法基本相近的转发效率,但存在内存占用较大的问题。BF表方式与流表项方式的内存占用情况如图6所示。此处的对比中流表项占用内存情况仅考虑流表项中hash所需比特位以及内容名称占用的内存。若内容数目为n,则hash所需比特位至少为lbn。由于内容名称长度为可变的,为方便对比,本文取常用的128 b。由图6可以看出,在较低的假阳性概率下,BF表内存占用情况明显优于流表项存储实现的方式,即使在设定0.1%假阳性概率下,所采用的两BF表结构占用内存也仅占流表项方式的约20%。
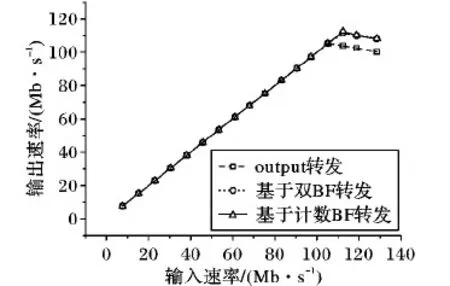
图5 本文方法与直接无状态转发的对比

图6 BF表方式与流表项方式的内存占用对比
4 结语
针对协同存储在数据面存储状态并依此快速转发数据的问题,本文基于POF设计了一种协同存储数据面快速转发方法,通过在数据面的交换机端维护BF表的方式,在节省数据面开销的前提下实现对存储状态的维护,并设计了扩充POF指令直接操作BF表和优化转发流程。实验结果表明本文方案相比基于控制器维护状态并转发的方式转发效率有明显提升,且略优于原有直接无状态转发指令,同时具有较低的内存空间开销。下一步的工作中,我们将考虑在实际应用场景如海云协同等环境下的部署问题,以及针对不同业务场景需求的进一步扩展与优化。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
西安航空学院学报(2021年1期)2021-07-24
科学家(2021年24期)2021-04-25
数码世界(2020年12期)2021-01-20
数码世界(2020年11期)2020-11-23
学校教育研究(2020年11期)2020-06-08
电子制作(2019年13期)2020-01-14
网络安全和信息化(2019年7期)2019-07-10
网络安全和信息化(2019年5期)2019-06-04
电子制作(2019年24期)2019-02-23
