
基于Paragraph Vector模型的科研热点发现方法
2018-10-24 07:46郭佳罗森林陈倩柔
电子设计工程 2018年20期
郭佳,罗森林,陈倩柔
(北京理工大学信息系统及安全对抗实验中心,北京100081)
随着互联网信息时代的到来,信息在各个领域呈现爆炸式快速增长的态势。在互联网上几乎可以找到任意所需的信息,尤其是互联网搜索引擎的出现,更是大幅提升了信息查找的过程;但由于信息过多,从这些海量信息中去除冗余,挖掘有价值的信息较为困难。同样对于科学研究者而言,情况也是类似的。科学研究者不仅需要时刻把握领域内研究内容的变化趋势,还需要具备快速了解并掌握一个新方法的能力。阅读相关领域的论文是科研工作者快速掌握知识的主要途径,然而由于每个领域均有大量已发表的论文。同时,新论文的发表也层出不穷。这使得科学研究者快速了解研究内容、跟进研究热点变得困难。缓解该问题有效、可行的方法是利用热点发现方法对一个领域随时间变化的研究热点做出检测与总结。
1 相关工作
科研热点发现是话题发现的一个分支。话题发现起源于话题检测与跟踪(Topic Detection and Tracking,TDT)[1]。近年来,国内外诸多学者针对科研热点话题做出了众多研究工作。税等[2]使用Single-Pass聚类算法进行话题识别,并对已聚类的报道进行周期分类,提高了聚类的准确类。为了取得更好的聚类效果,路等[3]利用一个两层的K-means和层次聚类算法,并结合LSI话题模型,检测并抽象出文本数据中的热点话题。随着研究的深入,文献[4-5]引入了模拟数学模型改进聚类算法提高了话题发现效果。Oladimeji[6]利用一种融合k-means聚类和神经网络的NED检测算法,通过k-means与神经网络的融合方法能提高事件的检测速率。宋[7]提出一种基于SOM聚类的话题发现方法,结合词向量模型抽取数据的特征和改进的SOM进行话题聚类。Daniel等[8]利用Labeled-LDA模型,将文本数据的话题标签应用于话题建模,并结合4S分类模型对话题进行细维度划分。Weng等[9]针对社交数据短小的问题,将同一用标签的数据整合成一个长文档,然后利用LDA进行主题挖掘。L Qiu[10]等提出LDA+K-means的聚类方法,通过LDA主题模型补充语义信息提高聚类效果。Chen[11]等人提出一种基于随机森林和图结构的OTD算法,提升语料语义信息的挖掘,比词袋模型表示的话题更优。EI-Kishky[13]利用关联算法快速得到短语集,结合短语袋主题模型挖掘主题-短语的分布信息,生成主题短语来表述话题。方等[14]利用K-means对文本聚类,然后通过LDA模型对每个类建模,并结合词频、词长和词跨度计算每个话题词的权重。
基于聚类的话题发现方法存在文本特征语义表达能力不深的缺点。同时,稀疏表示法在解决实际问题时经常会遇到维数灾难,且语义信息无法表示、无法揭示词之间的潜在联系等问题。本文针对以上问题,引入深度学习的Paragraph Vector(PV)模型表达文本特征。采用PV向量,缓解维数灾难问题,且挖掘词之间的关联属性,优化向量语义上的准确度。
2 科研热点发现方法
2.1 算法框架
本方法首先对文本集合提取正文,获得正文集合后进行句子清洗,去停用词后得到预处理结果。接着对预处理结果使用PV模型构建向量表示,得到文本的语义表示向量。然后对语义表示向量计算相似度,进行聚类分析得到研究主题。对主题热度排序时加入文献的引用信息,选择前N个主题作为研究热点,原理如图1所示。
2.2 引用信息提取
引用信息提取指基于文本数据的结构化特征获取文本的引用信息,即引用次数。例如,Radev等[15]发布了AAN(ACL Anthology Network)语料。ANN中包括论文ID、作者信息、发表年份、论文来源和论文被引用信息。ANN中记录如下:
C08-3004==>A00-1002
说明论文编号C08-3004的论文引用了ACL中另一篇编号为A00-1002的论文。利用这些信息可统计论文被引次数,及被引时间的变化趋势。
2.3 Paragraph Vector分析
Paragraph vector[16]模型是一种无监督的且不定长文本的连续分布式向量表示方法。PV模型的框架,如图3所示。每个段落对应一个向量,对应段落表示矩阵D中的一行。每一个词也对应一个唯一的向量,对应词表示矩阵W中的一行。段向量和词向量加权共同预测语境中的下一个单词。图3输入Paragraph ID 的段落向量,以及单词“the”、“cat”和“sat”的词向量,PV模型训练后可预测出下一个单词为“on”。PV模型的推断过程及参数,如式所示。

ω1,ω2,...,ωt+k表示训练语料中的单词,按词序排列。yi是单词ωi非标准化对数概率,计算方法如式(2)所示。
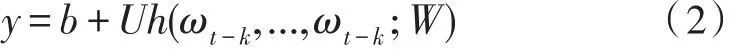
b,U是softmax函数中的参数,h由段落表示矩阵D和词表示矩阵W共同计算得出。

图2 PV模型框架
2.4 主题检测
本文采用余弦夹角定义两个向量之间的距离,余弦值越大代表两个文档之间越相似。向量dx={x1,x2...xn}和向量dy={y1,y2...yn}分别表示文档dx和dy,相似度计算公式如式(3)所示。

文中采用K-means聚类算法检测主题,该算法的优点是简单实用、时间复杂度较低适合大数据聚类,且适合高维度的文本聚类。
2.5 主题热度排序
主题热度与两方面因素有关:1)该主题下包含的文本数,数目越多说明研究者越多,该主题研究热度也越高;2)该主题下文本的平均被引次数,文本的平均被引次数越多说明文本的影响力越大,该研究主题越重要。根据主题内文本的数量和平均被引次数,主题热度的打分策略如式(4)所示。

式中:H(Ci)为主题热度,NCi为主题Ci的文本数量,表示主题Ci的平均被引次数,参数θ用于调整主题内文本数量与平均被引次数的权重。本文取θ=0.5。
3 科研热点发现方法对比试验
3.1 实验目的和数据源
为了验证本方法通过利用PV补充语义信息,能够提高话题发现的效果。本实验采用ANN语料库中ACL正刊会议集2012年收录的168篇会议论文作为实验数据。
3.2 评价方法
3.2.1 ARI方法
兰特指数(Adjusted Rand Index,ARI)计算方法如下。

RI如式(6),TP表示同一类的样本对被分到同一个簇的个数;TN表示不同类的样本对,被分到不同簇的个数;FP表示不同类的样本对,被分到同一个簇的个数;FN表示同一类的样本对,被分到不同簇的个数。
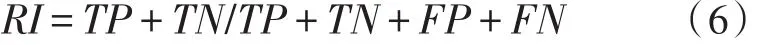
3.2.2 同质性,完整性和V-measure
同质性(homogeneity,h)是指,每个类簇只包含一个真实类别的样本。完整性(completeness,c)是指,所有属于同一个类别的样本均被划分到同一类簇中。同质性和完整性的调和平均值为V-measure。已知数据集的真实聚类结果为C,实验聚类结果为K。计算方法如下。
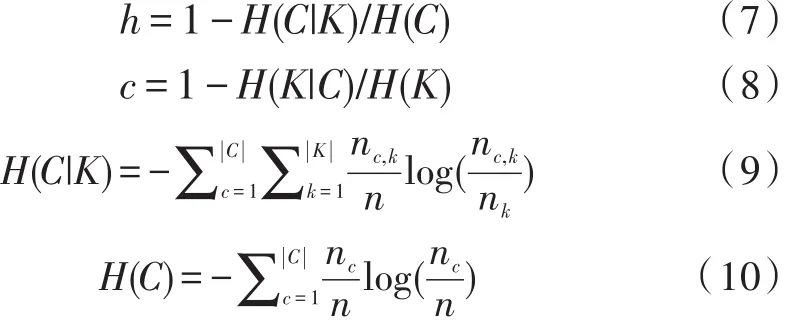
H(C|K)是已知聚类结果K,求真实类别标记的条件熵,C)是类别的熵[17],其中,nc和nk分别表示真实类别c和聚类类别k中样本的个数,nc,k表示从类别c被分配到类别k的样本个数,H(k|C)和H(K)使用相似的定义方法。
V-measure的计算方法,如式(11)所示。

h、c和v取值范围为[0,1],越接近1说明聚类效果越好。
3.3 实验结果和结论
3.3.1 向量长度和窗口长度选择实验
L表示PV模型生成向量的维度,W表示上下文词的个数。采用网格法调整参数,L从25~200步进为25调整,W从3~11步进为2调整。实验结果,如图3所示。
由图3可知,当L=100,W=3时,聚类结果最优。当L不变,W增大时,实验结果呈下降趋势。说明词与周围词的关联度较大,W过长会引入较大的噪声,导致结果下降。

图3 参数选择实验
3.3.2 聚类个数选择实验
在向量长度为100,窗口长度为3的条件下,调整聚类个数。聚类个数K从3开始,以2为步长到81为止,结果如图4所示。

图4 聚类个数实验
当K值在[13,49]范围内变动时,ARI的值在0.45左右略微浮动。一方面因本实验所用语料文本规模较小,主题划分粒度不宜过细;另一方面是因对于ARI评价方法而言,当聚类个数增多时[18],ARI的值有趋向于1的趋势。因此,本文K取13。
3.3.3 对比分析实验
本方法与2012年程辉提出的基于VSM的研究热点发现方法以及基于LDA的话题发现方法进行比较。
在聚类个数为13,聚类方法为K-means的条件下,得到实验结果如表1所示。

表1 对比实验结果
由表1可知,基于PV的热点发现方法相比基于LDA及VSM的方法,无论在ARI评价标准或是HCV评价标准下,效果均有优势,发现话题更为精准。原因在于:首先,本文利用PV模型优化向量语义上的准确度。VSM基于词性词频构建文档特征,不仅无法表示语义信息且还存在维数灾难的问题。LDA引入隐藏层,构建基于语义维度的文档表示向量,然而由于LDA基于词袋假设构建模型,忽略了词语上下文的信息,故语义表达能力仍有欠缺。PV低维空间表示法,缓解了维数灾难问题,通过挖掘词之间的关联属性,优化向量语义上的准确度,从而提高了话题发现的准确度。其次,本文将论文的被引信息作为论文语义特征的补充。论文的被引次数及被引趋势,说明论文的研究价值与意义,进一步提高了话题发现的准确率。
4 结束语
研究热点发现可以帮助科学研究者快速掌握当前研究热点、研究内容的变化趋势,这对研究工作起到了更好的参考指导作用。针对研究热点发现语义特征维数过高,且无法表示语义信息的问题,本文利用深度学习的PV模型表达文本特征。PV模型的低维空间表示法,不但缓解维数灾难问题,且还能挖掘词之间的关联属性,优化向量语义上的准确度。同时,本文挖掘文本的引用信息,将论文被引特征作为内容表示的补充,从而提高了话题发现的准确度,并降低了漏检率。
猜你喜欢
小学生学习指导(低年级)(2021年9期)2021-10-14
开放教育研究(2020年2期)2020-03-31
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
小学生学习指导(低年级)(2019年9期)2019-09-25
小学生学习指导(低年级)(2018年9期)2018-09-26
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
现代语文(2016年21期)2016-05-25
电子设计工程(2015年6期)2015-02-27
大连民族大学学报(2015年2期)2015-02-27
