
基于YOLO网络模型的异常行为检测方法研究
2018-10-24 07:46刘雪奇孙胜利
电子设计工程 2018年20期
刘雪奇 ,孙胜利
(1.中国科学院上海技术物理研究所上海200083;2.中国科学院大学北京100049;3.上海科技大学上海201210;4.中国科学院红外探测与成像技术重点实验室上海200083)
与传统的人工监控相比,智能视频监控可有效地降低误检和漏检概率,但目前监控视频中对各种异常的排查和报警大多依赖于人工,智能化的人体异常行为检测技术还处于发展中[1]。同时由于监控中人体和背景的复杂多样,对于特定场景下的检测就变的尤为困难。
对于某一特定监控场景,涉及到的人体异常行为通常较复杂,包括目标远近大小、重叠遮挡,背景纷乱复杂等[2]。这些都会对异常行为的检测产生很大影响,通常采用的方法是先将目标通过轮廓信息从视频序列中分割出来,然后进行特征提取,将提取到的特征与标准异常行为样本进行比对,最后利用分类器判断是否为异常行为[3];包括基于区域光流能量的检测方法[4]也是先对目标进行提取然后作分析。然而对于特定场景下,人体异常行为存在复杂多样、较难明确定义的问题,对此,一种简单的解决方式是将人体行为分为两类,忽略中间的过渡行为分为正常行为和异常行为。因为对于如实验室这样的特定场景,异常行为识别的需求可能只是是否穿戴工作服和工作帽这类简单的分类问题,所以分为两类可以很好的解决异常行为定义的问题。
传统智能视频分析技术由于采用人工选择特征,存在准确率低、浅层学习无法解析大数据等问题,而深度学习可以很好地克服这些问题,使视频分析过程中识别准确率更高、鲁棒性更好、识别种类更丰富[5]。本文将深度学习应用到监控中的人体异常行为检测,通过将复杂的异常行为输入到深度神经网络YOLO中进行自动特征提取和分类,将目标提取这一步交给神经网络,与之后的目标分类同时放到一个网络中,利用神经网络的深层次特征提取、高精度检测分类特性,可以将定义的异常行为准确的检测出来,实现从输入数据到输出检测结果的端到端的异常行为检测。通过GPU对检测过程进行加速,可以实现对监控视频的实时检测。
1 方法描述
文中选取了实验室监控场景进行相关的实验研究工作,具体的方法流程如图1所示。

图1 实验方法流程图
首先要获得监控场景的数据视频,通过帧截取图像、筛选;然后根据需求对异常行为的定义用LabelImg软件进行标定,此处标定的标签不是为了目标提取,而是直接标定为是否异常的两类,从而让目标提取和分类都交给网络去做,获得网络训练和测试的图像数据;参考YOLO的网络结构,将训练数据输入到YOLO网络中进行训练,从而直接训练出可以对输入图像或视频数据进行判断是否存在异常行为的网络模型。
1.1 数据处理
实验所采用的数据是实验室上网工作室中的监控数据视频,对于不规范上网的异常行为进行检测。在输入网络进行训练之前,数据需要进行一系列处理,包括视频的帧截取,图像筛选,标签标定。实际工作中用到的处理软件有Smart Player和LabelImg,Smart Player软件用来将视频数据进行转换和截取图像;LabelImg软件用来标定图像标签。
其中图像的标签标定涉及到对异常行为的定义,由于异常行为多样,较难泛化为一类或两类,因此实验中将除了正常的上网行为动作以外的其他行为都定义为异常行为。例如除了正常行走和端坐,其他包括弯腰、下蹲、伸展肢体、低头玩手机等行为都定义为异常行为。实验中标签分为两类:normal和abnormal;一共标定了1146张图像数据,1000张用作训练数据,其余的作为测试数据。
1.2 采用的网络结构
YOLO是一种新的目标检测方法[6],由Joseph Redmon[7]等人提出,这种方法的突出优势在于目标检测速度很快,同时又能保持较高的识别准确率,而且背景误检率低。其主要思路是将目标检测问题看作一个回归问题,只采用单个神经网络来回归从整张图的输入到目标边界和类别概率的输出,实现端到端的直接预测,即端到端的目标检测。本文借鉴这一回归思想,将目标检测网络结构YOLO应用到分类问题,将目标区域的类别作为最终结果,把异常行为的检测当做回归问题来解决。此外,YOLO的检测速度非常快,可以达到45帧/s的实时检测。
从 R-CNN 网 络[8]、Fast R-CNN 网 络[9]到 Faster R-CNN网络[10]采用的思路都是proposal+分类(proposal提供目标位置信息,分类提供类别信息)[11-13],在VOC2007数据集上mAP能达到73.2%,精度已经很高,但是识别速度还不够快。YOLO采用了更为直接的思路:将整张图作为网络的输入,直接在输出层回归bounding box(识别框,记作bbox)的位置和bounding box所属的类别,从而实现把目标识别当作回归问题来解决。基于这种回归思想,本文将异常行为的检测也作为回归问题,将整张图作为输入,检测出标定有是否为异常行为的bbox的图像作为输出。
YOLO借鉴了Google-Net分类网络结构,有24个卷积层,2个全链接层,开始的卷积层用来提取图像特征,全连接层用来预测输出概率。作者还修改训练了YOLO的快速版本(Fast YOLO),Fast YOLO模型卷积层和卷积核相对较少,它只有9个卷积层和2个全连接层,最终输出为 7×7×(5×2+20)的张量(因为有20类)[7]。这样的网络结构对于人体行为特征的提取和对是否异常的分类同样适用,对于实验中的两类标签,输出就是7×7×(5×2+2)的张量。
1.3 模型训练

图2 实验训练过程的基本原理图
实验网络训练中的具体流程如下:
1)将处理过的图像进行resize处理,调整图像尺寸为448×448作为整个神经网络的输入。
2)通过运行神经网络得到一些bbox坐标、bbox中包含的人体目标(Object)的置信度和类别概率3种信息:
将输入的一幅图像分成S×S个网格,如图2虚框内将图像分成7×7个网格,当某Object的中心落在这个网格中,那么这个网格就负责预测这个Object。
每个网格都要预测一个类别信息记为C类,那么对于S×S个网格,每个网格既要预测B个bbox,同时还要预测C个类别,所以输出就是 S×S×(5×B+C)的一个张量,对应图2中输出的张量就是7×7×(5×2+2)。
每个网格要预测B个bbox(图2中为2个),而每个bbox又要预测x,y,w,h和confidence共5个值。其中x,y是bbox中心位置的坐标,并且其值被归一化到[0,1];w,h是bbox的宽度和高度,同样归一化到[0,1];每个bbox除了要回归自身的位置之外,还要附带预测一个confidence值。这个confidence代表了所预测的bbox中含有Object的置信度和这个bbox预测的有多准两种信息,计算方式如下:
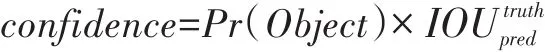
其中如果有Object落在一个网格里,等式右边第一项取1,否则取0。第二项是预测的bbox和实际的标签框之间的IOU值[7]。
3)在测试的时候,将每个网格预测的类别信息和bbox预测的confidence信息相乘,就得到每个bbox的具体类别置信分数:

最后通过设置阈值,滤掉得分低的bbox,对保留的bbox进行非极大值抑制处理,就得到最终的检测结果。
图2为实验训练过程的基本原理图,区别于传统异常行为检测方法先进行目标识别然后进行分类,进而对异常行为进行检测,本文直接将两个步骤都交给YOLO网络去做,从而实现了输入一张图像直接输出一张经过网络预测有检测结果的图像,即端到端的检测过程。而通过GPU的加速,对于输入的视频流可以实时的显示异常行为的检测框。
1.4 实验条件
硬件条件:DELL PowerEdge T630服务器(32G内存);两个CPU-E5-2620 v4;4个GTX1080Ti;
软件条件:Ubuntu14.04系统;CUDA 8.0;Python 2.7.6;OpenCV 2.4.13。
2 实验结果及分析
2.1 训练及测试结果
YOLO使用均方和误差作为loss函数来优化模型参数,即网络输出的 S×S×(5×B+C)维向量与真实图像的对应S×S×(5×B+C)维向量的均方和误差。实验中训练的网络的loss变化情况如图3所示,可以看到随着batches(训练批次)的增加,average loss(平均损失)在不断减小,逐渐趋于0,即整个网络结果趋于收敛。

图3 训练网络的平均损失变化
文中在4个GTX1080Ti显卡加速的实验条件下,对网络进行训练,最终获得网络权重文件,进而对图像和视频数据进行测试。实验中采用了1000张标定图像作为训练图像数据,146张作为测试数据,同时也对YOLO网络结构的简化版Fast YOLO和升级版YOLOv2[14]进行了训练和测试,部分图像测试对比结果如图4所示。图中3行图像分别对应Fast YOLO、YOLO和YOLOv2的检测结果。实验中红框的标签是normal,即正常行为;绿框的标签是abnormal,即异常行为。图4中第1列图中为红框,第2列、第3列为绿框,第4列中,左边为绿框,右边为红框,从第1、2列能明显的看出YOLO和YOLOv2网络模型框出的检测边界更准确。同时结果也充分说明了,主要用作目标检测的YOLO网络结构对于直接解决人体异常行为这种细分的分类问题同样适用。

图4 Fast YOLO、YOLO和YOLOv2检测结果对比图
2.2 评价与分析
文中采用了 IOU[15-16]、召回率(Recall)和精确率(Precision)[17]3个评价指标来对实验结果进行评价。
在目标检测的评价体系中,有一个检测评价函数叫做intersection-over-union(IOU),在实验中简单来讲就是模型产生的目标窗口和原来标记窗口的交叠率。即检测边框与真实边框(Ground Truth)的交集比上它们的并集,即为检测的准确率IOU:

召回率和精确度则采用如下方式计算:

TP——True Positive(真正,TP)被模型预测为正的正样本,可以称作判断为真的正确率;
FP——False Positive(假正,FP)被模型预测为正的负样本,可以称作误报率;
FN——False Negative(假负 ,FN)被模型预测为负的正样本,可以称作漏报率。

表1 3种网络结构检测结果对比
表1中列出了Fast YOLO、YOLO和YOLOv23种网络结构的检测对比结果。可以看出,简化版本的Fast YOLO网络,各项指标都最低,因为网络结构相对简化,在牺牲了检测精度的情况下,检测速度相对于其他两种要稍快些。而从IOU参数来看,其他两种网络结构比简化版本有很大提高,所以相对应图4中的检测框也能更准确的框定检测目标。YOLO和YOLOv2两种网络模型召回率接近100%,精确率可以达到96%以上。此外,在本文实验采用显卡GTX 1080Ti加速的条件下,对于视频流的检测速度可以达到30FPS左右。

图5 Precision-Recall(P-R)曲线图

图6 YOLO模型P-R曲线细节图
通过调整阈值可以让网络检测出更多结果(检测框),进而改变准确率或召回率的值,而评估一个分类器的性能,比较好的方法就是:观察当阈值变化时,Precision与Recall值的变化情况。如果一个分类器的性能比较好,那么它应该有如下的表现:让Recall值增长的同时保持Precision的值在一个很高的水平。从图5中可以看到,Fast YOLO网络模型的P-R曲线随着Recall值增长,Precision的值呈缓慢下降趋势,直到接近90%的召回率时下降为0;而YOLO网络模型当Recall值增长的时候,从图6可以看出,Precision的值一直处于96%以上;YOLOv2网络模型的P-R曲线跟YOLO网络模型的曲线很接近,没有在图中画出,精确率一直处于97%以上。因此,训练出的网络模型分类器可以很好地对异常行为进行检测。
3 结束语
本文通过对特定监控场景下对异常行为的定义需求标定数据,基于YOLO网络模型将标定的异常行为数据直接输入网络中进行训练,不将目标检测作为输出而直接得到是否异常的分类结果,从而让网络自动提取特征并分类,实现端到端的检测系统。最终实验结果表明这种方法可以很好地检测出监控视频中复杂的人体异常行为,并能够达到较高的检测精度。此外,这种方法可以迁移到不同监控场景,针对于特定场景、特定需求,可以达到很好地检测效果,对于满足不同行业的个性化需求方面具有重要意义。
猜你喜欢
中学生数理化·七年级数学人教版(2022年10期)2022-11-11
汽车维修与保养(2020年11期)2020-06-09
数学年刊A辑(中文版)(2019年3期)2019-10-08
北京航空航天大学学报(2017年6期)2017-11-23
中国惯性技术学报(2017年1期)2017-06-09
光学精密工程(2016年3期)2016-11-07
浙江大学学报(工学版)(2016年10期)2016-06-05
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
管理现代化(2016年3期)2016-02-06
管理现代化(2016年3期)2016-02-06
