
基于行为相似度的空调操作实时推荐
2018-10-31 05:31樊其锋黑继伟翟浩良
家电科技 2018年10期
樊其锋 黑继伟 翟浩良
广东美的制冷设备有限公司 广东佛山 528000
1 引言
近几年,家电行业的发展风起云涌,物联网已经成为该行业的重要组成部分。随着互联网的普及和硬件成本的压缩,以人为本,以服务为核心的互联网+,将逐渐成为该行业未来的发展趋势,同时,也给家电行业带来了挑战。因此,研究用户空调使用行为,为用户提供空调使用操作的推荐服务,具有非常重要的意义。但是,用户特征具有多样性,例如:年龄、阶层、体质、地理位置、环境等,对空调操作推荐具有较大的影响,且影响因子不同。本文研究依托大数据提取用户行为特征,基于行为相似度,为家电操作进行智能推荐,一方面,可以使空调使用更加智能,另一方面,可以提升用户使用黏度,将会促进家电行业智能度的再一次飞跃。
2 相关工作
空调行为推荐,是指为用户推荐空调操作的行为。对于用户来说,可以让空调的使用具有趣味性,更加便捷和智能;对于空调厂家来说,可以提升用户体验,增强用户黏性,提高销量。目前,空调行为推荐,主要分为传统的用户研究和大数据智能推荐。传统的用户研究,多以抽样设计的方式进行。其中,入户访谈、问卷法、焦点小组是使用较多的方式。大数据智能推荐,是基于海量数据和机器学习模型的推荐方法,在空调使用中为用户提供智能化的行为推荐服务。
智能推荐中比较关键的算法是相似度计算,有用户与用户之间的相似度计算,也有内容与内容之间的相似度计算。基于余弦(Cosine-based)的相似度计算:通过计算两个向量之间的夹角余弦值来计算操作之间的相似性。欧式距离:欧氏距离是最常用的距离计算公式,衡量的是多维空间中各个点之间的绝对距离,当数据很稠密并且连续时,这是一种很好的计算方式。其他相似度计算方法还包括曼哈顿距离、明可夫斯基距离、Jaccard系数等。
智能推荐的模型和算法主要分为基于内容的推荐和基于用户的推荐,推荐方法主要包括KNN、协同过滤、关联规则等。
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法。该方法的思路是:如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居),这K个实例的多数属于某个类,就把该输入实例分类到这个类中。该算法在分类时有个主要的不足是,当样本不平衡时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。
协同过滤(Collaborative Filtering,简称CF)推荐算法,CF的基本思想是根据用户之前的喜好来给用户推荐操作。CF算法分为基于用户和基于内容两类。基于用户的协同过滤算法基本思想是如果用户A喜欢操作a,用户B喜欢操作a、b、c,用户C喜欢操作a和c,那么认为用户A与用户B和C相似,因为他们都喜欢a,而喜欢a的用户同时也喜欢c,所以把c推荐给用户A。该算法用最近邻居(nearest-neighbor)算法找出一个用户的邻居集合,该集合的用户和该用户有相似的喜好,算法根据邻居的偏好对该用户进行预测。基于内容的协同过滤算法与基于用户的协同过滤算法不同点为以内容为中心,再通过计算用户对不同历史操作的喜欢程度,从而推荐相似的操作给用户,基于用户的协同过滤算法的推荐质量取决于用户历史数据集,同时存在稀疏性问题与可扩展性问题。协同过滤算法示意图如图1。
本文提出一种基于行为相似度的空调操作推荐方法,把用户特征划分为多个特征组,并通过多元线性回归模型来确定影响因子,然后通过Fo-KNN来进行推荐。更好的解决了用户不同特征对空调操作推荐影响不同的问题。
3 空调操作实时推荐
本章详细介绍空调操作实时推荐的算法与过程。总体架构如图2。
首先,对用户信息提取用户特征,把用户特征分为多个特征组,结合用户的历史行为相似度,使用多元线性回归模型,计算出各个特征组的权重系数;然后,根据特征和权重来计算用户之间的相似度;接着,针对特定用户,通过Fo-KNN算法查找该用户最近的K个邻居,根据该K个邻居的行为,推荐该用户的空调操作。
接下来,本文将从数据预处理、特征提取、KNN实时推荐这几个部分进行阐述。
3.1 数据预处理
3.1.1 数据采集
从用户APP和物联网空调上,收集用户相关信息。本文所采集的数据源包含了以下两个部分内容:
(1)用户信息。用户信息包括用户年龄、性别、职业、收入、体质、房屋面积、朝向、楼层、用户地理位置等,此类数据记录了用户信息,用于计算用户之间的相似度。
(2)用户操作数据。用户操作数据包括用户开关机、设置温度、设置风速、设置风向、设置模式等数据,此类数据记录了用户对于空调的完整操作,以及操作的时间,可用于统计用户行为。考虑到操作行为的时序性、时效性以及消息缓冲等问题,本文选取Kafka和Flume来实现空调数据的接入:通过Flume接收多渠道的数据;通过Kafka接收Flume处理后的数据,按照多个topic,进行队列划分和缓冲,等待下游消费。
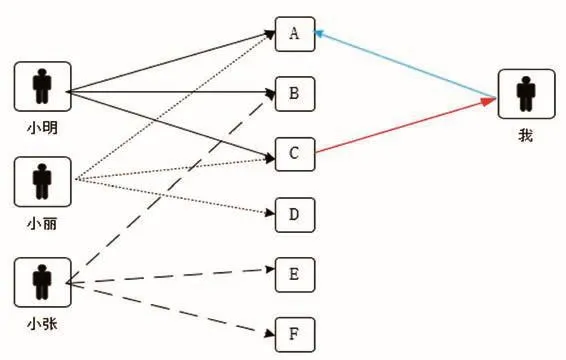
图1 协同过滤算法示意图

图2 行为推荐流程图

图3 不同K值的平均准确率

图4 与KNN准确率对比图
3.1.2 数据清洗
云端所接收的数据,其中包含了部分噪音数据,例如上报频率异常等,此类数据形成原因是由于早期物联网空调出产品类繁多,电控软件版本过低,又不支持远程升级,需要对此类数据进行清洗。
3.1.3 数据存储
在本文中,数据是多样的。从内容上看,主要包括用户操作数据、用户信息等;从结构上看,包括结构化数据、半结构化数据和非结构化数据。针对不同的场景,本文选取HDFS、HBase、Mysql和Redis来构建数据仓库。
HDFS:基于Hadoop的分布式文件存储系统,适用于存储超大规模的源数据。本文用于存储空调上报的非结构化原始数据。
HBase:基于Hadoop的Nosql数据库系统,适用于超大规模数据的快速查找和更新。本文用于存储经过大数据计算后的结构化和半结构化数据。
Mysql:关系型数据库,适用于存储小规模的结构化数据。本文用于存储用户空调机型、空调地理位置等数据。
Redis:缓存系统,适用于存储高频访问的key-value数据。本文用于存储空调实时状态数据。
3.1.4 数据计算
大数据平台,需要支持大规模数据的批量和实时计算需求,以实现数据抽取、数据预处理、数据分析和实时监控等。本文使用MapReduce、Hive和Spark streaming来实现大规模数据的分布式计算。
MapReduce:是第一代计算引擎,“分治法”思想。本文用于大规模数据的批量离线计算。
Hive:通过把类SQL语句分解成MapReduce任务,以实现结构化数据的SQL操作。本文用于结构化数据的离线统计分析。
Spark streaming:建立在Spark之上的实时计算框架,通过丰富的API和基于内存的高速执行引擎,可以满足用户流式、交互式的应用场景。本文用于上报数据的实时计算。
3.2 特征提取
3.2.1 用户表示
本文以年龄、性别、体重、职业、收入、体质、房屋面积、朝向、楼层、用户地理位置等信息来表示用户,记为V=<年龄、性别、体重、职业、收入、体质、房屋面积、朝向、楼层、地理经度、地理纬度>。如表1所示。
例:用户1=<22, 男, 75, 销售, 5万, 怕热, 96, 北, 11,113.3, 22.5>。
3.2.2 用户特征组
考虑到用户特征之间的特性与关联性,我们将用户特征分为用户特性、房屋特性、地理特性这三个组。其中,用户特性Vu=<年龄、性别、体重、职业、收入、体质>,房屋特性Vh=<房屋面积、朝向、楼层>,地理特性Vg=<地理经度、地理纬度>。
因此,用户V可表示为
本文通过用户特征组来衡量不同用户之间的行为相似度,不同的特征组对用户行为具有不同的影响因子。
3.2.3 影响因子
以用户特征组作为自变量,用户在同一时刻的行为相似度作为因变量,通过多元线性回归模型,训练出特征组的影响因子。
(1)用户特性Vu相似度
本文采用余弦距离来计算用户特性之间的相似度。具体公式如下;
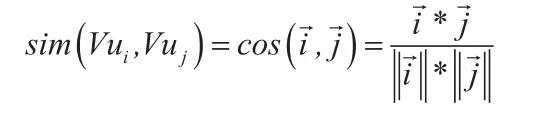
(2)房屋特性Vh相似度
本文也采用余弦距离来计算房屋特性之间的相似度。具体公式同上。
(3)地理特性Vg相似度
本文采用欧式距离来计算地理特性之间的相似度。具体公式如下:

其中,distance(i,j)表示地理特性i与地理特性j的距离,lati和lngi分别表示地理特性i的经度和纬度。
(4)用户行为Vo相似度
选取部分用户的历史操作行为作为训练集,采用欧式距离来计算用户行为之间的相似度。具体公式同上。
(5)多元线性回归
以用户之间的用户特性Vu相似度、房屋特性Vh相似度、地理特性Vg相似度作为自变量,以用户之间的操作相似度作为因变量,根据多元线性回归模型来训练出每个特征组的影响因子。
自变量:xi=
因变量:yi=Voi
训练集:{(x1,y1),(x2,y2),…,(xN,yN)}包含N条训练数据,其中,xi是三维向量,
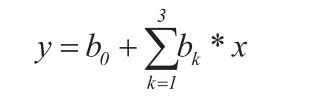
其中,
3.3 基于Fo-KNN的实时推荐
基于用户特征组和影响因子,本文通过优化的KNN:Fo-KNN模型,对空调行为进行实时推荐。
首先,根据用户信息和历史操作行为,计算每两个用户之间的行为相似度,并生成相似度矩阵;然后,针对某个特定用户,从当前使用空调的所有用户中选取与该用户距离最近的K个邻居;接着,以用户距离为权重,计算这K个邻居的操作行为加权平均值,并以此作为对该用户的实时行为推荐。
(1)相似度计算
通过3.2小节,每个用户都可以表示为
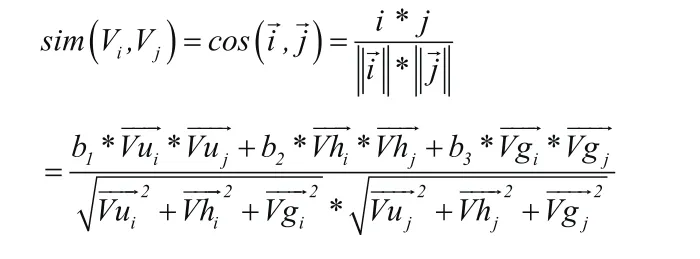
生成的用户行为相似度矩阵如表2。
(2)选取K个邻居
首先,通过云端实时查询当前正在使用空调的所有用户;针对某个特定用户,从这些用户中选取与该用户相似度最高的K个邻居。

表1 用户表示

表2 用户历史行为相似度矩阵

表3 数据集
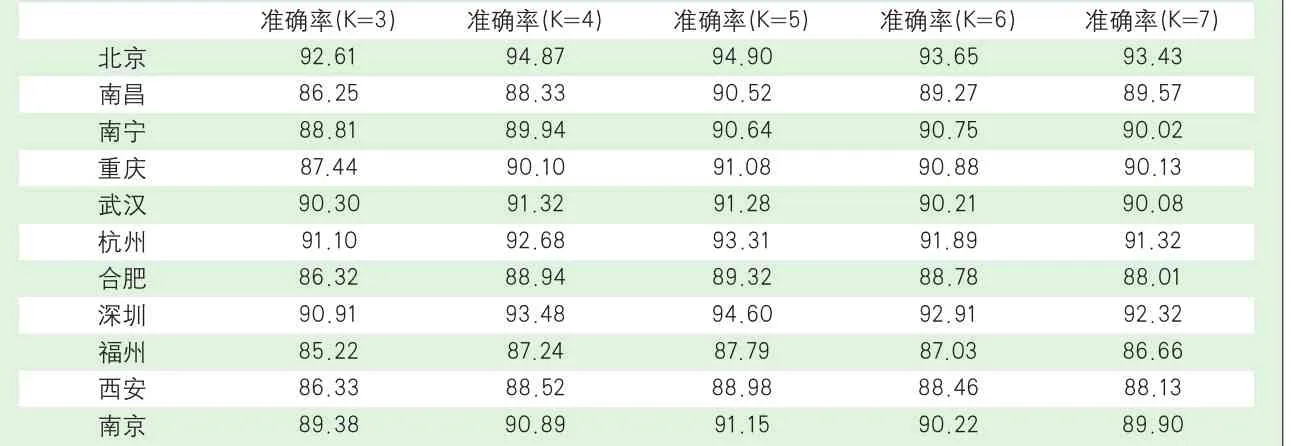
表4 准确率
(3)实时行为推荐
以用户距离为权重,计算这K个邻居的当前操作行为加权平均值,并以此作为对该用户的实时行为推荐。推荐的操作行为包括设置温度和设置风速等。下面以设置温度为例进行说明。
K个邻居的设置温度加权平均:
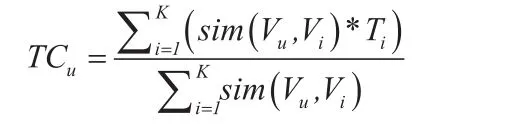
其中,sim(Vu,Vi)表示用户u和用户i之间的相似度,Ti表示用户i当前的设置温度,TCu表示当前用户u的推荐设置温度。
TCu即为推荐的实时设置温度,设置风速等其他操作行为类似。
4 实验与分析
本节通过实验来评估该推荐算法的效果。首先,介绍实验的数据集和评估方法;然后,通过参数调优和城市抽样,对实验结果进行分析并给出实验结论。
4.1 数据集与评估方法
该推荐方法,主要涉及用户信息和空调使用行为这两类数据。本实验随机抽取2017年的部分用户及其操作行为作为数据集,其中包括训练集和测试集,具体如表3。
本文实时推荐的空调操作包括设置温度、设置风速等。下面以设置温度为例,介绍本文实验。
实验中,对于测试集中的用户及行为,通过推荐的设置温度和用户实际调节的设置温度来计算准确率P,以此评估推荐算法的效果。准确率P计算公式为:

其中,TCu表示算法推荐的设置温度,Ts表示用户实际的设置温度。14表示设置温度取值范围为[17,30],以1摄氏度为精度,共14个值。
4.2 结果与分析
该实验通过参数调优和城市抽样,对推荐算法的结果进行实验论证,具体的准确率如表4所示。
4.2.1 参数调优
Fo-KNN算法中,K的取值对算法准确率影响较大,本文针对K的不同取值进行调优。从图3中可以看出,当K=5时平均准确率最高。因此,Fo-KNN算法中K值参数选取为5。
4.2.2 与KNN算法效果对比
本实验抽样全国不同地区的11个城市,分别运行Fo-KNN算法与KNN算法,对推荐结果进行评估。KNN算法实现方法为:对于用户所有特征,不进行特征组划分,同时不计算各个特征的影响因子,运行KNN算法计算准确率。对比图如图4所示。
从该实验可以看出,Fo-KNN算法整体的平均准确率达到了91.23%,KNN算法整体的平均准确率为86.26%,Fo-KNN准确率提升了接近5%,取得了较好的效果。同时,在抽样的11个城市中,北京和深圳准确率最高,福州和西安最低,其他较平均。整体来看,经济较发达的城市准确率偏高,可能是因为经济越好的地区,空调使用需求越集中。
5 总结
本文研究基于行为相似度的空调操作实时推荐,提出了优化的KNN算法:Fo-KNN算法,把用户特征划分为不同的特征组,深入研究各个特征组对空调操作的影响,解决了空调操作推荐中用户研究不深入的问题,为用户提供更加精准的空调操作推荐服务。首先,提取用户特征,并把用户特征分为多个特征组;然后,结合用户行为相似度,计算各个特征组的影响因子;接着,基于Fo-KNN算法,经过计算相似度、选取K个邻居、实时推荐,为用户实时推荐空调使用行为;最后,通过参数调优及准确率对比,与KNN算法进行效果对比,算法准确率提升了接近5%,并对实验结果进行分析。
猜你喜欢
现代畜牧科技(2021年4期)2021-07-21
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
流行色(2020年9期)2020-07-16
家庭影院技术(2018年9期)2018-11-02
中国交通信息化(2018年5期)2018-08-21
CHIP新电脑(2017年6期)2017-06-19
小学阅读指南·低年级版(2017年5期)2017-05-18
汽车维护与修理(2016年10期)2016-07-10
