
基于时间序列与信息融合的突发事件信息瀑布溯源方法
2018-12-08 11:17朱鹏朱星圳王莉
现代情报 2018年10期
朱鹏 朱星圳 王莉

〔摘 要〕为探究突发事件信息瀑布溯源机理,本文设计了基于时间序列与信息融合的信息瀑布溯源模型。论文以“美联航拖拽亚裔”突发事件为案例,运用TF-IDF与TextRank算法进行关键信息抓取,借助OWL本体技术、时间序列及信息融合模型,实现了突发事件信息瀑布的溯源,并提醒相关职能机构等控制事态发展。本研究是对信息溯源方法的探索与补充,能帮助相关管理机构对信息瀑布实行预测与调控。
〔关键词〕突发事件;信息瀑布;时间序列;信息融合模型;溯源方法
DOI:10.3969/j.issn.1008-0821.2018.10.006
〔中图分类号〕G206.2 〔文献标识码〕A 〔文章编号〕1008-0821(2018)10-0038-05
〔Abstract〕In order to explore the traceability mechanism of emergencies information cascades,this paper designs an information cascades traceability model based on time series and information fusion.This study takes“United Airlines dragging Asian Americans”as a case,uses TF-IDF and TextRank algorithm to capture key information,then takes OWL ontology technology,time series and information fusion model to trace the origin of emergencies information cascade,and remind the relevant functional agencies to control the development of events.This work is an exploration and supplement to the method of information traceability,it can help the relevant management institutions to predict and control the information cascade.
〔Key words〕emergencies;information cascade;time series;information fusion;tracing method
隨着云计算、物联网、大数据等技术的兴起和发展,信息以井喷式的速度增长,海量信息资源开发与共享的时代已经来临,使得突发事件的研究进入了新阶段。近年来,各类高关注度的突发事件层出不穷,如马航MH370失踪事件,美国波士顿马拉松爆炸事件,美国联合航空公司强行拖拽亚裔乘客事件等。这类突发事件会产生极大的社会影响,快速形成突发事件信息瀑布,此类信息瀑布发展态势迅猛,往往会对依存的环境与组织带来颠覆性与毁灭性的破坏[1]。深入研究突发事件信息瀑布,厘清其发生机制、演化特征,对理解与治理突发事件舆情有着重要的理论与现实意义[2]。基于此,本文从信息瀑布溯源的角度探究突发事件信息瀑布发生发展的演进过程,从而为突发事件信息瀑布治理提供策略支持。目前,已有不少根据追踪路径重现信息历史状态与演变过程,实现数据信息历史档案追溯的技术[3],但由于信息具有易复制、易扩散等特性,其溯源存在一定的难度。针对此,本文设计了基于时间序列与信息融合的突发事件信息瀑布溯源的新方法,挖掘突发事件信息瀑布各时间节点的源头,以期为信息瀑布的调控治理提供策略支持。
1 相关工作
信息溯源(Information Provenance)又称信息起源[4],Simmhan等人[5]将数据溯源定义为从元数据到数据产品的衍生过程信息追踪。Glavic等人在其研究中认为数据溯源是对目标数据衍生前的原始数据以及演变过程的描述[6];Interlandi等在此基础上进行了拓展,认为数据溯源作为一种元数据,记录工作流演变过程、标注信息以及实验过程等信息[7]。
国内来看,戴超凡等[8]在前人理论研究的基础上,将数据溯源定义为“记录数据从产生到消亡或转换的整个生命周期内所发生的变化和经过处理的信息”;明华等[9]在研究中将其定义为“根据追踪路径重现数据的历史状态和演变过程,实现数据历史档案追溯的一种追本溯源技术”。由此可见,信息溯源的重点在于追踪强调数据处理过程、流转产生的数据流、流经节点、使用情况等的信息,以服务于流程再造,追本溯源。也就是说,数据溯源可定义为根据数据运动产生的数据流信息,在面临个人数据隐私泄露溯源等需要时,重现个人数据的历史演变路径的溯源过程,从而确定泄露源或发出者的身份、位置等信息[10]。
数据溯源重点在于建立数据溯源模型,由于数据结构越来越复杂,数据量越来越大,需要考虑数据的异构性,形成结合时间、过程和异构分布特征的模型,再将这些数据信息存储为带有溯源信息的异构数据库,通过数据库接口连接成目标数据库,最终从这个目标数据库进行逆操作实现数据溯源[11]。目前最具代表性的溯源方法有两种:基于查询反演(QueryInversion)的数据溯源方法[12]和基于标注(Annotation)的数据溯源方法[13]。前者是对查询或演化过程构造逆查询或反向推导,后者是指原始数据的传播过程中加入标注信息一起传播,通过对结果数据的分析和推导找到标注信息从而找到数据起源。
综合来看,目前关于信息溯源的研究已经取得了丰厚的成果,然而尚有部分内容值得探究。具体变现为:首先,大数据时代效率尤为重要,但基于标注的信息溯源方法产生的标注信息量甚至大于原始数据量,这使得数据信息在传输过程的速度大大降低;而基于查询反演的溯源方式则在信息传递一段时间后难以根据反函数得出准确结果,其误差会随着信息传播时间的长度发生正向增长。其次,作为动态数据流,高频率的数据输入对溯源系统的开销和吞吐量有着极高的要求,而标注信息和反向推导的过程都占据了大量的空间和时间。基于此,本文将这两种传统方法融合取其精粹,提出了基于时间序列与信息融合的信息溯源方法,并将其应用到突发事件信息瀑布溯源领域。
2 研究模型
2.1 突发事件信息瀑布时间序列
突发事件信息瀑布类型多样,但都具有其最基本的时间序列特征,都要经历形成、传播、漂移、嬗变与演进五个阶段[14],且突发事件信息瀑布的产生一般难以预测,突发事件一旦发生,人们就争相通过互联网来交流相关信息,提出诸多意见并多次转发传播从而形成突发事件信息瀑布,对社会稳定造成不利影响[15];形成和传播是突发事件信息瀑布发生质变后产生巨大影响的过程。由于事件被推向大众面前,其产生过程中逐步积累起来的种种意识形态通过网络数据信息的形式快速传递,产生巨大的影响力,给整个社会带来不同程度的动荡[16];漂移与嬗变期是指在突发事件信息瀑布广泛传播之后,由此带来的人们的议论,形成社会舆论,超过了相关部门可以管控的阶段。许多情况下,漂移与嬗变之间没有明显的界线划分,两者是同时进行的[17];整个突发事件信息瀑布发展稳定之后进入演进的节点。这一时期按照不同的标准会有不同的结论。而信息瀑布在经历这些时间序列后,会步入新信息瀑布形成阶段,从管理的角度出发,可以以社会恢复正常运行状态为结束标志;从过程的角度出发,可以以危害和影响完全消除作为结束标志[18]。本文设计的突发事件信息瀑布时间序列如图1所示,与此同时,针对时间序列我们提出了各阶段可能对应的平台或过程。
如图1所示,突发事件信息瀑布时间序列的每个过程都有具体的平台或相应机构,在不同的时间节点承担不同的调控职责,在突发事件信息瀑布时间序列的演化过程中,可以通过平台或机构来检测突发事件现象,一旦事态不能正常发展,可以溯源找到责任人,同时实现对突发事件信息瀑布做出应对与调控。因而,追踪与捕获突发事件信息瀑布时间序列的各个阶段中引发突发事件的实体行为可以更好地进行问题溯源。
2.2 突发事件信息瀑布信息融合模型设计
信息融合是将各种途径、任意时间和空间上获得的信息作为一个整体进行综合分析处理,为决策以及控制服务[19]。信息融合模型至少需要有原始数据层、特征层以及决策层。其信息抽象程度由低向高逐层划分。其中原始数据层是对收集到的数据的存储、检测和过滤,進行数据的录入和简单筛选,在包括时间序列数据、焦平面数据等像素或分辨单位上进行;特征数据层则是对上一层中的原始信息进行处理后存储的内容。收集到的原始信息多种多样,而储存的特征数据则是对这些信息的融合,特征层数据的融合是将信息特征进行信息聚类、分类等数据处理过程,为决策层提供数据输入;决策层则是根据不同形式的数据输入输出目标,将特征数据进行融合。决策层融合的输出分为两种形式:硬决策是输出最终结论,而软决策是同时给出各个结论的支持程度[20]。在上述3个层次中,特征层是最重要的环节,它在整个信息融合模型中起到了承上启下的作用。
在本文中,主要依托时间序列数据,构建实现突发事件信息瀑布溯源的信息融合模型,具体步骤如下:
Step 1:明确本体构建的领域范围。对于突发事件信息瀑布来说,应当选定具体的突发事件,尽可能涵盖所选领域中的所有知识和线索,但范围不能过大,极大的本体范围会对整个模型造成难以承受的负荷。本文拟选择美联航拖拽乘客的事件,本体领域是与美联航相关的所有信息资源,其时间上既包含事件发生前的相关信息,又包括后续报道等,形成较为完整的突发事件信息瀑布时间序列。
Step 2:获取领域知识、定义关系。一旦选定某一突发事件,便可以将与之相关的数据信息都收集进数据仓库,明确数据之间的关系,定义明确、清晰的类,确定属性,找出类之间的逻辑关系。将其作为原始数据,即作为信息融合模型中的原始数据层。明确美联航事件中涉及的人事物等,整理其中的关系。
Step 3:用OWL表示本体。OWL本体包含有类、属性和个体的描述,将抽象出来的时间序列数据信息放到模型中的特征数据层。本体本身就是从现实知识世界中抽象剥离出来的,因此本体将获取到的领域知识转化成了其可处理的具有特征项的编码。本文中美联航突发事件信息瀑布的本体抽象如图2所示。
在图2中,左侧是有关航空产业(owl:Thing)的部分概念,整个航空产业中包含有航空公司和乘客两个部分,这两个子类之间是互斥关系(owl:disjointWith)。右侧是美联航(美国联合航空公司)的一个个体,是左侧概念在现实世界中反映的一个值,乘客的值域是群众,但同时群众也可以是乘客,两者为互逆关系(owl:inverseOf),且两者都有个体的属性。最后再对每个类添加个体,如:亚裔乘客,媒体等,表示现实世界中的联系,见图3。
通过图3中OWL本体的逻辑关系可以看出:最底层取自于现实世界,是客观存在的个体,是现实知识的收集,是本体的来源;中间层是知识概念化,本体模型是从现实知识体系中抽象出来的,代表了所选领域的特征,独立于任何表示语言;顶层是机器可识别的编码层,是用特定的OWL语言将前面层的知识转化成计算机语言[21]。
Step 4:提出信息融合模型。本文采用关联数据思想进行模型连接,关联数据采用RDF数据模型。由于每个数据的网址URL就是其名称标识(包含各种格式的元数据信息),因此在关联数据的基础上建立的信息融合模型中存储的数据本身就是结构化数据。准确来说,关联数据是指网络上传播的信息或数据,可以与外部数据相互链接[22]。OWL作为本体表示语言继承了RDF的基本事实陈述方式、类和属性分层结构,用该语言对数据仓库中的关联数据构架本体,形成机器可处理的有语义的编码。
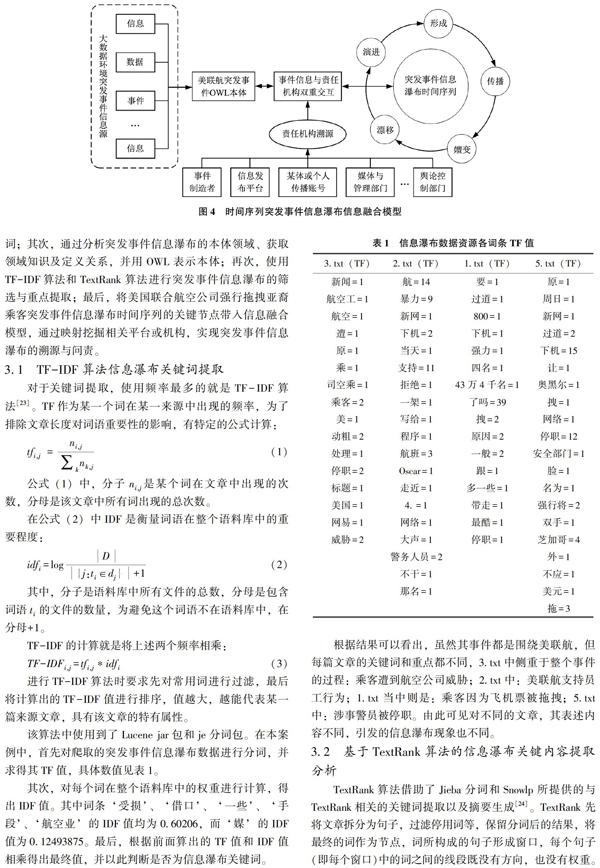
本文提出的时间序列信息融合模型,主要通过采集美联航突发事件形成的舆情信息瀑布,构建美联航突发事件OWL本体,并基于OWL本体设计突发事件信息与责任机构双重交互的模块。该模块既链接突发事件信息瀑布的时间序列(形成、传播、嬗变、漂移、演进),又实现了责任机构的溯源问责,能根据突发事件的具体时间节点和事件状态,实现突发事件信息瀑布的管控与问责。具体模型如图4所示。
3 实验与结果分析
构建时间序列突发事件信息瀑布信息融合模型后,本研究选取2017年4月9日发生的美国联合航空公司强行拖拽亚裔乘客事件作为模型验证的实验案例,此突发事件发生后引发广大人民群众的热议,随着事件的发展,人们对涉事人员的态度也褒贬不一,其中不乏一些激进的言论和行为,形成了较为强烈的信息瀑布。
实验首先通过从网站等媒体平台中抓取了美国联合航空公司强行拖拽亚裔乘客事件信息瀑布的新闻并提取关键
词;其次,通过分析突发事件信息瀑布的本体领域、获取领域知识及定义关系,并用OWL表示本体;再次,使用TF-IDF算法和TextRank算法进行突发事件信息瀑布的筛选与重点提取;最后,将美国联合航空公司强行拖拽亚裔乘客突发事件信息瀑布时间序列的关键节点带入信息融合模型,通过映射挖掘相关平台或机构,实现突发事件信息瀑布的溯源与问责。
3.1 TF-IDF算法信息瀑布关键词提取
该算法中使用到了Lucene jar包和je分词包。在本案例中,首先对爬取的突发事件信息瀑布数据进行分词,并求得其TF值,具体数值见表1。
其次,对每个词在整个语料库中的权重进行计算,得出IDF值。其中词条‘受损、‘借口、‘一些、‘手段、‘航空业的IDF值均为0.60206,而‘媒的IDF值为0.12493875。最后,根据前面算出的TF值和IDF值相乘得出最终值,并以此判断是否为信息瀑布关键词。
根据结果可以看出,虽然其事件都是围绕美联航,但每篇文章的关键词和重点都不同,3.txt中侧重于整个事件的过程:乘客遭到航空公司威胁;2.txt中:美联航支持员工行为;1.txt当中则是:乘客因为飞机票被拖拽;5.txt中:涉事警员被停职。由此可见对不同的文章,其表述内容不同,引发的信息瀑布现象也不同。
3.2 基于TextRank算法的信息瀑布关键内容提取分析 TextRank算法借助了Jieba分词和Snowlp所提供的与TextRank相关的关键词提取以及摘要生成[24]。TextRank先将文章拆分为句子,过滤停用词等,保留分词后的结果,将最终的词作为节点,词所构成的句子形成窗口,每个句子(即每个窗口)中的词之间的线段既没有方向,也没有权重。而句子之间的线段则是根据句子之间的相似度计算权重。
由于突发事件信息瀑布评论数据量巨大,在实验中先在数据库中将评论筛选1次,对单条评论字数超过20的进行关键词提取,但仍旧有着极大的数量,因而实验进行了多次重要关键词的提取与分析。
3.3 突发事件信息瀑布溯源结果分析
3.3.1 基于时间序列突发事件信息瀑布溯源分析
每个事件都有其发生的时间序列,当事件成为突发事件时,最初爆发的时间点就成为突发事件的起点,所有与该时间点相近的时刻所产生的相关言论、评论都极有可能会和该突发事件信息瀑布产生根源处的联系。按时间序列溯源就是找出突发事件信息瀑布的形成、传播、漂移、嬗变、演进的各个时间节点,对这些时刻附近的与该突发事件相关的信息抓取下来,找出对应信息的发布人,从而达到确定责任人的目的。这是溯源过程中最简单的方式。其效果对新闻网站上的信息瀑布作用比较大,新闻网站上的信息大多是基于一定事实根据的,所以其发布的信息在网络上的流传也较为有效,形成的信息瀑布也比较固定规范,按时间序列溯源也很容易找到最初发布信息的网站或集体。
3.3.2 根据信息融合模型对突发事件信息瀑布溯源分析
实验中,运用了TF-IDF和TextRank两种算法提取关键信息,在信息融合模型中建立了有关部门和关键信息的词典,该词典中包含有各个部门以及与部门相关的事件关键词,通过对收集到关键词与词典中关键词的匹配,尽可能多的选取相关的部门作为责任方。
通过多次计算,可以得出,在本文收集到的新闻数据中的关键信息为:美联航、强行、拖拽乘客、下飞机、医生;评论数据中的关键词为:美国、歧视、华人、选、机票。由此可以看出事件发生后媒体报道的新闻重点在于整个事件的过程以及涉及的人或单位;而评论中含有群众的主观想法,这些想法会进一步形成信息瀑布,引发社会议论与冲动性行为,如果不及时处理可能会引起社会化激進行为,产生不良的社会影响。从评论中流落出的主观思想来看,人民群众对该突发事件十分愤慨,更是在严厉谴责美联航的行为,如果任由事件发展下去,会对美联航的极为负面的影响,不仅会受到乘客的联合抗议与抵制,受到华人的强烈谴责,另外中美的航空产业发展也可能因此受到影响。为了控制事态发展,找出解决对策,在该案例中通过时间序列信息融合模型溯源提取出来的关键词可以帮助追溯相关的责任单位,匹配到的与之相关的责任者。
4 结 论
本研究通过对信息瀑布溯源的探讨,借助TF-IDF、TextRank和OWL本体技术分析数据来源的多样性和复杂性,基于时间序列与信息融合模型,设计了运用多种算法提取关键信息的方法,对抓取到的信息瀑布数据进行处理分析,通过对分析处理的结果进行溯源,找到突发事件过程中的关键人物以及相关部门。论文以美国联合航空公司强行拖拽亚裔乘客突发事件为案例,验证了模型和方法的可行性,并认为通过时间序列和信息融合模型对信息瀑布溯源是行之有效的。本研究能为政府等机构组织控制突发事件事态发展提供决策支持,研究方法是对信息溯源的增量补充。
参考文献
[1]Sattari M,Zamanifar K.A Cascade Information Diffusion Based Label Propagation Algorithm for Community Detection in Dynamic Social Networks[J].Journal of Computational Science,2018,25:122-133.
[2]李建标,巨龙,任广乾.钝化信念维系的信息瀑布及其应用[J].经济评论,2011,(3):30-35.
[3]沈志宏,张晓林.语义网环境下数据溯源表达模型研究综述[J].现代图书情报技术,2011,(4):1-8.
[4]Stamatogiannakis M,Athanasopoulos E,Bos H,et al.PROV2R:Practical Provenance Analysis of Unstructured Processes[J].ACM Transactions on Internet Technology,2017,17(4):37.
[5]Simmhan Y L,Plale B,Gannon D.A Framework for Collecting Provenance in Data-Centric Scientific Workflows[J].Icws,2006:427-436.
[6]Glavic,Boris,Dittrich,Klaus.Data Provenance:A Categorization of Existing Approaches[J].Symposium on Combustion,2007,23(1):693-698.
[7]Interlandi M,Shah K,Tetali S D,et al.Titian:Data Provenance Support in Spark[J].Proceedings of the Vldb Endowment,2015,9(3):216-227.
[8]戴超凡,王濤,张鹏程.数据起源技术发展研究综述[J].计算机应用研究,2010,27(9):3216-3221.
[9]明华,张勇,符小辉.数据溯源技术综述[J].小型微型计算机系统,2012,(9):1917-1923.
[10]殷建立,王忠.大数据环境下个人数据溯源管理体系研究[J].情报科学,2016,35(2):139-143.
[11]倪静,孟宪学.关联数据环境下数据溯源描述语言的比较研究[J].现代图书情报技术,2013,29(2):18-23.
[12]Fan H.Tracing Data Lineage Using Automed Schema Transformation Pathways[M].Advances in Databases.Springer Berlin Heidelberg,2002:50-53.
[13]Chiticariu L,Tan W C,Vijayvargiya G.DBNotes:A Post-it System for Relational Databases Based on Provenance[C].ACM SIGMOD International Conference on Management of Data,Baltimore,Maryland,Usa,June.DBLP,2005:942-944.
[14]Zhao Xin,Barber Stuart,Taylor Charles C.,et al.Classification Tree Methods for Panel Data Using Wavelet-transformed Time Series[J].Computational Statistics & Data Analysis,2018,127:204-216.
[15]张玉亮.基于发生周期的突发事件网络舆情风险评价指标体系[J].情报科学,2012,(7):1034-1037.
[16]杨长春,袁敏.基于交互关系的突发事件热度预测研究[J].现代情报,2017,37(3):40-45.
[17]兰月新.突发事件网络谣言传播规律模型研究[J].图书情报工作,2012,56(14):57-61.
[18]李纲,陈璟浩.突发公共事件网络舆情研究综述[J].图书情报知识,2014,(2):111-119.
[19]曹高辉,徐元,梁梦丽,等.基于情境的信息融合模型研究[J].情报学报,2017,36(6):537-546.
[20]杜元伟,杨娜,DUYuan-wei,等.大数据环境下双层分布式融合决策方法[J].中国管理科学,2016,24(5):127-138.
[21]顾益军.融合LDA与TextRank的关键词抽取研究[J].现代图书情报技术,2014,30(7):41-47.
[22]丁楠,潘有能.基于关联数据的图书馆信息聚合研究[J].图书与情报,2011,(6):50-53.
[23]Wu H C,Luk R W P,Wong K F,et al.Interpreting TF-IDF Term Weights as Making Relevance Decisions[J].Acm Transactions on Information Systems,2008,26(3):55-59.
[24]王子璇,乐小虬,何远标.基于WMD语义相似度的TextRank改进算法识别论文核心主题句研究[J].现代图书情报技术,2017,1(4):1-8.
(责任编辑:孙国雷)
