
科学文献中参考文献影响力评估方法研究
2018-10-18 02:17顾进广张铭晖
小型微型计算机系统 2018年10期
张 瑜,顾进广,4,张铭晖,张 俊
1(武汉科技大学 计算机科学与技术学院,武汉 430065)
2(智能信息处理与实时工业系统湖北省重点实验室,武汉 430065)
3(深圳证券信息有限公司,广东 深圳 518028)
4(国家新闻广电出版总局富媒体数字出版内容组织与知识服务重点实验室,北京 100038)
1 引 言
对于科研人员而言,在日常研究工作中阅读大量的文献是必不可少的.当阅读一些具有影响力的文献时,研究人员可能需要通过这些文献的研究动机来深入理解这些文献.当研究人员想要选择新的研究方向时,他们需要查阅相关文献以及这些文献的参考文献.由于并非所有的参考文献都是非常重要的,有必要过滤出所需要的重要参考文献.通常,研究人员会选择寻找一些更具价值的参考文献,这些参考文献是引用文献学术思想的主要来源.但是,一篇文献中有许多参考文献,研究人员如何高效地在这些参考文献中找到最重要的参考文献呢?
当前,关于引用文献影响力评估的研究可以分为两类:(1)非监督方法.主要包括图模型,如由Dietz等[1]提出的引文影响模型(CIM).其它一些模型可以用来计算主题分布概率,如局部因子图模型[2],传承主题模型(ITM)[3],引文追踪话题(CTT)模型[4],成对约束玻尔兹曼器(PRBMs)[5]及概率生成图模型[6].(2)监督方法.Bethard等[7]通过使用一些特征来计算学习权重相似度来进行引文推荐,可以利用训练集学习启发性指导来评估影响力.这些方法旨在从不同的角度解决链路强度问题,使用监督方法的引文影响力评估方法采用启发式线索,可以避免陷入局部术语细节.此外,还有社交网络中影响力最大化研究方法[8,9],也可用于引用文献影响力评估.本文将考虑融合这几个方面的优点,以使用主题信息和文献自身的静态特征来评估引文影响力.
可将参考文献重要性评估问题设计成一个集成参考文献各种重要因素的文献数据集上的分类器.本文引入主题相似性将关键词相似性作为重要考虑因素,将引用计数作为文献的人气指数,期刊的影响力也可以用来评估不同期刊中的文献影响力.本文设计了一个文献分类器,使用带标签的逻辑回归模型评估这些特征的重要性权重,以反映参考文献对引用文献的影响程度;建立逻辑回归模型作为影响力评估模型;使用具有不同特征值的新文献实例模型来评估参考文献的重要程度.这对于研究人员以更高效的方式来获得有影响力的文献是非常有帮助的.
2 相关工作
现有的研究工作中有不少关于影响力评估的研究,如图模型和监督方法.潜在狄利克雷分配(LDA)模型[10]是一种生成概率模型,将引文集成到主题建模中[11].基于LDA的扩展变形可以用来提取文献的潜在主题,以建立引文和文献之间的关系模型.Tang等[4]提出了一种基于估计主题模型计算引文关系影响力的方法,通过考虑源文献和目标文献的主题分布以及主题-类别混合来计算引文的影响力.Dietz等[1]提出的引文影响模型(CIM)描述了引文行为的生成过程,被引用文献对引用文献的影响可以通过引文的统计信息进行评估.Qi等[3]提出了一种迭代的主题进化学习框架,利用LDA和引文网络,研究了一个新的继承主题模型.Hall等[12]将无监督主题建模应用于ACL文集,以分析主题的变化过程,并检查每个主题随时间变化的强度,展示了主体思想的变化过程.生成模型可用于对随机生成进行建模,这适用于文献的生成过程,并且可以仅使用文档里的词而不考虑每个词的含义来评估主题级别的影响.
Bethard等[7]提出的引用推荐检索模型是一种基于监督的引文关系分析方法,其特征包括相似术语、他引关系、相似主题和引用习惯,它们的权重可以通过SVM-MAP进行计算.这种方法利用文献自身的信息,反映了文献的研究动机,可以在引文影响评价中充分利用这些特征.
上述方法都是关于参考链接的评估,但其目的各不相同,如文献搜索,引文推荐和引文关系分类等.本文探索采用启发式方法来辅助引文影响评估.文献中存在一些重要的特征,例如文献之间的内容相似性,作者之间的共同作者关系,参考链接,引用计数,会议影响力,共同引用关系等,虽然这些特征不能被视为共同特征,但它们包含了影响文献引用动机的重要因素,可以有效地使用这些特征来检测文献之间的隐含关系.为此,本文设计了一个分类器来捕捉有影响力的参考文献,以帮助研究人员有效地获得有影响力的重要文献.
3 参考文献影响力评估特征选择
3.1 引文统计
科学文献形成了一个通过引文关系连接的文献研究网络[13].学术网络中的引文统计特征包括引文数、引文PageRank.常见符号D是整个语料库,l和r是文献,M是文献的数量.引文数是文献被引用的次数,用于表达文献的重要程度[7].文献1的引文数可以用公式(1)表示.
Citing(1)={1′∈D:1′cites1}
favg-citation-count(1)=log(|citing(1)|/yeardiff)
(1)
其中,yearcur表示当前年份,yearpub表示出版年份.引文数是从Libra copra下载的.使用平均引文数来反映每篇参考文献的长期影响.引文数特征由对数值归一化,以便保持在引文数缩放范围.
3.2 文献的相似性
为了更好地捕捉文献的主题,将主题的相似性作为扩展特征.文献1的主题向量用公式(2)表示.
topics(1)={probt1,probt2,…,probtK}
(2)
其中,probti是文献1的主题ti的推断概率;K是主题的数量.
借用文献之间Jensen-Shannon (JS) 差异作为文献相似性度量,它为每对分布的KL发散度之和的平均值,如公式(3)所示.
(3)
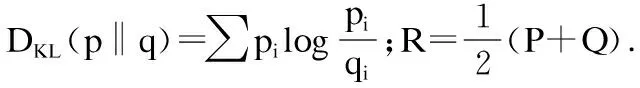

(4)
这种主题相似性度量是一种语义上的相似性,并没有考虑每个主题的术语特征.考虑引入文献的标题和摘要来度量文献的相似性.如公式(5)和公式(6)所示.
Title-similarity(r,l)=cosine(TF(r),TF(l))
(5)
Abstract-similarity(r,l)=cosine(TF-IDF(r),
TF-IDF(l))
(6)
利用相关性向量来计算关键词相似性,如公式(7)所示.
Keywords-Similarity(r,l)=
consine(Relevance(r),Relevance(l)
(7)
其中,Relevance(r)和Relevance(l)为文献r和l的相关性向量.
3.3 作者引文行为
文献作者的影响对参考文献的选择也是十分重要的.通过计算文献作者引用参考文献的总次数表示作者引文偏好的权重,用公式(8)表示.
(8)
其中,author_cited(l,ai)是作者ai被文献1引用的总次数,它是从语料库中统计出来的,U是文献1中的作者数量.
3.4 期刊影响力
在高级期刊中发表的文献比低级期刊更具影响力,可利用的期刊信息有出版物、引文和作者,用一种简单的方法来计算期刊的影响力,如公式(9)所示.
fconference(r)=log(Npubs+Ncites+Nauthors)
(9)
其中,Npubs是出版物的数量,Ncites是引文的数量,Nauthors是作者的数量,本文使用对数来表示三个值的权重.
4 影响评估模型
对参考文献影响进行评估的目的是为当前的研究选择出最有影响力的参考文献,这就好比使用一个过滤器来滤出非常重要的参考文献.过滤模型大致可分为两种类型:生成模型(如Naïve Bayes)和判别模型(如支持型向量机和逻辑回归(LR)).大量的分类测试表明,判别模型要优于生成模型.因此,本文使用逻辑回归模型(LR 模型)作为影响评估模型.
4.1 模型描述
使用逻辑回归模型可以训练每个特征的权重,并且可以根据这些特征来计算每篇参考文献属于非常重要类型的概率.可以用公式(14)来预测影响概率.
(10)
对参考文献是否为非常重要类型的分类通常有一个临界值,将该值用θ表示.如果影响概率大于θ,则评估的参考文献属于“重要”类型,否则属于“非常重要”的类型.通常情况下,θ可取值0.5,θ的最佳取值也可以根据文献数据集来确定.
接下来的问题是如何训练特征的权重.在训练影响过滤模型时,本文借助了梯度下降法[14],采用学习等级来控制在梯度方向上的跨度,其值通常取rate=0.02.
算法1.逻辑回归模型训练算法
begin
if(p>θ)
predict yj=important
else predict yj=very-important
if(yj=very-important)
end
用逻辑回归模型训练特征的权重后,可以利用概率度量作为影响评分.如果参考文献影响评分大于θ,则预测表明它为“重要”,否则为“非常重要”,然后,将预测的标签与原本的标签进行比较,可以得到“非常重要”类型数和“重要”类型数,以及非常重要类型错误分类数和重要类型错误分类数的静态特征,以此来评估模型的性能.
4.2 模型评估
为评估使用的影响评估模型,考虑到非常重要类型错误分类率(vimr)和重要类型错误分类率(imr),其中具有较低vimr和imr的分类器优于较高的.将影响评分与临界值θ进行比较可以确定分类类型,所以精度对本文的方法而言并不是一个好的指标.接收者操作特性(ROC)曲线分析可用于评估非常重要和重要的错误分类概率之间的平衡.(vimr,imr)的点集决定了ROC空间中的曲线.将ROC曲线下方面积记为AUC.为了得到vimr和imr之间可能的临界值,我们使用1-AUC 来测算随机“重要”类型消息得分比随机“非常重要”类型消息得分还低的错误概率.综上,本文的评估指标是vimr,imr,1-AUC以及ROC曲线上方面积的百分比.其中具有较低vimr,imr和1-AUC 的分类器要优于高的.
5 实验结果与分析
我们收集了关于计算机科学的两个学术语料库.一个是Arnetminer(现为AMiner)的文献,其中包含629814篇文献和超过632752个引用关系,删除了没有参考文献的文献.另一个是Libra上2011年5月之前的会议信息,其中分别包含177381个出版物,2770个会议和614587作者.使用两个学术语料库之间有交集且作者和会议信息完整的文献作为文献数据集.在预处理阶段,选择参考文献数量超过6篇的文献作为训练数据集,并把它们以结构化数据存储起来.为了训练LR模型,从1000篇文献中标记出6360篇参考文献作为训练集.将训练集中每篇参考文献的重要度进行数字化,用标签1和0分别标记“非常重要”和“重要”.利用训练后的LR模型,可以计算出参考文献的影响评分.
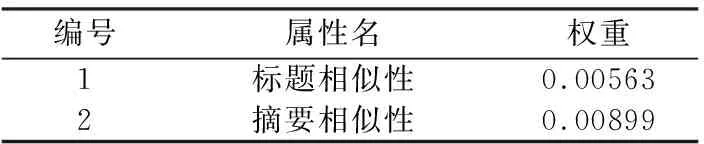
表1 基于LR模型的基线特征权重和等级Table 1 Baseline features weights and Rank according to LR model

表2 属性编号、属性名、特征权重和等级Table 2 Attributes number,name,features weights and Rank according to LR model
为了在添加上述特征后还能对结果进行合理的比较,使用标题和摘要相似性作为基线特征来训练LR模型,其中训练的权重如表1所示.
在LR模型中使用梯度下降法训练每个属性权重的方法已在4.1节中描述.表2给出了特征的绝对权重和等级.对于逻辑回归模型,由标记集训练的权重反映了每个特征的影响程度,绝对权重越高,特征的影响等级越高.
从表2可知,摘要相似性的权重最高.研究人员在选择参考文献时,他们会先通过阅读文献摘要作为第一步筛选.使用这些权重,在(vim%,im%)集上对接收者操作特性(ROC)曲线进行比较.由于临界值不是固定的,根据临界值θ的变化绘制了ROC曲线,如图1所示.

图1 使用带有基线特征(标题相似性和摘要相似性)和第3节中所有特征的逻辑回归模型绘制的ROC曲线Fig.1 ROC of logistic regression model using baseline features (title similarity and abstract similarity) and all the features mentioned in Section 3
如图1所示,具有所有特征的1-AUC (曲线上方的面积)小于仅具有基线特征的1-AUC.加入其他特征来促进分类器的辨别能力,这些特征对于参考文献影响评估是十分有用的.研究人员在选择参考文献时往往会忽略一些重要信息,可以在分析参考文献时充分使用这些特征,以得到更准确的结果.
6 结 语
在本文的研究中,使用辨别模型来训练一个分类器以区分有影响的参考文献,使用大量特征来评估参考文献的重要性.在特征集中通过梯度下降法训练LR模型后,得到每个特征的适当权重,然后使用该模型计算影响类型概率,以便在得分与临界值相比较时对参考文献进行评估.如实验结果所示,该模型的性能优于仅使用标题和摘要相似性的基准模型,这将是过滤参考文献的更好方法.
此外,本文方法尚有一些不足之处.我们的数据集不能得到作者、文献和期刊/会议的精确计数,因为它们在不断变化.在LR模型中,只使用非常重要和重要这两个标记,但是参考文献的评估可以有各种不同的粒度.如果能找到参考文献的鉴别划分策略,就能得到一个更合理的评价.另外,使用的语料库主要是计算机科学方面,如果条件允许,可以在更大的文献引用数据库上进行测试,以测试这些特征是否符合这里观察到的模式或能否揭示科学引文的新趋势.
猜你喜欢
河北画报(2020年8期)2020-10-27
国际比较文学(中英文)(2019年1期)2019-11-12
NBA特刊(2018年14期)2018-08-13
雪莲(2017年2期)2017-05-12
人大建设(2017年11期)2017-04-20
环球市场信息导报(2017年1期)2017-04-08
东方教育(2016年4期)2016-12-14
瞭望东方周刊(2015年12期)2015-04-14
人间(2015年21期)2015-03-11
中国校外教育(下旬)(2014年10期)2014-11-20
