
基于特征的藏文音节识别算法
2018-10-24 07:46张日培姜占才
电子设计工程 2018年20期
张日培,姜占才
(青海师范大学计算机学院,青海西宁810008)
藏文是我国少数民族文字之一,藏族是应用藏文的主体民族,藏文文语转换系统的研究与建立对繁荣和发展藏族文化有着重大意义。
经过众多专家学者的多年努力,主流语种和部分少数民族语种文语转换系统的研究取得了丰硕成果[1-7]。但现在仍然没有一套完整实用的藏文文语转换系统面世。通过对主流语言文语转换系统成果的分析,发现构建藏文的文语转换系统必需要解决藏文词语的分词识别问题。关于这一问题的研究,文献[8]提出通过提取特征的方法对藏文进行分词识别;此之后的研究者们在藏文的特征提取方法上提出有益的见解、取得了一定的成绩[9-11]。通过对众多成果的归纳,目前可用于藏文识别的藏文特征主要有:藏文字符投影特征,笔画方向特征,笔画结构特征,小波能量分布特征[12-14]。
以上方法虽均可作为识别藏文字符的特征,但特征提取的计算过程相对繁琐,对长篇幅藏文的识别效率低,不能达到文语转换系统的效率要求。本文提出的藏文字符和音节的特征提取算法简单易行,能够达到让计算机先识“偏旁”(即藏文字符)再认“字”(即藏文音节),然后以“字”为基元识别整篇藏文的目的,为藏文文语转换系统的开发奠定基础。
1 识别算法的设计
1.1 基字位置判定
在现代藏文文法里,除符合现代藏文文法规律的藏文音节,还有少数特殊的藏文音节无法用现代藏文文法判断藏文基字位置[16]。
本文主要目的是为藏文文语转换系统提供藏文字符及音节识别,所以本文对所有藏文音节中基字位置统一做如下规律的基字位置判定。
1)单字音节基字位置判定:因为音节之中只有一个字符,所以基字位置就是当前字符位。
2)双字音节基字位置判定:首先判断第一个字符是否为前加字藏文字符,若是则确定基字位置为第二个字符;若不是则基字位置在第一个字符位。
3)三字音节基字位置判定:首先判断最后一个字符是否为又后加字如果不是则基字位置即为第二个字符位,如果是则基字位为第一个字符位。
4)四字音节基字位置判定:若为四字音节,则基字位置必为第二个字符位。
1.2 藏文文本的预处理
1.1.1 文本规范化
根据藏文的文字特点对不同字体不同格式的藏文文本转化为同一格式,方便之后对文本图像中藏文音节的切分与识别,提高系统的计算效率。
规范化处理后的藏文具体格式为:班智达输入法,字体为BZDHT四号字半紧缩粗体,操作系统为WIN7,文本原文件为左侧对齐TXT文档中光标选中的全蓝部分。
1.1.2 图像二值化
为了提高之后的切分与识别的计算效率,需要将规范化后大小为m×n的文本图像进行二值化处理。其核心方法为对图片像素灰度矩阵A进行处理。使其大于某一阈值P的像素xij为黑色(0)或白色(255)。

根据不同的研究需要,确定二值化的阈值p的方法有多种,这里介绍3种方法:第一种为经验法,即根据经验设定一个阈值进行二值化;第二种是像素平均值法,即求出整幅图像的像素平均值并将其作为阈值;第3种是像素直方图法,即选择图像像素分布直方图的两个最高峰,然后选两个最高峰之间的峰谷最低处的像素值作为阈值。
由于首先对藏文文本图像做过了归一化处理,并且为了更明显的突出图像中的藏文文本结构,所以本文采用了经验值法。即将由经验得出的阈值P=200直接赋予算法中。
1.1.3 文本行处理
对文本图像二值化之后,为方便之后的音节切分,将文本进行行处理,方法是将多行文本转化为单行文本。将文本图像像素矩阵做水平投影计算,部分文本图像与水平投影结果如图1所示。

图1 文本图像与水平投影结果
由图1得,每两行中间都有一行0像素作为分割。规范化之后的文本图像相邻的两行0像素分割线的高度为39,所以输入的文本图像高度为39的整数倍。对二值化之后的文本图像像素矩阵以39个像素为一行文本图像的高度由上至下依次剪切,然后首尾相接,即可实现图像矩阵的行变换。

经过此变换之后,像素矩阵A可以分为k个39×n的像素子矩阵Ak。因为在TXT文本中藏文文本左侧对齐但是右侧不一定对齐,所以会造成截图时右侧部分有无效的白色像素,为方便之后计算,在行变换的同时检测是否有无效的白色像素,如果有则执行删除操作。
对Ai进行列投影计算得到Si=[ ]s1s2…sn,从后向前依次检查sn的值是否为0,直到为0的sn出现并且计算此时Si的长度t,然后以值为长度截取Ai,得到新的单行像素矩阵Bi,最后执行首尾拼接操作。
令行拼接之后的像素矩阵为B则:

此时B矩阵即为预处理之后的文本图像像素矩阵。
1.3 特征的选择与提取
1.3.1 特征的选择
在模式识别中特征选择的评价标准大致可分为4种[17]:基于类内间距离的可分性、基于概率分布的可分性、基于熵的可分性、统计检验的可分性。在文本识别领域已经提出的可以选取的特征有:藏文字符投影特征,笔画方向特征,笔画结构特征,小波能量分布特征等。
分析以上方法可知选取藏文字符特征的标准可概括为:选取的特征可以准确识别每个藏文字符;选取的特征维数尽量低;特征的计算方法简单易行。
本文提出一种对图像矩阵的单向投影进行非线性变换提取特征参数的方法。
1.3.2 藏文字符特征参数提取
单个藏文字符文本图像在经过预处理后可得到一幅二值图,其二值图像素矩阵为0-1矩阵A,A矩阵尺寸为39行m列。计算矩阵A的列投影向量S,则S中的元素sj与A中元素xij计算关系如下:

然后对S中的元素sj做非线性变换,做此变换的目的在于区分字符在不同位置的列投影强度。即对S中的元素sj有如下非线性变换:

最后计算对像素矩阵列投影向量S变换后所提取的特征参数T’:

则根据式(3)(4)(5)可以得出选取的特征参数T’与藏文字符的文本图像像素矩阵A中的元素xij的关系为:

1.4 字符特征值
由式(6)可知,经过提取后的特征参数,藏文字符的图像矩阵可以变换为一个存在小数位的特征参数。若用字符特征参数直接进行识别运算会导致识别算法的复杂度上升和计算机存储空间的浪费。所以本文为方便计算机识别和存储对提取出来的特征参数T’进行如下变换:

即:T为特征参数T’得出的字符特征值。为了构建音节的特征向量统一以四位数规范特征值。30个辅音字母对应的特征值见表1。

表1 藏文字符与特征值对应表
特征提取算法以字符为基本单位,所以具有上加字或者下加字或者上下加字的基字算作一个基本单位,在提取特征时进行整体特征提取。由于篇幅关系,在表1中没有给出带有上加字或者下加字的基字对应的特征值。由表1可知,藏文全部30个辅音字符的特征值都是唯一的,因此,此特征值可识别藏文字符。
1.5 音节切分
1.5.1 音节内字符与音节符的特征值计算
由前文可知已经进行预处理的文本图像矩阵为B,对B矩阵进行列投影计算后得到列投影向量B’。B’中的元素分为两类,一类为0元素另一类为非0元素,在列投影计算过程中如果字符没有任何部分在此列当中,则该列投影的结果即为0。由此可知只要记录所有前边的元素不为0的0元素的位置,就可以确定文本中各个字符的列投影区间。列投影示意图如图2所示。
每一个投影相对集中的区域就是字符区域或者音节符区域,将各个区域划分出后分别利用式(6)求各个字符特征参数,再计算其特征值。
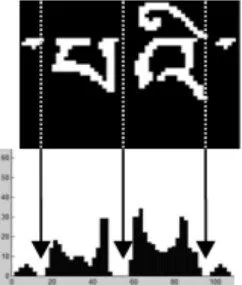
图2 像素矩阵列投影示意图
1.5.2 音节切分
由藏文文本的书写规范可知,藏文文本中每一个藏文音节都有音节符作为标记。只要识别出一篇文章音节符的位置,就可以根据音节符位置切分出整篇文章的各个音节。
藏文音节切分的具体步骤:将多行文本转化为单行文本;对单行文本的图像矩阵进行列投影运算;识别并且分割出字符或者音节符所在区域;对每一个有效区域进行特征值计算;根据特征值识别出音节符所在位置;根据音节符所在位置切分音节。
1.6 音节特征向量的提取
根据前文所述藏文文法和藏文结构特征,选择一个四维向量e=[e1e2e3e4]作为一个藏文音节特征向量。ei为组成此音节的字符特征值。音节特征向量中的各个元素e1、e2、e3、e4分别对应一个藏文音节的前加字、基字、后加字、又后加字的特征值。对于单字音节、二字音节、三字音节这些结构不完全的音节缺少的位置对应的特征值为‘0000’。
现代藏文文法中四字音节的又后加字是固定字符,所以为节省存储空间可令又后加字的特征值为1,即e4=1;若无又后加字则令e4=0。再将得到的音节特征向量做字符串处理,即将特征向量e转化成字符串E储存在计算机中。最后得到的音节特征向量为1*13的字符串矩阵,即13维向量。
1.7 音节识别
1.7.1 音节特征库的建立
首先找出藏文拼写无误的训练文本,训练文本图像经过预处理之后切分音节,分别计算各个音节的特征向量e再由特征向量计算音节特征字符串E,对得到的众多音节特征字符串E进行筛选,使得筛选过后的特征字符串无重复,以此建立单列的藏文音节特征库。
1.7.2 音节识别
音节的特征向量构成了音节的模式,要识别一个音节是藏文全部5300余个音节中的哪一个,即要识别该模式,必须依据一定的准则。为使识别过程简单、准确,选择均方误差最小准则,即欧氏距离最小准则。
设x是待识别音节的模式,维数为k(k=13),y为特征向量库中与x同维的模式,则定义它们之间的均方误差为欧氏距离,即:

yn是全部y中的第n行,n是行号,n=1、2、3……;yni是特征库中第n行第i个分量。只要求出x与全部y的找到则x就被识别成yn,而yn用其在特征向量库中的地址n给出。此法即为查表识别法。
1.8 识别算法的完整流程
识别算法流程如图3所示。
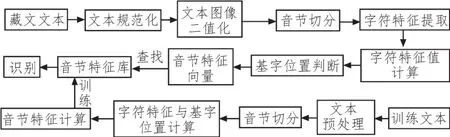
图3 识别算法流程图
2 算法仿真实验
2.1 实验方案
音节识别仿真实验必须建立在音节特征向量库的基础上,为此要建立藏文音节特征向量库。
第一部分,预处理仿真实验,查看预处理效果;
第二部分,音节特征向量提取,建立音节特征向量库。包含二值化、音节切分、特征提取、基字判断;
第三部分,音节识别仿真实验。
2.2 实验材料
实验用的藏文文本采用百度文库中的藏文作文,字体为作文作者随机选用字体。文本内容为藏文常用语句,主要有叙事、抒情、人文景观等。将藏文文本word形式下载到WIN7操作系统的电脑中,首先进行文本规范化,即将其复制粘贴进入TXT文档,调整字体为BZDHT四号字体,分辨率为1920×1080。然后进行截图采样。此种文本每一个音节都为有效音节,不存在书写错误,文本结尾以句段符结束。选择文本如图4所示。
2.3 实验程序及步骤
2.3.1 实验程序
根据文中提出的算法思想利用MATLAB语言对
算法进行编程并将算法中预处理部分和识别部分分别以文件名PTT.m与RGT.m存盘。测试程序对藏文文本图像二值化、计算藏文字符特征值、藏文音节切分、藏文音节特征值以及特征字符串的计算识别部分做了原始程序设计,更有利于在其他语言环境里进行测试和应用。

图4 藏文文本样本
2.3.2 实验内容
使用文中提出的算法实验内容如下:对选定的藏文文本样本进行样本规范化;对实验样本进行二值化处理;对实验样本进行行处理,使多行文本转化为单行文本;切分藏文音节;判断基字位置并计算音节特征字符串;用训练文本样本建立音节特征库;查表识别;
2.4 实验结果及分析
2.4.1 预处理算法实验结果
对选定样本进行预处理算法测试;
文本图像二值化、行变换和音节切分的实验结果分别如图5、图6、图7所示。

图5 藏文文本二值化图像

图6 藏文文本行变换处理部分结果图像
由图5可知对图4所示的文本经预处理和二值化处理得到预期的结果,即确定的字体字号和二值化结果。图中白色为像素‘1’,黑色部分为像素‘0’,由于背景处灰度值为‘0’故背景和‘0’像素处都为黑色。

图7 藏文文本音节切分结果图像
由图6可知,行变换后已将图5所示文本图像转化为单行的二值化图像,由图7可知,切分程序对图5中的文本实现了准确的音节切分。
2.4.2 音节特征字符串提取算法实验结果


图4的实验样本共有72个藏文音节,对每一音节逐一提取特征向量,其中包含音节内字符特征提取、音节基字位置判断、音节特征向量提取和字符串处理,得出了与各音节对应的特征字符串。
2.4.3 音节识别算法实验结果
为方便对照,表2中给出音节特征库部分数据:
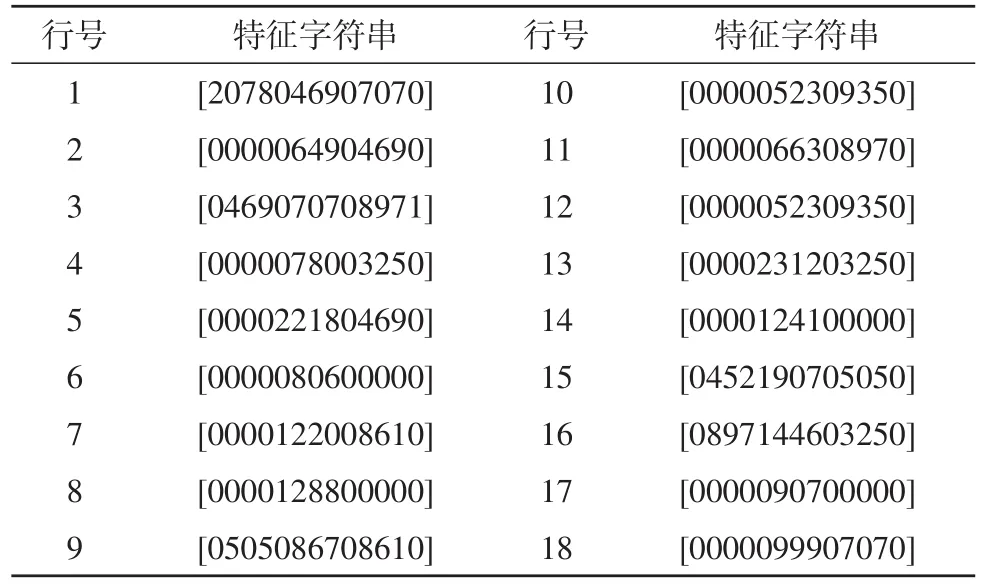
表2 部分音节特征库
由于篇幅关系,表3只给出了测试文本前10个藏文音节的查表识别结果:

表3 测试文本前十个藏文音节识别结果
由表3可知,依据均方误差最小准则(欧氏距离最小准则)的查表识别的识别结果是非常准确的,由此可以推断,只要音节特征向量库数据充分,即库内包含藏文全部5300余个音节的特征向量,就能实现藏文音节的准确识别。
3 结束语
文中提出一种基于音节特征的藏文音节识别算法。该算法主要包含音节特征向量的构建和对音节特征向量库进行查表识别两部分。音节特征向量的选择和提取建立在模式识别的理论基础上,从理论上保证了对所有藏文音节的高度可分性,并且计算过程简单易行。音节特征向量库的建立表示,只要向量库内数据充分就可以实现藏文全部5300余个音节的准确识别。经仿真实验验证该算法在计算速度和识别精度等方面均能达到实际应用的要求,为藏文文语转换系统的研究与开发奠定了良好的基础。
猜你喜欢
布达拉(2020年3期)2020-04-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
快乐作文(1.2年级)(2019年9期)2019-09-10
数字通信世界(2019年3期)2019-04-19
西夏学(2019年1期)2019-02-10
少儿美术(快乐历史地理)(2018年7期)2018-11-16
西藏大学学报(自然科学版)(2016年1期)2016-11-15
新闻传播(2016年17期)2016-07-19
中国音乐教育(2014年11期)2014-05-18
